一种基于图结构的地名地址的解析方法与流程
本发明涉及地名地址空间数据库的构建与检索技术领域,具体涉及一种基于图结构的地名地址的解析方法。
背景技术:
地名地址的检索包括两种类型:正向解析,根据地名地址的名称查询地名地址的空间位置等各类属性;逆向解析,即根据空间位置查询地名地址名称等各类属性;正向解析主要通过地址编码(geocoding),由于中文地名地址的特性,针对中文地名地址的正向解析主要包括分词与解析两步,分词多依赖自然语言处理的规则方法或机器学习方法,而解析多侧重于标准地址或兴趣点(poi)。随着智慧城市建设过程中地名地址标准化采集整合更新机制的逐步完善,需要对地名地址描述的丰富语义进行表达,而图数据库、全文索引技术的成熟,使基于图结构的地名地址解析成为可能。
因此,有必要开发一种基于图结构的地名地址的解析方法,通过定义地名地址图模型,构建地名地址图数据库,设计地名地址路径匹配方法,实现快速准确的解析地名地址。
技术实现要素:
本发明要解决的技术问题是提供一种基于图结构的地名地址的解析方法,通过定义地名地址图模型,构建地名地址图数据库,设计地名地址路径匹配方法,实现对地名地址的解析,从而实现快速准确地解析地名地址,且具有更好的解析广度。
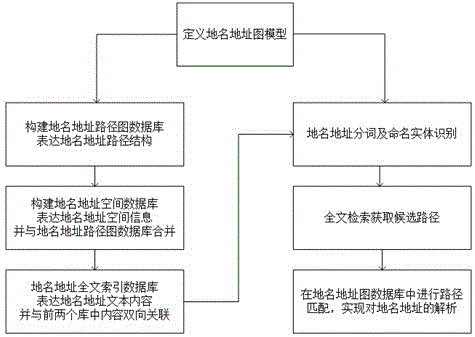
为了解决上述技术问题,本发明采用的技术方案是:该基于图结构的地名地址的解析方法,具体包括以下步骤:
s1定义地名地址图模型,用以表达地名地址的路径结构;
s2基于涉及地名地址的基础地理信息数据以及专题地理信息数据,构建地名地址路径图数据库、地名地址空间数据库和地名地址全文索引数据库,用于表达地名地址路径结构、地名地址空间信息和地名地址文本内容,并将所述地名地址空间数据库和地名地址路径图数据库合并;
s3基于地名地址图结构的解析方法,首先进行分词及命名实体识别,再通过全文索引获取候选路径,然后在地名地址图数据库中进行路径匹配,实现对地名地址的解析。
作为本发明的优选技术方案,所述步骤s2具体包括以下步骤:s21构建地名地址路径图数据库:基于兼容步骤s1定义的所述地名地址图模型,根据基底地名地址构建所述地名地址路径图数据库,所述地名地址路径图数据库包括主干地名地址图结构和外部地名地址图结构;
s22构建地名地址空间信息数据库:根据基底地名地址的要素信息以及空间网络模型,并进行空间索引,将r树和网络拓扑索引树合并入所述地名地址路径图数据库;
s23构建地名地址全文索引内容数据库:构建地名地址文本的全文索引,可针对地名地址的通名、专名、拼音、类型进行全文检索;
s24将合并后的地名地址路径图数据库和地名地址空间信息数据库与所述地名地址全文索引数据库的同一地名地址进行双向关联,当出现数据不一致时,以所述地名地址空间信息数据库作为数据一致性的基准;解析的遍历过程以所述地名地址路径图数据库及与其合并的所述地名地址空间信息数据库为核心。
作为本发明的优选技术方案,所述步骤s3基于地名地址图结构的解析方法包括分词及命名实体识别,全文检索获取候选路径,在所述地名地址图数据库中进行路径匹配;具体包括以下步骤:
s31地名地址进行分词及命名实体识别:采用自然语言处理的规则方法或机器学习方向进行分词及命名实体识别;针对分词及命名实体识别的模型训练,可以通过s21地名地址路径图数据库的遍历生成丰富的地名地址组合作为语料,支撑训练模型对于长程文本信息的建模;分词及命名实体识别获取待解析的n个地名地址候选分词结果si=sp1|sp2|...|spm,对应置信度为sci;
s32全文索引获取候选路径:对每个地名地址候选分词结果si,对所述分词结果si中含文本描述的地名spj在所述地名地址全文索引数据库中进行全文检索,获取候选地名地址节的id集合idsj,构建候选地名地址路径集合psi=ids1->ids2->...->ids,其中地名为id集合,地址仍为数字符号;->表示路径走向集合,所有的候选路径为前后ids的笛卡尔积;可根据阈值删去在连续ids中的低匹配度的候选地名地址节id,从而减少候选路径的数量;
