基于多GPU多分辨率弹跳射线的声目标强度仿真方法与流程
本发明属于计算机应用领域,具体涉及一种多gpu多分辨率弹跳射线的声目标强度仿真方法,可用于对水下目标的声目标强度进行快速仿真。
背景技术:
水声目标强度是描述水下目标远场回波特性的重要参数,目前有很多方法用来预测水下目标的散射特性,如边界元bem、有限元fem和t矩阵方法。这些方法的不足是:对于大尺度目标,计算速度很慢。范军等人于2012年提出的板块元pem方法,将目标表面用三角面元近似表示,通过将每个三角面元的散射声场叠加得到整个目标的散射声场的近似值。然而,板块元方法仅适用于凸面几何体,对于凹面复杂几何体的声目标强度预测值会有一定的误差。
弹跳射线法sbr是比较成熟且通用的高频方法,常被用来计算电大尺寸目标的雷达散射截面rcs。该弹跳射线法由于基于几何光学法go,考虑到射线在目标表面存在多次反射的情况,通过射线追踪确定射线与三角面元的相交情况,且基于物理光学法po进行散射场计算,因而特别适合目标几何结构存在遮挡的情况。同时,研究人员对该算法提出了很多加速方法,比如利用八叉树、kd树等数据结构加速射线追踪过程。但是对于大尺度目标,弹跳射线法中需要计算的射线数量非常多,且计算复杂度很高,因而研究人员提出了多分辨率弹跳射线法,通过声线管束分裂将管束分级,能有效减少仿真计算量。但在中央处理单元cpu上,利用多分辨率弹跳射线法进行水下目标的声目标强度计算时,声线管束的分裂过程以串行方式实现的计算时间过长,不利于实时预报。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提出一种多gpu多分辨率弹跳射线的声目标强度仿真方法,在gpu平台上并行实现声线管束分裂,缩短水下复杂目标的声目标强度计算时间,提高水下复杂目标的声目标强度计算速度。
本发明的技术方案是这样实现的:
一、技术原理
图形处理单元gpu,是目前主流的协处理器。gpu采用单指令多线程simt体系结构,一个warp的32个线程由一个控制器控制,同时处理一条指令,正是这种设计使gpu具有超强的浮点计算能力。弹跳射线法的特点是数据之间的依赖度不高,具有很高的并行性,因而gpu的众核架构非常适合用来加速弹跳射线法,虚拟孔径面生成、射线追踪以及场积分均可利用gpu并行加速,其与cpu相比能显著提高仿真效率。将多分辨率弹跳射线法在gpu上进行并行加速,能进一步提高水下目标的声目标强度仿真速度。同时还可将仿真系统在多gpu平台上进行移植,达到实时仿真水下目标的声目标强度的效果。
二、实现方案
根据上述原理,本发明的实现步骤包括如下:
(1)利用catia软件绘制仿真模型,将模型保存为.igs格式;
(2)利用ansysicemcfd软件对模型进行非结构化网格剖分,得到模型的三角面元信息和节点信息,并存储在cpu内存中;
(3)在cpu端采用大小节点并行算法对剖分后的模型进行无堆栈kd-tree建树,以加速射线追踪过程,并将cpu内存中的信息通过pcie接口拷贝到各gpu显存上;
(4)选用多个gpu计算卡,并参考gpu显存大小,在各gpu上开辟一次显存空间;
(5)在第一个gpu上对剖分后的模型进行二维初始虚拟孔径面生成,并按照gpu计算卡数量对初始虚拟孔径面进行区域划分,得到多个子孔径面,每个子孔径面对应一个gpu计算卡,并将每个子孔径面的边界信息传递到对应gpu计算卡上,采用并行的方式以步长λ生成声线管束的角顶射线;
(6)在gpu端采用并行的方式追踪声线管束的角顶射线,记录每条角顶射线与三角面元的相交信息,并判断每个声线管束的属性信息:
若声线管束的四个角顶射线均没有与任何一个三角面元相交,则该声线管束是无效的,抛弃该声线管束;
若声线管束的四个角顶射线均与同一个三角面元相交,则该声线管束是有效的,执行(9);
若声线管束的四个角顶射线没有与同一个三角面元相交,则在gpu端利用有序密集排列方法进行声线管束分裂,通过计算每个声线管束的四个偏移地址索引,完成本次分裂过程,执行(7);
