一种植物品种DUS测试方法与流程
本发明属于植物品种dus测试技术领域,主要针对dus测试中获取的数据进行处理分析、实现dus判定、和优化dus测试指南以及试验设计的方法。
背景技术:
植物品种特异性(distinctness)、一致性(uniformity)和稳定性(stability)测试(简称dus测试)是指采用相应的测试技术与标准,通过种植试验或室内分析对植物品种的特异性、一致性和稳定性进行评价的过程。dus测试是各国品种管理的基本技术依据,是植物新品种保护、品种审定或登记的必要条件。对于植物选种、育种,推动种子工程建设,促进农林业生产的发展有着重要的意义。
特异性是指一个植物品种有一个以上性状明显区别于已知品种。一致性是指一个植物品种的特性除可预期的自然变异外,群体内个体间相关的特征或者特性表现一致。稳定性是指一个植物品种经过反复繁殖后或者在特定繁殖周期结束时,其主要性状保持不变。
国际上,dus测试的历史是与植物新品种保护制度的历史是同步的。1957年2月,法国政府邀请12个西欧国家参加同年5月在巴黎举行的外交大会,探讨建立一个专门的植物新品种保护制度。1961年底在巴黎召开的第二届外交大会上通过了“植物新品种保护国际公约”,并据此成立“国际植物新品种保护联盟(upov)”。该公约分别于1972年、1978年和1991年进行了三次修订,形成目前最完善的dus术语名词和定义。upov汇总其成员dus测试经验,组织起草并逐步采纳了15个tgp技术文件和323个dus测试指南,全面规范了dus测试的基本概念和原理、已知品种确认及品种库构建与维护、测试经验与合作、dus测试指南研制、试验设计与统计分析、dus审查程序、新植物类型测试指导、分子技术应用原则等内容。
中国于1997年3月20日颁布《植物新品种保护条例》,将dus列为品种授权的必要实质条件,整个条例内容是参考upov1978年文本制定,dus的定义是参考upov1991年文本制定。1999年4月23日中国加入upov公约1978年文本,成为upov第39个成员,同年开始接收植物新品种权申请。2000年9月29日,原农业部在全国建立1个dus测试总中心和14个分中心,具体承担植物新品种dus测试工作。2015年11月4日,新修订的《种子法》首次将植物新品种保护纳入品种管理范围,并将dus测试规定为品种审定和登记的前置条件。随着dus测试工作量的不断增加,原农业部后来又陆续新建了13个分中心和3个测试站。截止目前,农业农村部一共发布159个植物保护目录,将玉米等5个作物列入品种审定目录,将马铃薯等29个作物列入品种登记目录。
虽然upov发布了一整套dus测试指导文件,但并没有提供具体的操作方法。英国的dust统计分析软件和法国的gaia品种管理软件是目前仅有的两款在upov范围内免费共享的软件,但前者仅涉及数理统计分析功能且操作繁琐,后者仅涉及品种描述分析功能且权重设置主观性强,两者使用起来都有局限性。
近年来,各国代表在upov技术工作组年度会议上都交流了自己的数据分析方法,但主要集中在统计分析方面,功能分散,操作步骤多,尤其缺乏原始数据的质量控制方法,导致分析结果不稳定、分析效率低。
一直以来,本发明人不断深入研究,发明了一套全面的dus分析方法,只需一套固定性状参数,就可以对不同地点和年份的数据进行汇总分析,得出科学准确的测试结果,同时分析速度大大加快。
技术实现要素:
为高效分析植物品种dus测试数据,提高dus测试的试验水平和评价质量,同时为dus判定提供全面、准确的依据,本发明人开发了一套植物品种dus测试试验及数据分析和评价方法。并且,本发明人开发的数据分析方法可以借助excel程序方便地实现。
鉴于此,本发明提供如下技术方案:
一种植物品种dus测试方法,包括进行植物种植试验、以统一的格式采集和处理试验数据、以及进行dus分析,所述植物种植试验中的品种类型包括待测品种、标准品种和任选的近似品种;其特征在于,所述以统一的格式采集和处理试验数据包括将性状原始数据转化成代码的步骤;该步骤包括:
对于每个目测性状vg和vs原始数据,直接赋予对应的代码,进行植物品种dus测试;
对于每个测量性状mg和ms原始数据,进行频率分布分析,包括:选择任意一次试验的性状原始数据或者任意多次试验的性状原始数据进行lsd分析(任何一次或多次试验数据均可,尽可能品种数量多的试验,计算一次即可,无需每次试验都计算),获得测量性状的lsd0.05值;求出所有品种的所有测量性状原始数据的平均值;以所有品种的测量性状原始数据平均值为中心标准值,以2倍lsd0.05为级差,设定各级标准值;以各级标准值为中心,向两侧各延伸1/2级差所构成的区间,设为每个代码的分级区间;每个区间的最小值,作为分级值;统计各分级区间的品种数和百分比;
