用于参数化二元神经网络的自动机器学习策略网络的制作方法
用于参数化二元神经网络的自动机器学习策略网络
背景技术:
1.深度神经网络(deep neural network,dnn)是解决广泛领域的复杂问题的工具,例如计算机视觉、图像识别、图像处理、语音处理、自然语言处理、语言翻译、以及自动驾驶车辆。最近的改进已使得dnn的体系结构变得明显更深并且更复杂。因此,顶级性能的dnn模型的密集存储、计算和能量成本阻止它们部署在资源受限的设备(例如,客户端设备、边缘设备,等等)上进行实时应用。
2.二元神经网络可以在神经网络中为权重和/或激活使用二元值。这样做与全精度实现方式相比可以提供更小的存储要求(例如,1比特相对于32比特浮点值)以及更便宜的逐比特操作。然而,由于二元值的精度较低,二元神经网络准确性低于全精度实现方式。此外,传统的训练二元神经网络的方法并不灵活,因为传统的解决方案在传统时间密集型训练的一轮中只能输出单个二元神经网络实例。更进一步,二元神经网络的传统训练采用低效率的两阶段训练,这要求预先训练全精度32比特模型,然后从预先训练的全精度32比特模型来训练二元版本。
附图说明
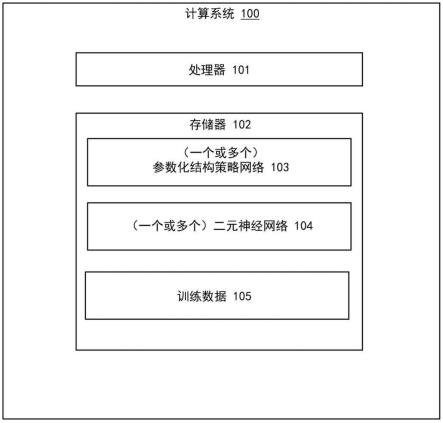
3.图1图示了系统的实施例。
4.图2图示了参数化二元神经网络的自动机器学习策略网络的示例。
5.图3图示了训练自动机器学习策略网络的示例。
6.图4图示了第一逻辑流程的实施例。
7.图5图示了第二逻辑流程的实施例。
8.图6图示了第二逻辑流程的实施例。
9.图7图示了存储介质的实施例。
10.图8图示了系统的实施例。
具体实施方式
11.本文公开的实施例为参数化二元神经网络提供了自动机器学习(machine learning,ml)策略网络(本文也称为“策略代理”或“策略网络”)。一般来说,策略网络可以近似一个或多个二元神经网络的二元权重的后验分布,而不要求全精度(例如,32比特浮点)参考值。一个或多个二元神经网络可以对二元权重的后验分布进行采样,而不要求应用传统上为增强二元神经网络的准确性而要求的缩放因子(例如,逐层和/或逐滤波器的缩放因子)。策略网络一般可提供多个二元权重共享设计。例如,策略网络可以提供逐层权重共享、逐滤波器权重共享、和/或逐核权重共享。可以使用四阶段强化学习算法来训练策略网络。有利的是,这样做有利于对不同的二元权重实例进行采样,以从经训练的策略网络来训练给定的二元神经网络体系结构,其中二元神经网络的体系结构(它定义了如何在层级拓扑结构中堆叠神经网络的参数)在训练之前是已知的。通过提供增强的准确性,二元神经网络的不同实例可以支持硬件专门化和/或用户特定的应用。换句话说,不同的用户和/或设
备可以各自拥有专用的二元神经网络,它们共享相同的体系结构,同时提供相似的识别准确性。此外,相对于全精度实现方式,二元神经网络和策略网络提供了增强的精度,并且存储、能量和处理资源要求有所降低。
12.大体上,关于本文使用的符号和术语,接下来的详细描述的一个或多个部分可按照在计算机或计算机的网络上执行的程序过程来呈现。这些过程描述和表示被本领域技术人员用来最有效地将其工作的实质传达给本领域其他技术人员。过程在这里并且一般而言被设想为是通向期望结果的操作的自洽序列。这些操作是要求对物理量的物理操纵的操作。通常(但并非一定),这些量采取能够被存储、传送、组合、比较和以其他方式操纵的电信号、磁信号或光信号的形式。已证明有时将这些信号称为比特、值、元素、符号、字符、项、数字等等是方便的,主要是出于习惯用法的原因。然而,应当注意,这些和类似的术语都将与适当的物理量相关联并且只是应用到这些量的方便标签。
13.另外,这些操纵经常是按通常与人类操作者执行的精神操作相关联的术语(例如添加或比较)来提及的。然而,在本文描述的形成一个或多个实施例的一部分的任何操作中,人类操作者的这种能力并不是必要的,或者在大多数情况下并不是想要的。更确切地说,这些操作是机器操作。用于执行各种实施例的操作的有用机器包括由存储在内的根据本文的教导编写的计算机程序来选择性激活或配置的通用数字计算机,和/或包括为要求的目的而特别构造的装置。各种实施例还涉及用于执行这些操作的装置或系统。这些装置可以是为要求的目的而特别构造的或者可包括通用计算机。对各种这些机器所要求的结构从给出的描述中将是清楚的。
14.现在参考附图,附图中相似的标号始终用于指代相似的元素。在接下来的描述中,出于说明目的,记载了许多具体细节以提供对其的透彻理解。然而,可明显看出,没有这些具体细节也可实现新颖的实施例。在其他实例中,以框图形式示出公知的结构和设备以促进对其的描述。意图是覆盖权利要求的范围内的所有修改、等同和替换。
15.图1图示了为参数化二元神经网络提供自动机器学习策略网络的计算系统100的实施例。计算系统100可以是任何类型的计算系统,例如服务器、工作站、膝上型电脑、或者虚拟化计算系统。例如,系统100可以是嵌入式系统,例如深度学习加速卡、具有深度学习加速的处理器、神经计算棒,等等。在一些示例中,系统100包括片上系统(system on a chip,soc),而在其他实施例中,系统100包括印刷电路板或者具有两个或更多个分立组件的芯片封装。系统100包括处理器101和存储器102。图1中描绘的计算系统100的配置不应被认为是对本公开的限制,因为本公开适用于其他配置。处理器101代表了任何类型的计算机处理器电路,例如,中央处理单元、图形处理单元,或者其他任何处理单元。另外,处理器中的一个或多个可包括多个处理器、多线程处理器、多核处理器(无论多个核心是共存于同一管芯上还是在分开的管芯上)、和/或一些其他种类的多处理器体系结构,通过这些体系结构,多个物理上分开的处理器以某种方式链接起来。
16.存储器102代表了任何类型的信息存储技术,包括要求不间断地提供电力的易失性技术,以及包括需要使用可能可移除也可能不可移除的机器可读存储介质的技术。因此,存储器102可包括各种类型(或组合类型)的存储设备中的任何一种,包括但不限于只读存储器(read-only memory,rom)、随机访问存储器(random-access memory,ram)、动态ram(dynamic ram,dram)、双数据速率dram(double-data-rate dram,ddr-dram)、同步dram
(synchronous dram,sdram)、静态ram(static ram,sram)、可编程rom(programmable rom,prom)、可擦除可编程rom(erasable programmable rom,eprom)、电可擦除可编程rom(electrically erasable programmable rom,eeprom)、闪速存储器、聚合物存储器(例如,铁电聚合物存储器)、奥氏存储器、相变或铁电存储器、硅-氧化物-氮化物-氧化物-硅(silicon-oxide-nitride-oxide-silicon,sonos)存储器、磁卡或光卡、一个或多个个体铁磁盘驱动器、或者被组织成一个或多个阵列的多个存储设备(例如,被组织成独立盘冗余阵列阵列或者raid阵列的多个铁磁盘驱动器)。应当注意,虽然存储器102被描绘为单个块,但存储器102可包括多个存储设备,这些存储设备可以基于不同的存储技术。因此,例如,存储器102可以表示以下各项的组合:光驱或闪存卡读取器,通过它可以在某种形式的机器可读存储介质上存储和运送程序和/或数据;铁磁盘驱动器,来将程序和/或数据在本地存储相对较长的时间;以及一个或多个易失性固态存储器设备,使得能够相对快速地访问程序和/或数据(例如,sram或dram)。还应当注意,存储器102可以由多个基于相同存储技术的存储组件组成,但由于使用中的特殊性,这些组件可以被分开维护(例如,一些dram设备被用作主存储,而其他dram设备被用作图形控制器的独特帧缓冲器)。
