基于不规则数据计算推荐金额的方法及系统与流程
本申请涉及数据处理领域,具体地说,涉及一种基于不规则数据计算推荐金额的方法及系统。
背景技术:
随着计算机的飞速发展,数据的来源越来越多样,覆盖的范围越来越广泛,因此,如何从海量的、模糊的和不完全的数据中提取有用的信息是科研者一直以来的追求。
在进行赔付金额的设定时,大多是通过回归预测模型进行设定,现有的回归预测模型有根据业务经验设定推荐金额、局部加权线性回归和分类模型等。根据业务经验设定大多是通过业务经验设定推荐金额,主要依赖于业务人员的业务经验,科学性差,而且主要依赖于人力,当变量组合较多时,会耗费很大的人力,且计算效率很低。局部加权线性回归虽然有一定的科学性,但局部加权线性回归方法是基于数值型数据进行处理,而进行推荐金额设定时,自变量中存在不少标称型数据,将标称型数据转换为数值型数据是一个难题。此外,局部加权线性回归的输出仍然接近于平滑的连续性数据,与实际业务场景中的数据仍然有较大差别,业务可解释性差。使用分类模型时,通过合理的构建特征虽然可以提高精度,但其存在召回率与精准率不能兼得的问题,因此,在进行赔付金额的设定时,分类模型并不实用。
技术实现要素:
有鉴于此,本申请提供了一种基于不规则数据计算推荐金额的方法及系统,综合考虑自变量信息得到稳定性较高的目标函数,可以输出具有业务可解释性的合理推荐金额,而且能有效避免分类模型中召回率与精准率不可兼得的问题,可以使用与多种场合。
为了解决上述技术问题,本申请有如下技术方案:
第一方面,本申请提供一种基于不规则数据计算推荐金额的方法,包括:
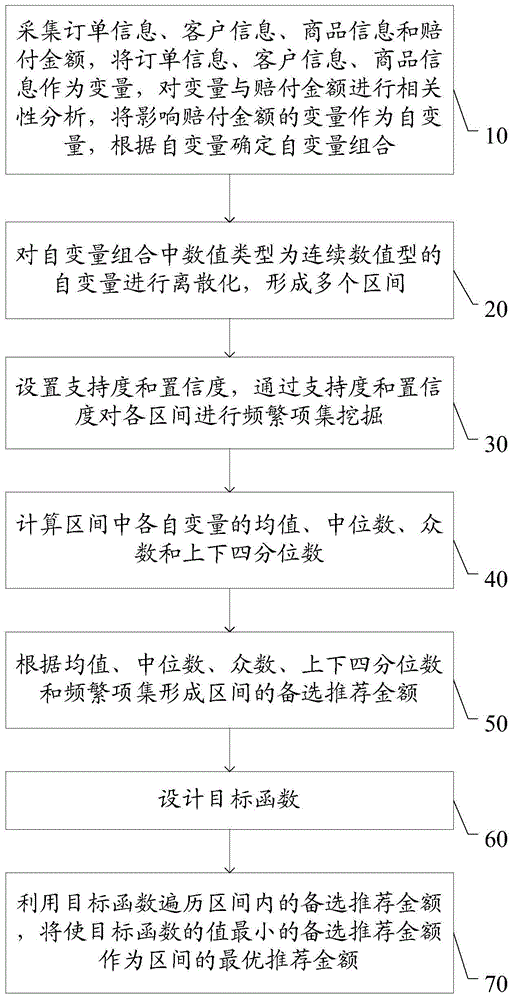
采集订单信息、客户信息、商品信息和赔付金额,将所述订单信息、客户信息、商品信息作为变量,对所述变量与赔付金额进行相关性分析,将影响所述赔付金额的变量作为自变量,根据所述自变量确定自变量组合;
对所述自变量组合中数值类型为连续数值型的自变量进行离散化,形成多个区间;
设置支持度和置信度,通过所述支持度和置信度对各所述区间进行频繁项集挖掘;
计算所述区间中各自变量的均值、中位数、众数和上下四分位数;
根据所述均值、所述中位数、所述众数、所述上下四分位数和所述频繁项集形成所述区间的备选推荐金额;
设计目标函数为cost=eλcost_a+ecost_b,其中,λ表示平滑系数,cost_a表示赔付成本的提升率,cost_b表示满意度偏移量;
利用所述目标函数遍历所述区间内的备选推荐金额,将使所述目标函数的值最小的所述备选推荐金额作为所述区间的最优推荐金额。
可选地,其中:
所述对所述变量与赔付金额进行相关性分析,具体为:采用联列表分析方法或假设检验分析方法分别对所述订单信息、客户信息、商品信息与赔付金额进行相关性分析。
可选地,其中:
筛选不存在频繁项集的区间作为第一区间,利用与所述第一区间相邻区间的备选推荐金额作为所述第一区间的备选推荐金额。
可选地,其中:
设计目标函数之前,还包括:
筛选不存在频繁项集的区间作为第一区间,利用所述第一区间的均值、中位数、众数和上下四分位数作为第一区间的备选推荐金额。
可选地,其中:
所述对各所述自变量组合进行频繁项集挖掘,具体为:采用apriori方法进行频繁项集挖掘。
可选地,其中:
所述对所述自变量组合中数值类型为连续数值型的自变量进行离散化,具体为:将所述连续数值型订单金额按照最细粒度分段,根据相似度对相邻段进行合并,对合并后形成的各个区间进行调整,使得各所述区间之间的分界点为整数。
可选地,其中:
所述赔付成本的提升率为
根据所述区间内的多个备选推荐金额的均值计算满意度偏移量
