一种骨髓细胞形态学自动检测系统的计数及分析方法与流程
本发明创造属于骨髓细胞形态学检测领域,具体涉及了一种骨髓细胞形态学自动检测系统的计数及分析方法。
背景技术:
骨髓细胞形态学镜检是血液学中关键诊断手段之一,常用于诊断多种病症,包括白血病、多发性骨髓瘤、淋巴瘤、贫血和全血细胞减少。根据世界卫生组织发布的《骨髓恶性肿瘤诊断指南》,在诊断时需要进行详细、精确的显微镜人工检查。正常骨髓含有发育阶段的所有分化细胞,从早期前体干细胞到功能成熟细胞,包括作为大多数血细胞前体的造血干细胞以及被认为是骨髓的守门员细胞的间充质干细胞和内皮干细胞。这些细胞的形态学特征取决于本身的生物学特性,同时受到涂片、染色和图像采集过程的影响。目前人工镜检仍然是重要的诊断和治疗疗效监测的方法。
其主要缺陷在于镜检规则执行不严。当前,我国进行的传统骨髓细胞形态学诊断主要依靠骨髓涂片人工镜检。在人工镜检的环节中,分类细胞数量的确定、分类部位的划分以及细胞难易的取舍都存在个人主观因素的影响。这些因素都会导致分类计数的准确性受到干扰,从而降低镜检结果的可靠性和稳定性。
申请号为cn201811168824.4的专利公开了一种基于深度学习的骨髓细胞分类方法及分类装置,其中该方法包括:对骨髓细胞样本图像中的骨髓细胞标注细胞位置以及其分类标签;从骨髓细胞样本图像中提取预设尺寸的具有单一分类标签的图像块样本;构建骨髓细胞分类任务的卷积神经网络,然后利用由图像块样本组成的训练集进行训练,得到骨髓细胞分类模型;将骨髓细胞待测图像切割成预设尺寸的多个测试图像块,将多个测试图像块遍历地输入骨髓细胞分类模型,检测出多个测试图像块中的骨髓细胞边缘,并输出骨髓细胞对应的分类标签以及分类置信概率。
其不足之处在于,现有的关于骨髓细胞形态学的检测系统无法对数据是否具有参考性进行判断。
技术实现要素:
为了解决现有的关于骨髓细胞形态学的检测系统无法对数据是否具有参考性进行判断的问题,本发明创造提出了可以对数据是否具有参考性进行判断且可以尽可能的确保最终数据贴近真实值的骨髓细胞形态学自动检测系统的计数及分析方法。
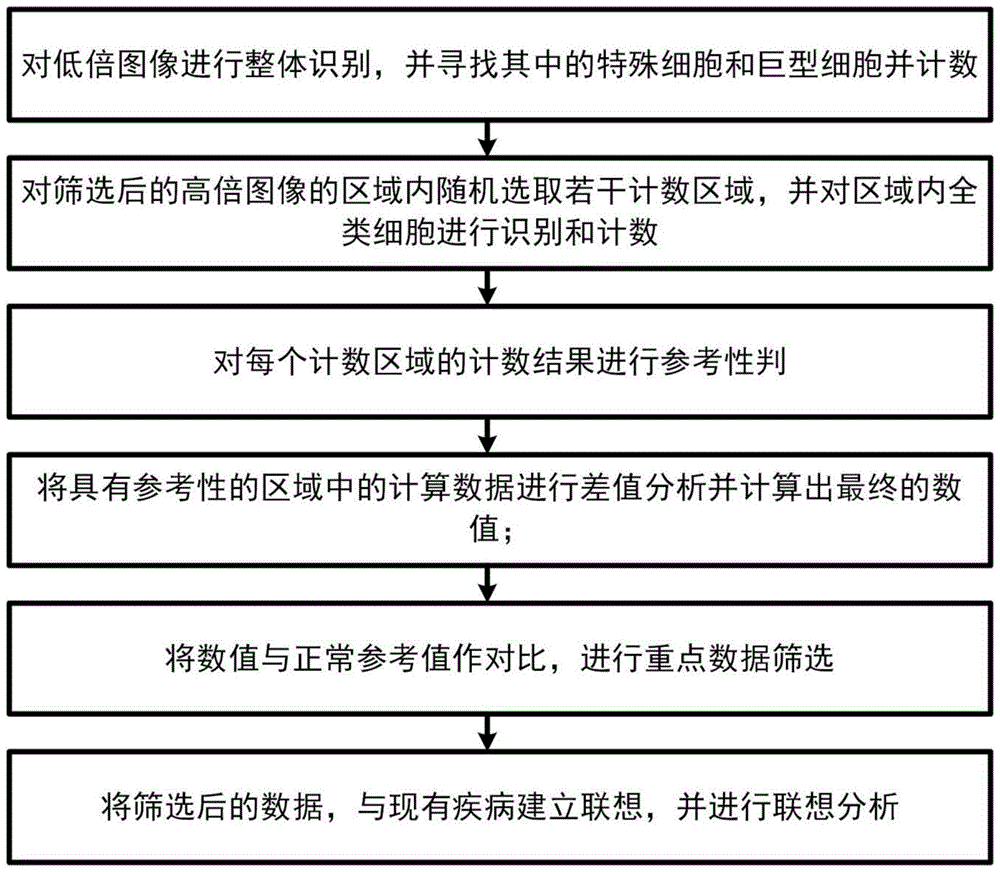
为了实现上述目的,本发明创造所采用的技术方案是,一种骨髓细胞形态学自动检测系统的计数及分析方法,包括以下步骤:s1:对低倍图像进行整体识别,并寻找其中的特殊细胞和巨型细胞并计数;s2:对筛选后的高倍图像的区域内随机选取若干计数区域,并对区域内全类细胞进行识别和计数;s3:对每个计数区域的计数结果进行参考性判断;s4:将具有参考性的区域中的计算数据进行差值分析并计算出最终的数据;s5:将数据与正常参考值作对比,进行重点数据筛选;s6:将筛选后的数据,与现有疾病建立联想,并进行联想分析。
作为优选,所述的s2中的计数区域包括正计数区域和拓展计数区域,所述的拓展计数区域位于正计数区域外围,为正计数区域的延伸;所述的正计数区域的面积为a个细胞平均面积大小;所述的拓展计数区域的边界与正计数区域的边界距离为b个细胞平均直径距离;在对正计数区域内的细胞计数时,如果发现落入正计数区域内的细胞不完整,则将其延伸到拓展计数区域,然后测量该细胞在正计数区域的面积与在拓展计数区域的面积,将位于两个区域的面积作对比,如果在拓展计数区域内的面积大,则不计数,反之则计数。
