一种基于SVD的高斯混合模型参数初始化方法与流程
本发涉及到大数据分析和建模领域,尤其是涉及到一种高斯混合模型的参数初始化方法。
背景技术:
在数据驱动的人工智能时代,大数据分析和建模技术占有重要地位。当汇聚的海量数据在没有标记或者标记代价太昂贵的情况下,无监督聚类算法为解决此类问题提供了可靠的解决方案。其中,高斯混合模型(gaussianmixturemodels,gmm)利用组合高斯概率密度函数能够精准刻画数据高斯分布的特点,根据数据分属不同的模型分量,实现数据的聚类,以及异常模式数据的识别。gmm数学模型中包含多个参数,如模型分量数、模型混合系数、均值和协方差,在参数求解过程中,最常用的方法是最大期望(expectationmaximization,em)算法和变分推断(variationalinference,vi)方法。然而,这两种方法都对参数的初始值比较敏感,合理的参数初始值有利于模型快速收敛到最优值。在现有的em和vi参数推理过程中,常用的初始值设置方式包括随机初始化法、固定值初始化法、聚类初始化法等。从数据集中随机选择一个或多个数据作为参数初始值的缺点是随机性较强,导致gmm聚类的结果不固定,且有可能达不到最优;将固定值作为参数初始值的缺点是主观性较强,导致gmm聚类的结果达不到最优;而将聚类算法的结果作为参数初始值,一方面聚类过程增加了参数求解的复杂度,另一方面,像kmeans聚类算法需要输入一些参数初始值,仍然没有解决参数初始值根据数据特点自适应设置的问题。
因此,为了解决gmm参数初始值自适应设置问题,本发明提出了一种基于svd的高斯混合模型参数初始化方法,利用svd技术分解数据矩阵,对数据集进行初始聚类,确定gmm模型分量数的初始值,进而确定gmm模型混合系数、均值和协方差初始值,再基于em和vi算法推理出gmm模型参数的最优值。
技术实现要素:
本发明为了克服现有技术的不足,本发明提供了一种基于svd的高斯混合模型参数初始化方法。
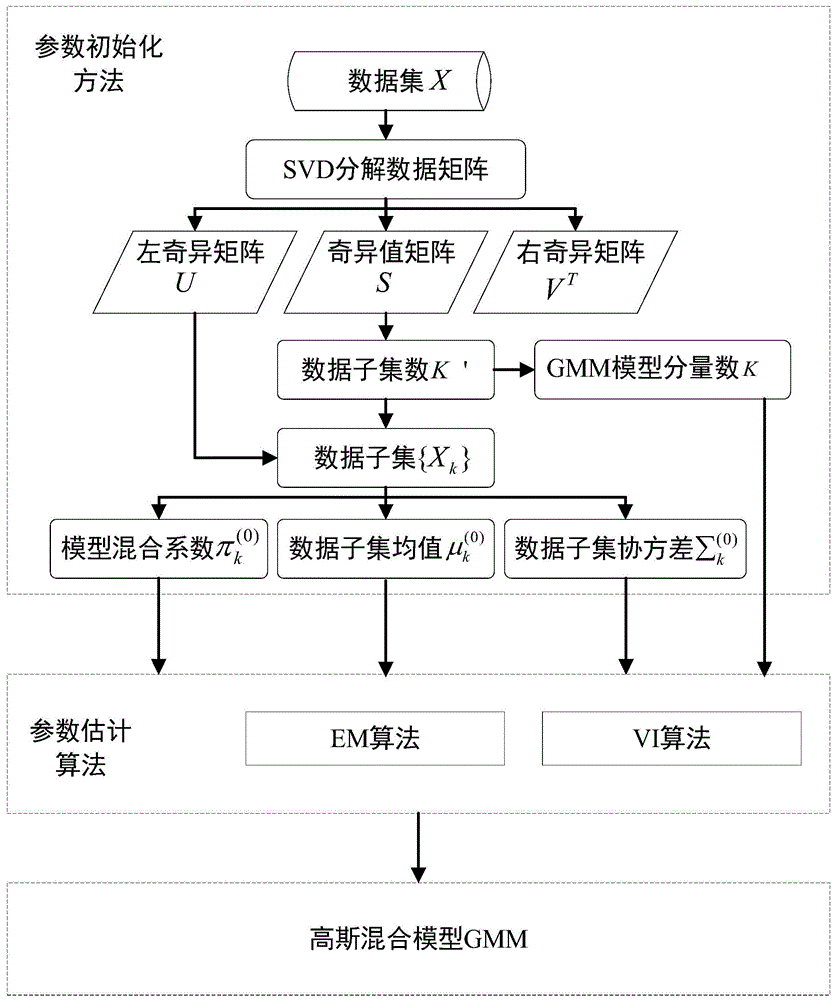
在数据驱动的人工智能时代,大规模数据的采集和分析成为一种有效的技术手段,而在网络安全领域,通过网络流量大数据的分析和建模,实现网络威胁的检测和预测,具有重要意义。在针对海量高维网络流量大数据建立高斯混合模型检测网络中的威胁时,提出一种基于svd的高斯混合模型参数初始化方法。本发明采用的技术方案是:步骤一:针对海量高维网络流量数据集x,包含n个样本,数据维度为d,数据集合分为k个类别,包括正常流量种类和威胁流量种类;利用svd技术分解数据矩阵x,x=usvt;
其中,u是n×n的正交矩阵,也称为左奇异矩阵;s是n×d的对角奇异值矩阵,其对角线上的元素为x的奇异值,并按照从大到小的降序排列;vt是d×d的正交矩阵,是v的转置,也称为右奇异矩阵;
