一种OCR识别模型训练中的动态数据增强方法与流程
本发明涉及一种ocr识别方法,尤其是涉及一种ocr识别模型训练中的动态数据增强方法。
背景技术:
使用数据增强技术主要是在训练数据上增加微小的扰动或者变化,一方面可以增加训练数据,提升模型的泛化能力,另一方面可以增加噪声数据,从而增加模型的鲁棒性。
针对ocr文本数据增强,目前主要有两种思路:i.采用基于几何变换的方法(如空间几何变换、像素颜色变换、模糊)的固定组合或者随机组合对已有的训练样本进行数据增强,获取更为丰富的样本;ii.由于ocr识别文本的内容非常广泛,如票据和行驶证中姓名和医院中的生僻字,通过样本的图像变换并不能增加该类样本的多样性,因此需要利用样本合成的思路进行数据增强,从而获得生僻字对应的训练样本。
技术实现要素:
本发明提供了一种ocr识别模型训练中的动态数据增强方法,用于解决ocr识别模型训练的文本数据增强方式,通过深度学习中结合离线增强和在线增强来提升模型的泛化能力,从而克服以下问题:
(1)目前的数据增强都是在训练模型之前操作的,训练集通常是十万甚至百万数量级别,这对计算机的存储能力有很高的要求;
(2)在训练模型之前进行数据增强具有一定的盲目性,数据增强的目的不仅是获得更多数量的训练样本,而是获得和真实样本更像的更多数量的样本。
其技术方案如下所述:
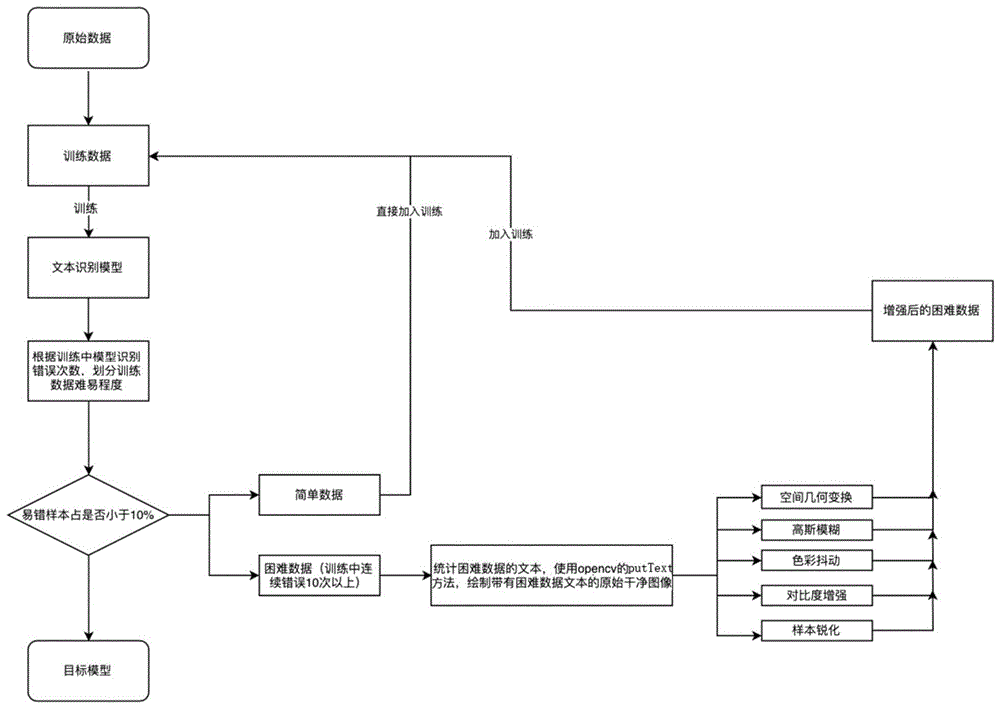
一种ocr识别模型训练中的动态数据增强方法,包括下列步骤:
s1:对原始数据进行标注处理,形成初始训练数据,全部的初始训练数据作为总样本数据;
s2:对初始训练数据进行文本识别的模型训练,获得文本识别模型;
s3:在模型训练的过程中,使用文本识别模型对初始训练数据进行评估,将初始训练数据划分不同类型,并根据评估结果判断初始训练数据的不同类型占比是否符合设定占比条件,符合则转到步骤s5,如果不符合则继续向下处理;
s4:对设定类型的初始训练数据进行数据增强处理,然后与没有进行数据增强处理的其他类型的初始训练数据,作为下一轮的初始训练数据,返回步骤s2;
s5:对每一轮文本识别模型的评估中,根据评估结果判断初始训练数据的不同类型占比是否符合设定占比条件,符合则认为已经形成目标模型,结束训练。
进一步的,步骤s1中,所述原始数据是将多行文本图片按照每行的排布进行分割处理,将多行文本图片切成的长条的文本图片。
步骤s1中,每个长条的文本图片和其对应标注的文字形成一个初始训练数据。
进一步的,步骤s3中,所述评估是使用文本识别模型与初始训练数据对应标注的文字进行比对。
步骤s3中,初始训练数据在模型训练中的连续识别错误超过设定次数,划为困难级别的数据,否则为简单级别的数据。
进一步的,步骤s4中的数据增强处理包括以下步骤:
s41:统计困难级别的初始训练数据的文本信息,使用opencv的puttext方法,绘制对应文本的原始干净图像;
s42:对原始干净图像进行增强处理,获得增强后的困难级别的初始训练数据。
步骤s42中的增强处理包括:(1)空间几何变换类处理;(2)模糊类处理;(3)像素颜色变换类处理;(4)边界变换类处理。
进一步的,步骤s4中,简单级别的初始训练数据,进行如步骤s42的增强处理后,再加入到训练数据的队列中正常进行训练。
