一种面向任务智能调度的网络结构自适应优化方法与流程
本发明涉及信息处理技术领域,尤其是涉及一种高度智能化、大量节省资源与时间开销提高人物调度效率的面向任务智能调度的网络结构自适应优化方法。
背景技术:
在大数据、云计算和人工智能时代,数据的密集计算往往不能依靠单一的处理器完成,需要依赖于分布式环境下的异构计算系统。分布式异构计算系统已经成为数据中心广泛采用的计算体系结构,而分布式异构计算系统中的任务调度是计算机体系结构研究领域中的热点问题之一,且已被证明是np完全问题。早期的科学研究提出了以启发式调度为主的调度算法,但随着软硬件环境的更新迭代,传统的启发式调度方法因为泛化性和自适应能力较差,很难普遍适用于新型的应用场景,导致其在新应用和新硬件系统中不能充分发挥系统效率。
近年来随着机器学习领域研究的不断深入,基于机器学习在调度方面的应用开始迅速发展。基于机器学习的调度方法具有传统调度方法不具备的高度自适应能力,能够满足现代软硬件复杂环境的复合需求,对提升系统效率、提高系统自适应能力等方面存在着巨大潜力。在机器学习领域众多分支中,基于强化学习方法探索策略的组合优化性问题解决调度应用问题引起了最为广泛的关注。alphago面世的空前成功证明了强化学习与“已知环境下的有限策略集中寻求最优策略”类型的问题具有相当高的契合度,而调度也同属该类型问题。因此在过去的几年里,基于q-learning、dqn、mcts等强化学习方法在调度方面均有研究与应用的相关实验,大量实验结果表明,一方面,基于强化学习的调度方法使计算机系统的自适应能力大幅提高,更符合现代大数据、智能化、云计算环境下多目标异构系统的复杂需求;另一方面,由于这些模型的设计并非专为调度问题而生,因此大多通用性较差,同时,由于策略网络模型的输入没有考虑硬件资源拓扑关系,调度策略的探索会产生大量无效策略,导致所需的训练时间长,同时需要大规模硬件计算资源的支撑。因此,基于强化学习的任务调度方法能更好地满足现代计算系统的复杂需求,提高系统效率和自适应能力,但同时也存在建模难度高、算法训练时间长、训练所需的计算资源大等问题。
例如,一种在中国专利文献上公开的“一种异构集群中任务调度方法、装置及电子设备”,其公告号cn110489223a,包括针对各个计算节点,确定调度至该计算节点的各个任务;将各个子任务分别划分为多个子任务;当子任务对应的父子任务执行完成时,将子任务添加到就绪子任务队列中;针对就绪子任务队列中的各个第一子任务,当该第一子任务在图形处理器gpu计算单元的执行速率大于该第一子任务在中央处理器cpu计算单元的执行速率,则将该第一子任务添加至gpu子任务队列;根据gpu子任务队列中各个第二子任务与gpu正在执行的子任务的干扰关系,将各个第二子任务调度至第二子任务对应的目标gpu。尽管该方案提高了异构集群的系统吞吐量,但其节点和连接的数量级庞大,极大地增加了系统的不必要开销,增大了连接的资源与时间开销。
技术实现要素:
本发明是为了克服现有技术的系统不必要开销大、连接的时间和资源开销大的问题,提供一种面向任务智能调度的网络结构自适应优化方法,本发明能够提供极易适合于做任务调度的神经网络,使神经网络的拓扑结构自适应进化成适合做调度的网络结构,缩短任务完成的最大完成时间,提高任务的调度效率,且确保在发挥性能优势的同时尽可能减少节点和连接的资源与时间开销。
为了实现上述目的,本发明采用以下技术方案:
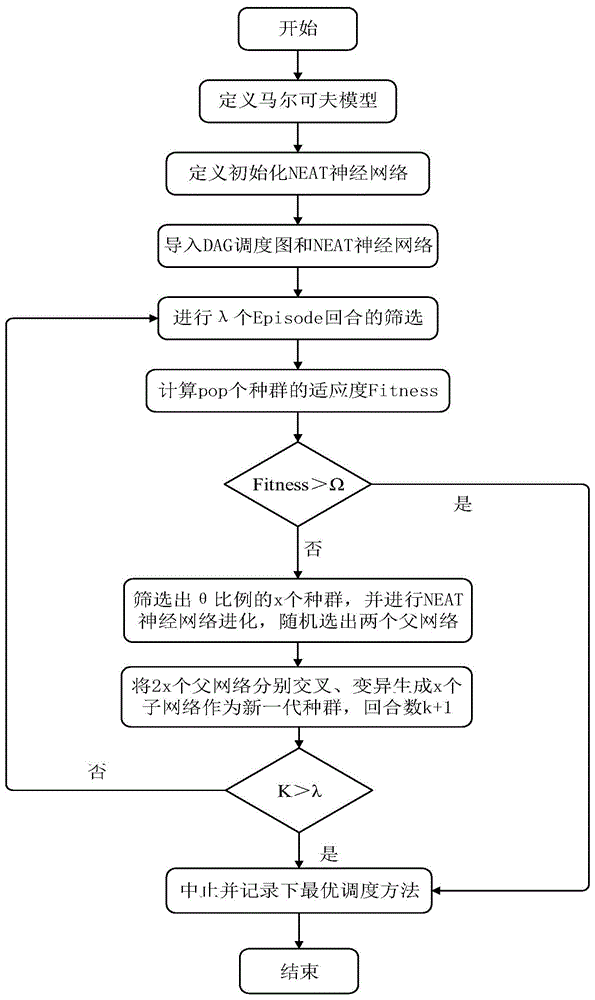
一种面向任务智能调度的网络结构自适应优化方法,其特征在于,包括以下步骤:
s1:定义马尔可夫模型;
s2:定义初始化neat神经网络;
