人脸简笔画生成方法及装置与流程
本发明涉及计算机技术领域,具体涉及一种人脸简笔画生成方法及装置。
背景技术:
将人脸图像转换为简笔画,在公共安全领域和数字娱乐领域均具有很重要的应用价值。
在传统图像处理方法中,如果要使生成的简笔画效果好,需要图像处理方法的运算复杂度很高,这难以满足实时性的需求,随着机器学习技术的发展,基于机器学习的图像处理技术比传统的图像处理技术运算速度高且精确度也高,因此衍生出很多由人脸图像生成简笔画的机器学习模型。
然而,这些机器学习模型由人脸图像生成的简笔画受人脸属性变化(如人脸纹理特性等属性)的影响较大,生成效果不佳。
技术实现要素:
本发明的目的是针对上述现有技术的不足提出的一种人脸简笔画生成方法及装置,该目的是通过以下技术方案实现的。
本发明的第一方面提出了一种人脸简笔画生成方法,所述方法包括:
从接收到的图像中裁剪出人脸图像,并预测所述人脸图像中人脸的属性类别;
将所述人脸图像输入已训练的通用人脸肖像合成模型,以使所述通用人脸肖像合成模型合成所述人脸图像的第一人脸简笔画;
确定所述属性类别需使用的已训练的专用人脸肖像合成模型,并将所述人脸图像输入所述专用人脸肖像合成模型,以使所述专用人脸肖像合成模型合成所述人脸图像的第二人脸简笔画;
将所述第一人脸简笔画和所述第二人脸简笔画进行融合,得到第三人脸简笔画。
本发明的第二方面提出了一种人脸简笔画生成装置,所述装置包括:
属性预测模块,用于从接收到的图像中裁剪出人脸图像,并预测所述人脸图像中人脸的属性类别;
通用合成模块,用于将所述人脸图像输入已训练的通用人脸肖像合成模型,以使所述通用人脸肖像合成模型合成所述人脸图像的第一人脸简笔画;
专用合成模块,用于确定所述属性类别需使用的已训练的专用人脸肖像合成模型,并将所述人脸图像输入所述专用人脸肖像合成模型,以使所述专用人脸肖像合成模型合成所述人脸图像的第二人脸简笔画;
融合模块,用于将所述第一人脸简笔画和所述第二人脸简笔画进行融合,得到第三人脸简笔画。
在本发明实施例中,在使用通用人脸肖像合成模型合成第一人脸简笔画的同时,针对不同的人脸属性类别使用不同的专用人脸肖像合成模型合成第二人脸简笔画,以克服人脸属性变化对于肖像简笔画合成质量的影响,进而由第一人脸简笔画和第二人脸简笔画融合得到的第三人脸简笔画更加精确,并且满足不同人脸属性的个性化需求。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明根据一示例性实施例示出的一种人脸简笔画生成方法的实施例流程图;
图2为本发明示出的一种人脸不同部位区域的分割示意图;
图3为本发明示出的一种人脸简笔画生成系统结构示意图;
图4为本发明根据一示例性实施例示出的一种电子设备的硬件结构图;
图5为本发明根据一示例性实施例示出的一种人脸简笔画生成装置的实施例流程图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
在本发明使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本发明。在本发明和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本发明可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本发明范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
由于现有用于合成人脸简笔画的机器学习模型单一,难以满足不同人脸属性(如年龄、性别等属性)的用户对于肖像简笔画的不同需求,本发明提出的人脸简笔画生成方法,旨在克服人脸属性变化对于肖像简笔画合成质量的影响,使得给予任意属性的人脸图像,都可以合成出清晰美观、身份一致的高质量肖像简笔画,满足不同人脸属性的个性化需求。