作为优选,所述的细胞平均面积指所需要检测位置的红细胞系统、粒细胞系统、淋巴细胞系统和单核细胞系统的细胞的平均面积。
作为优选,所述的s3中参考性判断的方法是,统计每个计数区域内的总计数细胞量,如果计数个数在t的范围之内,数据保留,反之则删除不符合的计数,并重新选取计数位置,即当a和t之间的关系符合
作为优选,所述的s4包括以下步骤;a1:设定一个目标统计总数c,将c除以计数区域的个数,得出每个计数区域应统计的细胞数量为d;a2:将每个计数区域的实际计数量e分别与应统计量d作比,获得
作为优选,所述的s6包括以下步骤:b1:分别对骨髓象和血液象的数据与数据库中的现有疾病进行联想;b2:建立筛选出的数据与联想疾病之间的相似度和相异度评判体系;b3:将每种联想疾病的相似度与相异度作对比,当相似度大于相异度时,将该疾病归纳为疑似疾病;b4:将骨髓象中的疑似疾病与血液象中的疑似疾病名词相匹配;b5:将完成匹配的疑似疾病的相似度相乘以及相异度相乘,最终得出整体的检测结果对该疾病的相似度和相异度;b6:将相似度按照从高到低排序,完成对数据的分析和与疾病的联想。
作为优选,所述的相似度的计算方法为将筛选出的数据与现有疾病对应的数据相比较,将落入现有疾病数据范围的数据个数与现有疾病的数据个数对比获得相似度。
作为优选,所述的相异度的计算方法为将筛选出的数据与现有疾病对应的数据相比较,将不落入现有疾病数据范围的数据个数与现有疾病的数据个数对比获得相异度。
作为优选,所述的落入现有疾病数据范围是指其种类与现有疾病的数据种类相同且数值落入现有疾病的数值范围内。
作为优选,所述的a的取值范围为200-400;所述的b的取值范围为2-8,具有参考性的计数区域的个数至少为5个;所述的c的取值范围为正计数区域的面积与计数区域个数乘积的一半。
本发明创造的有益效果:本申请采用多点取样,然后在对每个取样点的数据进行代表性分析,使得每个取样点的数据都具有参考性。然后在将所有具有参考性取样点的数据进行加权计算,使得统计的数据更加贴近真实值,使得最终数据的指向更加精准。
附图说明
图1:整体流程示意图
图2:数据差值计算流程示意图
图3:现有疾病联想流程示意图
具体实施方式
一种骨髓细胞形态学自动检测系统的计数及分析方法,包括以下步骤:s1:对低倍图像进行整体识别,并寻找其中的特殊细胞和巨型细胞并计数。s2:对筛选后的高倍图像的区域内随机选取若干计数区域,并对区域内全类细胞进行识别和计数。s3:对每个计数区域的计数结果进行参考性判断。s4:将具有参考性的区域中的计算数据进行差值分析并计算出最终的数据。s5:将数据与正常参考值作对比,进行重点数据筛选。s6:将筛选后的数据,与现有疾病建立联想,并进行联想分析。
s2中的计数区域包括正计数区域和拓展计数区域,拓展计数区域位于正计数区域外围,为正计数区域的延伸。正计数区域的面积为a个细胞平均面积大小。拓展计数区域的边界与正计数区域的边界距离为b个细胞平均直径距离。在对正计数区域内的细胞计数时,如果发现落入正计数区域内的细胞不完整,则将其延伸到拓展计数区域,然后测量该细胞在正计数区域的面积与在拓展计数区域的面积,将位于两个区域的面积作对比,如果在拓展计数区域内的面积大,则不计数,反之则计数。