(2)确定标准值、分级值和区间代码,包括:根据统计结果,判定总区间覆盖范围是否小于3级或者大于9级;小于3级的性状剔除,不适宜用于植物品种dus分析;大于9级的性状,调增lsd0.05的倍数,并参考各分级区间百分比是否均匀来调整分级,使得分级范围处于9级以内;处于3和9级之间的性状,可以在两端各空出1-2级以便将来出现新品种时使用;如果最小分级区间最小值小于零,则将最小分级区间的最小值设置为0,再按照前面确定的倍数的lsd0.05从小到大进行分级,重新确定标准值;优选地,将得出的标准值精确到合适的小数点位数(例如0位小数,即取整);
选择测量性状实测值处在各级标准值或其附近的一个植物品种作为相应分级区间的标准品种,误差较大时,适当平移标准值,使标准品种实测值与其对应的标准值接近,由此最终形成一套相对固定的标准值和标准品种。标准品种的选取应兼顾品种的适应能力、繁殖材料的可获得性和表达状态的代表性进行选择。
在不同的测试试验中,标准值通常保持不变,可在后续步骤中进行验证,当出现不合适的情形,例如有新的表达状态出现,再重新调整、确定。标准品种通常也保持不变,在每次试验中重复种植。标准品种的实测值及由其决定的分级值会随着试验而变化。
基于所给出的分级区间和代码,将试验中的测量性状mg和ms原始数据代码化,获得区间代码,区间代码可以直接用于植物品种dus分析,或者将区间代码进一步优化处理后,用于植物品种dus分析。
优选地,在上述植物品种dus测试方法中,以统一的格式采集和处理试验数据包括:制作统一的表格、设置统一的数据格式(如数据类型)、数值范围和任选的数值单位等,对试验数据和统计假设有效性进行检验;
所述对试验数据有效性进行检验包括:进行数据格式、数值范围和/或任选的数值单位匹配检验,所述检验借助程序在输入时或输入后对数据自动进行,若出现输入的数据与所设置的数据格式、数值范围和/或任选的数值单位不相符,则表明出现异常值,若出现异常值,则对异常值进行自动标识。
优选地,所述植物种植试验可以仅进行一期试验。优选地,所述植物种植试验进行两期或两期以上试验。一年生或两年生植物一个完整的繁殖周期是从播种到收获的时间,多年生植物是正常开花结果年份从发芽到收获的时间。植物生长受温度、雨量和光照影响较大,年度间会表现较大差异,一个年份往往不能准确判定品种描述和差异。所以dus测试一般需要两个生长周期,对于那些一致性较差、品种间差异较小的作物或品种(如牧草),往往需要3个生长周期,对于那些无性繁殖、可控环境种植(温室)、品种差异明显的作物或品种(如蝴蝶兰),1个生长周期也可以结束dus测试。
稳定性测试一般取同一品种不同世代的种子进行种植试验分析。如果下一代种子与上一代种子性状表达状态一致,并且都具备一致性,则表示该品种具备稳定性。如果一个品种在某次试验中具备了一致性,也就意味着具备了稳定性。
杂交品种的一致性和稳定性也可以通过测试亲本的一致性或稳定性进行判断。
已知品种是指已受理申请或者已通过品种审定、品种登记、新品种保护,或者已经销售、推广的植物品种。待测品种是指申请品种权保护、审定或登记的品种,或者是从市场上抽检待评价的品种。近似品种:是指为了特异性测试而从品种库中筛选出来的与待测品种在表型或者分子特征上相近、需要在田间种植试验中进一步验证的品种。标准品种:是指在种植试验中用于评价环境影响、指明性状表达状态的已知品种。
性状按表达类型可以分为质量性状(ql)、假质量性状(pq)和数量性状(qn)。按观测类型分为目测(v)和测量(m)。按记录类型分为群体(g)和个体(s)。按观测类型和记录类型组合可分为群体目测(vg)、群体测量(mg)、个体目测(vs)、个体测量(ms)。
表达状态:植物品种dus测试指南或标准中,将每个测试性状的表达范围划分为一系列表达状态。为便于定义性状和规范描述,每个表达状态赋予一个相应的数字代码,以便于测试数据记录、处理和品种描述。
优选地,所述制作统一的表格包括制作统一的参数表,所述参数表中至少包括以下参数的字段:代码、标准值、表达状态、标准品种、性状编号、性状名称、数值类型;优选地,所述参数表中还包括选自以下的一种或多种参数字段:表达类型、观测类型、观测时间、数量单位、分级值、极大值、极小值、代码索引、分级值索引、分组、权重、阈值和照片。
其中,性状编号、代码、表达状态、标准品种、性状名称、表达类型、观测类型、观测时间、数量单位、数值类型、极大值、极小值参数可根据dus测试指南进行预设。
标准值按照上述方法确定。
标准品种的实测值为本次试验中测得的数据。
代码索引是为每个代码设置一个识别码,可设置为由“性状编号*10000+代码”组合而成,便于后面通过性状编号和代码提取对应信息。
