一种基于GMM聚类的多尺度识别交通信号标志的方法与流程
本发明涉及一种交通信号标志识别方法,尤其是涉及一种基于gmm聚类的多尺度识别交通信号标志的方法。
背景技术:
交通信号灯和交通标志牌的实时识别是自动驾驶和辅助驾驶技术的重要组成部分,也是实现安全驾驶的重要环节。车辆需要在行驶过程中快速识别出前方路段的交通信号灯和交通标志牌并以此为依据做出正确的行车操作或提醒驾驶员保持安全驾驶。这样做提高了自动驾驶的安全性且减小了交通事故发生的可能性。
传统的方法主要根据交通信号标志的颜色和形状等特征来识别。rgb颜色分割是一种基于颜色特征的识别方法,但该方法的识别准确度较差。针对这一缺点,相继出现了his颜色分割、hsv多阈值分割等算法,虽然满足了一定的识别要求,但计算耗时太长,无法实现实时检测。基于形状特征的识别方法有hough变换、梯度方向信息、canny边缘检测等方法,但这些方法受限于形状匹配的模板,存在鲁棒性差等问题。
为了克服传统识别方法的缺点,目前性能最好且用的最多的就是基于深度学习的目标检测方法,它又可大体分为single-stage和two-stage两大类。但是基于two-stage的方法需要产生大量的候选区域,导致识别速度非常慢,无法实现实时检测。虽然现有的基于single-stage的方法拥有较快的识别速度,但其对小目标的识别效果大多都较差。小目标指的是在图像中占据较小像素的目标,一般其长宽不到图像尺寸的10%,只有几十个像素。而在交通信号标志图像中会以小目标居多。所以,现有的基于single-stage的目标检测方法对交通信号标志的识别效果欠佳。
除此以外,现有的基于single-stage的目标检测方法使用的先验框是通过k-means聚类得到的。但k-means的每个聚类在所有维度上的协方差都为零,使聚类结果局限于圆形。而由所有标定框的长宽大小构成的二维数据集是不规则形状的,如果使用圆形来聚类将会使聚类结果产生巨大误差,导致训练过程中预测框的回归过程耗时严重,影响到了训练速度和识别速度;并且,由于聚类结果的不准确也会直接造成神经网络识别准确度低下。
同时,现有的目标检测方法大多要求训练数据集样本充足且数量均匀,如果有几个类别的数据集样本太少,那么最终这几类的识别效果将会非常差,会出现误检和漏检的现象。
针对现有的基于single-stage的交通信号标志识别方法的这几大问题,寻找一种训练速度快、识别速度快和识别准确度高的新方法,以代替现有的识别方法,便成为了目前亟需解决的问题。
技术实现要素:
为解决上述问题,本发明提出一种基于gmm聚类的多尺度识别交通信号标志的方法,显著提高了识别准确度、训练和识别速度且对小目标对象也能实现高准确度识别。
本发明的技术方案采用如下步骤:
步骤一:数据准备;
通过对中国交通违章事件进行的统计,选择违章概率最高的25类交通标志作为数据集类别;一共收集到10000张包含有交通灯和交通标志牌的数据集,标定数据集并生成xml格式文件;随机选取2000张样本图片作为测试集,不参与神经网络的训练,只用来测试网络模型的性能;剩下的8000张样本图片被分为6000张训练样本和2000张验证样本后,需要参与神经网络模型的训练;计算并保存每个训练样本和验证样本中所有标定框的长宽大小。
步骤二:通过gmm聚类得到先验框尺寸作为网络的参数参与训练;
所述的步骤二中的gmm是以n个训练样本和验证样本中所有标定框的长宽大小作为二维数据点来构成;设有样本xi,则gmm的表达式:
其中:n是gmm中单一高斯模型的个数;πm是每个单一高斯模型的占比;p(xi|μm,varm)是样本xi在第m个单一高斯模型中的概率密度函数;μm、varm依次表示第m个高斯模型的均值、方差;
