一种基于辅助信息的中文抽取性集成无监督摘要的方法与流程
本发明涉及一种生成摘要的方法,尤其涉及一种基于辅助信息的中文抽取性集成无监督摘要的方法。
背景技术:
随着文本信息爆炸性增长,读者需要更高效快捷的方式来了解文章的主要内容。自动摘要任务是自然语言处理的一个分支,是从一篇或者几篇长文本中生成一篇短文本的技术。自动摘要可以应用在各种场景,比如新闻文本,会议记录,医疗档案,社交文本等。自动摘要已经得到了广泛地研究,现有技术分为两类:抽取性自动摘要和生成性自动摘要。抽取性自动摘要从原文中选择重要的语言信息并把这些重要信息拼接起来组成最后的摘要;生成性自动摘要通过学习规则来捕捉关键信息生成一段原文章中没有出现的句子。最近几年生成性自动摘要技术发展很快,但是生成性自动摘要需要大量训练数据并且结果不具有泛化能力较差。工业界一般使用抽取性自动摘要而不是生成性自动摘要。传统抽取性自动摘要对于语言类别没有要求。不同于西方语言,中文处理非常有挑战。其中最大的不同是中文需要借助分词工具来更好处理中文语言信息。分词工具的优劣直接或者间接影响最终文本摘要的好坏。
现有技术中,基于图的自动摘要方法在textrank算法本质依然是google提出的pagerank算法,pagerank算法最大的问题是排序下沉,在textrank结果中会导致出现重叠的句子在最终的摘要中;基于中心的自动摘要方法严重依赖于聚类算法的质量,鲁棒性存在问题;基于次模函数的自动摘要方法未考虑到词语之间的予以相似度;基于深度学习的自动摘要方法严重依赖于大量带标记的训练数据,并且结果不够稳定。
现有技术的抽取性自动摘要算法有很多可以提高的地方,主要体现在三个方面。第一,大多数抽取性自动摘要算法基于单一数学模型,很多算法如textrank有本身难以提高的缺陷。第二,随着互联网和手机的普及,越来越多新闻文本数据在网络上传播,目前在市面上没有一个可以结合新闻标题的算法。第三,传统无监督算法具有鲁棒性高的特点,但是很多不具备深度学习算法所提出理解语义的特点;大部分深度学习算法可以理解语义,但是大部分依赖于高质量标记数据。
技术实现要素:
因此,本发明提出了一种基于辅助信息的中文抽取性集成无监督摘要的方法。采用两种不同的无监督学习方法对数据集进行建模,对抽取结果通过改进版的mmr和新闻标题对结果摘要的抽取。
方法具体过程:
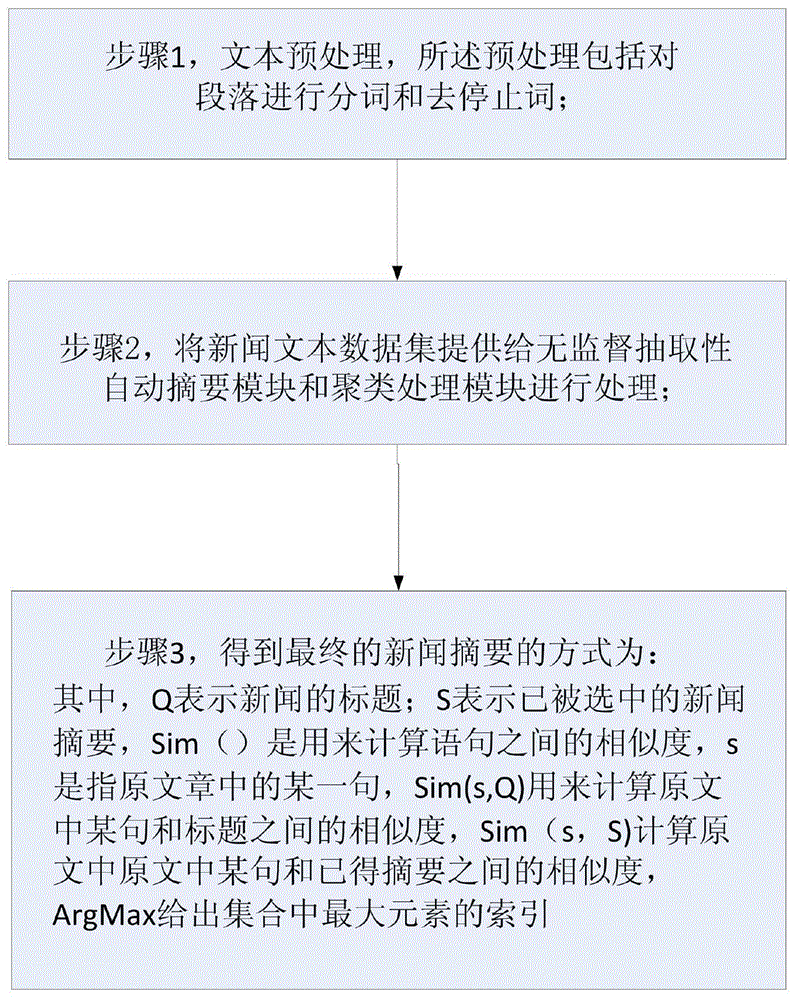
步骤1,文本预处理,包含分词,去停止词等过程;
步骤2,将新闻文本数据集提供给textrank算法和affinitypropagation算法。因为affinitypropagation算法无法直接处理文本数据,所以本算法使用腾讯提供的800万中文词向量先对中文词进行向量化操作,然后把所得到的中文词向量转化成中文句向量。使用预训练词向量的好处是结果比较稳定,同时能够获取词之间的语义信息。最后,定义affinitypropagation算法得到质心的句子为affinitypropagation算出的新闻摘要。
步骤3,最终的新闻摘要为:
其中q表示新闻的标题;s表示已被选中的新闻摘要;s表示新闻中的段落。算法时考虑到新闻中段落顺序的特征,在撰写新闻过程中越靠前的段落包含的重要信息越多。λ控制mmr算法的多样性和准确性。当λ值比较大的时候,mmr选出的摘要准确性比较高;当λ值比较小的时候,mmr选出的摘要多样性比较高。最终的目标是平衡摘要的多样性和准确性。mmr中λ预设为0.7,mmr算法的输入是textrank算法和affinitypropagation算法中的输出,也就是各自针对新闻文本生成的摘要。
本发明提出的基于基于集成学习以及中文新闻标题辅助的抽取性自动摘要算法通过集成学习,提高了现有算法的鲁棒性,克服了单一数学模型自身的缺点;本发明的算法合理利用新闻标题信息提高算法的性能,因为新闻标题一般来说高质量地提取了新闻中的主要内容;最后,使用预训练词向量让传统算法结合语义信息得到更好的结果。
