一种基于注意力机制深度学习的混沌时间序列预测方法与流程
本发明涉及一种基于注意力机制深度学习的混沌时间序列预测方法,属于混沌系统技术领域。
背景技术:
混沌系统是一种从无序运动中产生有序高维复杂的非线性动力系统。混沌的离散情况常表现为混沌时间序列,混沌时间序列是由混沌系统生成的具有混沌特性的时间序列,混沌时间序列中蕴涵着系统非常丰富的动力学信息,混沌时间序列是混沌理论通向现实世界的一个桥梁,是混沌系统的一个重要研究领域。根据takens相空间延迟重构定理,混沌系统的内在规律可以通过混沌时间序列进行重构预测。如何选择或构造预测模型是混沌时间序列预测中的关键问题之一。
近年来,提出了各种混沌时间序列预测模型。例如volterra滤波器,径向基函数网络,支持向量机,模糊模型等。在这些模型中,神经网络(nn)由于其强大的学习能力和良好的泛化能力成为最广泛使用的模型,尤其是在深度学习出现之后。神经网络在混沌领域中的大多数应用都是基于前馈神经网络,例如径向基函数网络和反向传播网络。尽管如此,传统的基于梯度下降的神经网络学习算法在混沌时间序列预测应用中仍存在一些明显的弊端和局限性,包括:(1)这些模型收敛速度慢,趋于陷入局部最优,影响了预测精度和广泛的应用。(2)由于是静态网络,这些模型在识别混沌动力学系统方面有局限性。(3)对于这些网络,确定合适数量的隐藏节点也是一个挑战。目前虽已涌现出许多基于深度学习的混沌时间序列预测方法,尤其是长短时记忆神经网络lstm,尽管lstm可以捕获长期依赖关系并弥补递归神经网络rnn训练过程中梯度消失和梯度爆炸的问题,但其对每个隐藏层滑动窗口步长的关注度是一致的,这可能会引起分散注意力的问题,影响混沌时间序列的预测效果。
技术实现要素:
为了克服现有技术中存在的不足,本发明目的是提供一种基于注意力机制深度学习的混沌时间序列预测方法。该方法基于深度神经网络以及注意力机制对多元混沌时间序列进行预测。
为了实现上述发明目的,解决已有技术中所存在的问题,本发明采取的技术方案是:一种基于注意力机制深度学习的混沌时间序列预测方法,包括以下步骤:
步骤1、构建混沌时间序列数据集,利用lorenz系统和rossler系统生成混沌时间序列数据,具体包括以下子步骤:
(a)lorenz系统方程通过公式(1)进行描述,
式中,
(b)为使lorenz系统完全进入混沌状态,丢弃初始瞬态前1000个点;
(c)通过简单的交叉验证生成训练集和测试集,获得具有混沌特性的时间序列;
(d)rossler系统方程通过公式(2)进行描述:
式中,
(e)舍弃掉瞬态,将前20000个点划为训练集,接着5000个点划为测试集;
步骤2、对混沌时间序列进行相空间重构,根据takens定理进行相空间重构,对于d′维混沌吸引子的一维标量时间序列{x(i):1≤i≤n}都可以在拓扑结构不变情况下找到一个d维嵌入相空间,通过一维的混沌时间序列{x(i)}的不同延迟时间τ来构建d维相空间状态向量,d维相空间状态向量通过公式(3)进行描述:
xi=(x(i),…,x(i+(d-1)τ),i=1,2,…,n-(d-1)τ(3)
式中,xi表示相空间状态向量,x(i)表示标量时间序列,d表示嵌入维数,τ表示延迟时间,takens定理证明找到合适的嵌入尺寸,如果延迟坐标的维数是动态系统的维数,则在该嵌入维数空间中恢复吸引子,吸引子在嵌入维空间中恢复,在重构空间的轨迹中,动力系统保持微分同胚性,设置嵌入维数d=5,延迟时间τ=1;