s3:导入dag调度图和neat神经网络;
s4:进行λ个episode回合的筛选;
s5:计算pop个种群的适应度fitness;对fitness进行判断,若fitness大于ω,中止并记录最优调度方法,否则进行s6;
s6:筛选出θ比例的x个种群,并进行neat神经网络进化,随机选出两个父网络;
s7:将2x个父网络分别交叉、变异生成x个子网络作为新一代种群,回合数k+1;
s8:对s7中的k进行判断,若k大于λ,中止并记录下最优调度方法,否则返回s4;
其中,λ为最大回合数,ω为阈值,pop为种群数,所述s6中的进化包括复制、交叉和变异操作。
本发明首先导入调度模型,根据调度模型定义马尔可夫模型(s,a,r,s',γ)各参数代表意义,初始化进化神经网络neat各项参数;随后进行最多λ个回合的循环,每个回合包括马尔可夫过程和进化过程:马尔可夫过程通过计算适应度fitness评价每一代pop个神经网络的性能优劣,筛选出比率为θ的优良神经网络,进化过程通过复制、交叉、变异操作生成下一代神经网络;最后,当出现fitness大于阈值ω的神经网络或λ个回合结束时,停止实验并记录fitness最高的神经网络,该网络结构及其调度策略即为该调度模型下找到的最优网络结构及调度策略。本发明提出的进化神经网络结合强化学习的调度模型结构简单,可节省大量资源与时间开销,同时能使神经网络的拓扑结构自适应进化成适合做调度的网络结构,缩短任务最大完成时间,提高任务的调度效率。
作为优选,所述s1包括以下步骤:
s11:定义马尔可夫模型(s,a,r,s',γ)进行决策;
s12:dag调度初始化定义两个队列,未完成的任务队列queue1和已完成任务队列queue2,将state(n)定义为queue1队列当前的状态,其中state(0)对应queue1队满状态,此时所有任务均未调度;state(n)对应queue1队空状态,此时所有任务已调度完毕,一个episode回合结束;
π(a|s)=p[at=a|st=s]
s13:一个episode回合结束时,得到奖励累加值gt,
其中,马尔可夫模型中,s表示state状态、a表示action动作、r表示reward奖励值、s'表示state'下一状态,γ表示衰减系数;
任务调度完毕的过程就是寻找最优策略的过程,π为策略符号,是指给定状态s时,动作集上的动作的一个分布;π(a|s)在状态s时的所有动作a(i)的分布集合,统称为状态s下的策略;a为动作,s为状态,at=a表示在t时刻选择的动作a,st=s表示在t时刻的状态s;
qπ(s,a)表示状态-行为值函数,qπ(s,a)的意义为计算基于t时刻的状态state(st=s),选择一个动作action(at=a)后能获得的未来回报reward奖励的期望总和eπ,eπ[gt|s,a]表示s状态下动作a的奖励值总和gt的期望函数;
gt表示奖励值总和,r(i)表示action(i)执行后获得的即时奖励,γr(t+2)表示在t时刻往后计算奖励时,每多过一步会产生γ∈(0,1)的奖励衰减,因此r(t+k+1)前系数为γ的k次方,在s4中也包括gt奖励值总和。
作为优选,所述s2中初始化neat神经网络包括输入层和输出层。
neat神经网络不仅会训练和修改网络的权值,同时会修改网络的拓扑结构,包括新增或删除节点、增加节点间连线等操作。初始的neat神经网络只有输入层和输出层,随着episode回合的迭代和种群间基于种群适应度fitness计算的筛选评价机制,好的neat神经网络种群被筛选出来并进一步演化为更深层、更复杂、性能更优良的网络。显然,不同的任务模型将会使neat神经网络演化为完全各异的,本发明的模型训练的neat神经网络适合该dag模型对应的调度任务,相比传统的全连接神经网络其性能更强,资源开销更小。