17.如图所示,存储器102包括一个或多个参数化结构策略网络103,一个或多个二元神经网络104,以及训练数据105的数据存储。尽管被描绘为驻留在存储器102中,但策略网络103、二元神经网络(bnn)104和/或训练数据105可被实现为硬件、软件、和/或硬件和软件的组合。此外,当至少部分体现为软件时,策略网络103、二元神经网络104、和/或训练数据105可被存储在耦合到计算系统100的其他类型的存储装置中。
18.一般来说,策略网络103被配置为对可使用利用强化学习的四阶段训练阶段来训练的以后验分布为条件的一个或多个bnn 104提供二元权重值(例如,1比特值,例如
“‑
1”和/或“1”)。策略网络103可以提供一个或多个权重共享设计。权重共享设计可包括由神经网络核所共享的权重,由神经网络滤波器所共享的权重,以及由神经网络层所共享的权重。例如,当权重由神经网络的各层所共享时,层中的给定参数的每个权重是从单个后验分布中采样的。在这样的示例中,如果网络的一层包括100个参数,那么该层的100个参数中的每一个的权重值都是从该层的单个后验分布(例如,基于后验分布函数生成)中采样的。此外,如果在神经网络中存在5个层,在层共享设计中可能存在5个后验分布(例如,每个层有1个后验分布)。在滤波器共享中,神经网络的给定滤波器的参数的权重值是从该滤波器的后验分布中采样的,其中神经网络中的每个滤波器与各自的后验分布相关联。在核共享中,神经网络的给定核的参数的权重值是从该核的后验分布中采样的,其中神经网络中的每个核与各自的后验分布相关联。这样做减少了训练二元神经网络所要求的分布的数目。
19.一旦经过训练,则二元神经网络104中的一个或多个的二元权重值就可被策略网络103采样。bnn 104代表了对于权重和/或激活使用二元(例如,1比特)值的神经网络。在一个实施例中,bnn 104的权重和/或激活值被强制为
“‑
1”和/或“1”的值。示例神经网络包括但不限于深度神经网络(deep neural network,dnn),例如卷积神经网络(convolutional neural network,cnn)、递归神经网络(recurrent neural network,rnn),等等。神经网络一般实现动态编程,以确定和解决近似值函数。神经网络是由多层非线性处理单元的级联形成的,用于特征提取和变换。一般来说,神经网络的每个后续层都使用来自先前层的输出作为输入。神经网络一般可包括输入层、输出层和多个隐藏层。在一些实施例中,策略网络
103包括输入层、多个隐藏层和输出层。神经网络的隐藏层可包括卷积层、汇聚层、完全连接层、softmax层、和/或归一化层。在一个实施例中,多个隐藏层包括三个隐藏层(例如,隐藏层的计数包括三个隐藏层)。在一些实施例中,策略网络103的各层的神经元不是完全连接的。相反,在这样的实施例中,每一层的神经元的输入和/或输出连接可以被分离成组,其中每个组是完全连接的。
20.一般来说,神经网络包括两个处理阶段,即训练阶段和推断阶段。在训练过程期间,深度学习专家通常会构建网络,确立网络中的层数、每层执行的操作、以及层与层之间的连接。许多层具有参数,这些参数可以被称为权重,其确定了该层所执行的确切计算。训练过程的目的是学习权重,通常是经由基于随机梯度下降的权重空间的游走来进行的。一旦训练过程完成,基于经训练的神经网络的推断(例如,图像分析、图像和/或视频编码、图像和/或视频解码、脸部检测、字符识别、语音识别,等等)通常采用输入数据的前向传播计算来生成输出数据。
21.图2是更详细图示出系统100的组件的示意图200。更具体地说,图2描绘了示例策略网络103和示例二元神经网络104的组件。如前所述,二元神经网络104可以被配置为执行任何数目和类型的识别任务。在此使用图像识别作为示例识别任务,这不应被认为是对本公开的限制。在这样的图像识别示例中,训练数据105可包括多个标记的图像。例如,训练数据105中描绘猫的图像可被标记有指示出该图像描绘猫的标签,而训练数据105中描绘人类的另一图像可被标记有指示出该图像描绘人类的标签。
22.如图2所示,bnn 104包括层213-216,其中包括两个隐藏层214-215。虽然描绘了bnn 104的两个隐藏层,但bnn 104可具有任何数目的隐藏层。一般来说,bnn 104的层213-216的权重可以被强制为
“‑
1”或“1”的值。然而,如图所示,隐藏层213-214的权重是从策略网络103中采样的。
23.就本文使用的而言,bnn 104的体系结构可以由“f”表示,并且目标训练数据105可以被表示为“d(x,y)”,其中x对应于训练数据105中的一个或多个图像,y对应于应用到图像的标签。bnn 104的二元权重可被称为“w”,并且可以从由p(w|x,y)定义的后验分布函数中采样。在一些实施例中,w可以以策略网络103的参数θ为条件,如以下公式1所定义:
24.p(w|x,y)=p
θ
(w)
ꢀꢀꢀꢀ
公式1
25.在公式1中,“w”对应于bnn 104的权重。因此,本文公开的实施例可以用以θ为条件的p(w|θ)来用公式表示并近似后验分布p(w|x,y),而不要求任何先验公式(例如,可以使用伯努利分布来随机生成θ的初始值)。一旦估计出后验分布p(w|x,y),就可以由bnn 104的一个或多个实例来采样后验分布p(w|x,y)的二元值。换句话说,后验分布的函数可以向bnn 104返回二元值p(w|x,y)。
26.如图2所示,状态“s”是策略网络103的输入层201的输入。状态“s”可以是策略网络103的当前状态(包括任何权重、后验分布和/或θ值)。策略网络103进一步包括隐藏层202-204和输出层205。策略网络103的参数一般可包括一个或多个θ值和隐藏层202-204的权重(为清晰起见,没有画出每一者)。在一些实施例中,隐藏层202-204的θ值和/或权重不是二元值,而可以是全精度值(例如,fp32值)。示例性地,一个或多个二元权重206、二元权重的一个或多个核207以及二元权重的一个或多个滤波器208可以被bnn 104采样。如图所示,策略网络103的各层之间的连接提供二元层共享参数209、二元滤波器共享参数210、二元核共
享参数211、以及二元权重特定参数212。如图所示,策略网络103的层201-205不是完全连接的(例如,给定层的每个神经元并没有连接到下一层的每个神经元)。