步骤3、使用lstm神经网络模型训练混沌时间序列数据,lstm神经网络模型将输入的历史时间序列数据编码成隐藏状态和细胞状态,通过门的设计,lstm神经网络模型自适应地控制积累信息的强弱,其中每个细胞计算单元的计算过程通过公式(4)-(9)进行描述:
it=σ(wi[ht-1,xt-1]+bi)(4)
ft=σ(wf[ht-1,xt-1]+bf)(5)
ot=σ(wo[ht-1,xt-1]+bo)(8)
ht=ottanh(ct)(9)
式中,it,ft,ot分别表示输入门、遗忘门和输出门,ct表示细胞状态,wi,wf,wo,wc分别表示控制每个门输出的权值矩阵,bi,bf,bc,bo分别表示it,ft,ct,和ot的偏置量,ct-1表示上一层的细胞,xt-1表示当前的输入,ht-1表示上层的隐藏层输出,σ为sigmoid函数,tanh为激活函数,h表示隐层输出;
步骤4、构建基于预测的注意力机制模型,随着输入混沌时间序列长度的增加,训练模型的隐藏层信息会丢失或者引入噪声干扰,预测网络的性能会迅速下降,这里使用注意力机制在所有时间步长上自适应选择相关的隐藏状态信息,具体地,基于先前的预测网络lstm单元隐藏状态来计算时间t处每个隐藏状态的关注权重通过公式(10)-(12)进行描述:
式中,
步骤5、构建离线训练模型,训练模型使用端到端的方式通过时间反向传播算法bptt进行训练,损失函数使用均方根误差rmse函数,设置学习率lr=0.01,选择adam算法作为优化算法,训练优化的目标是使模型输出的
式中,n为样本总数,t表示任一时刻样本,yt为第i个样本的预测值,
步骤6、在线预测,具体包括以下子步骤:
(a)、将步骤1得到的测试混沌时间序列数据,通过步骤2相空间重构对数据进行处理;
(b)、通过步骤3使用lstm神经网络模型对混沌时间序列进行预测,利用步骤4构建模型隐藏层的注意力机制模型;
(c)、在步骤5训练模型中优化好参数后,将所学得的参数迁移至预测模型,当预测一段长度为t的时间序列(x0,x1,…,xt-1)时,使用预测模型做间接多步预测,迭代地将模型预测的输出作为下一步模型的输入,最终得到长度为p预测序列
本发明有益效果是:一种基于注意力机制深度学习的混沌时间序列预测方法,包括以下步骤:(1)构建混沌时间序列数据集,(2)对混沌时间序列进行相空间重构,(3)使用lstm神经网络模型训练混沌时间序列数据,(4)构建基于预测的注意力机制模型,(5)构建离线训练模型,(6)在线预测。与已有技术相比,本发明一种基于深度学习的混沌时间序列预测方法,模型结构清晰,具有参考价值,可以应用到混沌系统的例如金融市场预测或能源预测等方面。
附图说明
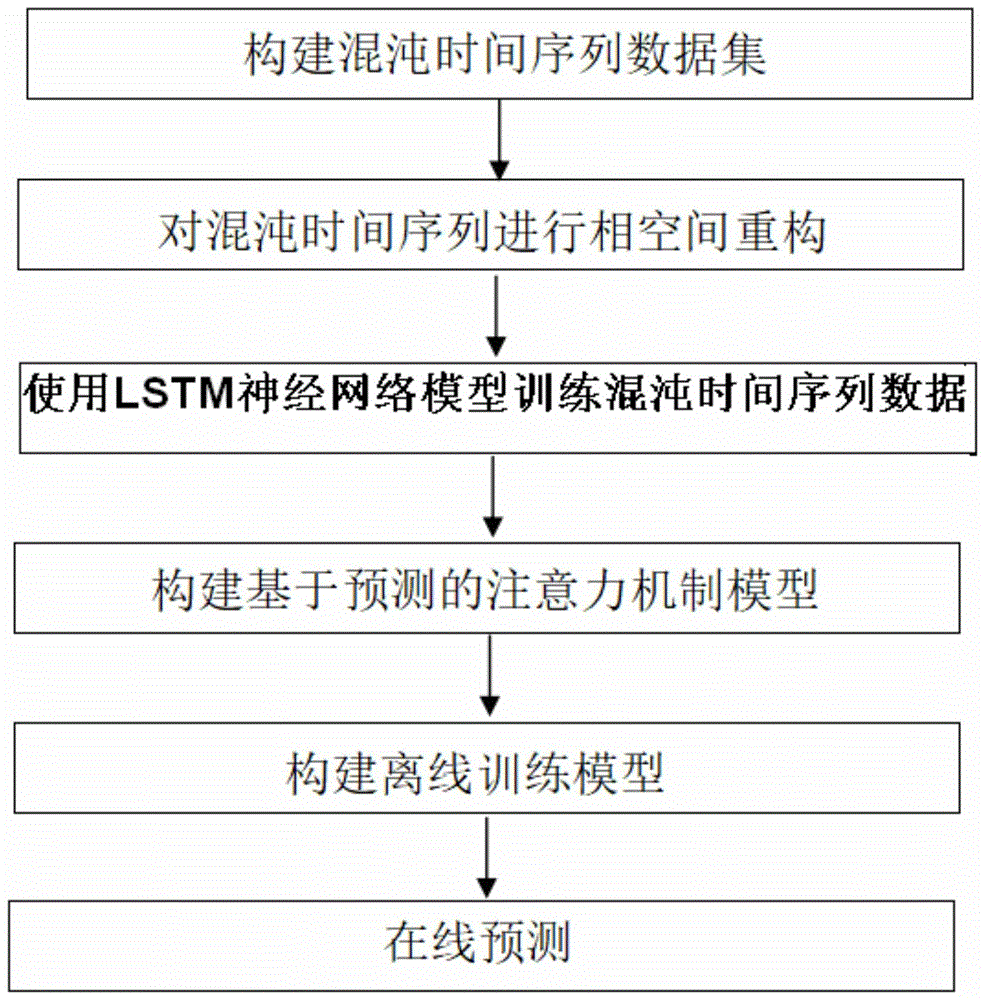
图1是本发明方法步骤流程图。
图2是本发明中的深度神经网络模型图。
具体实施方式
下面结合附图对本发明作进一步说明。
如图1所示,一种基于注意力机制深度学习的混沌时间序列预测方法,包括以下步骤:
步骤1、构建混沌时间序列数据集,利用lorenz系统和rossler系统生成混沌时间序列数据,具体包括以下子步骤:
(a)lorenz系统方程通过公式(1)进行描述,
式中,