作为优选,所述s3包括以下步骤:
s31:导入dag调度图和neat神经网络;
s32:设置输入和输出节点数;
s33:设置初始种群数pop、终止条件ω、最大回合数λ、种群存活率θ、种群变异各方向概率ε;
其中,输入节点对应调度任务数n,输出节点对应处理器数p。
作为优选,所述s4包括以下步骤:
s41:将每个episode回合分成n个step,分别对应n个任务的调度过程;
s42:第k个episode回合中,在step(i)时,将当前state(i)输入neat神经网络并采用输出中value值最大的action(i),同时获得reward(i);
s43:循环执行step直至i>n,当前episode回合结束,将reward累加得到该种群在该episode回合获得的总价值accumulation(k);
其中,step(i)第i步’,总价值accumulation(k)与s2中的gt奖励值总和。
作为优选,所述s5包括以下步骤:
s51:将pop个种群分别执行步骤s4得到pop个accumulation;
s52:选取pop个accumulation的最小值计算种群适应度fitness;
s53:计算第k代种群适应度fitness(k);
s54:’对fitness(k)进行判断,若fitness大于ω,表示任务调度已达到期望值,此时中止并记录最优调度方法,否则进行s6;
其中,fitness(k)为第k代种群适应度,ω为阈值。
根据木桶效应,选用pop个accumulation的最小值能够得出最为可靠的结果。
作为优选,所述s53的计算方式为:
其中,fitness(k)为第k代种群适应度,accumulation(k)为总价值,step表示调度过程总共需要调度任务的次数。
作为优选,所述s6包括以下步骤:
s61:根据遗传算法的轮盘赌淘汰制筛选出θ比例的x个种群;
s62:进行neat神经网络进化,随机选出两个父网络。
作为优选,所述s62包括以下步骤:
s621:进行neat神经网络复制,将保留的种群网络拷贝一份,使总数变成2x;
s622:进行neat神经网络交叉,随机选出两个neat网络parent1和parent2为父网络,将两个网络的节点信息对齐,生成一个全新的子网络,子网络的信息随机从双亲中某一个获得;
s623:进行neat神经网络变异,生成的子网络每个节点均有ε的概率产生多种变异。
作为优选,所述s623中的多种变异包括增加中间节点、减少中间节点、节点间添加连线和改变连线权重。
因此,本发明具有如下有益效果:
1.本发明首先导入调度模型,根据调度模型定义马尔可夫模型(s,a,r,s',γ)各参数代表意义,初始化进化神经网络neat各项参数;随后进行最多λ个回合的循环,每个回合包括马尔可夫过程和进化过程:马尔可夫过程通过计算适应度fitness评价每一代pop个神经网络的性能优劣,筛选出比率为θ的优良神经网络,进化过程通过复制、交叉、变异操作生成下一代神经网络;最后,当出现fitness大于阈值ω的神经网络或λ个回合结束时,停止实验并记录fitness最高的神经网络,该网络结构及其调度策略即为该调度模型下找到的最优网络结构及调度策略。本发明提出的进化神经网络结合强化学习的调度模型结构简单,可节省大量资源与时间开销,同时能使神经网络的拓扑结构自适应进化成适合做调度的网络结构,缩短任务最大完成时间,提高任务的调度效率;