由公式(1)可知:gmm由单一高斯模型通过一定权重比叠加而成;因此,gmm可以用n个单一高斯模型无限逼近,就可认为所有标定框尺寸可被聚类为n个不同大小的先验框尺度;通过em算法对gmm的参数进行迭代更新:首先,分别初始化每个单一高斯模型的均值μ、方差var和每个单一高斯模型的占比π;通过以下公式(2)计算样本xi属于第m个单一高斯模型的概率,可称为样本xi对第m个单一高斯模型的贡献系数:
通过以下公式(3)计算似然函数初始值:
在得到wi,m之后,通过公式(4)、公式(5)和公式(6)依次更新πm、μm和varm:
以上便完成了一次gmm参数的更新,而通过更新后的πm、μm和varm可以进一步更新贡献系数和计算出此时的似然函数值,并往复迭代;随着参数的更新,似然函数值会不断变大,直到似然函数值的变化量小于预设阈值,此时gmm的参数达到收敛,聚类过程结束;
考虑到在多尺度识别网络中,最后需要输出五个尺度的预测结果,而每个尺度的预测结果需要三个不同大小的先验框;因此,需要通过gmm聚类出15个不同大小的先验框,即取n=15。
步骤三:先训练数据集中出现过多类的样本图像,若该样本图像中出现少类,也同时参与训练:将待训练图像输入神经网络中,网络提取输入图像不同层次的特征图,再通过上采样和特征融合,最后输出五个不同尺度的预测结果;通过迭代训练可以更新模型参数,得到过渡模型;其中多类为数据集中出现次数大于设定阈值的类,少类为数据集中出现次数小于设定阈值的类;
所述的神经网络的构建步骤如下:
设计由卷积层、bn归一化层、leakyrelu非线性激活函数串联构成的cbl基本单元;设计由步长为1的1×1cbl卷积和步长为1的3×3cbl卷积构成的res残差单元结构;设计由一个步长为2的3×3cbl卷积和n个res残差单元结构串联构成的resn结构;
神经网络分为特征提取网络和多尺度预测网络;特征提取网络会先调整输入图像的尺寸为512×512×3,再用1个输出通道为16的cbl卷积单元对输入图像进行滤波;再依次使用res1、res2、res8、res8、res4、res4残差结构对特征图进行下采样操作,同时增加特征图的通道数;通过特征提取网络可以依次得到128×128、64×64、32×32、16×16、8×8这些不同尺度的特征图,五个不同尺度的特征图将会被用于下一阶段的多尺度预测;
多尺度预测网络会将尺度为8×8的特征图依次通过步长为1的1×1、3×3、1×1、3×3、1×1五个cbl卷积来调整通道数,再通过一个步长为1的3×3cbl卷积和一个步长为1的1×1cbl卷积后可以得到8×8×90的预测结果;同时,尺度为8×8的特征图在依次通过步长为1的1×1、3×3、1×1、3×3、1×1、1×1六个cbl卷积和一次上采样后需要与尺度为16×16的特征图进行特征融合,得到新的特征图;新的特征图将会进行与尺度为8×8的特征图相同的变换,然后得到16×16×90的预测结果;同时,将会进一步与尺度为32×32的特征图进行特征融合;依次对特征提取网络得到的五个特征图进行上述变换,最后将得到128×128×90、64×64×90、32×32×90、16×16×90、8×8×90五个不同尺度的预测结果;
最终的预测结果会分别将输入图像分割成了128×128、64×64、32×32、16×16、8×8个网格,每个网格会产生三个预测框;预测框是由该网格对应的先验框通过回归过程得到的;每个预测框又由30个参数构成;参数分别为预测框中心的相对位置(x_offset,y_offset)、预测框的长宽(h,w)、预测置信度和25个类别的分类结果。
所述的步骤三中的训练步骤如下:
依据训练集和验证集的所有样本中出现次数是否大于500,将所有类别分为多类和少类,并分别保存出现过多类和少类的样本序号;先用步骤三中的神经网络训练多类序号的样本,同时也要训练这些样本中出现的少类目标;训练多类的步骤如下:
1)将多类序号的样本按照3:1的比例分离出训练集和验证集,两者都需参加训练;而验证集是通过训练网络的超参数来提高网络的识别准确度;
2)将训练集和验证集的xml格式的标定文件转换成训练所需的文件格式并保存;