27.如前所述,策略网络103可以为可由给定bnn 104采样的二元值提供依权重而定的共享、核共享、滤波器共享、以及层共享设计。可以在训练之前知道bnn 104的体系结构(例如,如何在层级拓扑结构中堆叠bnn 104的参数)。一般来说,神经网络的每一层可具有一个或多个滤波器,每个滤波器可具有一个或多个核,并且每个核可具有一个或多个权重。在权重特定共享中,给定bnn 104的每个权重206(例如,参数的二元值)是从以各自的θ值为条件的策略网络103的各个后验分布(例如,权重共享参数212)中采样的。因此,例如,对于包括500个参数的神经网络,策略网络103可包括以各自的θ值为条件的500个分布(例如,以不同的θ值为条件的500个分布)。因此,例如,图2中最右边的核207中的每个参数的二元值可以以最右边的核207的后验分布为条件,而该后验分布以θ值为条件。在核共享中,bnn 104的给定核的二元权重值是从策略网络103(例如,一个或多个核207)中的后验分布(例如,核共享参数211)中采样的。在滤波器共享中,bnn 104的给定滤波器的二元权重值是从策略网络103中的滤波器(例如,滤波器208中的一个或多个)的后验分布(例如,滤波器共享参数210)中采样的。因此,例如,图2中最左边的滤波器208中的每个参数的二元值可以以策略网络中的最左边的滤波器208的后验分布为条件,而该后验分布以θ值为条件。在层共享中,bnn 104的层(例如,层214-215)中的每个参数的二元权重值是从策略网络103中的该层的后验分布中采样的,该后验分布以θ值为条件。因此,例如,bnn 104的层214中的每个参数可以从策略网络103中以θ值为条件的该层的后验分布中采样。类似地,bnn 104的层215的值可以从策略网络103中的该层的以各自的θ值为条件的后验分布中采样。
28.一般来说,由“f”表示的bnn 104可具有“l”层。在这样的示例中,对于由l索引的卷积层,1≤l≤l,二元权重集是o
×i×k×
k张量,其中o是输出通道数,i是输入通道数,并且k是空间核大小。继续这个示例,每一组k
×
k权重可以被称为核,每一组i
×k×
k权重可以被称为滤波器,并且每一组o
×i×k×
k权重可以被称为层。通过将核中的每一个权重视为单个维度,给定的权重可以被索引为w
liok
,其中1≤l≤l,1≤i≤i,1≤o≤o,并且1≤k≤k2。
29.策略网络103提供用于使用共享参数209-212来确定θ值的策略网络。如前所述,策略网络103的输入是状态“s”,它可以对应于策略网络103的二元权重值的当前状态。隐藏层202可被称为h1,隐藏层203可被称为h2,并且隐藏层204可被称为h3。层共享参数209可被称为θ
1l
,滤波器共享参数210可被称为θ
2li
,核共享参数211可被称为θ
3lio
,并且权重特定参数212可被称为θ
4liok
。
30.图3是描绘四阶段训练过程的示意图300。更具体而言,训练可包括至少训练策略网络103中的θ值,然后其可用于为一个或多个bnn 104采样二元权重。如图所示,输入/输出阶段301定义训练数据105的一个或多个图像,作为对bnn 104的输入层213的输入。如前所述,策略网络103可被采样以提供bnn 104的二元权重。然而,策略网络103可以以由各自的θ值定义的一个或多个后验分布为条件。在执行共享的实施例中,共享权重是以具有各自的θ值的后验分布(例如,对于层、滤波器和/或核)为条件的。图3中描绘的训练阶段302包括第一前向阶段303、第二前向阶段304、第一后向阶段305、以及第二后向阶段306。
31.在第一前向阶段303中,bnn 104的二元权重值是从策略网络103的当前后验分布p(w|θ)中采样的。通过将f(*;θ)表示为概率采样过程,用于逐层共享的值(例如,层共享
参数209)可以从由以下公式2定义的后验分布中采样:
[0032][0033]
因此,如公式2所示,层共享参数是至少部分以策略网络103的状态“s”和θ为条件的。为了采样层共享参数209的值,bnn 104和/或策略网络103可以应用公式2。如前所述,公式2所定义的各个后验分布可被应用于策略网络103中的每一层。逐滤波器共享参数(例如,滤波器共享参数210)可以从由以下公式3定义的后验分布中采样。
[0034][0035]
如公式3中所示,滤波器共享参数210是至少部分以层共享参数209为条件的。为了采样滤波器共享参数210的值,bnn 104和/或策略网络103可以应用公式3。如前所述,公式3所定义的各个后验分布可被应用于策略网络103中的每个滤波器。逐核共享(例如,核共享参数211)可以从由以下公式4定义的后验分布中采样。
[0036][0037]
如公式4中所示,核共享参数211是至少部分以滤波器共享参数210为条件的。为了采样核共享参数211的值,bnn 104和/或策略网络103可以应用公式4。如前所述,公式4所定义的各个后验分布可被应用于策略网络103中的每个核。公式5可对应于权重特定概率输出p
liok
:
[0038][0039]
在公式5中,p
liok
的值是表征策略的权重特定概率输出。下面的公式6可被用于计算在第一前向阶段303中返回到bnn 104的采样权重。
[0040][0041]
按照公式2-6中的策略,在第一前向阶段303中执行二元权重采样,以生成由不同的共享设计所连接的不同二元权重。为了说明参数共享机制,两个示例权重w
liok1
和w
liok2
可以驻留在同一个核中(例如,图2中描绘的核207之一)。这些权重w
liok1
和w
liok2
可以根据p
liok1
和p
liok2
来采样,其中p
liok1
和p
liok2
是根据以下的公式7和8来计算的。
[0042][0043][0044]
因此,如公式7和8中所示,采样的权重值包括层共享参数209、滤波器共享参数210和核共享参数211之间的依赖性。当从策略网络103采样二元权重值时,这种依赖性可被传授给bnn 104。
[0045]
在第二前向训练阶段304中,由bnn 104使用被表示为x的一批训练数据105(例如,从训练数据105中选择的一个或多个图像)来执行前向传播。换句话说,在第二前向阶段304中,bnn 104分析来自训练数据105的一个或多个图像以产生输出。该输出可反映bnn 104对训练图像中所描绘的内容(例如,人类、狗、猫、字符“e”、字符“2”,等等)的预测。此输出可被表示为y
*
,其中y被表示为图像的标签(例如,指示出在训练图像中描绘了一只猫的标签)。因为bnn 104可能未生成正确的输出(例如,确定猫的图像描绘的是狗),所以可以基于第二
前向阶段304确定误差。误差(或者交叉熵度量)可以被定义为δ(y
*
,y),其中δ是损失函数。
[0046]
在第一后向阶段305中,相对于在第一前向阶段303中采样的二元权重值计算一个或多个梯度在第二后向阶段306中,策略网络103的θ值被更新。然而,由于不能被琐碎地评估,所以本文公开的实施例使用强化学习算法来更新策略网络103的θ值,该算法提供被表示为的伪奖励值r。在一个实施例中,可以使用以下公式9-10来计算奖励值r。
[0047][0048][0049]
在公式10中,β是用于计算奖励值r
liok
的缩放因子。因此,奖励值r
liok
是基于当前权重的梯度、当前权重和缩放因子的。在一个实施例中,更新θ的值的强化算法是基于以下公式11的:
[0050][0051]
一般来说,公式11可计算期望奖励值。在一个实施例中,可以应用根据公式12的无偏估计量作为强化算法的一部分:
[0052][0053]
一旦策略网络103的θ参数被更新,采样的权重就被丢弃,并且使用策略网络103的更新后的θ参数来重新采样。使用策略网络103的更新后的θ参数可允许bnn 104在运行时操作中提高准确性。图3中描绘的四阶段训练一般可被重复任意次数。
[0054]
图4图示了逻辑流程400的实施例。逻辑流程400可代表本文描述的一个或多个实施例所执行的一些或所有操作。例如,逻辑流程400可代表为参数化二元神经网络提供自动机器学习策略网络的一些或所有操作。实施例不限于此情境中。