2.初始的neat神经网络只有输入层和输出层,随着episode回合的迭代和种群间基于种群适应度fitness计算的筛选评价机制,好的neat神经网络种群被筛选出来并进一步演化为更深层、更复杂、性能更优良的网络;本发明的模型训练的neat神经网络适合该dag模型对应的调度任务,相比传统的全连接神经网络其性能更强,资源开销更小;
3.相比于传统启发式或基于普通全连接神经网络的调度模型和算法,本发明可以根据不同任务模型使神经网络向不同方向进化,自适应能力强;同时,节点和连接数极少,能够节省资源与时间开销,既能改变节点和连接的拓扑关系,也可以改变连接权重值,变化方式灵活,完全跳出传统神经网络的梯度下降,避免陷入局部最优。
附图说明
图1是本发明的流程图。
图2是本发明的一种实施例的工作流程图。
图3是本发明neat神经网络增加连接和节点的示意图。
图4是本发明两个neat神经网络交叉产生新网络的示意图。
图5是本发明λ个episode回合中neat最优网络的进化过程示意图。
图6是本发明性能变化示意图。
图7是本发明种群分化示意图。
具体实施方式
下面结合附图与具体实施方式对本发明做进一步的描述。
实施例1:
本实施例一种面向任务智能调度的网络结构自适应优化方法,如图1所示,包括以下步骤:
s1:定义马尔可夫模型;
s2:定义初始化neat神经网络;
s3:导入dag调度图和neat神经网络;
s4:进行λ个episode回合的筛选;
s5:计算pop个种群的适应度fitness;对fitness进行判断,若fitness大于ω,中止并记录最优调度方法,否则进行s6;
s6:筛选出θ比例的x个种群,并进行neat神经网络进化,随机选出两个父网络;
s7:将2x个父网络分别交叉、变异生成x个子网络作为新一代种群,回合数k+1;
s8:对s7中的k进行判断,若k大于λ,中止并记录下最优调度方法,否则返回s4;
其中,λ为最大回合数,ω为阈值,pop为种群数,所述s6中的进化包括复制、交叉和变异操作。
首先导入调度模型,根据调度模型定义马尔可夫模型(s,a,r,s',γ)各参数代表意义,初始化进化神经网络neat各项参数;随后进行最多λ个回合的循环,每个回合包括马尔可夫过程和进化过程:马尔可夫过程通过计算适应度fitness评价每一代pop个神经网络的性能优劣,筛选出比率为θ的优良神经网络,进化过程通过复制、交叉、变异操作生成下一代神经网络;最后,当出现fitness大于阈值ω的神经网络或λ个回合结束时,停止实验并记录fitness最高的神经网络,该网络结构及其调度策略即为该调度模型下找到的最优网络结构及调度策略。本发明提出的进化神经网络结合强化学习的调度模型结构简单,可节省大量资源与时间开销,同时能使神经网络的拓扑结构自适应进化成适合做调度的网络结构,缩短任务最大完成时间,提高任务的调度效率。
下面说明本发明的另一方面实施例2:
如图2-5所示,本实施例的一种工作流程,具体包括以下步骤:
s1:定义马尔可夫模型。
步骤s1包括以下步骤:
s11:定义马尔可夫模型(s,a,r,s',γ)进行决策;
s12:dag调度初始化定义两个队列,未完成的任务队列queue1和已完成任务队列queue2,将state(n)定义为queue1队列当前的状态,其中state(0)对应queue1队满状态,此时所有任务均未调度;state(n)对应queue1队空状态,此时所有任务已调度完毕,一个episode回合结束;
π(a|s)=p[at=a|st=s]
s13:一个episode回合结束时,得到奖励累加值gt,
其中,马尔可夫模型中,s表示state状态、a表示action动作、r表示reward奖励值、s'表示state'下一状态,γ表示衰减系数;