s33在所述地名地址图数据库中进行路径匹配:对每个地名地址候选路径集合psi,在所述地名地址路径图数据库中进行路径匹配,根据地名地址的领域特点,采用路径匹配算法计算匹配度,实现对地名地址的解析。
作为本发明的优选技术方案,所述主干地名地址图结构为树状结构,分为三大层分别为:包含省市县和街道社区的区划地名、包含街路巷及物业小区的骨架地名、包含门楼牌、楼幢、层户的地址。在地名地址图模型中,各节点(node)表达地名地址的位置语义(空间坐标、类型属性等),关系(relationship)默认为地名地址节点间的最基本的“包含/隶属”关系。
作为本发明的优选技术方案,所述外部地名地址图结构为包含描述信息的外部地名地址,所述描述信息包括兴趣点、道路交汇点、出入口;所述外部地名地址图结构的外部地名地址节点以多链接的方式接入所述主干地名地址图结构的地名地址节点中,形成网状结构。外部地名地址图结构表达更为丰富复杂的外部地名地址,其中,关系则为地名地址文本中描述的各类空间关系以及逻辑关系。此地名地址图模型,标准地名地址部分,对地名地址分类体系不作约束,兼容现有国家标准、行业标准,通过外部地名地址灵活支持图结构中节点与关系的扩展。
作为本发明的优选技术方案,所述步骤s33采用路径匹配算法计算匹配度的过程为:
s331遍历入口选择:将描述信息丰富的所述外部地名地址作为入口,或以所述骨架地名作为入口进行双向遍历;即当兴趣点(poi)等描述信息丰富的外部地名地址为主的情况下,兴趣点(poi)作为遍历入口,否则以骨架地名作为入口进行双向遍历;
s332遍历过程策略:从入口节点开始进行双向遍历,当前序遍历无法匹配时,则后续遍历停止;对于有多个入口节点可并行遍历,从而支持map-reduce方法;在遍历过程中若涉及空间关系,则采用显性保存的空间关系路径,反之则进入所述地名地址空间信息数据库空间索引树继续遍历;可以在遍历之前整体先做全文检索,或延迟至遍历过程中进行单个地名地址节的全文检索,即在前序或后续遍历时,根据对应分词文本,实时获取候选地名地址节,进行过滤;
s333遍历结果匹配度计算:针对每个所述地名地址候选路径集合psi的每条所述地名地址路径,根据其在所述地名地址路径图数据库中遍历匹配的路径长度以及中间关系间隔设置匹配度pm,并结合对应置信度sci加权作为解析结果的匹配度。其中,中间关系间隔,针对空间索引、区划地名、骨架地名、地址、以及外部地名地址需设置不同的权重。
与现有技术相比,本发明具有的有益效果为:基于图结构将地名地址路径与其空间索引与全文索引进行了统一,较传统基于全文索引及标准地址结构的地名地址解析方法,能更好的表达地名地址的丰富语义,具有更好的解析广度(鲁棒性)。
附图说明
图1是本发明基于图结构的地名地址的解析方法的流程图;
图2是本发明基于图结构的地名地址的解析方法的地名地址图模型及数据库架构示意图;
图3是本发明基于图结构的地名地址的解析方法的地名地址解析方法示例图。
具体实施方式
下面将结合本发明的实施例图中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。
实施例:如图1所示,该基于图结构的地名地址的解析方法,具体包括以下步骤:
s1定义地名地址图模型(见图2地名地址图模型及数据库架构),用以表达地名地址的路径结构:
s11主干地名地址图结构为树状结构,表达标准地名地址,分为三大层:省市县、街道社区等为区划地名(树状结构),街路巷及物业小区(街道社区)等为骨架地名,门楼牌、楼幢、户室号为地址(树状结构为主);在地名地址图模型中,各节点(node)表达地名地址的位置语义(空间坐标、类型属性等),关系(relationship)默认为地名地址节点间的最基本的“包含/隶属”关系;