[0055]
如图所示,在块410,一个或多个二元神经网络104的权重被限制为二元值。例如,每个bnn 104的权重可以是
“‑
1”或“1”的值。每个bnn 104的激活权重可以进一步被限制为二元值。此外,可以接收bnn 104的体系结构(例如,层级模型)作为输入。在块420,二元神经网络104的权重被配置为被从策略网络103采样。策略网络103可包括多个后验分布的theta(θ)值。在块430,可以使用上文描述和下文参考图5描述的四阶段训练过程来训练策略网络103和/或(一个或多个)bnn 104。在块440,一个或多个二元神经网络104可被用于执行一个或多个运行时操作。例如,二元神经网络104可以使用从策略网络103采样的二元权重来进行图像处理(例如,识别图像中的对象)、语音处理、信号处理,等等。
[0056]
图5图示了逻辑流程500的实施例。逻辑流程500可代表本文描述的一个或多个实施例所执行的一些或所有操作。例如,逻辑流程500可被实现来训练策略网络103。实施例不限于此情境中。
[0057]
如图所示,在块510,可以在第一前向训练阶段中从策略网络103采样二元权重值。如前所述,根据以一个或多个θ值为条件的后验分布来采样权重值。二元权重值可包括权重特定的二元值、核共享的二元值、滤波器共享的二元值、以及层共享的二元值。因此,例如,用于bnn 104的一个或多个层的权重值可以是从由策略网络103提供的逐层共享结构中采样的。在块520,接收一批或多批训练数据105。训练数据105可以是被标记的,例如,标记的图像、标记的语音样本,等等。在块530,使用在块510处采样的权重值和在块520处接收的训练数据来执行第二前向训练阶段。一般来说,在第二前向训练阶段中,二元神经网络104处理训练数据以基于从策略网络103采样的权重来生成输出。例如,如果训练数据105包括图像,则二元神经网络104可以使用在块510处采样的权重来处理图像,并且输出可对应于二元神经网络104认为在每个训练图像中描绘的对象(例如,车辆、人、猫,等等)。这样做允许了二元神经网络104在块540处确定误差。一般来说,二元神经网络104基于在块530处为每个训练图像生成的输出和被应用于每个训练图像的标签来确定误差。例如,如果训练图像描绘的是一只猫,而二元神经网络104返回的输出表明图像中描绘的是一只狗,则基于损失函数来计算出误差的程度。
[0058]
在块550,在第一后向训练阶段中,二元神经网络104经由二元神经网络104的后向传播为在块510处采样的每个权重值计算一个或多个梯度。在一个实施例中,二元神经网络104应用上述公式9来计算每个梯度。在块560,计算一个或多个奖励值,以在第二后向训练阶段中更新策略网络103的θ值。在一个实施例中,二元神经网络104应用上述公式10来计算每个奖励值。此外,策略网络103的隐藏层的权重可以被更新。在块570,在块560计算的值被用于更新θ值和/或策略网络103的隐藏层的权重。如前所述,θ值可包括用于策略网络103的一个或多个权重的后验分布的θ值,用于策略网络103的一个或多个层的后验分布的θ值,用于策略网络103的一个或多个滤波器的后验分布的θ值,以及用于策略网络103的一个或多个核的后验分布的θ值。
[0059]
图6图示了逻辑流程600的实施例。逻辑流程600可代表本文描述的一个或多个实施例所执行的一些或所有操作。例如,可以实现逻辑流程600的一些或所有操作来在策略网络103中提供不同的共享机制。实施例不限于此情境中。
[0060]
如图所示,在块610,权重特定的共享策略可被策略网络103应用。在这样的示例中,策略网络103可以为策略网络103和/或给定bnn 104的每个参数提供后验分布。每个参数的后验分布可以以各自的θ值为条件。在块620,核共享策略可被策略网络103应用。在这样的示例中,策略网络103可以为策略网络103和/或给定bnn 104的每个核提供后验分布,其中每个核的后验分布是以各自的θ值为条件的。在块630,滤波器共享策略可被策略网络103和/或给定bnn 104应用。在这样的示例中,策略网络103可以为策略网络103和/或给定bnn 104的每个滤波器提供后验分布,其中每个滤波器的后验分布是以各自的θ值为条件的。在块640,层共享策略可被策略网络103应用。在这样的示例中,策略网络103可以为策略网络103和/或给定bnn 104的每个层提供后验分布,其中每个核的后验分布以各自的θ值为条件。
[0061]
图7图示了存储介质700的实施例。存储介质700可包括任何非暂态计算机可读存储介质或者机器可读存储介质,例如光存储介质、磁存储介质或者半导体存储介质。在各种实施例中,存储介质700可包括制品。在一些实施例中,存储介质700可存储计算机可执行指
令,例如实现本文描述的逻辑流程或操作中的一个或多个的计算机可执行指令,例如分别用于关于图4-图6的逻辑流程400、500、600的指令701、702、703。存储介质700还可存储用于策略网络103(及其组件)的计算机可执行指令705、用于二元神经网络104(及其组件)的指令706、以及用于上文描述的公式1-12的指令704。此外,用于策略网络103、二元神经网络104和公式1-12的计算机可执行指令可包括用于从以各自的θ值为条件的一个或多个后验分布生成和/或采样的指令。计算机可读存储介质或机器可读存储介质的示例可包括能够存储电子数据的任何有形介质,包括易失性存储器或非易失性存储器、可移除或不可移除的存储器、可擦除或不可擦除的存储器、可写或者可改写的存储器,等等。计算机可执行指令的示例可包括任何适当类型的代码,例如源代码、编译的代码、解释的代码,可执行代码、静态代码、动态代码,面向对象的代码、视觉代码,等等。实施例不限于此情境中。
[0062]
图8图示了可适合用于实现如前所述的各种实施例的示范性计算体系结构800的实施例。在各种实施例中,计算体系结构800可包括电子设备或者可被实现为电子设备的一部分。在一些实施例中,计算体系结构800可代表例如实现系统100的一个或多个组件的计算机系统。实施例不限于此情境中。更概括而言,计算体系结构800被配置为实现本文参考图1-图7描述的所有逻辑、系统、逻辑流程、方法、装置和功能。
[0063]
如在本技术中使用的,术语“系统”和“组件”和“模块”意在指计算机相关实体,或者是硬件、硬件和软件的组合、软件或者是执行中的软件,其示例由示范性计算体系结构800提供。例如,组件可以是但不限于是处理器上运行的进程、处理器、硬盘驱动器、(光存储介质和/或磁存储介质的)多个存储设备、对象、可执行文件、执行的线程、程序、和/或计算机。作为示例,在服务器上运行的应用和服务器都可以是组件。一个或多个组件可驻留在进程和/或执行的线程内,并且组件可位于一个计算机上和/或分布在两个或多个计算机之间。另外,组件可通过各种类型的通信介质通信地耦合到彼此以协调操作。协调可涉及信息的单向或双向交换。例如,组件可以以通过通信介质传输的信号的形式来传输信息。信息可被实现为分配到各种信号线的信号。在这种分配中,每个消息是信号。然而,另外的实施例可替换为采用数据消息。可在各种连接上发送这种数据消息。示范性连接包括并行接口、串行接口和总线接口。
[0064]
计算体系结构800包括各种常见的计算元件,例如一个或多个处理器、多核处理器、协处理器、存储器单元、芯片组、控制器、外设、接口、振荡器、定时设备、视频卡、音频卡、多媒体输入/输出(i/o)组件、供电电源,等等。然而,实施例不限于由计算体系结构800的实现方式。
