一种基于双循环转录网络的车牌字符识别方法与流程
本发明涉及计算机视觉和模式识别技术领域,具体涉及一种基于双循环转录网络的车牌字符识别方法。
背景技术:
在很多深度学习任务中,训练集中存在某些类别下的样本数远大于另一些类别下的样本数,这就是样本失衡。样本失衡问题在车牌数据集上尤为明显。对于单排字符车牌,第一位的字符为省份字符,第二位至第七位字符为英文和数字字符,在车牌数据集中,数字和英文字符数量是汉字字符的数倍,因此存在严重的样本失衡问题,其中样本数目较少的类别被称为困难样本,样本数目较多的类别称为简单样本。样本失衡问题将导致车牌字符识别精度低的问题。
传统方法通过对困难样本增加权重来加强对困难样本的学习,但对于序列字符识别,该方法并不适用。因此本专利提出一种基于双循环转录网络的车牌字符识别方法来解决在车牌数据集中的样本失衡问题。
技术实现要素:
本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于双循环转录网络的车牌字符识别方法。
本发明的目的可以通过采取如下技术方案达到:
一种基于双循环转录网络的车牌字符识别方法,所述的车牌字符识别方法包括构建、训练双循环转录网络和应用双循环转录网络进行车牌识别,其中,所述的构建、训练双循环转录网络包括以下步骤:
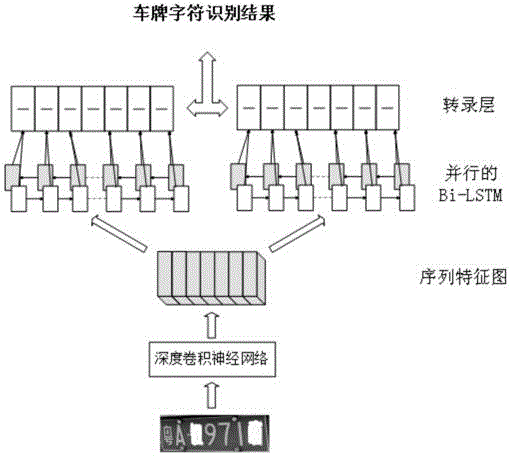
s1、使用卷积层、池化层、relu层构造深度卷积神经网络,对车牌图像进行特征提取,得到包含相对位置信息和时序信息的序列特征图x={x1,x2,…xi…,xt},其中xi∈r256,xi表示序列特征图的第i帧序列,t表示序列特征图宽度;
s2、构建bi-lstm(bi-directionallongshort-termmemory),将序列特征图全部输入到bi-lstm,得到车牌字符置信度估计序列p={p1,p2,…,pt},其中t表示置信度估计序列p的长度,p和x长度相等,所述的bi-lstm由两个并行的循环层构成,两个循环层传播方向相反,每个循环层由t个lstm单元链式连接而成,lstm单元内含有输入门和输出门,将序列特征图的第i,i=1,2,…,t帧序列xi对应输入到第i,i=1,2,…,t个lstm单元的输入门,然后用softmax激活函数对lstm输出门输出的值进行转化,得到车牌字符置信度估计序列p;
s3、构建转录层,对车牌字符置信度估计序列p进行映射,得到预测标签序列;
s4、构建双循环转录网络,双循环转录网络由一个深度卷积神经网络和两个并行排列的bi-lstm构成,两个bi-lstm分别称为第一bi-lstm和第二bi-lstm,深度卷积神经网络输出的序列特征图x分别输入第一bi-lstm和第二bi-lstm,对第一bi-lstm输出的车牌字符置信度估计序列进行转录,得到汉字字符预测标签序列,对第二bi-lstm输出的车牌字符置信度估计序列进行转录,得到英文字符和数字字符的预测标签序列;
s5、用含有汉字字符的车牌图像对深度卷积神经网络和第一bi-lstm进行训练,得到深度卷积神经网络的参数和第一bi-lstm的参数,固定深度卷积神经网络的参数,用含有英文字符和数字字符的车牌图像对第二bi-lstm进行训练,得到第二bi-lstm的参数;
所述的应用双循环转录网络进行车牌识别,包括以下步骤:
t1、将待识别的车牌图像输入训练完成的双循环转录网络,对第一bi-lstm和第二bi-lstm输出的车牌字符置信度估计序列分别进行转录,得到第一预测标签序列和第二预测标签序列;
t2、合并第一预测标签序列和第二预测标签序列,得到最终的车牌字符识别结果。