(7)判断分裂次数是否达到设定的阈值,若没有达到,返回(6),若达到,执行(8);
(8)在gpu端采用并行的方式追踪声线管束的角顶射线,记录每条角顶射线与三角面元的相交信息,并判断每个声线管束的属性信息:
若声线管束的四个角顶射线均与同一个三角面元相交,则该声线管束是有效的,执行步骤(9),否则,抛弃该声线管束;
(9)在gpu端利用板块元方法并行计算每个声线管束的散射声场
(10)在cpu端对每一次散射声场积分结果
与现有技术相比,本发明具有如下优点:
1)本发明由于通过在gpu上计算每个声线管束的四个偏移地址索引,并行实现声线管束分裂,有效减少了仿真计算量,提高了水下目标的声目标强度仿真速度;
2)本发明由于在gpu上实现多分辨率弹跳射线法,克服了现有技术中,在中央处理单元cpu上,以串行方式实现声线管束的分裂过程时计算用时太长,不利于实时预报的缺点;
3)本发明由于在多gpu平台上进行声目标强度仿真,达到实时仿真水下目标的声目标强度的效果,可满足实际工程需求。
附图说明
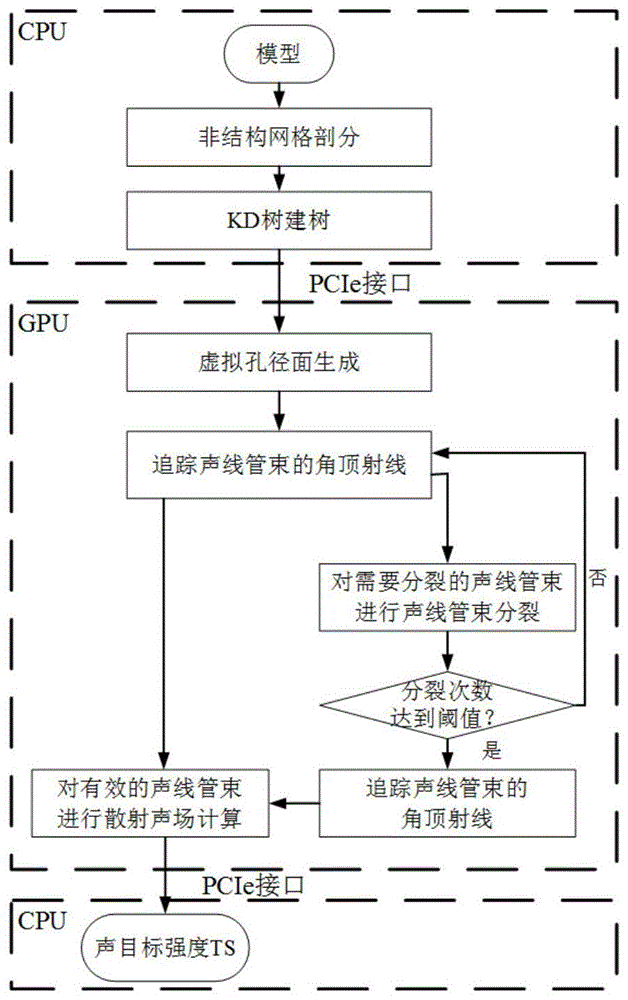
图1是本发明的实现流程图;
图2是本发明中声线管束分裂示意图;
图3是本发明仿真使用的半径为1米的刚性球体模型;
图4是用本发明对图3的声目标强度仿真结果图;
图5是本发明仿真使用的半径为1米,长度为6米的刚性圆柱体模型;
图6是用本发明对图5的声目标强度仿真结果图。
具体实施方式
以下结合附图,对本发明的实例和效果作进一步说明:
参照图1,本实例的实现步骤如下:
步骤1,绘制仿真模型,并进行非结构化网格剖分。
1.1)利用catia软件绘制仿真模型,并将该模型保存为.igs格式;
1.2)利用ansysicemcfd软件对仿真模型进行非结构化网格剖分,得到该模型的三角面元信息和节点信息,并存储在cpu内存中。
步骤2,构建kd树:
在cpu端对网格剖分后的模型构建kd树,以加速射线追踪过程,并将cpu内存中的信息通过pcie接口拷贝到各gpu显存上,现有建kd树的方法有表面积启发式算法sah,空间中分法,大小节点并行算法,其中:
表面积启发式算法sah,是通过计算不同分割面的代价值,选取代价值最小的分割面对包围盒进行划分,sah代价优化函数为
其中,ctraversal表示角顶射线遍历到当前节点的代价,sa(v)表示当前节点包围盒的表面积,sa(vl)表示当前候选剖分面下左子节点包围盒的表面积,nl表示在当前候选剖分面下被划分到左子节点的三角面元数量,sa(vr)表示右子节点包围盒的表面积,nr表示被划分到右子节点的三角面元数量,chit表示角顶射线与三角面元求交的代价值。sah算法的优势在于:建树质量高,但不足之处在于:当三角面元数量多时,使用sah算法计算代价函数存在误差,且建树时间太长。
空间中分法,是通过选取包围盒最长的边所平行的坐标轴作为剖分轴,选取的分割面垂直于剖分轴,空间中分法的优势在于:建树速度快,但不足之处在于:对于三角面元高度随机的模型,建树质量不高,会影响射线追踪效率。
本实例采用但不限于大小节点并行算法,其实现步骤如下:
2.1)根据剖分后模型的三角面元及节点信息,构建包含整个模型的轴对齐包围盒,并创建根节点;
2.2)将节点内的三角面元数量n与设定的阈值ε=256进行比较,若n≥ε,则该节点为大节点,采用空间中分法选取分割面,若n<ε,该节点为小节点,采用表面积启发式算法sah选取分割面;
2.3)生成当前节点的左右子节点,根据分割面位置将当前节点内的三角面元划分到左右子节点中;
2.4)分别对左右子节点重复调用步骤2.2)-2.3),直至满足节点达到规定树深或节点内包含的三角面元数量小于设定阈值,完成构建kd树;
2.5)将kd树的结构信息存储在cpu内存中。