[0065]
如图8所示,计算体系结构800包括处理单元804、系统存储器806、以及系统总线808。处理单元804(也称为处理器电路)可以是各种市售处理器中的任何一种,包括但不限于和处理器;应用、嵌入式和安全处理器;和和处理器;ibm和cell处理器;core(2)和处理器;以及类似的处理器。双微处理器、多核处理器和其他多处理器体系结构也可被用作处理单元804。
[0066]
系统总线808为包括但不限于系统存储器806到处理单元804的系统组件提供接
口。系统总线808可以是若干种类型的总线结构中的任何一种,其可进一步利用各种市售的总线体系结构中的任何一种互连到存储器总线(有或者没有存储器控制器)、外围总线和本地总线。接口适配器可经由插槽体系结构连接到系统总线808。示例插槽体系结构可包括但不限于加速图形端口(accelerated graphics port,agp)、卡总线、(扩展)工业标准体系结构((extended)industry standard architecture,(e)isa)、微信道体系结构(micro channel architecture,mca)、nubus、外围组件互连(扩展)(peripheral component interconnect(extended),pci(x))、pci快速、个人计算机存储卡国际联盟(personal computer memory card international association,pcmcia),等等。
[0067]
系统存储器806可包括采取一个或多个更高速存储器单元的形式的各种类型的计算机可读存储介质,例如只读存储器(read-only memory,rom),随机访问存储器(random-access memory,ram),动态ram(dynamic ram,dram),双数据速率dram(double-data-rate dram,ddram),同步dram(synchronous dram,sdram),大容量字节可寻址持久性存储器(bulk byte-addressable persistent memory,pmem),静态ram(static ram,sram),可编程rom(programmable rom,prom),可擦除可编程rom(erasable programmable rom,eprom),电可擦除可编程rom(electrically erasable programmable rom,eeprom),闪速存储器(例如,一个或多个闪存阵列),聚合物存储器,例如铁电聚合物存储器,奥氏存储器,相变或铁电存储器,硅-氧化物-氮化物-氧化物-硅(silicon-oxide-nitride-oxide-silicon,sonos)存储器,磁卡或光卡,例如独立盘冗余阵列(redundant array of independent disks,raid)驱动器之类的设备的阵列,固态存储器设备(例如,usb存储器、固态驱动器(solid state drive,ssd)),以及适用于存储信息的任何其他类型的存储介质。在图8所示的图示实施例中,系统存储器806可包括非易失性存储器810和/或易失性存储器812。基本输入/输出系统(basic input/output system,bios)可被存储在非易失性存储器810中。
[0068]
计算机802可包括采取一个或多个更低速存储器单元的形式的各种类型的计算机可读存储介质,包括内部(或外部)硬盘驱动器(hard disk drive,hdd)814,用于从可移除磁盘818读取或者向其写入的磁软盘驱动器(floppy disk drive,fdd)816,以及用于从可移除光盘822(例如,致密盘只读存储器(compact disc read-only memory,cd-rom)或数字多功能盘(digital versatile disc,dvd))读取或者向其写入的光盘驱动器820。hdd 814、fdd 816和光盘驱动器820可分别通过hdd接口824、fdd接口826和光驱动器接口828连接到系统总线808。用于外部驱动器实现方式的hdd接口824可包括通用串行总线(sb)和ieee 1394接口技术中的至少一者或两者。
[0069]
驱动器和关联的计算机可读介质提供数据、数据结构、计算机可执行指令等等的易失性和/或非易失性存储。例如,若干程序模块可被存储在驱动器和存储器单元810、812中,包括操作系统830、一个或多个应用程序832、其他程序模块834和程序数据836。在一个实施例中,一个或多个应用程序832、其他程序模块834和程序数据836可包括例如系统100的各种应用和/或组件,包括(一个或多个)策略网络103、(一个或多个)二元神经网络104、训练数据105、和/或本文描述的其他逻辑。
[0070]
用户可通过一个或多个有线/无线输入设备(例如键盘838)以及指点设备(例如鼠标840)来将命令和信息输入到计算机802中。其他输入设备可包括麦克风、红外(ir)遥控
器、射频(rf)遥控器、游戏板、触控笔、读卡器、电子狗、指纹读取器、手套、绘图板、操纵杆、键盘、视网膜读取器、触摸屏(例如,电容式、电阻式,等等)、轨迹球、触控板、传感器、触笔,等等。这些和其他输入设备经常通过耦合到系统总线808的输入设备接口842连接到处理单元804,但可通过其他接口连接,例如并行端口、ieee 1394串行端口、游戏端口、usb端口、ir接口,等等。
[0071]
监视器844或其他类型的显示设备也经由诸如视频适配器846之类的接口连接到系统总线808。监视器844可在计算机802内部或外部。除了监视器844以外,计算机通常还包括其他外围输出设备,例如扬声器、打印机,等等。
[0072]
计算机802可利用经由有线和/或无线通信到诸如远程计算机848之类的一个或多个远程计算机的逻辑连接来在联网环境中操作。在各种实施例中,一个或多个迁移可经由联网的环境发生。远程计算机848可以是工作站、服务器计算机、路由器、个人计算机、便携式计算机、基于微处理器的娱乐家电、对等设备或者其他常见的网络节点,并且通常包括相对于计算机802描述的许多或所有元素,但为了简明起见,只图示了存储器/存储设备850。描绘的逻辑连接包括到局域网(local area network,lan)852和/或例如广域网(wide area network,wan)854之类的更大网络的有线/无线连通性。这种lan和wan联网环境在办公室和公司中是常见的,并且促进了整个企业内的计算机网络,例如内联网,所有这些都可连接到全球通信网络,例如互联网。
[0073]
当在lan联网环境中使用时,计算机802通过有线和/或无线通信网络接口或适配器856连接到lan 852。适配器856可促进到lan 852的有线和/或无线通信,lan 852也可包括布置在其上的无线接入点来与适配器856的无线功能通信。
[0074]
当在wan联网环境中使用时,计算机802可包括调制解调器858,或者连接到wan 854上的通信服务器,或者具有用于通过wan 854建立通信的其他手段,例如通过互联网。可在内部或外部并且可以是有线和/或无线设备的调制解调器858经由输入设备接口842连接到系统总线808。在联网的环境中,相对于计算机802描绘的程序模块或者其一些部分可被存储在远程存储器/存储设备850中。将会明白,示出的网络连接是示范性的,并且在计算机之间建立通信链路的其他手段可被使用。
