基于阻尼因子的多元宇宙算法的DNA存储编码优化方法与流程
本发明涉及群体智能优化算法和dna存储编码,具体来说是用多元宇宙算法、阻尼因子和lévy飞行来优化dna编码序列,其属于dna存储中编码设计领域。
背景技术:
数据的海量增长使我们需要一种存储效率更高效,存储容量更高的新介质。dna作为一种高密度的存储介质,而且具有长期稳定性成为一种可行的解决方案。dna由四种核苷酸atcg构成,理论存储容量是传统电子系统中二进制的两倍。研究表明dna可以在适宜条件下保存上万年。基于dna的数据存储通常被用于开创性的工作,例如joedavis提出了一个开创性的“microvenus”项目,使用细菌作为存储介质用于储存非生物信息。本世纪初,bancroft等人提出了一种使用密码子三联体简单的编码方法,显示了dna作为存储介质的巨大潜力。dna存储在保存时间上具有优势,在适应的条件下dna数据存储可以保存多年。然而,读写dna数据的成本依然很高。但是最近dna合成和测序方法的飞速发展,dna存储在将来会是一个很有竞争力的存储解决方案。
技术实现要素:
本申请提出了基于阻尼因子的多元宇宙算法的dna存储编码优化方法,该方法首先用多元宇宙算法中的虫洞策略对初始种群进行搜索初始解集;其次,使用带有阻尼扰动因子的更新公式对宇宙集合进行更新;接着,将更新后得到的宇宙集合中的最优宇宙进行lévy飞行操作;最后,比对所得集合是否满足约束条件,符合约束的加入备选解集合;该方法可以构建出数量较优的dna存储编码序列。
为实现上述目的,本申请的技术方案为:基于阻尼因子的多元宇宙算法的dna存储编码优化方法,其具体为:构造满足组合约束条件的最优dna编码序列,首先要构造出一定个数的dna序列作为初始种群,对种群的适应度进行评价排序。其次,利用已经得出的dna编码序列,用阻尼因子和lévy飞行进行优化,得到适应度较高的dna编码序列。然后,通过约束比对根据约束判断是否加入备选解集合。最后,输出最优dna编码序列。
本发明由于采用以上技术方案,能够取得如下的技术效果:
1、用多元宇宙算法对初始种群进行适应度计算,引入黑/白洞隧道不仅可以把物质随机传送到最好宇宙,还可以提高初始种群的平均适应度;
2、使用lévy飞行的更新策略代替基于当前全局最优的随机更新,降低了极大极小值的个体对更新机制的影响,加快了收敛速度。当寻优过程中到达一个不理想状态时,使用阻尼因子可以跳出当前状态尝试在更大的范围内搜索,可以避免算法后期陷入局部最优;
3、本发明提出的阻尼因子的多元宇宙算法的dna序列优化算法能够搜索出数量较优的dna存储编码序列。
附图说明
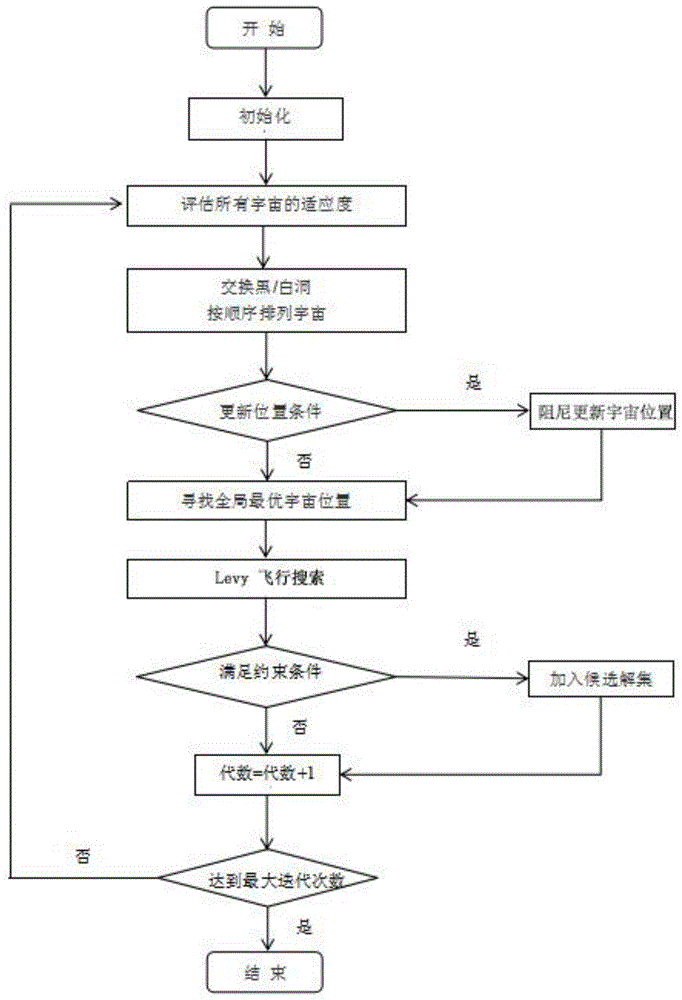
图1为本发明的实现流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施中的技术方案进行清楚、完整的描述,可以理解的是,所描述的实例仅仅是本发明的一部分实例,而不是全部的实施例。基于本发明的实施例,本领域的技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
本发明中涉及的约束条件有四条,分别为全不连续性约束、编辑距离、gc含量和地址不相关约束。将约束条件中的编辑距离和作为目标函数,其他三项作为约束条件。用在权利要求的第二步骤中计算每个个体的适应度值。全不连续性约束表示在一个dna序列中相同的碱基在相邻时不能连续出现。编辑距离指成对的dna序列之间的单字符编辑(插入、删除、替换)的最小数量之和。gc含量约束表示在dna序列集合中任意一个序列中鸟嘌呤(g)和胞嘧啶(c)的数量占整个序列碱基数量的百分比,本实施例将其约束在50%。地址不相关约束指对于成对的dna序列l,h。l的前缀不能作为h的后缀出现,反之亦然,在本申请设置前后缀长度为3。
详细步骤如下所示:
步骤1:生成初始宇宙种群,初始化算法需要的参数tdr,wep,maxiter,c1,wep是虫洞存在概率,wep是旅行距离率,maxtime是最大迭代次数;c1是阻尼扰动因子;
步骤2:计算每个宇宙适应度(膨胀率),更新参数best_universe,即当前最好的宇宙,用多元宇宙算法中的虫洞策略对初始宇宙种群进行排序,选出最优适应度宇宙,把当前适应度最优的作为初始宇宙集合;