分级值索引是为每个代码设置的另一个识别码,可设置为由“性状编号*10000+分级值”组合而成,便于区间法将原始值转换成代码。
分级值用于设置原始值对应代码的分级区间,是每个代码对应分级区间的最小值。
代码索引、分级值索引、分级值由标准值和实测值按预设的公式自动计算得到。
分组:在分组程序中用到。分组依据是分组性状,在dus测试指南中有记载。但考虑实际使用效果,可重新选用表达状态离散、易于区分、能够准确观测的质量性状和/或假质量性状作为分组性状。
权重在计算品种价值中用到,根据经验设定。例如生育期重要,权重为3,性状不太重要,权重为1,在品种价值评价中给出分值中适用,从技术角度评价品种种植的意义。
阈值在阈值法筛选近似品种用到。根据多年数据变异情况凭经验设定。例如,预先将质量性状设置为0,假质量性状设置为1,数量性状设置为2。如果在样品增加或技术改进后,发现预设的阈值不合适,可以进行适当的调整。
照片:对于每个拍摄的对象类型,人工预先赋予特定字符(例如数字编号),并以该字符对照片进行命名,如玉米照片分为幼苗、植株、雄穗、花丝、果穗五个类型照片,分别以1、2、3、4、5进行编号,照片以这些编号进行命名,例如1.jpg,表示幼苗照片。
为方便分析处理,可优化照片的存储管理,按统一的方法建立各级文件夹,例如照片\玉米\2019\品种名,将照片存入对应品种名的文件夹中。
根据对应关系,将用于命名照片的字符(如编号数字),输入到相应性状的照片字段内,并与相应的照片链接。
为了与其他系统衔接,存在需要统一修改照片名称或文件夹名称的情况。此时,按照旧名称、文件类型、文件地址、新名称的字段格式制作表格,输入照片新名称,通过程序链接文件夹和/或照片,可以完成文件或文件夹批量更名。
作为示例,如表1所示。
表1
关于数据格式(例如数据类型)、数值范围和任选的数值单位等的设置,可利用表格或数据库自带功能设置数据类型,以excel单元格为例,数据类型有任意数、整数、小数、序列、日期、时间、文本长度等。对于代码型目测数据,可以选择序列,并在数据来源里填入允许的代码值;对于连续型测量数据,可以选择小数,并在数据来源中填入允许的最小值和最大值;对于离散型测量数据,可以选择整数,并在数据来源中填入允许的最小值和最大值;对于日期型数据,可以选择日期,并在数据来源中填入开始日期和结束日期;对于比色卡型数据,可以选择文本长度,并在数据来源中填入最小长度4和最大长度5,等等。数值范围以玉米株高为例,可设置为30-500,根据需要设置数值单位,如cm。
优选地,采用统一格式的表格采集数据;例如,采用横排数据表或竖排数据表采集数据,优选地,采用横排数据表采集数据;所述横排数据表的格式为:按照待测、品种、试验、性状编号的字段进行横排,当针对同一性状测定了多个单株样本值时,同一性状编号连续重复横排;同一试验下的同一品种只列出一次,不能出现重复。
所述竖排数据表的格式为:按待测、品种、试验、性状、同一性状各单株样本编号的字段进行横排,而将性状编号作为数据竖排。
各表格中,待测字段下用“是”标识的品种表示需要待测试评价并需要出具分析报告的品种,其他品种用“否”表示,例如标准品种、近似品种,并非被测试评价品种,不需要针对其出分析报告。
优选地,在上述植物品种dus测试方法中,若在数据类型、数值范围和/或任选的数值单位匹配检验时出现异常值,则人工检查原始记录或田间样本;如果属于输入错误,则直接改正;如果属于客观事实,则保留该异常数据,继续进行之后的步骤。
优选地,在上述植物品种dus测试方法中,所述对试验数据有效性进行检验还包括采用boxplot法(箱线图法)和/或3σ法(三倍标准差法)进行检验,对试验中采集的多个样本的ms数据进行检验;若出现异常值,则进行自动标识,并人工介入判断异常原因,并进行弃用、补测或纠正处理。
优选地,采用竖排数据表进行boxplot法和/或3σ法检验;当数据采用横排数据表采集时,可以通过设计的程序将其转化为竖排数据表。
对于重复取样测量的性状,采用boxplot或3σ法可更精确地检验异常值,前者极端值不参与计算,后者极端值参与计算,两种方法互补。
经两种方法检验,仍为异常值,需要人工检查原始记录或田间样本,如属于输入错误,直接改正。属于客观事实的情况下,如果只有极少数(例如两个以内)无法说明原因的异常值,可以通过程序提供前后值的平均数进行修正(其他计算法例如整体平均值、极大似然法估算缺失值并不适用于dus测试数据的修正,采用该株附近株的试验结果估算缺失值,更能反映试验真实情况)。如果异常值较多,则不处理,可以考虑用相对方差法或者coyu法检验一致性。异常值也可能是环境或者取样方式造成的,如地力不均匀,环境不一致,或者取样没排除边际植株。这就需要优化试验设计和取样方式,必要时,扩大取样数量。
上述两种检验方法可在同一数据格式下进行,并用不同颜色标识出各种异常值。