[0075]
计算机802可操作来利用ieee 802标准族与有线和无线设备或实体进行通信,例如操作性地布置在无线通信中的无线设备(例如,ieee 802.16空中调制技术)。这至少包括wi-fi(或者无线保真)、wimax和bluetooth
tm
无线技术,等等。因此,通信可以是像传统网络那样的预定结构、或者简单地是至少两个设备之间的自组织通信。wi-fi网络使用被称为ieee 802.11x(a、b、g、n、ac、ay,等等)的无线电技术来提供安全、可靠、快速的无线连通性。wi-fi网络可用于将计算机连接到彼此,连接到互联网,以及连接到有线网络(有线网络使用ieee 802.3相关介质和功能)。
[0076]
至少一个示例的一个或多个方面可由存储在至少一个机器可读介质上的表示处理器内的各种逻辑的代表性指令来实现,这些指令当被机器、计算设备或系统读取时,使得该机器、计算设备或系统制作逻辑来执行本文描述的技术。这种被称为“ip核心”的表现形式可被存储在有形机器可读介质上并且被提供到各种客户或制造设施以加载到制作该逻辑或处理器的制作机器中。
[0077]
可以利用硬件元素、软件元素或者两者的组合来实现各种示例。在一些示例中,硬
件元素的示例可包括设备、组件、处理器、微处理器、电路、电路元件(例如,晶体管、电阻器、电容器、电感器,等等)、集成电路、专用集成电路(application specific integrated circuit,asic)、可编程逻辑器件(programmable logic device,pld)、数字信号处理器(digital signal processor,dsp)、现场可编程门阵列(field programmable gate array,fpga)、存储器单元、逻辑门、寄存器、半导体器件、芯片、微芯片、芯片组,等等。在一些示例中,软件元素可包括软件组件、程序、应用、计算机程序、应用程序、系统程序、机器程序、操作系统软件、中间件、固件、软件模块、例程、子例程、函数、方法、过程、软件接口、应用程序接口(application program interface,api)、指令集、计算代码、计算机代码、代码段、计算机代码段、字、值、符号,或者这些的任何组合。确定示例是否利用硬件元素和/或软件元素来实现可按照给定的实现方式所期望的根据任何数目的因素而变化,例如期望的计算速率、功率水平、耐热性、处理周期预算、输入数据速率、输出数据速率、存储器资源、数据总线速度以及其他设计或性能约束。
[0078]
一些示例可包括制品或者至少一个计算机可读介质。计算机可读介质可包括非暂态存储介质来存储逻辑。在一些示例中,非暂态存储介质可包括一种或多种类型的能够存储电子数据的计算机可读存储介质,包括易失性存储器或非易失性存储器、可移除或不可移除存储器、可擦除或不可擦除存储器、可写或可改写存储器,等等。在一些示例中,逻辑可包括各种软件元素,例如软件组件、程序、应用、计算机程序、应用程序、系统程序、机器程序、操作系统软件、中间件、固件、软件模块、例程、子例程、函数、方法、过程、软件接口、api、指令集、计算代码、计算机代码、代码段、计算机代码段、字、值、符号,或者这些的任何组合。
[0079]
根据一些示例,计算机可读介质可包括非暂态存储介质来存储或维护指令,这些指令当被机器、计算设备或系统执行时,使得该机器、计算设备或系统执行根据描述的示例的方法和/或操作。指令可包括任何适当类型的代码,例如源代码、编译代码、解释代码、可执行代码、静态代码、动态代码,等等。可根据预定的计算机语言、方式或语法来实现指令,用于指示机器、计算设备或系统执行特定的功能。可利用任何适当的高级别、低级别、面向对象、视觉、编译和/或解释编程语言来实现指令。
[0080]
可利用表述“在一个示例中”或者“示例”以及其衍生词来描述一些示例。这些术语的意思是联系该示例描述的特定特征、结构或特性被包括在至少一个示例中。在本说明书中各种地方出现短语“在一个示例中”不一定都指的是同一示例。
[0081]
可利用表述“耦合”和“连接”以及其衍生词来描述一些示例。这些术语并不一定意图是彼此的同义词。例如,使用术语“连接”和/或“耦合”的描述可指示出两个或更多个元素彼此发生直接物理或电气接触。然而,术语“耦合”也可以指两个或更多个元素没有彼此发生直接接触,然而仍彼此合作或交互。
[0082]
以下示例涉及进一步实施例,许多置换和配置将从这些实施例中清楚显现。
[0083]
示例1是一种装置,包括处理器电路,以及存储指令的存储器,所述指令当被所述处理器电路执行时使得所述处理器电路:接收从策略神经网络采样的二元神经网络的多个二元权重值,所述策略神经网络包括以θ值为条件的后验分布;基于训练数据和接收到的多个二元权重值确定所述二元神经网络的前向传播的误差;基于所述二元神经网络的后向传播来为所述多个二元权重值计算各自的梯度值;并且利用基于所述梯度值、所述多个二元权重值以及缩放因子计算的奖励值来更新所述策略神经网络的后验分布的θ值。
[0084]
示例2包括如示例1所述的主题,其中所述后验分布被以下各项中的一个或多个所共享:所述策略神经网络的层,所述策略神经网络的滤波器,所述策略神经网络的核,以及所述策略神经网络的权重。
[0085]
示例3包括如示例1所述的主题,其中所述策略神经网络包括多个后验分布,其中每个后验分布是以各自的θ值为条件的,其中所述二元神经网络的第一核的二元权重值是从所述多个后验分布中的以第一θ值为条件的第一后验分布采样的,其中所述二元神经网络的第一滤波器的二元权重值是从所述多个后验分布中的以第二θ值为条件的第二后验分布采样的,其中所述二元神经网络的第一层的二元权重值是从所述多个后验分布中的以第三θ值为条件的第三后验分布采样的。
[0086]
示例4包括如示例3所述的主题,其中所述策略神经网络的第一层的二元权重值是根据以下公式从所述多个后验分布中的所述第一后验分布采样的:
[0087]
示例5包括如示例4所述的主题,其中所述策略神经网络的第一滤波器的二元权重值是根据以下公式从所述多个后验分布中的所述第二后验分布采样的:
[0088]
示例6包括如示例5所述的主题,其中所述策略神经网络的第一核的二元权重值是根据以下公式从所述多个后验分布中的所述第三后验分布采样的:
[0089]
示例7包括如示例6所述的主题,其中所述二元权重值包括根据以下公式确定的权重特定概率输出:
[0090]
示例8包括如示例7所述的主题,其中所述二元权重值是基于以下公式来采样的:
[0091][0092][0093]
示例9包括如示例1所述的主题,其中所述策略网络包括三个隐藏层,其中所述策略网络的三个隐藏层不是完全连接层,其中所述三个隐藏层中的每个隐藏层包括一组或多组神经元。
[0094]
示例10包括如示例1所述的主题,所述存储器存储指令,所述指令当被所述处理器电路执行时使得所述处理器电路:基于被应用到由所述二元神经网络针对所述训练数据生成的输出的损失函数和被应用到所述训练数据的标签来确定所述二元神经网络的前向传播的误差。
[0095]
示例11包括如示例1所述的主题,所述存储器存储指令,所述指令当被所述处理器电路执行时使得所述处理器电路:基于所述梯度值、所述多个二元权重值和所述缩放因子来计算所述奖励值;并且利用强化算法和计算出的奖励值来更新所述θ值,其中所述梯度值是根据以下公式计算的:其中所述奖励值是基于以下公式计算的:其中所述奖励值是基于以下公式计算的:其中所述强化算法是基于期望奖励的,所述