这种大小节点并行算法的优势在于:水下目标多是紧致且完全对称的,如潜艇、鱼雷等,在大节点上采用空间中分法不会降低kd树的建树质量,在小节点上三角面元趋近于随机分布,采用sah算法可以保证建树质量。
步骤3,开辟显存空间。
选用多个gpu计算卡,并参考gpu显存大小,在各gpu上开辟一次显存空间,其大小m为:
m=2×(mtubes+mrays)
mtubes=hmax×wmax×mtube
mrays=[(hmax+1)×(wmax+1)+hmax×wmax]×mray
其中,mtubes、mrays分别为声线管束和角顶射线分配的显存大小,mtube、mray分别为每个声线管束和每条角顶射线所占显存的大小,hmax、wmax分别为在不超过gpu计算卡显存大小的情况下,虚拟孔径面的最大高度和宽度。
步骤4,生成虚拟孔径面和角顶射线。
4.1)在第一个gpu上对剖分后的模型进行二维初始虚拟孔径面生成,其实现步骤如下:
4.1.1)计算二维初始虚拟孔径面的边界值,即根据剖分后模型的节点信息,在gpu上计算节点的坐标极值(xmax,ymax)和(xmin,ymin),并将其作为二维初始虚拟孔径面的边界值,其中,xmax、xmin分别为节点坐标在水平方向上的最大值和最小值,ymax、ymin分别为节点坐标在垂直方向上的最大值和最小值;
4.1.2)根据边界值计算二维初始虚拟孔径面的宽度w和高度h:
其中,λ表示步长,
4.2)在每个gpu上生成角顶射线:
4.2.1)按照gpu数量对初始虚拟孔径面进行区域划分,得到多个子孔径面,每个子孔径面对应一个gpu,并将每个子孔径面的边界信息传递到对应gpu上;
4.2.2)在gpu上每个线程thread以步长λ生成一条角顶射线,多个线程thread同时并行生成多条角顶射线,表示如下:
(x,y)=(xmax-λ*m,ymin+λ*n)
其中,(x,y)表示角顶射线坐标,m、n分别表示线程thread在水平和垂直方向上的索引序号,0≤m<w,0≤n<h,w表示子孔径面的宽度,h表示子孔径面的高度,xmax表示子孔径面在水平方向上的最大值,ymin表示子孔径面在垂直方向上的最小值,*表示点乘。
步骤5,追踪声线管束的角顶射线,进行散射声场积分或声线管束分裂操作。
5.1)在gpu端采用并行的方式追踪声线管束的角顶射线,记录每条角顶射线与三角面元的相交信息;
5.2)根据声线管束的四个角顶射线与三角面元的关系,判断声线管束的属性信息:
若声线管束的四个角顶射线均没有与任何一个三角面元相交,则抛弃该声线管束;
若声线管束的四个角顶射线均与同一个三角面元相交,则对该声线管束进行散射声场积分操作,执行步骤8;
若声线管束的四个角顶射线没有与同一个三角面元相交,则在gpu端利用有序密集排列方法计算每个声线管束的四个偏移地址索引进行声线管束分裂,结果如图2所示;完成本次分裂过程后,执行步骤6;
所述计算每个声线管束的四个偏移地址索引,其实现步骤如下:
第一步,数据初始化:
对所有声线管束的属性信息按照每512个进行分组,设声线管束总数量为n;
在gpu上创建
利用gpu原子加操作计算每组声线管束中需要分裂的声线管束数量,并将该结果存储在辅助数组中,辅助数组长度为:
第二步,计算起始偏移地址:
根据辅助数组计算每个需要分裂的声线管束的起始偏移地址,创建
利用blelloch扫描算法并通过threadfence及原子加操作保证线程块block间扫描的同步性,计算得到需要分裂的声线管束的总数量m和每个需要分裂的声线管束的起始偏移地址ai,其中i表示需要分裂的声线管束序号,0≤i<m;
第三步,计算自身偏移地址:
在gpu上创建
对每一组声线管束利用gpu压缩算法,计算得到每个需要分裂的声线管束的自身偏移地址bi;
第四步,根据起始偏移地址ai和自身偏移地址bi,计算得到每个需要分裂的声线管束的四个偏移地址索引分别为ci、ci+1、ci+2、ci+3,其中ci=4×(ai+bi)。
