一种大数据处理方法及系统与流程
本发明涉及大数据处理技术领域,特别涉及一种大数据处理方法及系统。
背景技术:
随着物联网、社交媒体等新兴技术的快速发展,大数据时代已经逐渐到来,数据产生和传播的速度不断加快,数据的价值也会快速下降。如何获取庞大数据组并从中获取有价值的数据是大数据处理解决的问题。目前,在大数据处理技术中已经实现了大数据流数据的采集与处理,大数据处理应用于各行各业。但是,大数据处理过程中往往会出现数据冗余、缺失、冲突的问题,因此,提出一种采用边缘计算、人工智能和可视化孪生技术的大数据处理方法及系统,避免数据冗余、缺失、冲突的问题,实现数据驱动的信息-实体空间深度融合。
技术实现要素:
本发明提供一种大数据处理方法及系统,用以解决大数据处理过程中往往会出现数据冗余、缺失、冲突的问题。
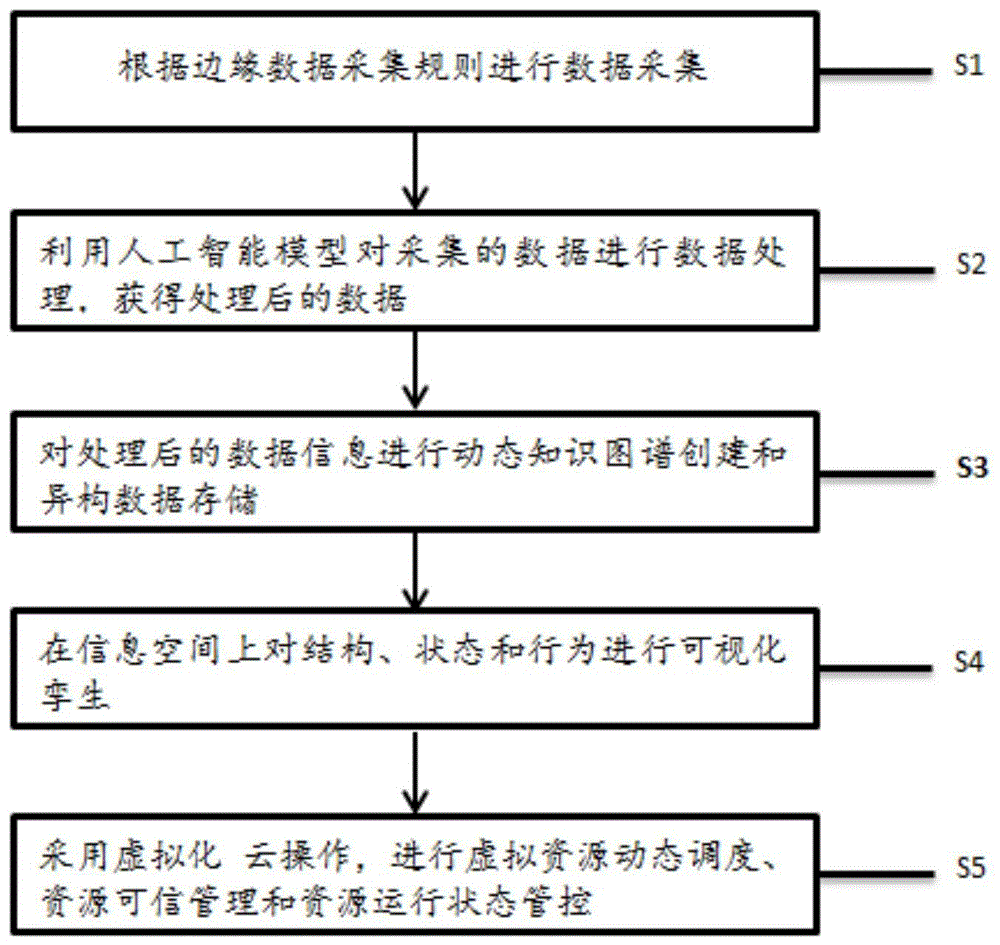
一种大数据处理方法,所述方法包括:
根据边缘数据采集规则进行数据采集;
利用人工智能模型对采集的数据进行数据处理,获得处理后的数据;
对处理后的数据进行动态知识图谱创建和异构数据存储;
在信息空间上对结构、状态和行为进行可视化孪生;
采用虚拟化云操作,进行虚拟资源动态调度、资源可信管理和资源运行状态管控。
优选地,所述数据采集采集的数据格式包括图像、视频、文本和音频。
优选地,所述根据边缘数据采集规则进行数据采集,包括:
基于光学系统的倾斜边缘计算方法进行数据采集;
对采集的数据进行数据清洗;
根据分布式异构数据源对清洗后的采集数据进行语义集成;
根据采集的数据及语义集成的结果进行数据传输消息队列管理,并对数据进程状态实时监控。
优选地,所述利用人工智能模型对采集的数据进行数据处理,包括:
对采集的数据利用人工智能模型获取数据的特征;
根据所述的数据特征获取所述采集的数据的分布规律;
根据所述数据的特征及规律生成多样化的可视化算法模型库。
优选地,所述对采集的数据利用人工智能模型获取数据的特征,包括:
步骤1、整理采集的数据;
将采集的数据记为矩阵s,矩阵s可表示为:
其中,aij为采集的关于属性i的第j类型数据,i和j的取值均为从1到n,n为所述采集的数据的属性数目,也是所述采集的数据的类型数目;
步骤2、根据下述公式,对采集的数据矩阵进行第一处理;
其中,s'为采集的数据矩阵s第一处理后的对应矩阵,aij为采集的关于属性i的第j类型数据,i和j的取值均为从1到n,n为所述采集的数据的属性数目,也是所述采集的数据的类型数目;
步骤3、根据下述公式计算协方差;
其中,r为s'的协方差矩阵,t为转置符号,n为所述采集的数据的矩阵的阶数;
步骤4、对协方差矩阵r进行特征分解,得到特征值;
r=diag[λ1,λ2,…,λk]
其中,λp为协方差矩阵的特征值,p的取值为从1到k,k为特征值的数目;
步骤5、根据λpr-e得到特征值分别对应的特征向量,并构成协方差矩阵r子空间的基w,w=[w1,w2,…,wd],d为子空间的维数也是特征向量的数目;
步骤6、得到数据特征;
d=wts'
其中,d为数据的特征矩阵,w为协方差矩阵r子空间的基,s'为采集的数据矩阵s第一处理后的对应矩阵。
优选地,所述对处理后的数据进行动态知识图谱创建和异构数据存储,包括:
确定数据集成的数据模型;
通过所述数据模型获取处理后的数据的数据图表;
根据分布式图处理框架将所述数据图表拆分为子图;
对所述子图进行迭代计算,确定数据集;
配置数据访问函数和接口,构成动态知识图谱;
针对动态知识图谱定义数据存储形式;
将处理后的数据转换成定义的数据存储形式进行存储。