优选地,上述频率分布分析在横排跨试验数据表中进行,在对一次试验ms性状数据进行频率分布分析时,从横排数据表中直接提取待测、品种、性状编号及其原始值到横排跨试验数据表中;在针对两次或两次以上试验ms性状数据进行频率分布分析时,从横排数据表中提取待测、品种、性状编号,并计算各性状的试验平均值,一并转入至横排跨试验数据表中,所述横排跨试验数据表格式为:待测、品种、同一性状不同试验的平均值或不同植株的原始值连续横排。
优选地,在上述植物品种dus测试方法中,对于mg、ms性状,在所采用的一套标准值不是由本次试验数据得到的情况下,还包括检验标准品种在本次试验中与获得所述一套标准值的试验中表现是否一致的步骤,该步骤包括:将本次试验中标准品种实测值同与其相对应的标准值进行比较,两者差值的绝对值除以标准值,若该值大于10%,则确认为异常值,对其进行标识(例如标识为特定的颜色);对于出现异常值的情况,人工判定是否属于可接受的异常情况,如果某个性状多个标准品种均因某种因素出现类似的变化,则认定为属于可接受的异常;如果该性状出现异常情况的标准品种与其他标准品种变化不一致,则需要剔除该标准品种实测值。
优选地,所述检验标准品种在本次试验与获得所述一套标准值的试验中表现是否一致的步骤中,在竖排处理数据表中计算本次试验中性状的实测值、标准差、样本数,把标准品种实测值提取到参数表中进行检验;所述竖排处理数据表可由竖排数据表转化而来,所述竖排处理数据表的格式为:待测、品种、试验、性状横排,并将竖排数据表中同一ms性状多个样本值处理成平均值、标准差、样本数,并预留区间代码、已知代码、回归代码、优化代码、表达状态的字段,将这些字段横排。
优选地,对于mg、ms性状,在所采用的一套标准值不是由本次试验数据得到的情况下,还包括利用标准品种矫正分级范围的步骤,该步骤包括:分级值第一个为零,第二个以下分别为:各标准品种的(实测值-标准值)/标准值所得值之和除以标准品种个数,再加上本代码对应标准值与前一代码对应标准值之和的1/2。
优选地,在上述植物品种dus测试方法中,对于数量性状,还包括利用已知品种(包括标准品种和/或近似品种)的已知代码与本次实验中该已知品种的相应平均值建立线性回归函数,并将待测品种的在本次试验中的原始数据平均值代入该回归函数,求出其回归代码;并对区间代码、已知代码、和回归代码进行分析,选取其中的众数代码、中间数代码或三者的平均数代码作为进一步优化的代码数据。
优选地,在上述植物品种dus测试方法中,当至少存在区间代码、已知代码、回归代码中的两种代码时,还包括采用代码极差进行检验步骤,该检验步骤包括:由这些代码中的最大值减最小值计算极差,对不同大小的极差进行不同的标识;例如,差1个代码显示黄色,差2个代码显示橙色,差3个代码显示红色,差4个及以上的代码显示紫色,对于标识的代码数据,人工检查原始数据,或调取照片确认,并根据需要人工修改优化的代码数据。
优选地,在上述植物品种dus测试方法中,还包括将多个试验的优化代码放在一起进行比较,运用最大值-最小值所得的代码极差对代码进行检验,根据极差大小,进行不同的标识,例如以不同的特定颜色显示,并对标识的代码数据,人工检查原始数据,或者调取照片确认,根据需要人工修改代码,获得跨试验的综合代码;
优选地,所述运用代码极差对代码进行的检验在竖排跨试验数据表中进行,包括:将两次或两次以上试验的竖排处理数据格式转成竖排跨试验数据格式,制作竖排跨试验数据表,竖排跨试验数据表格式为:待测、品种、性状、所述各次试验中的平均值、标准差、样本数、代码、表达状态横排并排显示,计算所有试验的平均值、标准差、样本数、优化代码的平均值,一并横排并排显示,其中,优化代码的平均值取整,即直接去掉小数点后的数值或四舍五入;计算不同试验的代码极差,根据极差大小,进行不同的标识,例如以不同的特定颜色显示,例如黄色(差1)、橙色(差2)、红色(差3)、紫色(差4以上);对于显色的代码数据,即各次试验间有差异的代码,人工检查原始数据,或调取照片确认,根据需要人工修改代码,确认的代码作为跨试验综合代码。
优选地,在上述植物品种dus测试方法中,还包括将转化的代码转入品种库的步骤;优选地,如果品种库中已经存在该品种或相应性状,则将结果进行覆盖;如果不存在,则在品种库的最后一行添加品种,或最后一列添加性状,更新品种库;
优选地,完成两次或两次以上试验后,对两次或两次以上试验的照片逐个进行对比,判定两次或两次以上试验是否有差异,如果有差异,检查原因,如果没差异,挑选一套标准照片,存储到预设的文件夹,例如存放到dus\玉米\标准照片\品种名称文件夹中。
