基于图基元的图嵌入学习方法与流程
本发明涉及图形处理技术领域,具体涉及一种基于图基元的图嵌入学习方法。
背景技术:
在日常生活中,图结构数据应用广泛。在生物化学领域,分子可以被视为图,各个原子被视为是节点,通过化学键相连;在学术引用网络中,发表的论文或学者通过彼此的引用相互连接;在电子商务领域,推荐系统可以根据基于用户和产品构成的图来进行高效精准地推荐。图结构具有不规则性:节点可能具有不同的邻居数量,节点本身可能带有复杂的特征,边也有多种形态,例如有向边、无向边、有权边、无权边等等。相比于其他结构,图结构能方便地表达数据的特征。
图嵌入(graphembedding)是一种将图结构的节点映射到低维空间向量的图学习方法,该方法能够有效处理例如节点分类、异常检测等下游任务。在自然语言处理(nlp,naturallanguageprocess)模型的启发下,图嵌入学习算法中许多算法以节点作为单词,采用随机游走(randomwalk)以生成路径作为“上下文”采集语料,然后将采集的语料输入到skip-gram模型中,从而学习得到图嵌入向量。该方法将图中的节点映射到低维度空间中,原图中相似的节点在低维度空间中也会接近。关键的问题是如何衡量节点之间的相似度,从而能够更好地处理下游任务。前人的算法主要通过节点之间的连通性与结构相似性这两点来衡量节点之间的相似性,大致可以分为以下几类:(1)基于连通性的算法:这些算法将紧密相连的节点或者具有多个公共邻居的节点视为高相似性,例如deepwalk、node2vec、line等,在原图中接近的点在经过这些算法学习后得到的嵌入向量也会较为相似;(2)基于结构相似性的算法:结构相似性衡量两个节点是否拥有相似的局部结构(自我中心网络ego-network),例如struc2vec等,在原图中结构性相似的点在经过这些算法学习后得到的嵌入向量会较为相似;(3)基于多种相似性或概率分布的算法:目前也有一些并不仅仅单一考虑了连通性或结构相似性,例如verse、graphwave,verse采用了三种定义的相似度,即社区结构(communitystructure)、节点角色(roles)和结构对等(structuralequivalence),graphwave则是采用概率分布的方式来度量节点之间的相似度。
然而,真实世界的数据是非常复杂的,具有冗杂噪音。上述已知模型具有以下不足:1)采用单一相似性度量标准无法很好地捕捉图中的信息特征,会导致一定的信息损失,例如基于结构相似度的算法不适用于强同质性的图数据,例如具有相同兴趣的用户连接的可能性比随机连接的可能性更大,而仅考虑连通性的算法会在重视结构性的任务中失败。2)过去这些模型都只适用于静态图,无法处理动态场景下的归纳学习(inductivelearning)任务。3)过去的模型无法在学习图嵌入向量的同时进一步生成对某个群体的表示向量,例如在社交网络中,闭合三角形的图基元motif表示节点用户经常彼此相互介绍朋友认识,而现有模型无法明确和定量地学习表示社交场景中的这种行为或是倾向于介绍朋友认识的这个团体。
本发明是基于图基元的图嵌入学习方法,图基元(motif)是构成图的基本模块,描述了不同节点之间特定连接的子图结构。图基元(motif)作为图中频繁出现的子图结构,蕴含着丰富的信息。图基元(motif)在生物信息学、神经科学、生物学和社交网络等领域中都有着广泛的应用,例如在社交网络中闭合三角结构的图基元(motif)表示该网络中的人倾向于互相介绍朋友认识,而开三角结构的图基元(motif)表示相反的意思。
技术实现要素:
本发明的目的是提供一种有机地统一连通性和结构相似性、更好地学习图的特征、适用于各种图形处理的基于图基元的图嵌入学习方法。
为了达到上述目的,本发明通过以下技术方案来实现:
基于图基元的图嵌入学习方法,包括如下步骤:
s1)选取多阶无向图基元
对于图中每个节点,统计其周围每种图基元出现的次数,生成图基元统计向量
s2)构造节点与图基元超节点的带权结构性边
将所有图基元放入图中作为图基元超节点,同时构造节点与图基元超节点的带权结构性边,其中第i种图基元超节点mi和节点u之间的结构性边的权重
s3)采用随机游走策略获取上下文语料
采用参数q来确定在结构性边或普通边上随机游走,采用πu表示节点u下一步游走的转移概率分布,公式为
s4)将图数据映射到低维稠密向量
采用skip-gram模型将节点和图基元超节点映射到低维嵌入空间,可得到不同图基元的嵌入向量。
进一步地,步骤s4)中,将skip-gram模型描述为优化问题,其目标函数为