下面以具体实施例对本发明提出的人脸简笔画生成方法进行详细说明。
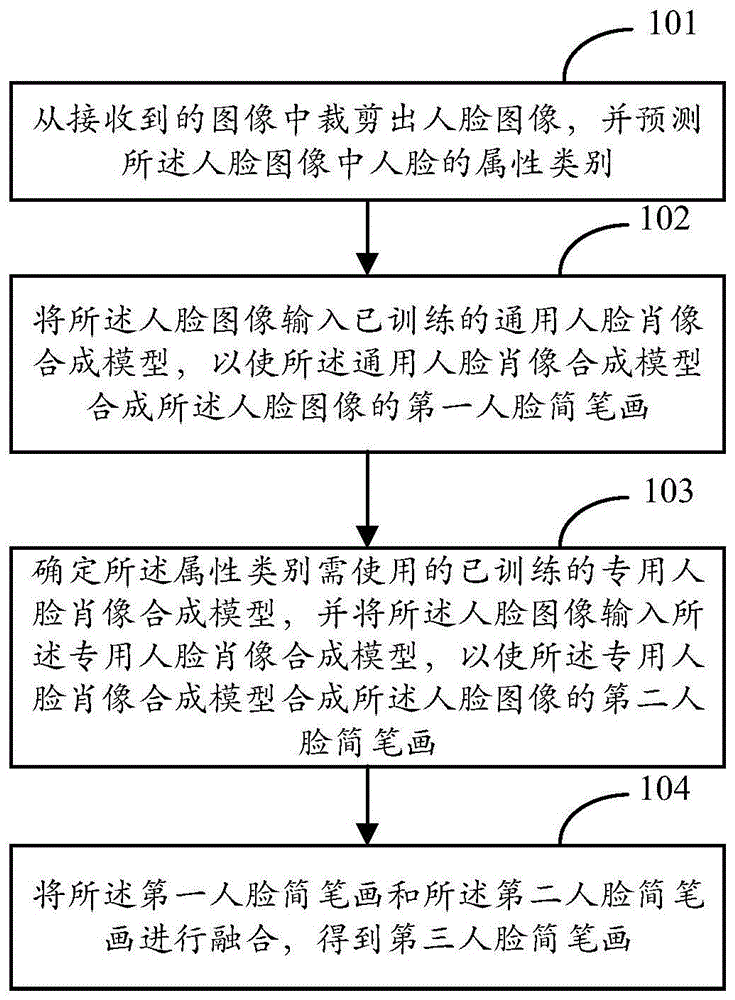
图1为本发明根据一示例性实施例示出的一种人脸简笔画生成方法的实施例流程图,所述人脸简笔画生成方法可以应用于电子设备(如pc机、终端、服务器等设备)上。如图1所示,所述人脸简笔画生成方法包括如下步骤:
步骤101:从接收到的图像中裁剪出人脸图像,并预测所述人脸图像中人脸的属性类别。
在一实施例中,针对从接收到的图像中裁剪出人脸图像的过程,可以通过将所述图像输入已训练的人脸检测模型,以使所述人脸检测模型检测所述图像中的人脸,并预测人脸关键点的位置,进而依据所述人脸关键点的位置对所述图像进行仿射变换,以校正所述图像中的人脸,最后从仿射变换后的图像中裁剪出设定尺寸的人脸图像。
其中,人脸关键点可以包括左眼中心、右眼中心、鼻尖、两个嘴角等关键位置。通过仿射变换可以校正图像中的人脸。可选的,通过仿射变换可以使图像中人脸的左眼和右眼位于水平位置,且左眼与右眼之间为设定像素距离。
例如,通过仿射变换可以将左眼与右眼调整到水平位置,且两眼之间调整为120个像素距离,在进行裁剪时,可以沿两眼到图像上边缘距离为250个像素的边界开始,裁剪出512*512像素大小的人脸图像,且两眼中心点位于人脸图像的垂直中心线上。
本领域技术人员可以理解的是,人脸检测模型可以采用相关技术中实现,本发明对人脸检测模型的具体实现方式不进行限定,如可以采用mtcnn模型进行人脸关键点检测。
需要说明的是,在预测所述人脸图像中人脸的属性类别之前,还可以对人脸图像进行调整亮度、美化皮肤的操作,以提升人脸图像视觉质量。
在一实施例中,针对预测所述人脸图像中人脸的属性类别的过程,可以通过将所述人脸图像输入已训练的预测模型,以由所述预测模型中的特征提取网络提取所述人脸图像的特征图并输出给所述预测模型中的属性预测网络,所述属性预测网络基于所述特征图预测人脸的属性类别。
示例性的,所述属性类别可以包括年轻男性、年轻女性、老年男性及老年女性等。
在本发明中,所述预测模型为多任务学习模型,也即所述预测模型还包括权重预测网络,针对所述预测模型的训练过程请参见下述步骤104中的相关描述,在此先不详述。
步骤102:将所述人脸图像输入已训练的通用人脸肖像合成模型,以使所述通用人脸肖像合成模型合成所述人脸图像的第一人脸简笔画。
其中,所述通用人脸肖像合成模型的输出为不考虑人脸属性类别直接合成的人脸肖像简笔画。
步骤103:确定所述属性类别需使用的已训练的专用人脸肖像合成模型,并将所述人脸图像输入所述专用人脸肖像合成模型,以使所述专用人脸肖像合成模型合成所述人脸图像的第二人脸简笔画。
其中,专用人脸肖像合成模型的输出为考虑人脸属性类别合成的人脸肖像简笔画,且每个属性类别对应使用一个专用人脸肖像合成模型进行人脸肖像简笔画合成。
在执行步骤102和步骤103之前,需要分别训练通用人脸肖像合成模型和每一属性类别对应的专用人脸肖像合成模型。
其中,通用人脸肖像合成模型和专用人脸肖像合成模型在训练时均采用生成对抗网络结构。并且人脸肖像合成模型和专用人脸肖像合成模型均采用编码器-解码器结构实现。
编码器使用多个卷积层实现,如编码器可以采用vggface特征提取器,相应的,解码器使用多个转置卷积层、归一化层和激活层实现。
针对各属性类别对应的专用人脸肖像合成模型的训练过程,可以包括:
以属性类别包括四种类别:年轻男性、年轻女性、老年男性及老年女性为例,首先获取人脸样本集,该人脸样本集中的每一人脸样本标记有属性类别,并获取每一人脸样本对应的真实人脸简笔画,针对每一属性类别,构建对应的专用人脸肖像合成模型和判别模型,并利用标记有该属性类别的人脸样本和对应的真实人脸简笔画以交替迭代方式优化已构建的专用人脸肖像合成模型和判别模型。