可选地,其中:
所述赔付成本的提升率为
根据所述区间内的多个备选推荐金额的中位数计算满意度偏移量
另一方面,本申请还提供一种基于不规则数据计算推荐金额的系统,包括:
采集模块,用于采集订单信息、客户信息、商品信息和赔付金额;
分析模块,用于将所述订单信息、客户信息、商品信息作为变量,对所述变量与赔付金额进行相关性分析,将影响所述赔付金额的变量作为自变量,根据所述自变量确定自变量组合;
离散化模块,用于对所述自变量组合中数值类型为连续数值型的自变量进行离散化,形成多个区间;
挖掘模块,用于设置支持度和置信度,通过所述支持度和置信度对各所述自变量组合进行频繁项集挖掘;
计算模块,用于计算所述区间中各自变量的均值、中位数、众数和上下四分位数;
备选推荐金额设置模块,用于根据所述均值、所述中位数、所述众数、所述上下四分位数和所述频繁项集形成所述区间的备选推荐金额;
目标函数设计模块,用于设计目标函数cost=eλcost_a+ecost_b,其中,λ表示平滑系数,cost_a表示赔付成本的提升率,cost_b表示满意度偏移量;
设置模块,用于利用所述目标函数遍历所述区间内的备选推荐金额,将使所述目标函数的值最小的所述备选推荐金额作为所述区间的最优推荐金额。
与现有技术相比,本申请所述的基于不规则数据计算推荐金额的方法及系统,达到了如下效果:
本申请所提供的基于不规则数据计算推荐金额的方法及系统,通过综合考虑相关自变量的信息,科学的设置目标函数,可以取代业务人员繁重的工作量,能够消除人工带来的主观偏见,而且可以适应类型混杂的不规则自变量,使得目标函数可以输出具有业务可解释性的合理推荐金额。另外,通过综合考虑自变量得到的目标函数的稳定性较高,有效避免分类模型中召回率与精准率不可兼得的问题,可以使用于多种场合。此外,由于赔付成本的提升率cost_a和满意度偏移量cost_b的量纲和变化率可能会不一致,因此,本申请在设计目标函数时,使用系数λ和指数函数对目标函数进行平滑,解决由于cost_a和cost_b的量纲和变化率不一致造成无法进行计算的问题,有利于提高赔付金额的计算效率。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1所示为本申请实施例所提供的基于不规则数据计算推荐金额的方法的一种流程图;
图2所示为本申请实施例所提供的基于不规则数据计算推荐金额的方法的另一种流程图;
图3所示为本申请实施例所提供的基于不规则数据计算推荐金额的方法的又一种流程图;
图4所示为本申请实施例所提供的离散化的一种流程图;
图5所示为本申请实施例所提供的基于不规则数据计算推荐金额的系统的一种结构示意图。
具体实施方式
如在说明书及权利要求当中使用了某些词汇来指称特定组件。本领域技术人员应可理解,硬件制造商可能会用不同名词来称呼同一个组件。本说明书及权利要求并不以名称的差异来作为区分组件的方式,而是以组件在功能上的差异来作为区分的准则。如在通篇说明书及权利要求当中所提及的“包含”为一开放式用语,故应解释成“包含但不限定于”。“大致”是指在可接收的误差范围内,本领域技术人员能够在一定误差范围内解决所述技术问题,基本达到所述技术效果。此外,“耦接”一词在此包含任何直接及间接的电性耦接手段。因此,若文中描述一第一装置耦接于一第二装置,则代表所述第一装置可直接电性耦接于所述第二装置,或通过其他装置或耦接手段间接地电性耦接至所述第二装置。说明书后续描述为实施本申请的较佳实施方式,然所述描述乃以说明本申请的一般原则为目的,并非用以限定本申请的范围。本申请的保护范围当视所附权利要求所界定者为准。