期望奖励是基于以下公式计算的:其中所述强化算法是基于无偏估计量的,所述无偏估计量是基于以下公式的:
[0096]
示例12包括如示例1所述的主题,其中所述策略神经网络的输入层接收所述θ值的初始状态作为输入,其中相应的多个二元权重值是针对所述二元神经网络的多个层中的每一层从所述策略神经网络采样的。
[0097]
示例13是一种非暂态计算机可读存储介质,包括指令,所述指令当被计算设备的处理器执行时,使得所述处理器:接收从策略神经网络采样的二元神经网络的多个二元权重值,所述策略神经网络包括以θ值为条件的后验分布;基于训练数据和接收到的多个二元权重值确定所述二元神经网络的前向传播的误差;基于所述二元神经网络的后向传播来为所述多个二元权重值计算各自的梯度值;并且利用基于所述梯度值、所述多个二元权重值以及缩放因子计算的奖励值来更新所述策略神经网络的后验分布的θ值。
[0098]
示例14包括如示例13所述的主题,其中所述后验分布被以下各项中的一个或多个所共享:所述策略神经网络的层,所述策略神经网络的滤波器,所述策略神经网络的核,以及所述策略神经网络的权重。
[0099]
示例15包括如示例13所述的主题,其中所述策略神经网络包括多个后验分布,其中每个后验分布是以各自的θ值为条件的,其中所述二元神经网络的第一核的二元权重值是从所述多个后验分布中的以第一θ值为条件的第一后验分布采样的,其中所述二元神经网络的第一滤波器的二元权重值是从所述多个后验分布中的以第二θ值为条件的第二后验分布采样的,其中所述二元神经网络的第一层的二元权重值是从所述多个后验分布中的以第三θ值为条件的第三后验分布采样的。
[0100]
示例16包括如示例15所述的主题,其中所述策略神经网络的第一层的二元权重值是根据以下公式从所述多个后验分布中的所述第一后验分布采样的:
[0101]
示例17包括如示例16所述的主题,其中所述策略神经网络的第一滤波器的二元权重值是根据以下公式从所述多个后验分布中的所述第二后验分布采样的:
[0102]
示例18包括如示例17所述的主题,其中所述策略神经网络的第一核的二元权重值是根据以下公式从所述多个后验分布中的所述第三后验分布采样的:
[0103]
示例19包括如示例18所述的主题,其中所述二元权重值包括根据以下公式确定的权重特定概率输出:
[0104]
示例20包括如示例19所述的主题,其中所述二元权重值是基于以下公式来采样的:
[0105]
[0106][0107]
示例21包括如示例13所述的主题,其中所述策略网络包括三个隐藏层,其中所述策略网络的三个隐藏层不是完全连接层,其中所述三个隐藏层中的每个隐藏层包括一组或多组神经元。
[0108]
示例22包括如示例13所述的主题,包括指令,所述指令当被所述处理器电路执行时使得所述处理器电路:基于被应用到由所述二元神经网络针对所述训练数据生成的输出的损失函数和被应用到所述训练数据的标签来确定所述二元神经网络的前向传播的误差。
[0109]
示例23包括如示例13所述的主题,包括指令,所述指令当被所述处理器电路执行时使得所述处理器电路:基于所述梯度值、所述多个二元权重值和所述缩放因子来计算所述奖励值;并且利用强化算法和计算出的奖励值来更新所述θ值,其中所述梯度值是根据以下公式计算的:下公式计算的:其中所述奖励值是基于以下公式计算的:其中所述奖励值是基于以下公式计算的:其中所述强化算法是基于期望奖励的,所述期望奖励是基于以下公式计算的:其中所述强化算法是基于无偏估计量的,所述无偏估计量是基于以下公式的:
[0110]
示例24包括如示例13所述的主题,其中所述策略神经网络的输入层接收所述θ值的初始状态作为输入,其中相应的多个二元权重值是针对所述二元神经网络的多个层中的每一层从所述策略神经网络采样的。
[0111]
示例25包括一种方法,包括:由在计算机处理器上执行的二元神经网络接收从策略神经网络采样的多个二元权重值,所述策略神经网络包括以θ值为条件的后验分布;基于训练数据和接收到的多个二元权重值确定所述二元神经网络的前向传播的误差;基于所述二元神经网络的后向传播来为所述多个二元权重值计算各自的梯度值;并且利用基于所述梯度值、所述多个二元权重值以及缩放因子计算的奖励值来更新所述策略神经网络的后验分布的θ值。
[0112]
示例26包括如示例25所述的主题,其中所述后验分布被以下各项中的一个或多个所共享:所述策略神经网络的层,所述策略神经网络的滤波器,所述策略神经网络的核,以及所述策略神经网络的权重。
[0113]
示例27包括如示例25所述的主题,其中所述策略神经网络包括多个后验分布,其中每个后验分布是以各自的θ值为条件的,其中所述二元神经网络的第一核的二元权重值是从所述多个后验分布中的以第一θ值为条件的第一后验分布采样的,其中所述二元神经网络的第一滤波器的二元权重值是从所述多个后验分布中的以第二θ值为条件的第二后验分布采样的,其中所述二元神经网络的第一层的二元权重值是从所述多个后验分布中的以第三θ值为条件的第三后验分布采样的。
[0114]
示例28包括如示例27所述的主题,其中所述策略神经网络的第一层的二元权重值是根据以下公式从所述多个后验分布中的所述第一后验分布采样的:
[0115]
示例29包括如示例28所述的主题,其中所述策略神经网络的第一滤波器的二元权
重值是根据以下公式从所述多个后验分布中的所述第二后验分布采样的:
[0116]
示例30包括如示例29所述的主题,其中所述策略神经网络的第一核的二元权重值是根据以下公式从所述多个后验分布中的所述第三后验分布采样的:
[0117]
示例31包括如示例30所述的主题,其中所述二元权重值包括根据以下公式确定的权重特定概率输出:
[0118]
示例32包括如示例31所述的主题,其中所述二元权重值是基于以下公式来采样的:
[0119][0120][0121]
示例33包括如示例25所述的主题,其中所述策略网络包括三个隐藏层,其中所述策略网络的三个隐藏层不是完全连接层,其中所述三个隐藏层中的每个隐藏层包括一组或多组神经元。
[0122]
示例34包括如示例25所述的主题,还包括:基于被应用到由所述二元神经网络针对所述训练数据生成的输出的损失函数和被应用到所述训练数据的标签来确定所述二元神经网络的前向传播的误差。
[0123]
示例35包括如示例25所述的主题,还包括:基于所述梯度值、所述多个二元权重值和所述缩放因子来计算所述奖励值;并且利用强化算法和计算出的奖励值来更新所述θ值,其中所述梯度值是根据以下公式计算的:其中所述奖励值是基于以下公式计算的:式计算的:其中所述强化算法是基于期望奖励的,所述期望奖励是基于以下公式计算的:其中所述强化算法是基于无偏估计量的,所述无偏估计量是基于以下公式的:
[0124]
示例36包括如示例25所述的主题,其中所述策略神经网络的输入层接收所述θ值的初始状态作为输入,其中相应的多个二元权重值是针对所述二元神经网络的多个层中的每一层从所述策略神经网络采样的。
[0125]
示例37包括一种装置,包括:用于接收从策略神经网络采样的二元神经网络的多个二元权重值的装置,所述策略神经网络包括以θ值为条件的后验分布;用于基于训练数据和接收到的多个二元权重值确定所述二元神经网络的前向传播的误差的装置;用于基于所述二元神经网络的后向传播来为所述多个二元权重值计算各自的梯度值的装置;以及用于利用基于所述梯度值、所述多个二元权重值以及缩放因子计算的奖励值来更新所述策略神经网络的后验分布的θ值的装置。