其中,所述专用人脸肖像合成模型输入为人脸样本,输出为合成的人脸简笔画;所述判别模型输入为合成的人脸简笔画,输出为所述人脸简笔画的判别结果和人脸属性,以及输入为真实人脸简笔画,输出为所述真实人脸简笔画的判别结果和人脸属性。
基于上述描述,所述判别模型的损失值由合成的人脸简笔画的判别结果和类别、真实人脸简笔画的判别结果和属性类别得到,所述专用人脸肖像合成模型的损失值由合成的人脸简笔画与人脸样本之间的内容损失值、合成的人脸简笔画与真实人脸简笔画之间的风格损失值、所述判别模型的损失值得到。
其中,在由合成的人脸简笔画的判别结果和类别、真实人脸简笔画的判别结果和属性类别计算判别模型的损失值lca-adv时可以采用交叉熵损失函数计算。
对于合成的人脸简笔画与人脸样本之间的内容损失值的计算公式如下:
对于合成的人脸简笔画与真实人脸简笔画之间的风格损失值的计算公式如下:
gram(·)表示gram矩阵,即
由上述判别模型的损失值lca-adv、内容损失值lcontent、风格损失值lstyle计算专用人脸肖像合成模型的损失值的公式如下:
lglobal=lidentity+λlstyle+βlca-adv(公式3)
其中,λ≥0,β≥0。
在训练过程中,专用人脸肖像合成模型与判别模型交替迭代优化,即优化公式如下:
其中,g*表示专用人脸肖像合成模型的优化,d*表示判别模型的优化。
需要说明的是,针对通用人脸肖像合成模型的训练过程与上述专用人脸肖像合成模型的训练原理相同,区别在于通用人脸肖像合成模型可以利用上述人脸样本集中的所有人脸样本进行训练优化,不再赘述。
可选的,也可以先训练通用人脸肖像合成模型,然后利用通用人脸肖像合成模型初始化专用人脸肖像合成模型后,再对专用人脸肖像合成模型进行微调优化,以提升模型训练效率。
步骤104:将所述第一人脸简笔画和所述第二人脸简笔画进行融合,得到第三人脸简笔画。
基于上述步骤101中描述的预测模型还包括权重预测网络,预测模型中的特征提取网络提取人脸图像的特征图还出输出给权重预测网络,所述权重预测网络基于该特征图预测融合权重。
进一步地,通过利用融合权重对第一人脸简笔画和第二人脸简笔画进行融合,融合公式如下:
ofinal=β·gk*(x)+(1-β)·gu(x)(公式5)
其中,·表示像素值点乘,gk*(x)表示第二人脸简笔画,gu(x)表示第一人脸简笔画,β表示融合权重。
针对预测模型的训练过程,可以先利用人脸样本集中的每一人脸样本优化已构建预测模型中的特征提取网络和属性预测网络,直至特征提取网络和属性预测网络收敛,再利用人脸样本集中的每一人脸样本经过已优化的特征提取网络得到的特征图优化已构建预测模型中的权重预测网络,直至权重预测网络的损失值低于预设值;
其中,特征提取网络包括多个卷积层,属性预测网络和权重预测网络均由多个全连接层实现。
权重预测网络的损失值为人脸样本与融合得到的第三人脸简笔画之间的内容损失值。
所述融合得到的第三人脸简笔画为人脸样本分别经过通用人脸肖像合成模型和对应的专用人脸肖像合成模型得到第一人脸简笔画和第二人脸简笔画后,利用人脸样本的特征图经过权重预测网络得到的融合权重对第一人脸简笔画和第二人脸简笔画进行融合得到。
由此可见,属性类别预测由预测模型中的特征提取网络和属性预测网络实现预测,融合权重预测由预测模型中的特征提取网络和权重预测网络实现预测,因此预测模型为多任务学习模型。
并且,在优化权重预测网络之前,需要先完成通用人脸肖像合成模型和专用人脸肖像合成模型的优化训练。
需要说明的是,在从接收到的图像中裁剪出人脸图像之后,可以通过将所述人脸图像输入已训练的人脸解析模型,以使所述人脸解析模型对所述人脸图像中的人脸各部位区域进行分割,并获取所述人脸解析模型输出的面部区域的位置。