一种大数据处理系统,所述系统包括:业务边缘计算单元、人工智能计算引擎单元、动态知识图谱单元、数字孪生可视化交互单元和云资源智能运维支撑单元;
所述业务边缘计算单元,用于根据边缘数据采集规则进行数据采集;
所述人工智能计算引擎单元,用于利用人工智能模型对采集的数据进行数据处理,获得处理后的数据;
所述动态知识图谱单元,用于对处理后的数据进行动态知识图谱创建和异构数据存储;
所述数字孪生可视化交互单元,用于在信息空间上对结构、状态和行为进行可视化孪生;
所述云资源智能运维支撑单元,采用虚拟化云操作,进行虚拟资源动态调度、资源可信管理和资源运行状态管控。
优选地,所述业务边缘计算单元,包括:边缘数据采集模块、边缘数据可信预处理模块和边缘处理进度监控模块;
所述边缘数据采集模块,用于根据边缘数据采集规则进行数据采集;
所述边缘数据可信预处理模块,用于对采集的数据进行数据清洗和根据分布式异构数据源对清洗后的采集数据进行语义集成;
所述边缘处理进度监控模块,用于根据采集的数据及语义集成的进行数据传输消息队列管理,并对数据进程状态实时监控。
优选地,所述人工智能计算引擎单元,包括:数据特征获取模块、数据规律获取模块和可视化算法模型库建立模块;
所述数据特征获取模块,用于对采集的数据利用人工智能模型获取数据的特征;
所述数据规律获取模块,用于根据所述数据特征获取所述采集的数据的变化规律;
所述可视化算法模型库建立模块,用于根据所述数据的特征及规律生成可视化算法模型库。
优选地,所述动态知识图谱单元,包括:数据模型选取模块、数据图表建立模块、图表拆分模块、数据计算模块、知识图谱创建模块、数据存储形式定义模块和数据存储模块;
所述数据模型选取模块,用于确定数据集成的数据模型;
所述数据图表建立模块,用于通过所述数据模型获取处理后的数据的数据图表;
所述图表拆分模块,用于根据分布式图处理框架将所述数据图表拆分为子图;
所述数据计算模块,用于对所述子图进行迭代计算,确定数据集;
所述知识图谱创建模块,用于配置数据访问函数和接口,构成动态知识图谱;
所述数据存储形式定义模块,用于针对动态知识图谱定义数据存储形式;
所述数据存储模块,用于将处理后的数据转换成定义的数据存储形式进行存储。
本发明的有益效果在于:
(1)采用边缘计算、人工智能和数字孪生技术的大数据处理方法及系统,避免数据冗余、缺失、冲突的问题;
(2)运用人工智能模型对数据处理,实现用户需求与数据价值无缝融合;
(3)可对pb级以上规模的海量数据存储、知识抽取、共享,实现面向特定行业价值链的分布式数据空间构建与开放服务;
(4)帮助企业不同用户在信息空间对企业实体、生产计划、业务活动行为的建模、可视化分析、智能决策与推演;
(5)可以实现虚拟资源动态调度、资源可信管理和资源运行状态管控。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明所述的一种大数据处理方法的示意图。
图2为本发明所述的一种大数据处理系统的示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
本发明实施例提供了一种大数据处理方法,如图1所示,所述大数据处理方法包括:
s1、根据边缘数据采集规则进行数据采集;
s2、利用人工智能模型对采集的数据进行数据处理,获得处理后的数据;
s3、对处理后的数据进行动态知识图谱创建和异构数据存储;
s4、在信息空间上对结构、状态和行为进行可视化孪生;
s5、采用虚拟化云操作,进行虚拟资源动态调度、资源可信管理和资源运行状态管控。