(b)为使lorenz系统完全进入混沌状态,丢弃初始瞬态前1000个点;
(c)通过简单的交叉验证生成训练集和测试集,获得具有混沌特性的时间序列;
(d)rossler系统方程通过公式(2)进行描述:
式中,
(e)舍弃掉瞬态,将前20000个点划为训练集,接着5000个点划为测试集;
步骤2、对混沌时间序列进行相空间重构,根据takens定理进行相空间重构,对于d′维混沌吸引子的一维标量时间序列{x(i):1≤i≤n}都可以在拓扑结构不变情况下找到一个d维嵌入相空间,通过一维的混沌时间序列{x(i)}的不同延迟时间τ来构建d维相空间状态向量,d维相空间状态向量通过公式(3)进行描述:
xi=(x(i),…,x(i+(d-1)τ),i=1,2,…,n-(d-1)τ(3)
式中,xi表示相空间状态向量,x(i)表示标量时间序列,d表示嵌入维数,τ表示延迟时间,takens定理证明找到合适的嵌入尺寸,如果延迟坐标的维数是动态系统的维数,则在该嵌入维数空间中恢复吸引子,吸引子在嵌入维空间中恢复,在重构空间的轨迹中,动力系统保持微分同胚性,设置嵌入维数d=5,延迟时间τ=1;
步骤3、使用lstm神经网络模型训练混沌时间序列数据,lstm神经网络模型将输入的历史时间序列数据编码成隐藏状态和细胞状态,通过门的设计,lstm神经网络模型自适应地控制积累信息的强弱,其中每个细胞计算单元的计算过程通过公式(4)-(9)进行描述:
it=σ(wi[ht-1,xt-1]+bi)(4)
ft=σ(wf[ht-1,xt-1]+bf)(5)
ot=σ(wo[ht-1,xt-1]+bo)(8)
ht=ottanh(ct)(9)
式中,it,ft,ot分别表示输入门、遗忘门和输出门,ct表示细胞状态,wi,wf,wo,wc分别表示控制每个门输出的权值矩阵,bi,bf,bc,bo分别表示it,ft,ct,和ot的偏置量,ct-1表示上一层的细胞,xt-1表示当前的输入,ht-1表示上层的隐藏层输出,σ为sigmoid函数,tanh为激活函数,h表示隐层输出;
步骤4、构建基于预测的注意力机制模型,随着输入混沌时间序列长度的增加,训练模型的隐藏层信息会丢失或者引入噪声干扰,预测网络的性能会迅速下降,这里使用注意力机制在所有时间步长上自适应选择相关的隐藏状态信息,具体地,基于先前的预测网络lstm单元隐藏状态来计算时间t处每个隐藏状态的关注权重通过公式(10)-(12)进行描述:
式中,
步骤5、构建离线训练模型,训练模型使用端到端的方式通过时间反向传播算法bptt进行训练,损失函数使用均方根误差rmse函数,设置学习率lr=0.01,选择adam算法作为优化算法,训练优化的目标是使模型输出的
式中,n为样本总数,t表示任一时刻样本,yt为第i个样本的预测值,
步骤6、在线预测,具体包括以下子步骤:
(a)、将步骤1得到的测试混沌时间序列数据,通过步骤2相空间重构对数据进行处理;
(b)、通过步骤3使用lstm神经网络模型对混沌时间序列进行预测,利用步骤4构建模型隐藏层的注意力机制模型;
(c)、在步骤5训练模型中优化好参数后,将所学得的参数迁移至预测模型,当预测一段长度为t的时间序列(x0,x1,…,xt-1)时,使用预测模型做间接多步预测,迭代地将模型预测的输出作为下一步模型的输入,最终得到长度为p预测序列
- 还没有人留言评论。精彩留言会获得点赞!