步骤二:针对网络流量数据集x,采用gmm建立模型刻画数据特点,gmm的模型分量数与数据集x的流量类别数相等,因此,根据奇异值矩阵得到gmm的模型分量数初始值;
利用奇异值矩阵元素下降趋势、前n个元素之和代表奇异值矩阵大部分信息以及数据矩阵的维度,进而确定奇异值矩阵中保留的奇异值元素数目,将其作为原始数据矩阵的初始聚类数;由于每一个聚类数据由一个gmm分量描述,则初始聚类数与模型分量数相等,得到gmm模型分量数的初始值;
步骤三:根据左奇异矩阵得到网络流量数据集x的初始聚类子集,从而实现将网络流量数据集初步划分到多个类别聚类,同时,得到每个gmm模型分量的初始数据集合;
在确定奇异值矩阵中保留的奇异值元素数目之后,能够确定奇异值矩阵的规模,对应地确定左奇异矩阵的规模;在左奇异矩阵中,查找每一列数据中的最大值,并将最大值对应的列序号相同的原始数据聚为一类,实现将数据集的初始聚类;
步骤四:根据初始聚类子集,得到gmm的每个模型分量混合系数,用于表示gmm模型对每个网络流量数据聚类的刻画权重;
gmm模型分量混合系数表示初始聚类子集中的数据被聚类到相应模型分量的概率,因此将每个模型分量描述的初始聚类中子集的长度与原始数据集的长度比值,作为每个模型分量混合系数的初始值。
将这些参数初始值输入到em和vi算法中,进一步求解出参数的最优值,最终得到最优的gmm聚类模型。
作为优选,所述的根据奇异值矩阵得到gmm的模型分量数初始值,根据左奇异矩阵得到原始流量数据集的初始聚类子集,即初始把流量数据集分为正常类别集合和威胁类别集合,具体为:
由于s中对角线元素si按照从大到小的降序排列,保留最大两个奇异值元素代替奇异值矩阵的全部信息,作为奇异值矩阵s的近似矩阵s';另外,s矩阵的维度也与元素的下降趋势有关;因此,定义保留的奇异值矩阵的元素数量k'为
其中,
作为优选,根据初始聚类子集,得到gmm的每个模型分量混合系数、均值和协方差初始值,具体为:
原始数据集被分成了k个初始聚类,每个聚类中包含的数据子集为{xk},k=1,2,…,k,第k个子集的长度为len(xk);
对gmm分量的混合系数πk初始化,πk表示数据被聚类到第k个模型分量的概率,每个分量的混合系数与初始聚类中子集的长度以及数据集总长度有关,因此,定义第k个混合系数初始值为
gmm分量的均值μk初始化,原始数据集被分成了k个初始聚类,则第k个初始聚类中包含的数据子集为{xk},gmm通过构建多个分量来刻画每个聚类,则第k个分量中数据子集的均值表示为
gmm分量的协方差∑k初始化,原始数据集被分成了k个初始聚类,则第k个初始聚类中包含的数据子集为{xk},gmm通过构建多个分量来刻画每个聚类,则第k个分量中数据子集的协方差表示为