进一步地,对于不同的网络,可调整系数q。
进一步地,在动态场景中,对于新到达图中的节点
进一步地,对于图中每个节点,计算图基元统计向量的时间复杂度为o(|e|·|v|),其中e、v分别表示图中节点和边的集合;对于嵌入向量学习部分,采用基于霍夫曼编码的分层归一化函数,其时间复杂度为o(|v|·log(|v|)+l*n)o,其中n表示随机游走的数量,l表示随机游走的长度。
本发明与现有技术相比,具有以下优点:
本发明基于图基元的图嵌入学习方法,有机地统一连通性和结构相似性;不仅可学习得到节点的嵌入向量,同时也能得到图基元(motif)的嵌入向量;充分利用了图基元(motif)的性质,可在有向图、无向图、静态图、动态图等多种图形处理情况下使用。
附图说明
图1是本发明基于图基元的图嵌入学习方法的算例框架示意图。
图2是本发明基于图基元的图嵌入学习方法的2-4阶无向图基元(motif)示例图。
具体实施方式
下面结合附图,对本发明的实施例作进一步详细的描述。
本发明基于图基元的图嵌入学习方法,用来学习图节点和各种图基元的嵌入向量,嵌入向量学习更新的方法是期望最大化窗口大小内节点同时出现的概率。本发明将各种不同结构的图基元(motif)作为超节点插入网络,并构建一个由motif超节点与图中原始节点组成的异构网络;为了从异构网络生成语料库,提出一种基于motif的随机游走策略,确保具有高连通性或高结构相似性的节点在语料库中相对靠近。
如图1所示,本发明的发明点体现在:
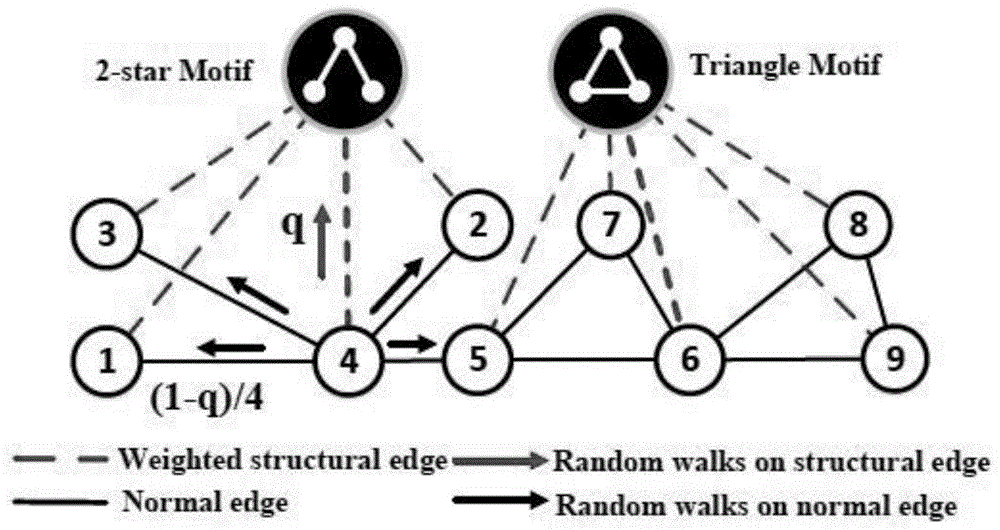
(1)将不同的图基元(motif)作为超节点放入图中,如图1中所示的2-starmotif和trianglemotif,并在超节点与节点之间构建结构性边,从而生成异构图(heterogeneousgraph)。对于某节点u与motif超节点,结构边的权重与该节点周围出现了该种类型的motif的数量成正比。图1中节点6周围出现了两个三角形motif((5,6,7),(6,8,9)),而节点7周围仅有1个三角形motif(5,6,7),因此节点6与trianglemotif超节点之间的结构性边的权重大于trianglemotif超节点和节点7之间的结构性边。
(2)在异构图上使用基于motif的随机游走策略采集语料,然后输入skip-gram模型得到图节点和motif超节点的嵌入向量。本发明采用q这一参数控制随机游走在结构性边和普通边的概率,从而有机地统一了连通性与结构相似度,使得算法能更好地学习图数据中的特征。
(3)通过学习得到的motif嵌入向量在动态场景下处理归纳学习问题。
具体地,基于图基元的图嵌入学习方法,包括如下步骤:
s1)选取多阶无向图基元
如图2所示,选取2-4阶的无向图基元(motif),对于图中每个节点,统计其周围每种图基元(motif)出现的次数,生成图基元统计向量(motifcountvector)
s2)构造节点与图基元超节点的带权结构性边
将所有图基元(motif)放入图中作为图基元超节点,同时构造节点与图基元(motif)超节点的带权结构性边,其中第i种图基元超节点mi和节点u之间的结构性边的权重
s3)采用随机游走策略获取上下文语料
采用参数q来确定在结构性边或普通边上随机游走,采用πu表示节点u下一步游走的转移概率分布,公式为
以图1中的节点4为例,如果游走到节点4,下一步有q的概率会走到2-starmotif超节点,走到邻居节点1、2、3、5的概率则为
s4)将图数据映射到低维稠密向量
采集上下文语料库后,采用skip-gram模型将节点和图基元超节点映射到低维嵌入空间,可得到不同图基元的嵌入向量。对于不同的网络,可根据特定的先验知识来调整系数q,系数q越大,随机游走在结构性边上的可能性就越大,结构相似的节点更容易出现在所采集的语料库中临近的位置,学得的嵌入向量会更加关注结构相似性。
进一步地,为简单起见,将skip-gram模型描述为优化问题,其目标函数为
本发明将motif超级节点放入了网络中,通过skip-gram模型,可以得到不同motif的嵌入向量,使得本发明能够很好地处理动态场景。在动态场景中,对于新到达图中的节点
本发明对于图中每个节点,计算图基元统计向量的时间复杂度为o(|e|·|v|),其中e、v分别表示图中节点和边的集合;对于嵌入向量学习部分,模型采用基于霍夫曼编码的分层归一化函数,其时间复杂度为o(|v|·log(|v|)+l*n)o,其中n表示随机游走的数量,l表示随机游走的长度。