在进行赔付金额的设定时,大多是通过回归预测模型进行设定,现有的回归预测模型有根据业务经验设定推荐金额、局部加权线性回归和分类模型等。根据业务经验设定大多是通过业务经验设定推荐金额,主要依赖于业务人员的业务经验,科学性差,而且主要依赖于人力,当变量组合较多时,会耗费很大的人力,且计算效率很低。局部加权线性回归虽然有一定的科学性,但局部加权线性回归方法是基于数值型数据进行处理,而进行推荐金额设定时,自变量中存在不少标称型数据,将标称型数据转换为数值型数据是一个难题。此外,局部加权线性回归的输出仍然接近于平滑的连续性数据,与实际业务场景中的数据仍然有较大差别,业务可解释性差。使用分类模型时,通过合理的构建特征虽然可以提高精度,但其存在召回率与精准率不能兼得的问题,因此,在进行赔付金额的设定时,分类模型并不实用。
有鉴于此,本申请提供了一种基于不规则数据计算推荐金额的方法及系统,综合考虑自变量信息得到稳定性较高的目标函数,可以输出具有业务可解释性的合理推荐金额,而且能有效避免分类模型中召回率与精准率不可兼得的问题,可以使用于多种场合。
以下结合附图和具体实施例进行详细说明。
图1所示为本申请实施例所提供的基于不规则数据计算推荐金额的方法的一种流程图,请参考图1,本申请实施例所提供的基于不规则数据计算推荐金额的方法,包括:
步骤10:采集订单信息、客户信息、商品信息和赔付金额,将订单信息、客户信息、商品信息作为变量,对变量与赔付金额进行相关性分析,将影响赔付金额的变量作为自变量,根据自变量确定自变量组合;
步骤20:对自变量组合中数值类型为连续数值型的自变量进行离散化,形成多个区间;
步骤30:设置支持度和置信度,通过支持度和置信度对各区间进行频繁项集挖掘;
步骤40:计算区间中各自变量的均值、中位数、众数和上下四分位数;
步骤50:根据均值、中位数、众数、上下四分位数和频繁项集形成区间的备选推荐金额;
步骤60:设计目标函数为cost=eλcost_a+ecost_b,其中,λ表示平滑系数,cost_a表示赔付成本的提升率,cost_b表示满意度偏移量;
步骤70:利用目标函数遍历区间内的备选推荐金额,将使目标函数的值最小的备选推荐金额作为区间的最优推荐金额。
具体地,请参考图1,本申请实施例所提供的基于不规则数据计算推荐金额的方法,通过步骤10采集订单信息、客户信息、商品信息和赔付金额,此处的订单信息、客户信息、商品信息和赔付金额均为历史信息,将采集到的订单信息、客户信息、商品信息作为变量,分析各个变量与赔付金额之间的相关性,得到赔付金额与订单信息、客户信息和商品信息之间的关系,并将影响赔付金额的变量作为自变量,利用所有自变量形成自变量组合。得到自变量组合后,通过步骤20,筛选自变量组合中的数值类型为连续数值型的自变量,并对连续数值型的自变量进行离散化,得到多个自变量区间。通过步骤30设置支持度和置信度,例如有事项a和事项b,支持度表示a和b同时出现的概率,置信度表示a出现时b出现的概率,设置合适的支持度和置信度后,对各个区间进行频繁项集挖掘,挖掘出该区间内支持度大于等于设置好的支持度的集合,得到自变量组合中一起出现的概率较大的自变量。通过步骤40计算区间中各自变量的均值、中位数、众数和上下四分位数,并在步骤50中利用均值、中位数、众数和上下四分位数以及频繁项集形成该区间内的备选推荐金额。