步骤3:产生随机数r1依次通过轮盘赌选出宇宙产生白洞,最优宇宙通过白洞与其他宇宙交换物质;
步骤4:对于每个宇宙个体,产生一个随机数r2,对r2和虫洞存在概率wep的大小进行判断,如果r2小于白洞存在概率wep,则执行步骤5,反之则执行步骤7;
步骤5:产生两个随机数r3、r4,并根据随机数r4和阻尼扰动因子c1以及旅行距离率tdr对宇宙物质进行更新,如果r3<0.5执行更新公式2,反之执行更新公式3;
步骤6:把更新结果作为lévy飞行搜索的输入,对最佳适应度宇宙为中心进行lévy飞行搜索操作;
步骤7:计算其他宇宙和初始宇宙是否满足约束条件,若满足即加入初始宇宙集合;
步骤8:判断是否达到最大迭代次数,若是进行步骤9,否则返回步骤2;
步骤9:对结果进行统计,输出序列最大个数。
实施例1
本发明的实施例是在以本发明技术方案为前提下进行实施的,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述实施例。实例中dna编码长度n为8,编辑距离约束为d≥5,全不连续性约束、gc含量约束、地址不相关约束如上所述。
步骤1:对种群进行初始化生成1000个长度为8的dna编码序列。初始化算法所需要的相关参数,虫洞存在概率wep中的min取0.2,max取1,旅行距离率tdr中p取6;
步骤2:用多元宇宙算法中的虫洞策略对初始种群进行搜索,首先初始化宇宙种群的适应度,并对宇宙适应度进行排序,选出最优适应度,把当前适应度最优的作为初始宇宙集合。就本实例通过matlab进行仿真实验通过gc含量,全不连续和地址不相关约束得到初始集合为29;
步骤3:将步骤2通过约束后得到的29条8维的dna序列用多元宇宙算法继续进行寻优操作。本实例用matlab里面的sort()函数得到宇宙个体适应度进行排序后的结果,使用随机数r1依次通过轮盘赌选出宇宙产生白洞,与其他宇宙交换物质,宇宙物质的更新方式为:
其中xij代表的是第i个宇宙中的第j个物质,xvj同理。ui代表的是第i个宇宙,所以ni(ui)是第i个宇宙的标准膨胀率。通过轮盘赌机制,选出第v个宇宙的第j个物质为xwj。其中r1为[0,1]之间的随机数;
步骤4:对于每个宇宙,产生一个随机数r2,对r2和虫洞存在概率wep的大小进行判断,如果r2小于洞存在概率wep,则执行步骤5,反之则执行步骤7;
步骤5:在[0,1]区间产生两个随机数r3,r4并根据随机数r4和旅行距离率tdr对宇宙物质进行更新,如果r3<0.5执行更新公式2,反之执行更新公式3;
xij=xj+c1*tdr×((ubj-lbj)×r4+lbj)(2)
xij=xj-c1*tdr×((ubj-lbj)×r4+lbj)(3)
其中xij代表的是第i个宇宙中的第j个物质,xj代表目前所创建的最佳宇宙的第j个物质,第j个物质的边界分别是ubj和lbj,c1是通过公式4计算的阻尼扰动因子,tdr是自适应的参数旅行距离率,r4是[0,1]区间的随机数。
步骤6:把更新结果作为lévy飞行搜索的输入,对最佳适应度宇宙进行lévy飞行搜索操作;
步骤7:计算其他宇宙和初始宇宙是否满足约束条件,若满足即加入初始宇宙集合newdna;
步骤8:判断是否达到最大迭代次数1000代,若是进行步骤9,否则返回步骤2;
步骤9:对结果进行统计,输出序列最大个数;
本发明提出基于阻尼因子的多元宇宙算法的dna存储编码优化方法,用基于阻尼因子的多元宇宙算法对初始种群进行搜索。通过gc、地址不相关约束和全不连续性约束筛选出符合要求的dna序列,以这些序列为基础根据带有阻尼因子的多元宇宙算法更新公式进行不断的更新,每次更新后对最优宇宙进行lévy飞行搜索操作,评价最优适应度后进入下一次迭代,最终将得到的最大dna序列编码集合作为输出结果。本发明在intel(r)cpu3.6ghz、4.0gb内存、windows10运行环境下,借助matlab对该算法进行仿真实验,实验结果表明本实例的方法结果优于其他算法的实验结果。
表1为初始dna序列
表2为n=8,d≥5时最优dna序列集合
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!