优选地,还包括利用照片对性状代码进行确认或矫正的步骤;优选地,将某个性状代码按从小到大的顺序排列后,提取该性状对应的照片进行依次目测比较;优选地,该操作在横排数据表或品种库中进行,将鼠标点在某个代码型性状列上,程序自动按代码按大小排序,并通过照片命名的字符(优选为数字编号),批量提取该性状对应的每个品种的照片,放在下一列对应位置,按顺序查看照片,人工确认是否有代码给错的情况,最终保证拟出具报告的代码和照片一致。
优选地,在上述植物品种dus测试方法中,所述特异性分析包括:利用代码,采用有差异性状数累加法、差异大于阈值性状数累加法、相关系数法和/或最小距离法对品种进行近似程度分析;例如,采用相关系数分析,根据相关系数的大小,判定特异性;优选地,将不同的大小级别进行不同的标识,并分别进行不同的下一步处理,例如,将相关系数大于90%、95%的分别用黄色和红色标识,将差异在95%以上的品种选出来进一步进行分析。
优选地,先对品种库中的品种进行分组,分组依据是分组性状,选用表达状态离散、易于区分、能够准确观测的性状(如质量性状和/或假质量性状)作为分组性状,如果某组内只有一个品种,则该品种不需要与其他品种进行对比;然后对于需要对比的品种利用有差异性状数累加法、差异大于阈值性状数累加法、相关系数法或最小距离法对品种进行近似程度分析。
优选地,当以上方法无法确认差异时(例如,对于相关系数分析中相关系数差异在95%以上的品种),利用品种照片进行对比确认(优选在品种库中进行,包括:删除品种库表格中待测字段下的所有数据,在需要进一步对比的待测品种前输入“是”,在前一步分析出的近似品种前输入“否”,依据该输入的该信息,通过程序依次调取待测品种和近似品种的照片,进行并排展现,人工快速查看、确认是否有差异),或者调取所有性状的代码(如果是mg性状增加平均值,如果是ms性状增加平均值和标准差)进行并排展现,查看是否存在差异较大的数据,优选该数据从竖排处理数据表或竖排跨试验数据表中调取)。
优选地,所述特异性分析还包括:利用原始数据进行差异显著性分析,优选地,针对在利用代码进行分析中差异在95%以上的品种,选取ms性状进行t测验或者lsd检验或者coyd分析,判定差异是否显著;和/或,选取vs性状进行皮尔逊卡方检验方法进行验证,或者当表达状态仅有两种时,选取费氏精确检验方法验证,判定差异是否显著;优选地,所述皮尔逊卡方检验在竖排行列数据表中进行,所述竖排行列数据表通过将原始数据从竖排数据格式经统计转换获得,或者直接按竖排行列数据格式,采集田间数据;所述竖排行列数据表的格式为:待测、品种、试验、性状、代码字段横排,每个代码字段下的数据为该代码在群体中出现的次数。
优选地,在上述植物品种dus测试方法中,所述特异性分析还包括:田间并排比较分析,优选地,在利用原始数据进行差异显著性分析结果仍然没有找到显著的差异时,将两个品种安排在下一次试验进行田间并排种植,直接进行田间并排目测比较或采集更详尽的数据进行统计分析。
所述一致性分析方法包括异型株法和/或标准差法,优选地,所述标准差法采用相对方差法,优选地,当存在两次或两次以上试验时,采用coyu法对所有试验进行检验,判定数量性状一致性。
优选地,所述异型株法包括:选取总株数、异型株数、总体标准三个参数,采用异型株分析方法,计算拒绝h0假设的概率,判定一致性,例如,该概率大于95%时,可以判定为不具备一致性;
优选地,所述相对方差法包括:选取总体数量、标准差两个参数,采用相对方差法分析,计算出实际相对方差和理论相对方差,判定一致性;例如,当实际相对方差大于理论相对方差的可以判定为不具备一致性。
dus测试指南的性状设置受制于已知品种数量和类型,一套好性状的标准是用最少的性状区分最多的品种。本发明方法提供性状相关性分析和遗传多样性分析两种方法来实现这一目的。
优选地,在上述植物品种dus测试方法中,还包括:性状相关系数分析,计算两两性状之间的相关系数,根据相关系数的大小,确定被对比的性状是否都保留,例如,相关系数大于95%的性状,取消其中一个。
优选地,在上述植物品种dus测试方法中,还包括:质量性状代码分布频率和均匀度分析,计算代码分布频率,再计算遗传多样性指数和最大遗传多样性指数,两者相除得到分布均匀度,根据性状分布频率或分布均匀度,确定是否保留该性状,例如,某个性状分布频率大于95%或者分布均匀度小于0.05,该性状予以剔除。
优选地,在上述植物品种dus测试方法中,还包括:数量性状数值分布频率分析,一倍lsd0.05级差区间内分布频率大于95%,或者遗传均匀度小于0.2(1最好,最均匀)(遗传多样性指数/最大遗传多样性指数=遗传均匀度),或者级数小于3的数量性状,予以剔除。
dus测试指南里一般都会规定数量性状采集多少个样本用于计算平均值或进行对比分析。但当两个品种在特异性或者一致性上差异变小时,观测群体的大小会影响测试结果的准确性。