请继续参考图1,得到备选推荐金额后,通过步骤60设计目标函数,本申请中设置目标函数为cost=eλcost_a+ecost_b,其中,λ表示平滑系数,通常取λ的值为0.3,cost_a表示赔付成本的提升率,cost_b表示满意度偏移量。得到目标函数后,通过步骤70,将区间内的多个备选推荐金额分别代入目标函数,计算目标函数中cost的值,选取使得目标函数cost的值最小的备选推荐金额作为该区间内的最优推荐金额,即赔付金额。需要说明的是,λ的值为0.3仅是在本实施例中的一种示意性说明,并不作为对本申请的限定,实际上,在不同的使用环境中,λ的值并不是完全相同的,其可以通过人工进行调整,选取使目标函数最优的一个平滑系数作为λ的值,本申请对此不进行限定。
本申请通过综合考虑相关自变量的信息,科学的设置目标函数,可以取代业务人员繁重的工作量,能够消除人工带来的主观偏见,而且可以适应类型混杂的不规则自变量,使得目标函数可以输出具有业务可解释性的合理推荐金额。另外,通过综合考虑自变量得到的目标函数的稳定性较高,有效避免分类模型中召回率与精准率不可兼得的问题,可以使用于多种场合。此外,由于赔付成本的提升率cost_a和满意度偏移量cost_b的量纲和变化率可能会不一致,因此,本申请在设计目标函数时,使用系数λ和指数函数对目标函数进行平滑,解决由于cost_a和cost_b的量纲和变化率不一致造成无法进行计算的问题,有利于提高赔付金额的计算效率。
可选地,对变量与赔付金额进行相关性分析,具体为:采用联列表分析方法或假设检验分析方法分别对订单信息、客户信息、商品信息与赔付金额进行相关性分析。具体地,本实施例中分析各个变量也即订单信息、客户信息、商品信息与赔付金额的相关性时,采用联列表分析方法或假设检验分析方法进行相关性分析。联列表又称为交互分类表,是观测数据按两个或更多属性分类时所列出的频数表,假设检验是根据一定的假设条件由样本推断总体的一种方法。通常情况下,通过联列表进行标称型数值的分析,假设检验实现数值型数据的分析,因此,本实施例中可以通过联列表分析赔付金额与用户类别和商品品类等标称型自变量的关系,通过假设检验分析赔付金额与订单金额的关系。当然,也可以通过联列表分析赔付金额与商品品类和用户类别的关系,或者通过假设检验分析赔付金额与订单金额的关系,本申请对此不做限定。
可选地,图2所示为本申请实施例所提供的基于不规则数据计算推荐金额的方法的另一种流程图,请参考图2,设计目标函数之前,还包括:步骤51:筛选不存在频繁项集的区间作为第一区间,利用与第一区间相邻区间的备选推荐金额作为第一区间的备选推荐金额。具体地,请参考图2,由于支持度和置信度的设置原因,可能会存在某些区间内不存在频繁项集,为了保证赔付金额的准确性,需要对不存在频繁项集的区间进行填充。本实施例中通过步骤51筛选出不存在频繁项集的区间,将其称为第一区间,利用与其相邻区间的备选推荐金额对第一区间进行填充,也即,将相邻区间的备选推荐金额作为第一区间的备选推荐金额,确保每一个区间均存在备选推荐金额,从而确保每一个区间均能通过目标函数遍历得到最优推荐金额,有利于提高最优推荐金额的准确率。
可选地,图3所示为本申请实施例所提供的基于不规则数据计算推荐金额的方法的又一种流程图,请参考图3,设计目标函数之前,还包括步骤52:筛选不存在频繁项集的区间作为第一区间,利用第一区间的均值、中位数、众数和上下四分位数作为第一区间的备选推荐金额。具体地,请参考图3,由于支持度和置信度的设置原因,可能会存在某些区间内不存在频繁项集,为了保证赔付金额的准确性,需要对不存在频繁项集的区间进行填充。本实施例中通过步骤52筛选出不存在频繁项集的区间,将其称为第一区间,利用该区间内的均值、中位数、众数和上下四分位数作为备选推荐金额,如此,可以确保即使不存在频繁项集的区间,也有备选推荐金额,从而确保每一个区间均能通过目标函数遍历得到最优推荐金额,有利于提高最优推荐金额的准确率。