其中,人脸各部位区域可以包括左眉、右眉、左眼、右眼、鼻子、嘴部、面部、头发、颈部、躯干以及背景等11个部位区域。参见图2,为由人脸解析模型输出的11个区域对应的解析结果,由图2所示,11个区域包括左眉、右眉、左眼、右眼、鼻子、嘴部、面部、头发、颈部、躯干以及背景。
需要进一步说明的是,在得到第三人脸简笔画之后,还可以对第三人脸简笔画进行后处理操作,并对处理后的第三人脸简笔画中位于所述面部区域中的简笔画进行调整,再对调整后的第三人脸简笔画进行矢量化操作,得到最终的人脸简笔画。
其中,后处理操作包括模糊、二值化、膨胀等操作,以弥补较窄的间断和细长的沟壑,消除较小的空洞,填补轮廓线中的断裂以达到平滑轮廓的目的。
可选的,在对面部区域中的简笔画进行调整时,可以针对属性类别为年轻女性的用户,去除位于面部区域中的简笔画,以达到去除面部皮肤区域的黑色线条、斑点的作用,针对属性类别为老年男性的用户,分别将左眼、右眼及鼻子区域以预设像素距离进行扩张得到扩张区域,将位于面部区域但未位于扩张区域的简笔画去除,以达到将面部皮肤区域中的鱼尾纹、法令纹对应的线条约束在阈值长度内的效果。
最后,对调整后的第三人脸简笔画进行矢量化操作可以使得生成的线条更加平滑,使最终的人脸肖像简笔画更加简洁和美观,并且符合不同年龄、性别用户的特点和需求。
针对上述步骤101至步骤104的过程,参见图3所示的系统结构,首先将人脸照片输入通用生成器得到第一人脸简笔画,并将人脸照片输入预测模型得到属性类别和融合权重,由属性类别控制门控模块选取对应的专用生成器,并将人脸照片输入选取的专用生成器得到第二人脸简笔画,进而利用融合权重对第一人脸简笔画和第二人脸简笔画进行融合得到第三人脸简笔画,再由自适应后处理模块对第三人脸简笔画进行模糊、二值化、膨胀、面部区域中简笔画的调整、矢量化等操作,得到最终的人脸肖像简笔画输出。
在本实施例中,在使用通用人脸肖像合成模型合成第一人脸简笔画的同时,针对不同的人脸属性类别使用不同的专用人脸肖像合成模型合成第二人脸简笔画,以克服人脸属性变化对于肖像简笔画合成质量的影响,进而由第一人脸简笔画和第二人脸简笔画融合得到的第三人脸简笔画更加精确,并且满足不同人脸属性的个性化需求。
图4为本发明根据一示例性实施例示出的一种电子设备的硬件结构图,该电子设备包括:通信接口401、处理器402、机器可读存储介质403和总线404;其中,通信接口401、处理器402和机器可读存储介质403通过总线404完成相互间的通信。处理器402通过读取并执行机器可读存储介质403中与人脸简笔画生成方法的控制逻辑对应的机器可执行指令,可执行上文描述的人脸简笔画生成方法,该方法的具体内容参见上述实施例,此处不再累述。
本发明中提到的机器可读存储介质403可以是任何电子、磁性、光学或其它物理存储装置,可以包含或存储信息,如可执行指令、数据,等等。例如,机器可读存储介质可以是:易失存储器、非易失性存储器或者类似的存储介质。具体地,机器可读存储介质403可以是ram(randomaccessmemory,随机存取存储器)、闪存、存储驱动器(如硬盘驱动器)、任何类型的存储盘(如光盘、dvd等),或者类似的存储介质,或者它们的组合。
与前述人脸简笔画生成方法的实施例相对应,本发明还提供了人脸简笔画生成装置的实施例。
图5为本发明根据一示例性实施例示出的一种人脸简笔画生成装置的实施例流程图,所述人脸简笔画生成装置可以应用于电子设备上。如图5所示,所述人脸简笔画生成装置包括:
属性预测模块510,用于从接收到的图像中裁剪出人脸图像,并预测所述人脸图像中人脸的属性类别;
通用合成模块520,用于将所述人脸图像输入已训练的通用人脸肖像合成模型,以使所述通用人脸肖像合成模型合成所述人脸图像的第一人脸简笔画;
专用合成模块530,用于确定所述属性类别需使用的已训练的专用人脸肖像合成模型,并将所述人脸图像输入所述专用人脸肖像合成模型,以使所述专用人脸肖像合成模型合成所述人脸图像的第二人脸简笔画;