因此,在本发明中,优选地,在上述植物品种dus测试方法中,在特异性分析中还包括最小样本数分析,依据标准差,结合α误差概率、β误差概率、允许的差异,分析得出特异性分析所需的最小样本数。
优选地,在上述植物品种dus测试方法中,在一致性分析中还包括最小样本数分析,依据异型株数、总体标准,结合α误差概率、β误差概率,分析得出一致性分析所需的最小样本数。
本发明方法优化了dus测试试验设计,实现多个试验数据的联合矫正,增加了dus测试分析结果的客观性。同时,本发明的方法可以借助excel程序高效地实现试验数据和统计假设有效性检验和dus数据分析,使得原先需要2个月才能完成的dus数据分析工作,缩减到1天完成。
附图说明
图1显示的是展示了链接照片的竖排处理数据表;
图2显示的是展示了链接照片的竖排跨试验数据表;
图3显示的是两次实验对比界面示例图;
图4显示的是在品种库中进行照片确认的界面示例图;
图5显示的是品种库中待测品种与近似品种照片对比界面示例图;
图6显示的是dus专用最少样本数计算界面图。
具体实施方式
以下对本发明的具体实施方式进行详细的说明。应当理解的是,此处所描述的具体实施方式仅用于示例性地对本发明进行说明,并不用于限制本发明。
本次试验作物为玉米,品种149个,其中品种147个,标准品种2个。第一年和第二年各种植一次。每个小区长5米、宽2.4米,四行种植,株行距为30cm×60cm,双粒播种,两叶一心期间苗,每个小区留苗至少80株,设置两个重复。田间管理措施同大田生产。数据采集时,vg、mg性状只采集一个值,vs、ms性状采集20个单株值,照片拍幼苗、植株、雄穗、花丝、果穗五种,取样均来自同一个小区。全生育期拍摄幼苗、植株、雄穗、花丝、果穗五种照片。
1、按照dus测试指南,设置玉米的参数表
因性状数量较多,以下仅以三个性状为例,参数表设置如表2所示:
表2
表2中,性状编号、代码、表达状态、标准品种、性状名称、表达类型、观测类型、观测时间、数量单位、数值类型、极大值、极小值等参数均可以根据dus测试指南进行预设,标准值按照上述方法确定;阈值、权重根据经验设定;代码索引、分级值索引、分级值由标准值和实测值按预设的公式自动计算得到。
2、横排数据表记录原始数据
记录格式如下表3所示。因品种和数量较多,仅列举前16个性状和前14个品种。
表3
按照统一的横排数据格式进行横排数据采集,制作横排数据表:按照待测、品种、试验、性状编号的字段进行横排。当针对同一性状测定了多个单株样本值时,同一性状编号连续重复横排。例如,表3中,针对性状编号为16的性状测定了20个单株样本,性状编号16连续横排。
表3中,待测字段中用“是”标识的品种表示需要待测试评价并需要出具分析报告的品种,其他品种用“否”表示,例如标准品种、近似品种,并非被测试评价品种,不需要针对其出分析报告。
同一试验下的同一品种只列出一次,不能出现重复。
3、数据检验
(1)数据格式(例如数据类型)、数值范围和/或任选的数值单位匹配检验
基于第1部分参数表中数据类型等数据格式、最小值、最大值等数值范围、天、cm等数值单位,检验横排数据。
检验结果中,用特定颜色例如红色标识出异常值。例如,基于第1部分参数表的设置,性状2的数值范围应落在1-5的范围,数据采集时录入的6即为异常值;性状16的数值范围应为10-70,数据采集时录入的4即为异常值。通过设计程序自动地将这些异常值显示为红色。
(2)利用boxplot法和3σ法进行试验数据有效性检验
将横排数据格式转化为竖排数据格式,制作竖排数据表。利用boxplot法和3σ法进行试验数据有效性检验。
转化的竖排数据表如表4所示。按待测、品种、试验、性状、同一性状各单株样本编号的字段进行横排,而将性状编号作为数据竖排。
表4
可采用同一竖排数据表进行两种计算,并用不同颜色标识出各种异常值。
boxplot法计算结果如表5所示(以黄色表示1.5倍中距,红色表示3倍中距)。
表5
3σ法计算结果如表6所示(黄色是2倍标准差,红色是3倍标准差)。
表6
经两种方法检验,仍为异常值,需要人工检查原始记录或田间样品,如属于输入错误,直接改正。属于客观事实的情况下,如果只有极少数(例如仅仅两个以内)无法说明原因的异常值,通过程序提供前后值平均。如果异常值较多,则不处理,用相对方差法或者coyu法检验一致性。
4、频率分布分析
(1)在对一次试验ms性状数据进行频率分布分析时,可以从横排数据表中直接提取待测、品种、性状编号及其原始值到横排跨试验数据表中;(2)在针对两次试验ms性状数据进行频率分布分析时,可以从横排数据表中提取待测、品种、性状编号,并计算各性状的试验平均值,一并转入至横排跨试验数据表中,所述横排跨试验数据表格式为:待测、品种、同一性状不同试验的平均值或不同植株的原始值连续横排。