可选地,对各自变量组合进行频繁项集挖掘,具体为:采用apriori方法进行频繁项集挖掘。具体地,本实施例中采用apriori方法进行频繁项集挖掘,apriori是一种挖掘布尔关联规则频繁项集的方法,采用逐层搜索的迭代方法,通过k-项集探索(k+1)-项集。采用apriori方法进行频繁项集挖掘时,首先扫描所有项,得到1-项集c1,根据支持度要求滤去不满足支持度条件的项集,得到频繁1-项集,根据频繁1-项集中的项,连接得到所有可能的2-项,进行剪枝,得到2-项集c2,然后滤去该项集中不满足支持度条件的项,得到频繁2-项集,依次类推,直至得到的项集ck为空,则算法结束。
需要说明的是,采用apriori方法进行频繁项集挖掘,仅是本申请在本实施例中的一种实施方式,在其他实施例中,也可以采用其他频繁项集挖掘方法,例如fp-growth树算法,fp-growth算法只需扫描原始数据两遍,将原始数据中的事务压缩到一个fp-tree树中,达到压缩数据的目的,接着通过fp-tree找出每个item的条件模式基、条件fp-tree,递归挖掘fp-tree得到所有的频繁项集,效率较高。
可选地,图4所示为本申请实施例所提供的离散化的一种流程图,请参考图4,对数值类型为连续数值型的自变量进行离散化,具体为:步骤11:将连续数值型订单金额按照最细粒度分段;步骤12:根据相似度对相邻段进行合并;步骤13:对合并后形成的各个区间进行调整,使得各区间之间的分界点为整数。具体地,请参考图4,将连续数值型订单金额做分箱处理时,首先通过步骤11对连续数值型订单金额按照最细粒度进行分段,例如将[0-1000]段内的订单金额,按照5元一个步长分为200段,然后通过步骤12对相邻段根据相似度进行合并,再通过步骤13对合并后形成的各个区间进行调整,使得各区间之间的分界点为整数。由于使用相似度合并之后可能会出现例如998.7这样的分界点,为了使各个区间内的数值均能够参与备选推荐金额的选取,并使得选取的备选推荐金额便于后续计算,需要对各区间根据业务规则进行微调,将非整数的分界点调整为更便于计算以及符合业务规则的整数。
可选地,赔付成本的提升率为
满意度偏移量的计算方法为
可选地,赔付成本的提升率为
满意度偏移量的计算方法为
需要说明的是,计算满意度偏移量时,除了采用均值和中位数之外,还可以采用众数或者四分位数进行计算,当采用众数或四分位数进行计算时,其计算方法与采用均值的计算方法相同,只需将计算公式中的均值替换为众数或者四分位数即可,因此,此处不在进行赘述。
基于同一发明构思,本申请还提供一种基于不规则数据计算推荐金额的系统100,图5所示为本申请实施例所提供的基于不规则数据计算推荐金额的系统100的一种结构示意图,请参考图5,本申请实施例所提供的基于不规则数据计算推荐金额的系统100,包括:
采集模块110,用于采集订单信息、客户信息、商品信息和赔付金额;
分析模块120,用于将订单信息、客户信息、商品信息作为变量,对变量与赔付金额进行相关性分析,将影响赔付金额的变量作为自变量,根据自变量确定自变量组合;
离散化模块130,用于对自变量组合中数值类型为连续数值型的自变量进行离散化,形成多个区间;
挖掘模块140,用于设置支持度和置信度,通过支持度和置信度对各自变量组合进行频繁项集挖掘;
计算模块150,用于计算区间中各自变量的均值、中位数、众数和上下四分位数;
备选推荐金额设置模块160,用于根据均值、中位数、众数、上下四分位数和频繁项集形成区间的备选推荐金额;
目标函数设计模块170,用于设计目标函数cost=eλcost_a+ecost_b,其中,λ表示平滑系数,cost_a表示赔付成本的提升率,cost_b表示满意度偏移量;