步骤6,设置分裂阈值δ=3,判断分裂次数q是否达到分裂阈值δ:
若q<δ,则返回步骤5,若q=δ,则执行步骤7。
步骤7,追踪声线管束的角顶射线,进行散射声场积分操作。
7.1)在gpu端采用并行的方式追踪声线管束的角顶射线,记录每条角顶射线与三角面元的相交信息;
7.2)根据声线管束的四个角顶射线与三角面元的关系,判断声线管束的属性信息:
若声线管束的四个角顶射线均与同一个三角面元相交,则对该声线管束进行散射声场积分操作,执行步骤8,否则,抛弃该声线管束;
步骤8,计算散射声场。
8.1)在gpu端利用板块元方法并行计算每个声线管束的散射声场
其中,w表示入射声波的角频率,波数k=2π/λ,λ表示入射声波的波长,i表示复数的虚部,选取声线管束的中心点为参考点,rm表示坐标原点到参考点的方向向量,r表示声波发射点到参考点的单位方向向量,t表示r在声线管束积分区域上的投影长度,n表示声线管束的顶点编号,n=1,2,3,4,δan表示声线管束的四条边的方向向量,δρn表示声线管束边上一点的坐标,δρn=(an+an+1)/2,an表示声线管束的第n个顶点的坐标,n0表示声线管束上的法向量;
8.2)利用归约算法对8.1)的计算结果进行矢量求和,并将每个gpu计算卡上的结果通过pcie接口拷贝回cpu端进行矢量累加,得到本次散射声场积分结果
步骤9,计算声目标强度值。
9.1)在cpu端对每一次散射声场积分结果
9.2)根据总散射声场
其中,波数k=2π/λ,λ表示入射声波的波长,j表示复数的虚部。
本发明的仿真效果通过以下仿真实验进一步描述:
1.仿真实验条件
系统测试的硬件环境为gpu:nvidiageforcegtx1080ti(4卡),cpu:intelcorei5-2470cpu3.20ghz3.60ghz。
gpu计算卡主要性能参数如表1:
表1
2.仿真模型
仿真模型1为刚性球体模型,如图3所示,球体的半径为1m;该模型的声目标强度理论值为-6db。
仿真模型2为刚性圆柱体模型,如图5所示,圆柱体的半径1m,长度6m;该模型的端部声目标强度理论值为35.98db,正横方向的声目标强度理论值为25.56db。
3.实验内容与结果
实验一:利用ansys软件对仿真模型1进行非结构网格剖分,设定最大网格尺寸为0.05m,剖分后的面元数量为11000,节点数量为5628,入射声波的中心频率为30khz,虚拟孔径面在模型的水平方向0~180度范围生成,对仿真模型1以步长a=0.004λ并行生成声线管束的角顶射线,利用多分辨率弹跳射线法进行声目标强度仿真计算,结果如图4所示。
从图4可见,本发明的仿真结果与其理论值接近,证明了本发明的正确性。
实验二:分别统计在单cpu,单gpu和4卡gpu三种硬件平台上对仿真模型1的仿真时间,结果如表2所示:
表2
从表2中可以看出,本发明在gpu上并行实现声线管束分裂可以显著提高对声目标强度的仿真速度,其与在cpu上以串行方式进行声线管束分裂相比,速度提高了10.65倍。
实验三:利用ansys软件对仿真模型2进行非结构网格剖分,设定最大网格尺寸为0.05m,剖分后的面元数量为32328,节点数量为16445。入射声波的中心频率为30khz,虚拟孔径面在模型的水平方向0~180度范围生成,对仿真模型2以步长a=0.01λ并行生成声线管束的角顶射线,利用多分辨率弹跳射线法进行声目标强度仿真计算,仿真结果如图6所示。
从图6可见,本发明的仿真的端部声目标强度与其理论值35.98db,正横方向的声目标强度与其理论值25.56db都很接近,证明了本发明的正确性。
实验四:分别统计在单cpu,单gpu和4卡gpu三种硬件平台上对仿真模型2的仿真时间,仿真时间如表3所示:
表3
从表3中可以看出本发明中在gpu上并行实现声线管束分裂可以显著提高对声目标强度的仿真速度,和在cpu上以串行方式进行声线管束分裂相比,加速比为3.75倍。
- 还没有人留言评论。精彩留言会获得点赞!