上述技术方案的原理及有益效果:首先采用边缘数据采集规则进行数据采集,然后利用人工智能模型对采集的数据进行数据处理,接着对处理后的数据进行创建动态知识图谱和异构数据存储,再次在信息空间上对结构、状态和行为进行可视化孪生,最后采用虚拟化云操作进行云资源智能运维。在上述技术方案中,采用边缘计算、人工智能和可视化孪生技术来有效避免数据冗余、缺失、冲突的问题,同时还采用虚拟化云操作来进行云资源智能运维,进而实现数据驱动的信息-实体空间深度融合。
本发明的一个实施例,所述数据采集采集的数据格式包括图像、视频、文本和音频。
上述技术方案的原理及有益效果:不论待采集数据的格式是图像、视频、文本、音频还是其他的格式形式都可以根据边缘数据采集规则进行数据采集,获得采集到的数据。通过上述技术方案,所述大数据处理方法可以针对不同格式的数据进行处理。
本发明的一个实施例,所述根据边缘数据采集规则进行数据采集,包括:
s11、基于光学系统的倾斜边缘计算方法进行数据采集;
s12、对采集的数据进行数据清洗;
s13、根据分布式异构数据源对清洗后的采集数据进行语义集成;
s14、根据采集的数据及语义集成的结果进行数据传输消息队列管理,并对数据进程状态实时监控。
上述技术方案的原理及有益效果:在采集数据时,首先根据光学系统的倾斜边缘计算方法进行数据采集,然后对采集的数据进行数据清洗,接着对清洗后的采集数据进行语义集成,同时根据采集的数据及语义集成的结果进行数据传输消息队列管理,并对数据进程状态实时监控。通过上述技术方案,对采集的数据进行数据清洗与语义集成可去除噪声数据、孤立数据,降低数据维度,获得优质的采集数据,数据进程状态监控可以通过监控获得实时数据状态进程。
本发明的一个实施例,所述人工智能模型包括统计分析模型、数据降维模型、分类/逻辑回归模型、决策与推理模型、轨迹挖掘模型、聚类与相似性模型和主题推荐模型。
上述技术方案的原理及有益效果:在利用人工智能模型对采集的数据进行数据处理时,根据相要获取的数据处理结果或者数据分析结果选择合适的模型。通过上述技术方案,借助不同的人工智能模型对数据进行处理可以从纷繁复杂的大数据中获得有效数据,同时对纷繁复杂的大数据进行分析得到数据分析结果,整个过程通过人工智能完成,高效精确,无需人为进行复杂运算。
本发明的一个实施例,所述利用人工智能模型对采集的数据进行数据处理,包括:
s21、对采集的数据利用人工智能模型获取数据的特征;
s22、根据所述的数据特征获取所述采集的数据的分布规律;
s23、根据所述数据的特征及规律生成多样化的可视化算法模型库。
上述技术方案的原理及有益效果:在进行数据处理时,首先对采集的数据利用人工智能模型获取数据的特征,然后根据所述数据特征获取所述采集的数据的分布规律,最后生成多样化的可视化算法模型库。通过上述技术方案生成多样化的可视化算法模型库,便于在获取数据目标知识时通过可视化算法模型库选择合适的人工智能模型获取数据特征和数据的分布规律。在上述技术方案中采用人工智能的方法利用人工智能模型进行处理,不仅可以从纷繁复杂的大数据中获得有效数据并得到数据分析结果,而且处理速度快,准确性高。
本发明的一个实施例,所述对采集的数据利用人工智能模型获取数据的特征,包括:
步骤1、整理采集的数据;
将采集的数据记为矩阵s,矩阵s可表示为:
其中,aij为采集的关于属性i的第j类型数据,i和j的取值均为从1到n,n为所述采集的数据的属性数目,也是所述采集的数据的类型数目;
步骤2、根据下述公式,对采集的数据矩阵进行第一处理;
其中,s'为采集的数据矩阵s第一处理后的对应矩阵,aij为采集的关于属性i的第j类型数据,i和j的取值均为从1到n,n为所述采集的数据的属性数目,也是所述采集的数据的类型数目;
步骤3、根据下述公式计算协方差;