设置模块180,用于利用目标函数遍历区间内的备选推荐金额,将使目标函数的值最小的备选推荐金额作为区间的最优推荐金额。
具体地,请参考图5,本申请实施例所提供的基于不规则数据计算推荐金额的系统100,包括采集模块110、分析模块120、离散化模块130、挖掘模块140、计算模块150、备选推荐金额设置模块160、目标函数设计模块170以及设置模块180。通过采集模块110采集订单信息、客户信息、商品信息和赔付金额,此处的订单信息、客户信息、商品信息和赔付金额均为历史信息。采集到相关信息后,通过分析模块120分析各个变量也即订单信息、客户信息、商品信息与赔付金额的相关性,得到赔付金额与订单信息、客户信息和商品信息之间的关系,并将影响赔付金额的变量作为自变量,根据所有自变量确定自变量组合。通过离散化模块130筛选自变量组合中的数值类型为连续数值型的自变量,并对连续数值型的自变量进行离散化,得到多个自变量区间。通过挖掘模块140设置支持度和置信度,例如有事项a和事项b,支持度表示a和b同时出现的概率,置信度表示a出现时b出现的概率,设置合适的支持度和置信度后,对各个区间进行频繁项集挖掘,得到自变量组合中一起出现的概率较大的变量。通过计算模块150计算区间中各自变量的均值、中位数、众数和上下四分位数,并通过备选推荐金额设置模块160,利用均值、中位数、众数和上下四分位数以及频繁项集形成该区间内的备选推荐金额。
得到备选推荐金额后,通过目标函数设计模块170设计目标函数为cost=eλcost_a+ecost_b,其中,λ表示平滑系数,通常λ的取值为0.3,cost_a表示赔付成本的提升率,cost_b表示满意度偏移量。得到目标函数后,通过赔付金额设置模块180将区间内的多个备选推荐金额分别代入目标函数,计算目标函数中cost的值,选取使得目标函数cost的值最小的备选推荐金额作为该区间内的最优推荐金额。需要说明的是,λ的值为0.3仅是在本实施例中的一种示意性说明,并不作为对本申请的限定,实际上,在不同的使用环境中,λ的值并不是完全相同的,其可以通过人工进行调整,选取使目标函数最优的一个平滑系数作为λ的值,本申请对此不进行限定。
通过以上各实施例可知,本申请存在的有益效果是:
本申请所提供的基于不规则数据计算推荐金额的方法及系统,通过综合考虑相关自变量的信息,科学的设置目标函数,可以取代业务人员繁重的工作量,能够消除人工带来的主观偏见,而且可以适应类型混杂的不规则自变量,使得目标函数可以输出具有业务可解释性的合理推荐金额。另外,通过综合考虑自变量得到的目标函数的稳定性较高,有效避免分类模型中召回率与精准率不可兼得的问题,可以使用于多种场合。此外,由于赔付成本的提升率cost_a和满意度偏移量cost_b的量纲和变化率可能会不一致,因此,本申请在设计目标函数时,使用系数λ和指数函数对目标函数进行平滑,解决由于cost_a和cost_b的量纲和变化率不一致造成无法进行计算的问题,有利于提高赔付金额的计算效率。
本领域内的技术人员应明白,本申请的实施例可提供为方法、装置、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
上述说明示出并描述了本申请的若干优选实施例,但如前所述,应当理解本申请并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本申请的精神和范围,则都应在本申请所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!