进一步地,所述的转录层用于对车牌字符置信度估计序列p进行映射,得到预测标签序列,定义车牌字符类别集合l={0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f,g,h,j,k,l,m,n,p,q,r,s,t,u,v,w,x,y,京,津,晋,冀,蒙,辽,吉,黑,沪,苏,浙,皖,闽,赣,鲁,豫,鄂,湘,粤,桂,琼,渝,川,贵,云,藏,陕,甘,青,宁,新,学,挂,使,警,港,澳},因为车牌图像中相邻两个车牌字符之间没有字符,所以字符类别集合l中插入空白字符,其中空白字符用”-”符号表示,得到车牌字符类别集合l′,其中l′=l∪{“-”};对车牌置信度估计序列p做b变换,得到预测标签序列,定义b变换的输入为m序列,输出为n序列,m序列和n序列中的所有字符选自车牌字符类别集合l′,定义b变换规则如下:当输入的m序列中存在相邻的相同字符时,对相同字符进行合并,当输入的m序列中有”-”字符时,无论”-”字符的相邻字符是否为相同字符,直接将”-”字符删除,同时将”-”字符的相邻字符保留,最后m序列筛选后剩余的字符组合成输出的n序列,其中n序列的长度小于m序列的长度;
对车牌字符置信度估计序列p进行b变换,得到预测标签序列。
进一步地,合并第一预测标签序列和第二预测标签序列的方式包括以下三种情况:
情况(1):第一预测标签序列为省份字符,第二预测标签序列为英文字符和数字字符,合并方式为省份字符在前,英文字符和数字字符在后;
情况(2):第一预测标签序列为车牌类别字符和省份字符,第二预测标签序列为英文字符和数字字符,合并方式为省份字符在前,英文字符和数字字符在中,车牌类别字符在后;
情况(3):第一预测标签序列和第二预测标签序列都为英文字符和数字字符,将第一预测标签序列作为最终的车牌字符识别结果;
其中,情况(1)对应普通车牌和新能源车牌,该普通车牌包括蓝牌和黄牌,情况(2)对应港澳车牌、教练车牌、拖挂车牌、使馆车牌,情况(3)对应警队车牌、军队车牌。
本发明相对于现有技术具有如下的优点及效果:
1、本发明提出的一种基于双循环转录网络的车牌字符识别方法,通过采用两个并行的bi-lstm对样本失衡类别分别进行预测,提高车牌字符识别准确率。
2、本发明提出的一种基于双循环转录网络的车牌字符识别方法,通过bi-lstm处理具有时序信息的特征图,提高车牌字符识别的准确率。
附图说明
图1是本发明实施例公开的一种基于双循环转录网络的车牌字符方法中双循环转录网络结构图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
本实施例公开了一种基于双循环转录网络的车牌字符识别方法,该车牌字符识别方法包括构建、训练双循环转录网络和应用双循环转录网络进行车牌识别。
本实施例中,构建、训练双循环转录网络包括以下步骤:
s1、使用卷积层、池化层、relu层构造深度卷积神经网络,对车牌图像进行特征提取,得到包含相对位置信息和时序信息的序列特征图x={x1,x2,…xi…,xt},其中xi∈r256,xi表示序列特征图的第i帧序列,t表示序列特征图宽度;
s2、构建bi-lstm(bi-directionallongshort-termmemory),将序列特征图全部输入到bi-lstm,得到车牌字符置信度估计序列p={p1,p2,…,pt},其中t表示置信度估计序列p的长度,p和x长度相等,所述的bi-lstm由两个并行的循环层构成,两个循环层传播方向相反,每个循环层由t个lstm单元链式连接而成,lstm单元内含有输入门和输出门,将序列特征图的第i,i=1,2,…,t帧序列xi对应输入到第i,i=1,2,…,t个lstm单元的输入门,然后用softmax激活函数对lstm输出门输出的值进行转化,得到车牌字符置信度估计序列p;
这里通过采用lstm单元,可以解决双循环转录网络在训练时出现梯度消失和梯度爆炸的问题,同时可以捕获序列特征图内的时序信息,增强双循环转录网络的拟合能力。
s3、设计转录层,对车牌字符置信度估计序列p进行映射,得到预测标签序列。