任务调度完毕的过程就是寻找最优策略的过程,π为策略符号,是指给定状态s时,动作集上的动作的一个分布;π(a|s)在状态s时的所有动作a(i)的分布集合,统称为状态s下的策略;a为动作,s为状态,at=a表示在t时刻选择的动作a,st=s表示在t时刻的状态s;
qπ(s,a)表示状态-行为值函数,qπ(s,a)的意义为计算基于t时刻的状态state(st=s),选择一个动作action(at=a)后能获得的未来回报reward奖励的期望总和eπ,eπ[gt|s,a]表示s状态下动作a的奖励值总和gt的期望函数;
gt表示奖励值总和,r(i)表示action(i)执行后获得的即时奖励,γr(t+2)表示在t时刻往后计算奖励时,每多过一步会产生γ∈(0,1)的奖励衰减,因此r(t+k+1)前系数为γ的k次方,在s4中也包括gt奖励值总和。
s2:定义初始化neat神经网络。
neat神经网络不仅会训练和修改网络的权值,同时会修改网络的拓扑结构,包括新增或删除节点、增加节点间连线等操作。初始的neat神经网络只有输入层和输出层,随着episode回合的迭代和种群间基于种群适应度fitness计算的筛选评价机制,好的neat神经网络种群被筛选出来并进一步演化为更深层、更复杂、性能更优良的网络。显然,不同的任务模型将会使neat神经网络演化为完全各异的,本发明的模型训练的neat神经网络适合该dag模型对应的调度任务,相比传统的全连接神经网络其性能更强,资源开销更小。
s3:导入dag调度图和neat神经网络。
其中,步骤s3包括以下步骤:
s31:导入dag调度图和neat神经网络;
s32:设置输入和输出节点数;
s33:设置初始种群数pop、终止条件ω、最大回合数λ、种群存活率θ、种群变异各方向概率ε;
其中,输入节点对应调度任务数n,输出节点对应处理器数p。
s4:进行λ个episode回合的筛选。
其中,步骤s4包括以下步骤:
s41:将每个episode回合分成n个step,分别对应n个任务的调度过程;
s42:第k个episode回合中,在step(i)时,将当前state(i)输入neat神经网络并采用输出中value值最大的action(i),同时获得reward(i);
s43:循环执行step直至i>n,当前episode回合结束,将reward累加得到该种群在该episode回合获得的总价值accumulation(k);
其中,step(i)第i步’,总价值accumulation(k)与s2中的gt奖励值总和。
s5:计算pop个种群的适应度fitness;对fitness进行判断,若fitness大于ω,中止并记录最优调度方法,否则进行s6。
其中,步骤s5具体包括以下步骤:
s51:将pop个种群分别执行步骤s4得到pop个accumulation;
s52:选取pop个accumulation的最小值计算种群适应度fitness;
s53:计算第k代种群适应度fitness(k):
其中,fitness(k)为第k代种群适应度,accumulation(k)为总价值,step表示调度过程总共需要调度任务的次数;
s54:,对fitness(k)进行判断,若fitness大于ω,表示任务调度已达到期望值,此时中止并记录最优调度方法,否则进行s6;
其中,fitness(k)为第k代种群适应度,ω为阈值。
s6:筛选出θ比例的x个种群,并进行neat神经网络进化,随机选出两个父网络。其中,步骤s6具体包括以下步骤:
s61:根据遗传算法的轮盘赌淘汰制筛选出θ比例的x个种群;
s62:进行neat神经网络进化,随机选出两个父网络。
步骤s62包括以下步骤:
s621:进行neat神经网络复制,将保留的种群网络拷贝一份,使总数变成2x;
s622:进行neat神经网络交叉,随机选出两个neat网络parent1和parent2为父网络,将两个网络的节点信息对齐,生成一个全新的子网络,子网络的信息随机从双亲中某一个获得;
s623:进行neat神经网络变异,生成的子网络每个节点均有ε的概率产生多种变异,包括增加中间节点、减少中间节点、节点间添加连线和改变连线权重。
下面对本发明的效果进行说明,如图6、图7所示,图6是本发明性能变化示意图,图中下方的曲线为平均种群适应度average_fitness,图中上方的曲线为最优种群适应度best_ffitnes,图中的曲线越高表示效果越好;图7是本发明种群分化示意图,表示初始pop个种群,经过n个回合后演化成多个不同种群。
本发明首先导入调度模型,根据调度模型定义马尔可夫模型(s,a,r,s',γ)各参数代表意义,初始化进化神经网络neat各项参数;随后进行最多λ个回合的循环,每个回合包括马尔可夫过程和进化过程:马尔可夫过程通过计算适应度fitness评价每一代pop个神经网络的性能优劣,筛选出比率为θ的优良神经网络,进化过程通过复制、交叉、变异操作生成下一代神经网络;最后,当出现fitness大于阈值ω的神经网络或λ个回合结束时,停止实验并记录fitness最高的神经网络,该网络结构及其调度策略即为该调度模型下找到的最优网络结构及调度策略。
本发明提出的进化神经网络结合强化学习的调度模型结构简单,可节省大量资源与时间开销,同时能使神经网络的拓扑结构自适应进化成适合做调度的网络结构,缩短任务最大完成时间,提高任务的调度效率;初始的neat神经网络只有输入层和输出层,随着episode回合的迭代和种群间基于种群适应度fitness计算的筛选评价机制,好的neat神经网络种群被筛选出来并进一步演化为更深层、更复杂、性能更优良的网络;本发明的模型训练的neat神经网络适合该dag模型对应的调度任务,相比传统的全连接神经网络其性能更强,资源开销更小;进化神经网络与传统的bp神经网络最大的差别在于它不是依靠梯度下降法反向传播更改连接权重,而是同时改变神经网络的拓扑结构和连接权重,每代神经网络进化有x概率改变拓扑结构,包括增加节点,删除节点,增加连接,减少连接四种方式,y概率采用区间随机赋值的方式改变连接权重。这种对神经网络的优化方式可以完全跳出局部最优的性能局限。但由于进化方向具有随机性,因此需要利用到遗传算法的筛选机制,同时对种群总数为pop的神经网络进行不同方向的进化,并筛选出表现最优的网络。被筛选出的最优神经网络根据遗传算法的交叉和变异操作生成下一代种群数为pop的神经网络,然后继续筛选和进化。通过这种机制,在保证每一代神经网络性能表现不差于前一代的同时提供了新的可能性,从而使神经网络向着更优性能不断靠拢直至收敛。相比于全连接神经网络动辄成百上千的中间层节点,进化神经网络中间层往往只有几个节点和十几个连接。
相比于传统启发式或基于普通全连接神经网络的调度模型和算法,本发明可以根据不同任务模型使神经网络向不同方向进化,自适应能力强;同时,节点和连接数极少,能够节省资源与时间开销,既能改变节点和连接的拓扑关系,也可以改变连接权重值,变化方式灵活,完全跳出传统神经网络的梯度下降,避免陷入局部最优。
上述实施例对本发明的具体描述,只用于对本发明进行进一步说明,不能理解为对本发明保护范围的限定,本领域的技术工程师根据上述发明的内容对本发明作出一些非本质的改进和调整均落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!