进一步的,步骤s1中,所述初始训练数据采用单个字的图片和其对应标注文字。
进一步的,步骤s5中,困难级别的数据的设定占比,设定为少于10%。
所述ocr识别模型训练中的动态数据增强方法是面向文本检测的信息整理方法,具有以下优点:
(1)在训练模型之前进行图像几何和颜色类的变换,获取分布更具有广泛性的样本,通过样本和成的方法,可以解决实际测试样本中的生僻字及印章、竖线干扰的问题。
(2)在训练的过程中动态的进行数据增强,可以提高模型对于检测效果的鲁棒性。
(3)本发明结合了训练之前的离线增强和训练过程中的动态增强,不仅减少了样本在本地的存储空间,提高了训练样本的丰富性及模型的学习能力和鲁棒性,使文本的识别率更高!
附图说明
图1是所述ocr识别模型训练中的动态数据增强方法的流程示意图。
具体实施方式
深度学习是基于大数据的一种方法,因此深度学习网络的表现一般是和数据量成正比的,使用者当然希望数据的规模越大、质量越高越好,模型才有更好的泛化能力,但是在实际采集数据的过程中,往往很难覆盖全部的场景,此外数据的获取也需要大量的成本,而数据增强是扩充数据样本规模的一种有效方法。目前数据增强可以分为两类,一类是离线增强,一类是在线增强。
本发明提供的ocr识别模型训练中的动态数据增强方法,是结合离线和在线的增强方法,能够对文本数据进行更有效的增强,如图1所示,包括以下步骤:
s1:对原始数据进行标注处理,形成初始训练数据;
对于存在多行文本的文本图片,按照每行的排布进行分割处理,将文本图片切成长条,形成原始数据。
对每个长条的文本图片标注出对应的文字,每个长条的文本图片和其对应的文字形成一个初始训练数据,所有长条的文本图片和标注出的对应文字形成全部的初始训练数据,并作为总样本数据。
s2:对初始训练数据进行文本识别的模型训练,获得文本识别模型;
对长条的文本图片进行文本识别,然后将识别后的文字对应保存,形成文本识别模型。
s3:在模型训练的过程中,使用文本识别模型对初始训练数据进行评估,将初始训练数据划分不同类型,并根据评估结果判断初始训练数据的不同类型占比是否符合设定占比条件,符合则转到步骤s5,如果不符合则继续向下处理;
评估是使用文本识别模型与初始训练数据对应标注的文字进行比对,如果比对符合,则说明该初始训练数据为容易识别的,如果不符合,说明该初始训练数据需要重新识别。
其中,模型训练是多次的训练次数,次数可以设定n1,每次模型训练获取的文本识别模型都会与对应标注的文字进行比对,如果初始训练数据在模型训练中的连续识别错误超过设定次数n2,且n2小于n1,比如可以设定n2为10次,则连续识别错误低于10次的初始训练数据被划为简单级别的数据,连续识别错误不小于10次的初始训练数据被划为困难级别的数据。
s4:对设定类型的初始训练数据进行数据增强处理,然后与没有进行数据增强处理的其他类型的初始训练数据,作为下一轮的初始训练数据,返回步骤s2;
比如简单级别的初始训练数据,可以直接加入到训练数据的队列中正常进行训练;而困难级别的初始训练数据会进行数据增强处理后,再加入到训练数据的队列中正常进行训练。
s5:对每一轮文本识别模型的评估中,根据评估结果判断初始训练数据的不同类型占比是否符合设定占比条件,符合则认为已经形成目标模型;