与现有技术相比,本发明的有益效果是:(1)相比较于随机初始化法和固定值初始化法,svd初始化方法不依赖系统随机性和人为主观性,能够通过算法客观、自动地计算出参数的初始值;(2)相对于聚类初始化方法,svd初始化方法计算复杂度较低、消耗的时间和系统资源较少,能够快速地得到参数的初始化值;(3)svd能够分解各种特点的数据矩阵,如离散型数据、连续型数据、离散与连续混合型数据、稀疏矩阵、高维等,对不同应用场景的数据分析和建模具有较强的适应性。
附图说明
图1:基于svd的高斯混合模型参数初始化流程图
具体实施方式
如图1所示,基于svd的高斯混合模型参数初始化方法具体实施方式包括如下:
假设海量高维网络流量数据集x,x=(x1,x2,…,xn,…xn),包含n个样本,即数据集合长度为n,数据维度为d,数据集合分为k个类别,则构建gmm模型的概率密度函数为
其中,k为gmm的分量数目,πk为第k个gmm分量的混合系数,满足约束条件为0≤πk≤1和
本发明采用基于svd的高斯混合模型参数初始化方法,具体过程如下:
(1)基于svd的矩阵分解。采用svd分解技术对数据矩阵x进行分解x=usvt,其中,u是n×n的正交矩阵,也称为左奇异矩阵;s是n×d的对角奇异值矩阵,其对角线上的元素为x的奇异值,并按照从大到小的降序排列;vt是d×d的正交矩阵,是v的转置,也称为右奇异矩阵。
(2)gmm模型分量k初始化。由于s中对角线元素si按照从大到小的降序排列,通过s0/s1的比较,发现奇异值元素的下降趋势,而且前面少数元素之和占全部元素之和较为接近,所以保留前面少量奇异值元素代替奇异值矩阵的全部信息,作为奇异值矩阵s的近似矩阵s'。另外,s矩阵的维度也与元素的下降趋势有关。因此,定义保留的奇异值矩阵的元素数量k'为
其中,
(3)在第(2)步中,原始数据集被分成了k个初始聚类,每个聚类中包含的数据子集为{xk}(k=1,2,…,k),第k个子集的长度为len(xk)。
(4)gmm分量的混合系数πk初始化。πk表示数据被聚类到第k个模型分量的概率,每个分量的混合系数与初始聚类中子集的长度以及数据集总长度有关,因此,定义第k个混合系数初始值为
(4)gmm分量的均值μk初始化。在第(2)步中,原始数据集被分成了k个初始聚类,则第k个初始聚类中包含的数据子集为{xk},gmm通过构建多个分量来刻画每个聚类,则第k个分量中数据子集的均值表示为
(5)gmm分量的协方差∑k初始化。在第(2)步中,原始数据集被分成了k个初始聚类,则第k个初始聚类中包含的数据子集为{xk},gmm通过构建多个分量来刻画每个聚类,则第k个分量中数据子集的协方差表示为
通过上述步骤,在得到gmm个参数的初始值之后,将参数的初始值输入到em和vi算法,进一步推理求解出模型的最优参数,使得gmm聚类的效果最优。
- 还没有人留言评论。精彩留言会获得点赞!