融合模块540,用于将所述第一人脸简笔画和所述第二人脸简笔画进行融合,得到第三人脸简笔画。
在一可选实现方式中,所述属性预测模块510,具体用于在预测所述人脸图像中人脸的属性类别过程中,将所述人脸图像输入已训练的预测模型,以由所述预测模型中的特征提取网络提取所述人脸图像的特征图并输出给所述预测模型中的属性预测网络,所述属性预测网络基于所述特征图预测人脸的属性类别。
在一可选实现方式中,所述装置还包括(图5中未示出):
训练模块,用于获取人脸样本集,所述人脸样本集中的每一人脸样本标记有属性类别,所述属性类别包括年轻男性、年轻女性、老年男性及老年女性;获取所述人脸样本集中每一人脸样本对应的真实人脸简笔画;针对每一属性类别,构建对应的专用人脸肖像合成模型和判别模型,并利用标记有该属性类别的人脸样本和对应的真实人脸简笔画以交替迭代方式优化已构建的专用人脸肖像合成模型和判别模型;其中,所述专用人脸肖像合成模型输入为人脸样本,输出为合成的人脸简笔画;所述判别模型输入为合成的人脸简笔画,输出为所述人脸简笔画的判别结果和人脸属性,以及输入为真实人脸简笔画,输出为所述真实人脸简笔画的判别结果和人脸属性;所述判别模型的损失值由合成的人脸简笔画的判别结果和类别、真实人脸简笔画的判别结果和属性类别得到,所述专用人脸肖像合成模型的损失值由合成的人脸简笔画与人脸样本之间的内容损失值、合成的人脸简笔画与真实人脸简笔画之间的风格损失值、所述判别模型的损失值得到。
在一可选实现方式中,所述预测模型还包括权重预测网络,所述属性预测模块510,还用于特征提取网络提取所述人脸图像的特征图并输出给权重预测网络,所述权重预测网络基于所述特征图预测融合权重;
所述融合模块540,具体用于利用所述融合权重对所述第一人脸简笔画和所述第二人脸简笔画进行融合。
在一可选实现方式中,所述训练模块,还用于利用所述人脸样本集中的每一人脸样本优化已构建预测模型中的特征提取网络和属性预测网络,直至特征提取网络和属性预测网络收敛;利用所述人脸样本集中的每一人脸样本经过已优化的特征提取网络得到的特征图优化已构建预测模型中的权重预测网络,直至所述权重预测网络的损失值低于预设值;其中,所述权重预测网络的损失值为人脸样本与融合得到的第三人脸简笔画之间的内容损失值,所述第三人脸简笔画为人脸样本分别经过通用人脸肖像合成模型和对应的专用人脸肖像合成模型得到第一人脸简笔画和第二人脸简笔画后,利用人脸样本的特征图经过权重预测网络得到的融合权重对第一人脸简笔画和第二人脸简笔画进行融合得到。
在一可选实现方式中,所述装置还包括(图5中未示出):
人脸解析模块,用于在所述属性预测模块510从接收到的图像中裁剪出人脸图像之后,将所述人脸图像输入已训练的人脸解析模型,以使所述人脸解析模型对所述人脸图像中的人脸各部位区域进行分割,并获取所述人脸解析模型输出的面部区域的位置;
后处理模块,用于在所述融合模块540将所述第一人脸简笔画和所述第二人脸简笔画进行融合,得到第三人脸简笔画之后,对所述第三人脸简笔画进行后处理操作;对处理后的第三人脸简笔画中位于所述面部区域中的简笔画进行调整,并对调整后的第三人脸简笔画进行矢量化操作,得到最终的人脸简笔画。
上述装置中各个单元的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本发明方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本发明旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本发明未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!