[0126]
示例38包括如示例37所述的主题,其中所述后验分布被以下各项中的一个或多个所共享:所述策略神经网络的层,所述策略神经网络的滤波器,所述策略神经网络的核,以及所述策略神经网络的权重。
[0127]
示例39包括如示例37所述的主题,其中所述策略神经网络包括多个后验分布,其中每个后验分布是以各自的θ值为条件的,其中所述二元神经网络的第一核的二元权重值是从所述多个后验分布中的以第一θ值为条件的第一后验分布采样的,其中所述二元神经网络的第一滤波器的二元权重值是从所述多个后验分布中的以第二θ值为条件的第二后验分布采样的,其中所述二元神经网络的第一层的二元权重值是从所述多个后验分布中的以第三θ值为条件的第三后验分布采样的。
[0128]
示例40包括如示例39所述的主题,其中所述策略神经网络的第一层的二元权重值是根据用于执行以下公式的装置从所述多个后验分布中的所述第一后验分布采样的:
[0129]
示例41包括如示例40所述的主题,其中所述策略神经网络的第一滤波器的二元权重值是根据用于执行以下公式的装置从所述多个后验分布中的所述第二后验分布采样的:
[0130]
示例42包括如示例41所述的主题,其中所述策略神经网络的第一核的二元权重值是根据用于执行以下公式的装置从所述多个后验分布中的所述第三后验分布采样的:
[0131]
示例43包括如示例42所述的主题,其中所述二元权重值包括根据用于执行以下公式的装置确定的权重特定概率输出:
[0132]
示例44包括如示例43所述的主题,其中所述二元权重值是基于用于执行以下公式的装置来采样的:
[0133][0134][0135]
示例45包括如示例37所述的主题,其中所述策略网络包括三个隐藏层,其中所述策略网络的三个隐藏层不是完全连接层,其中所述三个隐藏层中的每个隐藏层包括一组或多组神经元。
[0136]
示例46包括如示例37所述的主题,还包括:基于被应用到由所述二元神经网络针对所述训练数据生成的输出的损失函数和被应用到所述训练数据的标签来确定所述二元神经网络的前向传播的误差。
[0137]
示例47包括如示例37所述的主题,还包括:用于基于所述梯度值、所述多个二元权重值和所述缩放因子来计算所述奖励值的装置;以及用于利用强化算法和计算出的奖励值来更新所述θ值的装置,其中所述梯度值是根据以下公式计算的:其中所
述奖励值是基于以下公式计算的:其中所述强化算法是基于期望奖励的,所述期望奖励是基于以下公式计算的:其中所述强化算法是基于无偏估计量的,所述无偏估计量是基于以下公式的:
[0138]
示例48包括如示例37所述的主题,其中所述策略神经网络的输入层接收所述θ值的初始状态作为输入,其中相应的多个二元权重值是针对所述二元神经网络的多个层中的每一层从所述策略神经网络采样的。
[0139]
此外,在前述内容中,各种特征被一起归组在单个示例中以精简公开内容。这种公开方法不应被解释为反映了要求保护的示例要求比每个权利要求中明确记载的更多的特征的意图。更确切地说,如所附权利要求反映的,发明主题存在于单个公开示例的少于全部特征中。因此,在此将所附权利要求并入到“具体实施方式”部分中,其中每个权利要求独立作为一个单独的示例。在所附权利要求中,术语“包括”和“在其中”分别被用作相应术语“包含”和“其中”的简明英语等同物。另外,术语“第一”、“第二”和“第三”等等仅仅被用作标签,而并不意图对其对象施加数值要求。
[0140]
虽然主题是以特定于结构特征和/或方法动作的语言来描述的,但要理解,所附权利要求中限定的主题不一定限于以上描述的具体特征或动作。更确切地说,以上描述的具体特征和动作是作为实现权利要求的示例形式被公开的。
[0141]
适用于存储和/或执行程序代码的数据处理系统将包括通过系统总线直接或间接耦合到存储器元件的至少一个处理器。存储器元件可包括在程序代码的实际执行期间采用的本地存储器、大容量存储装置、以及提供至少一些程序代码的临时存储以减少在执行期间必须从大容量存储装置取回代码的次数的缓存存储器。术语“代码”覆盖了广泛的软件组件和构造,包括应用、驱动器、进程、例程、方法、模块、固件、微代码、以及子程序。从而,术语“代码”可以用来指指令的任何集合,这些指令当被处理系统执行时会执行一个或多个期望的操作。
[0142]
本文描述的逻辑电路、设备和接口可以执行在硬件中实现的和利用在一个或多个处理器上执行的代码实现的功能。逻辑电路指的是实现一个或多个逻辑功能的硬件或者硬件和代码。电路是硬件,并且可以指一个或多个电路。每个电路可执行特定的功能。电路系统的电路可包括用一个或多个导体相互连接的分立电气组件、集成电路、芯片封装、芯片组、存储器,等等。集成电路包括在诸如硅晶片之类的衬底上创建的电路,并且可包括组件。并且集成电路、处理器封装、芯片封装和芯片组可包括一个或多个处理器。
[0143]
处理器可以在(一个或多个)输入处接收信号,例如指令和/或数据,并且处理这些信号以生成至少一个输出。在执行代码时,代码会改变构成处理器管线的晶体管的物理状态和特性。晶体管的物理状态转化为存储在处理器内的寄存器中的一和零的逻辑比特。处理器可以将晶体管的物理状态转移到寄存器中,并且将晶体管的物理状态转移到另一个存储介质。
[0144]
处理器可包括执行一个或多个子功能的电路,这一个或多个子功能被实现来执行处理器的整体功能。处理器的一个示例是包括至少一个输入和至少一个输出的状态机或者专用集成电路(application-specific integrated circuit,asic)。状态机可通过对至少
一个输入执行预定的一系列串行和/或并行操纵或变换,来操纵至少一个输入以生成至少一个输出。
[0145]
如上所述的逻辑可以是用于集成电路芯片的设计的一部分。芯片设计是以图形计算机编程语言创建的,并且被存储在计算机存储介质或数据存储介质中(例如盘、磁带、物理硬盘、或者虚拟硬盘,例如存储在存储访问网络中)。如果设计者未制作芯片或者用于制作芯片的光刻掩模,则设计者通过物理手段(例如,通过提供存储设计的存储介质的拷贝)或者电子方式(例如,通过互联网)直接或间接地将所得到的设计传输给这些实体。存储的设计随后被转换为适当的格式(例如,gdsii)以便制作。
[0146]
所得到的集成电路芯片可被制作者以原始晶圆的形式分发(即,作为具有多个未封装芯片的单个晶圆)、作为裸片分发、或者以封装形式分发。在后一种情况下,芯片被安装在单芯片封装中(例如塑料载体,具有附接到主板或其他更高级载体的引线)或安装在多芯片封装中(例如陶瓷载体,其具有表面互连或隐埋互连中的任一者或两者)。在任何情况下,芯片随后与其他芯片、分立电路元件和/或其他信号处理器件被集成为以下各项的一部分:(a)中间产品,例如处理器板、服务器平台或者主板,或者(b)最终产品。
[0147]
以上对示例实施例的描述是为了说明和描述而给出的。其并不意图是穷举性的或者将本公开限制到所公开的精确形式。根据本公开,许多修改和变化是可能的。意图是本公开的范围不被本详细描述所限制,而是由所附权利要求来限定。未来递交的要求本技术优先权的申请可以按不同的方式要求保护公开的主题,并且一般地可包括本文以各种方式公开或以其他方式展示的一个或多个限制的任何集合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1