横排跨试验数据表如表7所示。
表7
频率分布分析以及标准值、分级值的确定
数量性状频率分布计算结果示例如表8所示。
表8
针对每个测量性状,分别以所有品种的所有原始数据的平均值为中心标准值,以2倍lsd0.05为级差,设定各级的标准值,以各级标准值为中心,向两侧各延伸1/2级差所构成的区间,设为每个代码的分级区间;每个区间的最小值,作为分级值;确定每级分级值和分级区间,统计各个分级区间的品种数和百分比。根据统计结果,判定总区间覆盖范围是否小于3级或者大于9级。小于3级的性状不适宜用于dus测试,予以剔除;大于9级的性状,调增lsd0.05的倍数,并参考各级区间百分比是否均匀来调整分级,使得分级范围处于9级以内;处于3和9级之间的性状,可以在两端各空出1-2级以便将来出现新品种时适用;由此获得一个更合理的分级。如果最小分级区间最小值小于零,则将最小分级区间的最小值设置为0,再按照前面确定的倍数的lsd0.05从小到大进行分级,重新确定标准值,将各级标准值取整。再根据标准品种在试验中的表现,判定标准品种的代码位置是否合适,如果不合适,将标准品种移到合适的代码位置,并根据标准品种的实测值,将标准值进行整体平移,使标准品种实测值与其对应的标准值接近。由此确定标准品种并形成一套相对固定的标准值。如表9所示。
表9
5、竖排数据格式转竖排处理数据格式,制作竖排处理数据表,进行代码数据检验和优化
将竖排数据格式转成竖排处理数据格式,即待测、品种、试验、性状横排,并将竖排数据表中同一ms性状多个样本值处理成平均值、标准差、样本数,并预留区间代码、已知代码、回归代码、优化代码、表达状态字段,将这些字段横排。处理后的表格格式如表10所示。
表10
对于mg、ms性状,在所采用的一套标准值不是由本次试验数据得到的情况下(例如第二年试验),检验标准品种在本次试验中与获得所述一套标准值的试验中表现是否一致。
在竖排处理数据表中,计算本次试验中性状的平均值(即实测值)、标准差、样本数。把标准品种实测值提取到参数表中。标准品种实测值与标准值的差值的绝对值除以标准值,该值大于10%则确认为差异过大,用特定的颜色(例如红色)显示提示为异常值。对于出现异常值的情况,人工判定是否属于可接受的异常情况(质量性状原则上不允许出现异常,出现的话,需要人工检查原因,予以修正)。如果某个性状多个标准品种因某种因素出现类似的变化,则属于可接受的异常,数据保留。如果该性状出现异常情况的标准品种与其他标准品种变化不一致,则需要剔除该标准品种实测值。
对于mg、ms性状,在所采用的一套标准值不是由本次试验数据得到的情况下,利用标准品种矫正分级范围。分级值第一个为零,第二个以下分别为:各标准品种的(实测值-标准值)/标准值所得值之和除以标准品个数,再加上本代码对应标准值与前一代码对应标准值之和的1/2。
根据标准值和实测值计算每个代码对应的分级值、分级值索引、分级区间后,并计算每个品种每个性状的代码,获得区间代码。
针对数量性状,如果本次试验中存在在品种库中有数据的已知品种,将品种库中已知品种的相应代码提到竖排处理数据表中的已知代码处。将这些已知品种在本次试验中的平均值与相应的已知代码建立线性回归关系,将其他品种在本次试验中的原始数据平均值代入该线性回归关系,计算出所有品种的回归代码。对区间代码、已知代码、和回归代码进行分析,选取其中的众数代码、中间数代码或三者的平均数代码作为进一步优化的代码数据。
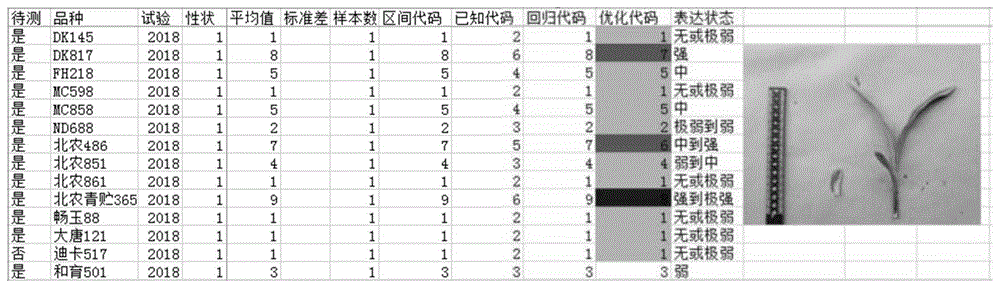
当至少存在区间代码、已知代码、回归代码中的两种代码时,采用代码极差进行检验。由这些代码中的最大值减最小值计算极差,按极差大小显示特定颜色,例如,差1个代码显示黄色,差2个代码显示橙色,差3个代码显示红色,差4个代码显示紫色等。对于显色的代码数据,人工检查原始数据,或调取照片确认,可以根据需要人工修改代码。通过设计程序,可快速调取照片进行确认。将鼠标放在需要调照片的代码上,通过程序链接照片,并展示在该代码同行空白位置处。如图1所示。
6、竖排处理数据格式转竖排跨试验数据格式,确定跨试验综合代码
将两年度试验的竖排处理数据格式转成竖排跨试验数据格式,制作竖排跨试验数据表,如下表所示。竖排跨年数据表格式为:待测、品种、性状、各年度试验中的平均值、标准差、样本数、代码、表达状态横排并排显示,并计算两年度试验的平均值、标准差、样本数、优化代码的平均值,一并横排并排显示。其中,优化代码的平均值取整(直接去掉小数点后数值或四舍五入)。另外,计算各年度代码极差,根据极差大小,以不同的特定颜色显示,例如黄色(差1)、橙色(差2)、红色(差3)、紫色(差4以上)。对于显色的代码数据(年度间有差异的代码),人工检查原始数据,或调取照片确认,可以根据需要人工修改代码。确认的代码作为跨试验综合代码。通过设计程序,可以实现快速调取照片进行确认。将鼠标放在需要调照片的代码上,通过程序链接照片,并展示在该代码同行空白位置处。如图2所示。