所述困难级别的数据的设定占比,设定为少于10%,这样当初始训练数据达到易错样本占总样本数据的比例小于10%时,则认为符合目标模型的需求,停止训练,不再进入步骤s4,得到的训练数据作为目标训练数据。
进一步的,步骤s4中,困难级别的初始训练数据进行的数据增强处理包括以下几个步骤:
s41:统计困难级别的初始训练数据的文本信息,使用opencv的puttext方法,绘制对应文本的原始干净图像;
所述原始干净图像是干净、无干扰、只有黑色文字的图像。
所述opencv的puttext方法支持将某个字体库里文本对应的字绘制在某张图片上。opencv是一个基于bsd许可(开源)发行的跨平台计算机视觉库,可以运行在linux、windows、android和macos操作系统上。它轻量级而且高效——由一系列c函数和少量c++类构成,同时提供了python、ruby、matlab等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
opencv用c++语言编写,它的主要接口也是c++语言,但是依然保留了大量的c语言接口。该库也有大量的python、javaandmatlab/octave(版本2.5)的接口。这些语言的api接口函数可以通过在线文档获得。如今也提供对于c#、ch、ruby,go的支持。opencv致力于真实世界的实时应用,通过优化的c代码的编写对其执行速度带来了可观的提升,并且可以通过购买intel的ipp高性能多媒体函数库(integratedperformanceprimitives)得到更快的处理速度。右图为opencv与当前其他主流视觉函数库的性能比较。opencv中除了提供绘制各种图形的函数外,还提供了一个特殊的绘制函数——在图像上绘制文字。这个函数即是cv::puttext()。
s42:对原始干净图像进行增强处理,获得增强后的困难级别的初始训练数据。
增强处理包括以下几种方法:
s421:空间几何变换类:对文本图片进行水平和垂直的翻转、随机裁剪、旋转、平移变换、仿射变换、透视变换。
s422:模糊类处理:如高斯模糊处理。
s423:像素颜色变换类处理:色彩抖动(rgb值做随机的增减)处理、对比度增强处理、高斯和椒盐噪声处理。
s424:边界变换类处理:样本锐化处理、样本浮雕处理。
通过以上处理后,将增强后的困难级别的初始训练数据,加入到训练数据的队列中正常进行训练,从而提高生僻字、易错字的准确率,提高复杂环境下的准确率。
进一步的,本发明中总样本数据采用的初始训练数据,除了可以使用长条的文本图片和标注出的对应文字,也可以针对单个字的图片和其对应文字。
并且,所述简单级别的初始训练数据,除了可以直接加入到训练数据的队列中正常进行训练,也可以进行如步骤s42的增强处理后,再加入到训练数据的队列中正常进行训练。
所述ocr识别模型训练中的动态数据增强方法可以解决实际测试样本中的生僻字及印章、竖线干扰的问题,可以提高模型对于检测效果的鲁棒性,减少样本在本地的存储空间,提高训练样本的丰富性及模型的学习能力和鲁棒性,使文本的识别率更高。
- 还没有人留言评论。精彩留言会获得点赞!