其中,r为s'的协方差矩阵,t为转置符号,n为所述采集的数据的矩阵的阶数;
步骤4、对协方差矩阵r进行特征分解,得到特征值;
r=diag[λ1,λ2,…,λk]
其中,λp为协方差矩阵的特征值,p的取值为从1到k,k为特征值的数目;
步骤5、根据λpr-e得到特征值分别对应的特征向量,并构成协方差矩阵r子空间的基w,w=[w1,w2,…,wd],d为子空间的维数也是特征向量的数目;
步骤6、得到数据特征;
d=wts'
其中,d为数据的特征矩阵,w为协方差矩阵r子空间的基,s'为采集的数据矩阵s第一处理后的对应矩阵。
上述技术方案的原理及有益效果:利用人工智能模型对采集的数据进行数据处理时,首先整理采集的数据,然后对采集的数据进行第一处理,接着计算第一处理后的数据的协方差,再根据协方差获得协方差的特征值和特征向量,进而得到采集的数据矩阵子空间的基,最后根据子空间的基得到处理后的数据矩阵。通过上述技术方案可以对采集的数据进行处理,获得的处理后的数据矩阵不仅具有原数据的主要数据特征而且维数比原数据低,达到过滤与降维的效果。
本发明的一个实施例,所述对处理后的数据进行动态知识图谱创建和异构数据存储,包括:
s31、确定数据集成的数据模型;
s32、通过所述数据模型获取处理后的数据的数据图表;
s33、根据分布式图处理框架将所述数据图表拆分为子图;
s34、对所述子图进行迭代计算,确定数据集;
s35、配置数据访问函数和接口,构成动态知识图谱;
s36、针对动态知识图谱定义数据存储形式;
s37、将处理后的数据转换成定义的数据存储形式进行存储。
上述技术方案的原理及有益效果:上述技术方案可分为动态知识图谱创建与数据异构存储;在动态知识图谱创建时,首先确定数据集成的数据模型,然后通过所述数据模型获取所述集群的数据图表,接着将所述数据图表拆分为子图进行迭代计算,最后配置数据访问函数和接口,构成动态知识图谱。在进行数据异构存储时,首先对待存储的数据定义数据存储形式,然后对待存储的数据定义数据存储形式。在上述技术方案中,动态知识图谱创建根据分布式图处理框架将所述数据图表拆分为子图,然后分别对子图进行计算,计算的时候可以分别迭代进行分阶段的计算,而且可进行并行计算,同时,动态知识图谱创建还能够把表格和图进行互相转换;在对数据存储时按照定义的数据存储形式进行存储,形成的存储数据库不仅条理清晰,而且分类明确,同时还可以通过数据的存储形式及定义数据存储形式的规则了解到待存储数据的属性。
一种大数据处理系统,如图2所示,所述一种大数据处理系统包括:业务边缘计算单元、人工智能计算引擎单元、动态知识图谱单元、数字孪生可视化交互单元和云资源智能运维支撑单元
所述业务边缘计算单元,用于根据边缘数据采集规则进行数据采集;
所述人工智能计算引擎单元,用于利用人工智能模型对采集的数据进行数据处理,获得处理后的数据;
所述动态知识图谱单元,用于对处理后的数据进行动态知识图谱创建和异构数据存储;
所述数字孪生可视化交互单元,用于在信息空间上对结构、状态和行为进行可视化孪生;
所述云资源智能运维支撑单元,采用虚拟化云操作,进行虚拟资源动态调度、资源可信管理和资源运行状态管控。
上述技术方案的原理及有益效果:业务边缘计算单元,用于进行数据采集;人工智能计算引擎单元,提供数据处理;动态知识图谱单元,进行海量数据存储、知识抽取、共享;数字孪生可视化交互单元,用来将结构、状态、活动行为进行可视化孪生;云资源智能运维支撑单元,用来进行虚拟资源动态调度、资源可信管理和资源运行状态管控。通过上述技术方案,不仅可以避免出现数据多、少、错的问题,而且可以实现面向特定行业价值链的分布式数据空间构建与开放、实现结构、状态、活动行为在信息空间的可视化孪生以及实现用户需求与数据价值无缝融合,同时还可通过云资源进行虚拟资源动态调度、资源可信管理和资源运行状态管控。