细胞平均面积指所需要检测位置的红细胞系统、粒细胞系统、淋巴细胞系统和单核细胞系统的细胞的平均面积。
s3包括以下步骤:c1:对每个计数区域内的细胞进行识别和计数。c2:对每个计数区域进行参考性判断,如果具有参考性,跳转s4;如果不具有参考性,跳转c3。c3:舍弃不具有参考性的区域,并重新选取计数区域。c4:对新选区的计数区域内的细胞进行识别和计数,跳转c2。
s3中参考性判断的方法是,统计每个计数区域内的总计数细胞量,如果计数个数在t的范围之内,数据保留,反之则删除不符合的计数,并重新选取计数位置,即当a和t之间的关系符合
s4包括以下步骤;a1:设定一个目标统计总数c,将c除以计数区域的个数,得出每个计数区域应统计的细胞数量为d。a2:将每个计数区域的实际计数量e分别与应统计量d作比,获得
a的取值范围为200-400。b的取值范围为2-8,具有参考性的计数区域的个数至少为5个。c的取值范围为正计数区域的面积与计数区域个数乘积的一半。
s6包括以下步骤:b1:分别对骨髓象和血液象的数据与数据库中的现有疾病进行联想。b2:建立筛选出的数据与联想疾病之间的相似度和相异度评判体系。b3:将每种联想疾病的相似度与相异度作对比,当相似度大于相异度时,将该疾病归纳为疑似疾病。b4:将骨髓象中的疑似疾病与血液象中的疑似疾病名词相匹配。b5:将完成匹配的疑似疾病的相似度相乘以及相异度相乘,最终得出整体的检测结果对该疾病的相似度和相异度。b6:将相似度按照从高到低排序,完成对数据的分析和与疾病的联想。
相似度的计算方法为将筛选出的数据与现有疾病对应的数据相比较,将落入现有疾病数据范围的数据个数与现有疾病的数据个数对比获得相似度。
相异度的计算方法为将筛选出的数据与现有疾病对应的数据相比较,将不落入现有疾病数据范围的数据个数与现有疾病的数据个数对比获得相异度。
落入现有疾病数据范围是指其种类与现有疾病的数据种类相同且数值落入现有疾病的数值范围内。
本申请采用多点取样,然后在对每个取样点的数据进行代表性分析,使得每个取样点的数据都具有参考性。然后在将所有具有参考性取样点的数据进行加权计算,使得统计的数据更加贴近真实值,使得最终数据的指向更加精准。
本申请将最总的数据与正常参考值进行对比,将其中非正常的数据提取出来,完通过大数据获取现有疾病在骨髓细胞方面的数据,将筛选出来的数据与现有疾病的数据进行对比联想,实现了对数据的利用和整理。降低了医生对病情诊断的难度,提高了诊断速度,降低了失误率。
相似度与相异度体系的建立使得数据与疾病之间关系实现了量化,使得联想的结果更加准确。由于有些疾病在骨髓象难以具体区分,具有迷惑性,而在血液象可以明显的区分。而有些疾病在血液象难以具体区分,但是在骨髓象有较大的差异。所以本申请根据该特性,最终将骨髓象和血液象联动,对联想结果进行了筛选,减少了对医生诊断时的干扰。
以上详细描述了本发明创造的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明创造的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明创造的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!