3)设置训练超参数中的class为所有类别的class,输入预先搭建好的预训练模型,并解冻模型的所有层,设置为可训练;
4)设计损失函数等于位置预测损失函数、置信度预测损失函数和类别预测损失函数之和,其值大小为预测结果和标定的真实结果之间的差距大小;
5)设置初始学习率和学习率衰减策略,训练中选择用adam算法作为优化器来自动调整神经网络的权重参数,来使损失函数值不断减小;
6)将输入图像尺寸调整为512×512,并输入到神经网络中进行50轮的迭代训练;直到达到训练次数或损失函数的变化量小于阈值,则停止训练,得到并保存为过渡模型。
步骤四:按步骤三的训练方法训练少类,得到最终模型;
少类样本训练步骤如下:
1)将少类序号的样本按照3:1的比例分离出训练集和验证集;
2)将训练集和验证集的xml格式的标定文件转换成训练所需的文件格式并保存;
3)设置训练超参数中的class为所有类别的class,输入过渡模型作为预训练模型,并解冻模型的最后七层,设置为可训练;
4)设计损失函数等于位置预测损失函数、置信度预测损失函数和类别预测损失函数之和,其值大小为预测结果和标定的真实结果之间的差距大小;
5)设置初始学习率和学习率衰减策略;训练中选择用adam算法作为优化器来自动调整神经网络的权重参数,来使损失函数值不断减小;
6)将输入图像尺寸调整为512×512,并输入到神经网络中进行100轮的迭代训练;训练时,也要训练少类样本中出现的多类目标;直到达到训练次数或损失函数的变化量小于阈值,则停止训练,得到并保存为最终模型。
步骤五:识别时将待识别图像输入最终模型,可得到图像相应位置上的识别结果。
识别具体步骤为:将待识别的交通信号标志图像或视频输入到最终模型中,经过特征提取、上采样、特征融合,神经网络模型最终将会输出五个不同尺度的预测结果,从预测结果中可以得知每个预测框的位置、大小信息以及框内出现各类别的概率;将所有预测框聚集在一起,通过nms算法去除冗余的预测框,最终可在图像或视频的相应位置上框出识别出的交通信号标志类别;
上述的nms算法具体步骤如下:
1)设定预测结果中每个预测框的预测置信度与其预测出的每类分类结果的乘积最大值作为该预测框的得分,而该最大值对应的类别即是该预测框预测出的框内所属类别;
2)设定得分阈值,将得分低于得分阈值的所有预测框剔除,保留得分高于得分阈值的所有预测框;
3)设定交并比阈值,在剩下的预测框中选取得分最高的预测框为标准,剔除所有与该预测框交并比大于交并比阈值的预测框;
4)重复步骤3),直到完成对所有预测框的处理。
本发明具有的有益效果是:
本发明提出了基于特征金字塔的五尺度识别网络。其中,8×8尺度的特征图有最大感受野,能够很好地检测图像中的大目标,而128×128尺度的特征图有最小的感受野,对图像中的小目标具有很好的识别效果。所以,本发明方法解决了现有的基于single-stage的交通信号标志识别方法无法较好识别小目标的问题,达到了很好的小目标识别效果。
相比于现有识别方法存在先验框聚类误差大的问题,本发明方法通过gmm来进行先验框聚类,使聚类结果可以拥有任意椭圆的形状,更加符合实际情况。这样做提高了聚类的灵活性,明显降低了聚类误差,加快了训练和识别过程中预测框的回归过程,从而提高了神经网络的识别准确度、训练速度和识别速度。
相比于现有识别方法对数据样本少的类别无法达到较好识别效果的问题,本发明方法先迭代训练多类样本得到过渡模型,再用过渡模型作为预训练模型,且用更多的训练次数迭代训练少类样本并得到最终模型。最后实现了对数据样本少的类别也能达到较好的识别效果,提高了整体识别准确度。
附图说明
图1为本发明的流程图;
图2为本发明的高斯混合聚类流程图;
图3为本发明的神经网络整体结构图;
图4为实施例的测试样本图像;
图5为实施例本方法得到的识别结果图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步详细说明。