定义车牌字符类别集合l={0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f,g,h,j,k,l,m,n,p,q,r,s,t,u,v,w,x,y,京,津,晋,冀,蒙,辽,吉,黑,沪,苏,浙,皖,闽,赣,鲁,豫,鄂,湘,粤,桂,琼,渝,川,贵,云,藏,陕,甘,青,宁,新,学,挂,使,警,港,澳},因为车牌图像中相邻两个车牌字符之间没有字符,所以字符类别集合l中插入空白字符,其中空白字符用”-”符号表示,得到车牌字符类别集合l′,其中l′=l∪{“-”};对车牌置信度估计序列p做b变换,得到预测标签序列,定义b变换的输入为m序列,输出为n序列,m序列和n序列中的所有字符选自车牌字符类别集合l′,定义b变换规则如下:当输入的m序列中存在相邻的相同字符时,对相同字符进行合并,当输入的m序列中有”-”字符时,无论”-”字符的相邻字符是否为相同字符,直接将”-”字符删除,同时将”-”字符的相邻字符保留,最后m序列筛选后剩余的字符组合成输出的n序列,其中n序列的长度小于m序列的长度;
假设π1和π2为车牌字符置信度估计序列,对π1做b变换:
b(π1)=b(”-”“-”stta”-”t”-”“-”“-”e)=state
对π2做b变化:
b(π2)=b(”-”sta”-”atte”-”e”-”)=staatee
对车牌字符置信度估计序列p进行b变换,得到预测标签序列。
s4、搭建双循环转录网络,双循环转录网络由一个深度卷积神经网络和两个并行排列的bi-lstm构成,两个bi-lstm分别称为第一bi-lstm和第二bi-lstm,深度卷积神经网络输出的序列特征图x分别输入第一bi-lstm和第二bi-lstm,对第一bi-lstm输出的车牌字符置信度估计序列进行转录,得到汉字字符预测标签序列,对第二bi-lstm输出的车牌字符置信度估计序列进行转录,得到英文字符和数字字符的预测标签序列。
s5、对含有汉字字符的车牌图像进行训练,得到深度卷积神经网络的参数和第一bi-lstm的参数。固定深度卷积神经网络的参数,用含有英文和数字字符的车牌图像对第二bi-lstm进行训练,得到第二bi-lstm的参数。
本实施例中,应用双循环转录网络进行车牌识别,包括以下步骤:
t1、将待识别的车牌图像输入训练完成的双循环转录网络,对第一bi-lstm和第二bi-lstm输出的车牌字符置信度估计序列分别进行转录,得到第一预测标签序列和第二预测标签序列;
t2、合并第一预测标签序列和第二预测标签序列,得到最终的车牌字符识别结果。
合并第一预测标签序列和第二预测标签序列的方式包括以下三种情况:
情况(1):第一预测标签序列为省份字符,第二预测标签序列为英文字符和数字字符,合并方式为省份字符在前,英文字符和数字字符在后;
情况(2):第一预测标签序列为车牌类别字符和省份字符,第二预测标签序列为英文字符和数字字符,合并方式为省份字符在前,英文字符和数字字符在中,车牌类别字符在后;
情况(3):第一预测标签序列和第二预测标签序列都为英文字符和数字字符,将第一预测标签序列作为最终的车牌字符识别结果;
其中,情况(1)对应普通车牌(蓝牌、黄牌)和新能源车牌,情况(2)对应港澳车牌、教练车牌、拖挂车牌、使馆车牌,情况(3)对应警队车牌、军队车牌;
通过第一bi-lstm来对车牌图像中的汉字字符进行识别,第二bi-lstm来对车牌图像中的英文字符和数字字符进行识别,有效解决了在车牌字符识别中训练样本失衡问题。
仿真生成110万虚拟车牌数据集,其中100万张虚拟车牌图像用于训练集,10万张虚拟车牌图像用于测试集,对比双循环转录网络和工业界常用的crnn网络在验证集和测试集上的识别准确率,crnn网络在验证集上的准确率为98.7%,在测试集上为68%,双循环转录网络在验证集上的准确率为98.9%,在测试集上准确率为95%,本发明提出双循环转录网络在验证集和测试集上的识别准确率都更高,验证了本发明的有效性。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!