下面通过实验数据验证说明本发明基于图基元的图嵌入学习方法的优等性能。实验验证使用的数据集包括两个真实数据集mobile、loan和四个公开数据集wiki、cora、citeseer和ppi,具体如下:
·mobile:该数据集由中国电信提供,用户被视为节点,而边则表示一个用户呼叫了另一个用户,该网络包含5000个节点(4105个负样和895个正样本),228110条边,数据集包含一周的通话记录。
·loan:该数据集由拍拍贷公司提供,节点表示拍拍贷公司的注册用户,边表示用户的通话记录,该数据集记录的时间范围是从2018年1月到2019年1月,该数据集中未及时偿还款的用户被视为正样本,而及时偿还的则被视为负样本,其中包含1104个节点(123个正样本和981个负样本)和1719条边。
·wiki:该数据集包含2,405个节点,17981条边,共17种分类,节点表示单词,边表示单词之间的共现关系。
·cora:该数据集包含2708个节点,5278条边,共7种分类,每个节点表示一篇学术论文,边表示论文之间的引用。
·citeseer:该数据集包含3264个节点,4536个边,共6种分类,每个节点表示一篇学术论文,边表示论文之间的引用。
·ppi:该数据集表示智人的蛋白质-蛋白质相互作用的图,包含了3890个节点和37845条边。
常用的基准算法包括以下几类:
·struc2vec:该算法通过节点的对称性学习嵌入向量。
·graphwave:该算法基于热量的小波扩散模型,用无监督的方式学习嵌入向量表示节点。
·netmf:该算法将基于word2vec的嵌入模型统一到矩阵分解框架中,包括deepwalk、node2vec、line和pte。
·verse:该算法考虑了多种相似性,社区结构、节点角色和结构对等,并使用单层神经网络学习嵌入向量。
·motifwalk:该算法利用图基元,通过有偏的随机游走策略在图中生成上下文,从而学习嵌入向量。
将本发明基于图基元的图嵌入学习方法与上述常用的基准算法分别在如下异常检测、节点分类、边预测的多个任务中进行验证,结果如下表所示。
表1不同算法在异常检测任务中的性能比较
表2不同算法在节点分类任务中的性能比较
表3不同算法在边预测任务中的性能比较
对于二分类问题,采用accuracy、precision、recall、f1等指标进行衡量,对于多分类问题,采用macro-f1和micro-f1指标进行衡量,定义含义如下:
其中tp表示truepositive,即真实标签是正例而模型也判定为正例(positive);fp表示falsepositive,即真实标签是负例而模型判定为正例(positive);fn表示falsenegative,即真实标签是正例而模型判定为负例(negative);tn表示truenegative,即真实标签是负例而模型也判定为负例(negative)。macro-f1先计算每个类别的f1,然后计算平均值,micro-f1先通过计算整体的tp、fn和fp,再计算f1。
从上述表格中可以得出,本发明在异常检测任务中,在mobile数据集上各指标都超过了基准算法,而在loan数据集上取得了最高的recall和f1。由于loan数据集的场景是检测欺诈,因此相比于precision,recall和f1的意义会更大,因此模型在异常检测任务中表现出色。而在节点分类与边预测任务中,本算法也取得了优于其他基准算法的结果。例如在节点分类任务中,对于macro-f1指标而言,本发明比其他基准算法中表现最好的算法分别在wikipedia,cora和citeseer数据集上的表现高了21.8%,12.4%,15.7%,对于micro-f1指标而言,本发明比其他基准算法中表现最好的算法分别在wikipedia,cora和citeseer数据集上的表现高了8.8%,13.5%,14.3%。在边预测任务中,对于mobile数据集本发明取得了最高的accuracy、precision、recall以及f1score;对于ppi数据集,本发明在accuracy、recall和f1score上也取得了最好的成绩。
表4不同算法在归纳学习任务中的性能比较
对于动态场景下的归纳学习任务,本算法的效果优于增量svd算法(incrementalsvd常见的归纳学习算法),本算法在f1指标上方面提升了85.5%。以上所述仅是本发明优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明构思的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!