s12外部地名地址图结构,表达更为丰富复杂的外部地名地址:兴趣点(poi)、道路交汇点、出入口、城市部件编号等外部地名地址节点以多链接的方式接入主干地名地址图结构的地名地址节点中,形成网状结构;比如,兴趣点(poi)可灵活的链接至街路巷、物业小区、门楼牌、户室号;此外,而除默认的最基本的“包含/隶属”关系外,所有空间关系以及逻辑关系都可以表达,比如出入口与物业小区的连通性,以及公司法人、子公司等;
s13此地名地址图模型,标准地名地址部分,对地名地址分类体系不作约束,兼容现有国家标准、行业标准,通过外部地名地址灵活支持图结构中节点与关系的扩展;
s2基于涉及地名地址的基础地理信息数据以及专题地理信息数据,构建表达地名地址空间信息、地名地址路径结构、地名地址文本内容的三个数据库,分别为地名地址路径图数据库、地名地址空间数据库、地名地址全文索引数据库(并将前两个库合并,见图2地名地址图模型及数据库架构);
s21构建地名地址路径图数据库:基于兼容s1定义的地名地址图模型,根据基底地名地址构建表达地名地址路径结构的图数据库,包括主干地名地址图结构与外部地名地址图结构;可将现有基于关系型数据库的标准地名地址普查成果(一般对应主干地名地址图结构),整合导入neo4j等图数据库中进行构建,由于图数据库“关系与对象具有同等地位”,因此可兼容各类地名地址标准的表达;然后根据兴趣点(poi)等,构建外部地名地址图结构,这部分的更新较主干地名地址图结构而言,更为灵活与频繁;
s22构建地名地址空间数据库(空间索引):根据基底地名地址的要素信息以及空间网络模型,并进行空间索引,r树、网络拓扑等索引树合并入s21地名地址路径图数据库;实施时两者尽量在同一数据库中,避免遍历时通讯损耗,比如neo4j图数据库支持空间索引与网络拓扑;参见图2地名地址空间数据库(空间索引)部分,左侧为要素空间索引的构建,可采用r树、r+树、r*树等树状结构的索引,右侧为线要素网络拓扑(连通性等)的网状表达;再与图2地名地址路径图数据库(地名地址图模型)部分进行合并,比如物业小区d1即链接在空间索引的r树中,也作为骨架地名链接在地名地址路径图数据库中;而物业小区d4与道路l31的邻近关系,也可以在r树与网络拓扑间增加;
在此基础上,可通过定期进行批量空间分析操作,将各地名地址要素的空间关系显性保存至s21地名地址路径图数据库中,尤其是针对较为灵活s12外部地名地址图结构;为使空间索引树状结构更好的融入,可将地名地址要素的几何体扩展为包含下一层地名地址的包络面;比如,针对街路巷,可将其包含的所有门楼牌的点一并作为该街路巷的包络面;
s23构建地名地址全文索引数据库:构建地名地址文本的全文索引,可针对地名的通名、专名、拼音、类型等进行全文索引,一般不需要对地址进行全文索引;可采用支持倒排索引的文档型数据库以及全文索引数据库,比如lucene、elasticsearch、solr等;
s24针对合并的s21&s22,与s23中的同一地名地址进行双向关联:数据一致性以s22地名地址空间数据库的基底数据为基准,而解析的遍历过程以s21地名地址路径图数据库以及与其合并的s22地名地址空间数据库为核心;参见图2地名地址全文索引数据库中,南京西路l31即为上部两个合并数据库中的l31节点;实施时,由于地名文本通名专名的特殊性,可采用图数据库附带的轻量全文索引引擎,比如lucene;
s3基于地名地址图结构的解析方法:分词及命名实体识别>全文检索获取候选路径>在地名地址图数据库中进行路径匹配;
待解析的地名地址描述具有多样性与模糊性,如图3示例“南京北京路和才大厦附近书店”的解析,对应的标准地名地址路径为“南京市>北京东路>63号>人才大厦>书店a(书店b……)”,即在s21&s22中包含了上述地名地址路径;