本发明的一个实施例,所述业务边缘计算单元,包括:边缘数据采集模块、边缘数据可信预处理模块和边缘处理进度监控模块;
所述边缘数据采集模块,用于根据边缘数据采集规则进行数据采集;
所述边缘数据可信预处理模块,用于对采集的数据进行数据清洗和根据分布式异构数据源对清洗后的采集数据进行语义集成;
所述边缘处理进度监控模块,用于根据采集的数据及语义集成的进行数据传输消息队列管理,并对数据进程状态实时监控。
上述技术方案的原理及有益效果:在业务边缘计算单元中,边缘数据采集模块,进行数据采集;边缘数据可信预处理模块,对采集的数据进行数据清洁和语义集成;边缘处理进度监控模块,用来进行数据传输消息队列管理和对数据进程状态实时监控。通过上述技术方案所述边缘数据可信预处理模块可以通过对采集的数据进行预处理后获得去除噪声数据、孤立数据,降低维度后的优质采集数据,所述边缘处理进度监控模块既可以协调数据传输,又可以通过监控获得实时数据状态进程。
本发明的一个实施例,所述人工智能计算引擎单元,包括:数据特征获取模块、数据规律获取模块和可视化算法模型库建立模块;
所述数据特征获取模块,用于对采集的数据利用人工智能模型获取数据的特征;
所述数据规律获取模块,用于根据所述数据特征获取所述采集的数据的变化规律;
所述可视化算法模型库建立模块,用于根据所述数据的特征及规律生成可视化算法模型库。
上述技术方案的原理及有益效果:所述数据特征获取模块,对采集的数据利用人工智能模型获取数据的特征;所述数据规律获取模块,根据所述数据特征获取所述采集的数据的变化规律;所述可视化算法模型库建立模块,根据所述数据的特征及规律生成可视化算法模型库。通过上述技术方案不仅可以快速准确的利用人工智能模型从纷繁复杂的大数据中获得有效数据并得到数据分析结果,而且建立可视化算法模型库可在运用人工智能计算时调用匹配的人工智能模型。
本发明的一个实施例,所述动态知识图谱单元,包括:数据模型选取模块、数据图表建立模块、图表拆分模块、数据计算模块、知识图谱创建模块、数据存储形式定义模块和数据存储模块;
所述数据模型选取模块,用于确定数据集成的数据模型;
所述数据图表建立模块,用于通过所述数据模型获取处理后的数据的数据图表;
所述图表拆分模块,用于根据分布式图处理框架将所述数据图表拆分为子图;
所述数据计算模块,用于对所述子图进行迭代计算,确定数据集;
所述知识图谱创建模块,用于配置数据访问函数和接口,构成动态知识图谱;
所述数据存储形式定义模块,用于针对动态知识图谱定义数据存储形式;
所述数据存储模块,用于将处理后的数据转换成定义的数据存储形式进行存储。
上述技术方案的原理及有益效果:动态知识图谱单元中,所述数据模型选取模块确定数据集成的数据模型;所述数据图表建立模块通过所述数据模型获取处理后的数据的数据图表;所述图标拆分模块根据分布式图处理框架将所述数据图表拆分为子图;所述数据计算模块对所述子图进行迭代计算,确定数据集;所述知识图谱创建模块通过配置数据访问函数和接口,构成动态知识图谱;所述数据存储形式定义模块针对动态知识图谱定义数据存储形式;所述数据存储模块将处理后的数据转换成定义的数据存储形式进行存储。通过上述技术方案,不仅可以形成条理清晰,分类明确的存储数据库,而且通过将所述数据图表拆分为子图进行迭代与分阶段计算时可以并行计算,加快所述动态知识图谱创建的时间,同时还能够把表格和图进行互相转换。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!