7、将跨试验综合代码转入品种库
将跨试验数据表中的综合代码数据转入品种库中,如表11所示。对于品种库中已有的品种或性状,代码数据直接覆盖;品种库中没有的品种或性状,在数据的最后一行(品种)或最后一列(性状)添加字段,并导入综合代码数据。这样,品种库的数据逐年更新和累加。
表11
8、标准照片整理
完成两年试验后,对两年的照片进行对比。判定两年照片是否有差异。如果有差异,检查原因,如果没差异,挑选一套标准照片,存放到dus\玉米\标准照片\品种名称文件夹中。对比界面示例如图3所示。
9、代码排序后批量调取照片确认代码
在横排数据表或品种库中,将鼠标点在某个代码型性状列上,程序自动按代码按大小排序,并通过第1部分的参数表中的性状照片字段下预设该性状对应的照片类型编号,批量提取该性状对应的每个品种的照片,放在下一列对应位置,按顺序查看照片,人工确认是否有代码给错的情况。最终保证拟出具报告的代码和照片一致。在品种库中进行照片确认的界面示例图如图4所示。
10、特异性分析
(1)品种库中进行近似品种筛选
在最终形成的品种库中,先根据参数表中设置的分组信息,对所有品种进行分组排序。可以快速地初步将品种分为若干组。如果某组内只有一个品种,则该品种不需要与其他品种进行对比。
然后,利用有差异性状数累加法、差异大于阈值性状数累加法、相关系数法或最小距离法对品种进行近似程度分析,分别设置一般提醒和特别警示数值区间,如表12所示。
表12
以相关系数为例,结果区中,横排是待测品种,竖排是所有品种,相关系数大于90%用黄色显示,大于95%的用红色显示。
(2)利用品种照片对比进一步确认
删除品种库表格中的待测字段下的所有数据,在需要进一步对比的待测品种前填上“是”,在第(1)步中分析出的近似品种前填上“否”。依据该输入的信息,通过程序依次调取待测品种和近似品种的照片,进行并排展现,人工快速查看、确认是否有差异。待测品种与近似品种照片对比界面示例如图5所示。
(3)调取原始数据
如果近似品种与待测品种照片没差异,从竖排处理数据表或竖排跨试验数据表中进一步调取两个品种所有测量性状的平均值、代码(ms性状还包括标准差)放在数据对比表格中,进行并排对比,如表13所示,查看是否存在差异较大的数据。
表13
(4)针对mg、ms性状,继续调取两个品种的单次试验原始数据或两次试验汇总数据进行t检验,或coyd分析。如表14和表15所示。
表14
表15
(5)对于vs性状,在竖排行列数据表中,利用皮尔逊卡方检验方法对待测品种和近似品种的特异性进行分析。
可以将原始数据从竖排数据格式经统计转成竖排行列数据格式,竖排行列数据表的格式为:待测、品种、试验、性状、代码字段横排,每个代码字段下的数据为该代码在群体中出现的次数,如表16所示。也可以直接按竖排行列数据格式,采集田间数据。
表16
皮尔逊卡方检验结果如表17所示。
表17
(6)当(5)中的表达状态仅有两种时,可以采用精度更高的费氏精确检验方法分析特异性。
费氏精确检验计算结果如表18所示。
表18
11、离散型数据一致性分析
离散型数据的一致性分析采用upov异型株法,本方法对显示界面进行了改造,便于数据记录和批量计算,界面表19所示。
表19
p值和结果是依据群体大小、异型株数、群体标准三个值计算而来。
12、连续型数据一致性分析-相对方差法;
一年数据可以采用相对方差法分析一致性,数据采集和分析界面如表20所示。
表20
13、连续型数据一致性分析-coyu方法
两年数据采用coyu法,数据可从横排跨试验数据表中获取,分析界面如表21所示。
表21
14、优化性状选择
dus测试指南的性状设置受制于已知品种数量和类型,一套好性状的标准是用最少的性状区分最多的品种。在此提供性状相关性分析和遗传多样性分析两种方法来实现这一目的。
性状相关性分析可以是原始值也可以是代码,分析结果如表22所示。
表22
从上表中可以看出,性状3和4的相关系数达到96.82%,说明两者区分品种作用高度相似,可以去除一个。
遗传多样性分析结果如表23所示。
表23
从表中可以看出,性状3、4的遗传多样性指数偏低,遗传均匀度偏高,区分品种能力不强。
15、最少样本数计算
参考相关统计学方法,设计dus专用最少样本数计算界面如图6所示。
图6中,左边为连续型数据分析界面,右边为离散型数据分析界面,左图界面设计考虑了估计总体和均值差,带功效和不带功效四种情况,右图界面设计考虑了总体估计带功效和不带功效两种情况。
针对不同作物的实际标准差或百分率差,可以重新计算。
- 还没有人留言评论。精彩留言会获得点赞!