附图说明
图1为本发明的具体流程图;
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明提出了一种基于辅助信息的中文抽取性集成无监督摘要的方法。采用两种不同的无监督学习方法对数据集进行建模,对抽取结果通过改进版的mmr和新闻标题对结果摘要的抽取。
方法具体过程:
步骤1,文本预处理,所述预处理包括包含分词,去停止词等过程;具体方式为在第一步文本预处理过程中,首先要对文本进行分句操作,把文章分成n句段落。在分割成段落之后,我们使用分词工具(结巴分词)对段落进行分词。同时,把段落中的停止词过滤。停止词是一般文本中大量出现的词,比如我,你,他,的,等等。过滤后的结果包含文章中主干信息的段落。
步骤2,将新闻文本数据集提供给textrank算法和affinitypropagation算法。所述textrank处理的具体过程为,首先,使用预处理之后的结果把每个句子用向量表示;之后,计算句子向量之间的相似性并存放在矩阵中;然后相似矩阵转换以句子为节点,相似度为边的图结构上使用pagerank算法进行计算;最后选中排名最高的一组句子构成最终摘要。
传播子算法的思想是将全部样本看作网络的节点,然后通过网络中各条边的消息传递,计算各样本的中心。聚类过程中,有两种消息在各节点见传递,分别是吸引度和归属度。affinitypropagation算法的输入是样本之间的相似度矩阵。在预处理之后,使用中文词向量和sif算法来构造对应句子的中文句向量,然后计算句子之间的相似度。affinitypropagation中r(i,j)来描述样本j适合样本i的类代表程度;a(i,j)来描述样本i选择样本j作为其类代表的适合程度。r(i,j)与a(i,j)之和越大,点j作为聚类中心的可能性越大。
通过affinitypropagation得到的中心对应的句子被提取出来作为最终的摘要。本发明使用腾讯提供的800万中文词向量先对中文词进行向量化操作,使用sif[10]把所得到的中文词向量转化成中文句向量,使用预训练词向量的好处是结果比较稳定,同时能够获取词之间的语义信息。腾讯中文词向量可以在高维空间上学习词语之间的关联关系。在一个训练好的英文word2vec词向量模型上,可以得到词之间的语义关联关系,比如king-man+woman=queen。词向量的另一种表示方法是one-hot表示形式,但是无法学习词之间的关联关系。本发明中把之前腾讯所得的词向量转化为句向量,分为两步:步骤2.1对句子中的每个向量,乘以一个权重a/(a+p_w),其中a是一个常数(取0.001),p_w为该词的词频;对于出现频率越高的词,其权重越小;步骤2.2计算句向量矩阵的第一个主成分,让每个句向量减去它在u上的投影。
步骤3,得到最终的新闻摘要的方式为:
其中,q表示新闻的标题;s表示已被选中的新闻摘要,sim()是用来计算语句之间的相似度。s是指原文章中的某一句,sim(s,q)用来计算原文中某句和标题之间的相似度,sim(s,s)计算原文中原文中某句和已得摘要之间的相似度。argmax给出集合中最大元素的索引。基于新闻中段落顺序的特征,在撰写新闻过程中越靠前的段落包含的重要信息越多。所述λ控制mmr算法的多样性和准确性,当λ值比较大的时候,mmr选出的摘要准确性比较高;当λ值比较小的时候,mmr选出的摘要多样性比较高。最终的目标是平衡摘要的多样性和准确性。mmr中λ预设为0.7。
本发明提出的基于基于集成学习以及中文新闻标题辅助的抽取性自动摘要算法通过集成学习,提高了现有算法的鲁棒性,克服了单一数学模型自身的缺点;本发明的算法合理利用新闻标题信息提高算法的性能,因为新闻标题一般来说高质量地提取了新闻中的主要内容;最后,使用预训练词向量让传统算法结合语义信息得到更好的结果。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!