s31地名地址分词及命名实体识别:采用自然语言处理的规则方法或机器学习方向进行分词及命名实体识别;针对分词及命名实体识别的模型训练,可以通过s21地名地址路径图数据库的遍历生成丰富的地名地址组合作为语料,支撑训练模型对于长程文本信息的建模;分词及命名实体识别获取待解析的n个地名地址候选分词结果si=sp1|sp2|...|spm,对应置信度为sci;
如图3示例的一个分词结果“南京|cit北京路|str63号|tab和才大厦|poi附近|ner书店|typ”,其中,cit等为分词后地名地址节的类型;
s32全文检索获取候选路径:针对每个地名地址候选分词结果si,对其分词结果含文本描述的地名部分spj在s23地名地址全文索引数据库中进行全文检索,获取候选地名地址节的id集合idsj,构建候选地名地址路径集合psi=ids1->ids2->...->idsm(地名为id集合,地址仍为数字符号);其中,->表示路径走向集合,故所有的候选路径为前后ids的笛卡尔积;可根据阈值删去在连续ids中的低匹配度的候选地名地址节id,从而减少候选路径的数量;
如图3示例全文检索后,根据“北京路|str”可获取南京市的“北京西路l21”、“北京东路l22”等主干地名地址节点,以及其他城市的“北京东路lxx”主干地名地址节点;此例中,兴趣点(poi)“和才大厦”较为模糊,可获取“和平大厦d2”、“人才大厦d1”等较多外部地名地址节点;
s33针对每个地名地址候选路径集合psi,在s21地名地址图数据库中进行路径匹配,即将地名地址解析问题转化为地名地址路径匹配问题;针对地名地址的领域特点,对路径匹配算法可进行优化:
s331遍历入口选择:当兴趣点(poi)等描述信息丰富的外部地名地址为主的情况下,兴趣点(poi)作为遍历入口,否则以骨架地名作为入口进行双向遍历;如图3示例,从“北京西路l22”、“北京东路l22”、“北京东路l88”等进行双向遍历;
s332遍历匹配策略:从入口节点开始进行双向遍历,当前序遍历无法匹配时,则后续遍历停止;针对多个入口节点可并行遍历,从而支持map-reduce方法;如图3示例,“北京东路l88”向前序遍历时,无法匹配“南京市025”,故后续遍历停止;遍历过程中如涉及空间关系,即可采用显性保存的空间关系路径,也可进入s22地名地址空间数据库空间索引树继续遍历;如图3示例,遍历至“人才大厦d1”地名地址节点时,如在定期批量空间分析操作时,已将“书店ad3”地名地址节点进行了链接,则直接遍历;另参见图2,通过r树中的一系列闭包矩形还可遍历至“书店bd4”;可在遍历之前整体先做全文检索,或也可延迟至遍历过程中进行个别的全文检索,即在前序或后续遍历时,根据对应分词文本,实时获取候选地名地址节,进行过滤;如图3示例,可在遍历至对应“和才大厦”文本时,再进行全文检索,从而通过过滤遍历至“人才大厦d1”;
s333遍历结果匹配度计算:针对每个地名地址候选路径集合psi的每条匹配成功的地名地址路径,根据其在地名地址图数据库中遍历匹配的路径长度以及中间关系间隔设置匹配度pm,并结合sci加权作为最终解析结果的匹配度;其中,中间关系间隔,针对空间索引、区划地名、骨架地名、地址、以及外部地名地址需设置不同的权重;如图3示例,遍历匹配至“书店bd4”的中间关系间隔虽然大于遍历匹配至“书店ad3”,但只要空间索引节点长度在阈值内,则可认为两者匹配度一样;实施时,可采用支持cypher等查询语句的图数据库,通过“...”等关键字进行有中间关系间隔的遍历匹配;地名地址全文索引数据库地名地址全文索引数据库地名地址全文索引数据库地名地址全文索引数据库。
以上所述仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!