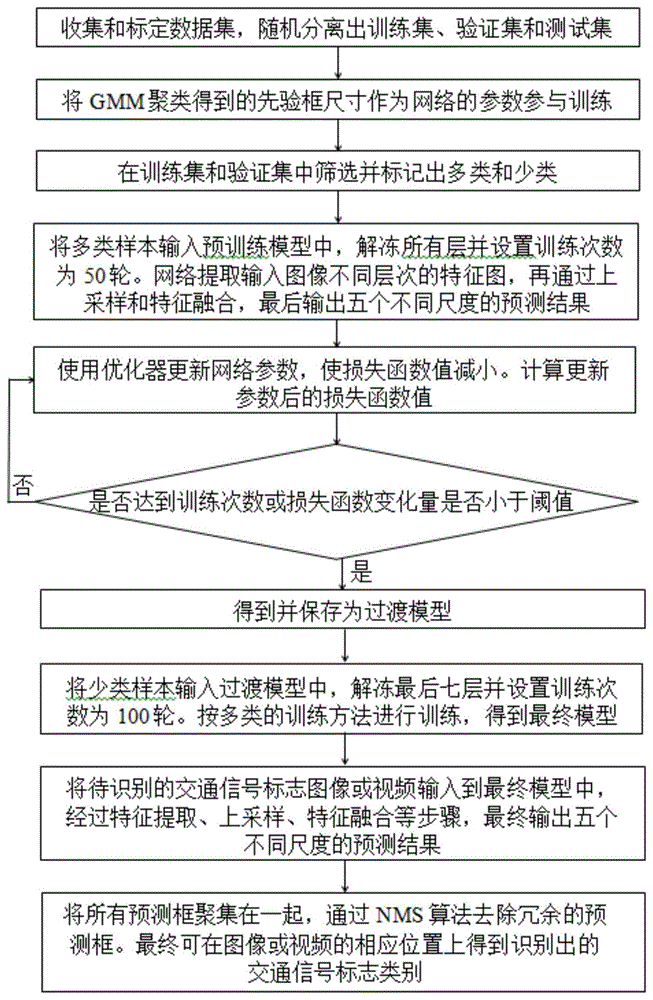
如图1所示,本发明包括以下步骤:
步骤一:数据准备;
通过对中国交通违章事件进行的统计,选择违章概率最高的25类交通标志作为数据集类别;一共收集到10000张包含有交通灯和交通标志牌的数据集,标定数据集并生成xml格式文件;随机选取2000张样本图片作为测试集,不参与神经网络的训练,只用来测试网络模型的性能;剩下的8000张样本图片被分为6000张训练样本和2000张验证样本后,需要参与神经网络模型的训练;计算并保存每个训练样本和验证样本中所有标定框的长宽大小。
步骤二:通过gmm聚类得到先验框尺寸作为网络的参数参与训练;
如图2所示,所述的步骤二中的gmm是以n个训练样本和验证样本中所有标定框的长宽大小作为二维数据点来构成;设有样本xi,则gmm的表达式:
其中:n是gmm中单一高斯模型的个数;πm是每个单一高斯模型的占比;p(xi|μm,varm)是样本xi在第m个单一高斯模型中的概率密度函数;μm、varm依次表示第m个高斯模型的均值、方差;
由公式(1)可知:gmm由单一高斯模型通过一定权重比叠加而成;因此,gmm可以用n个单一高斯模型无限逼近,就可认为所有标定框尺寸可被聚类为n个不同大小的先验框尺度;通过em算法对gmm的参数进行迭代更新:首先,分别初始化每个单一高斯模型的均值μ、方差var和每个单一高斯模型的占比π;通过以下公式(2)计算样本xi属于第m个单一高斯模型的概率,可称为样本xi对第m个单一高斯模型的贡献系数:
通过以下公式(3)计算似然函数初始值:
在得到wi,m之后,通过公式(4)、公式(5)和公式(6)依次更新πm、μm和varm:
以上便完成了一次gmm参数的更新,而通过更新后的πm、μm和varm可以进一步更新贡献系数和计算出此时的似然函数值,并往复迭代;随着参数的更新,似然函数值会不断变大,直到似然函数值的变化量小于预设阈值,此时gmm的参数达到收敛,聚类过程结束;
考虑到在多尺度识别网络中,最后需要输出五个尺度的预测结果,而每个尺度的预测结果需要三个不同大小的先验框;因此,需要通过gmm聚类出15个不同大小的先验框,即取n=15。
步骤三:先训练数据集中出现过多类的样本图像,若该样本图像中出现少类,也同时参与训练:将待训练图像输入神经网络中,网络提取输入图像不同层次的特征图,再通过上采样和特征融合,最后输出五个不同尺度的预测结果;通过迭代训练可以更新模型参数,得到过渡模型;其中多类为数据集中出现次数大于设定阈值的类,少类为数据集中出现次数小于设定阈值的类;
如图3所示,所述的神经网络的构建步骤如下:
设计由卷积层、bn归一化层、leakyrelu非线性激活函数串联构成的cbl基本单元;设计由步长为1的1×1cbl卷积和步长为1的3×3cbl卷积构成的res残差单元结构;设计由一个步长为2的3×3cbl卷积和n个res残差单元结构串联构成的resn结构;
神经网络分为特征提取网络和多尺度预测网络;特征提取网络会先调整输入图像的尺寸为512×512×3,再用1个输出通道为16的cbl卷积单元对输入图像进行滤波;再依次使用res1、res2、res8、res8、res4、res4残差结构对特征图进行下采样操作,同时增加特征图的通道数;通过特征提取网络可以依次得到128×128、64×64、32×32、16×16、8×8这些不同尺度的特征图,五个不同尺度的特征图将会被用于下一阶段的多尺度预测;
多尺度预测网络会将尺度为8×8的特征图依次通过步长为1的1×1、3×3、1×1、3×3、1×1五个cbl卷积来调整通道数,再通过一个步长为1的3×3cbl卷积和一个步长为1的1×1cbl卷积后可以得到8×8×90的预测结果;同时,尺度为8×8的特征图在依次通过步长为1的1×1、3×3、1×1、3×3、1×1、1×1六个cbl卷积和一次上采样后需要与尺度为16×16的特征图进行特征融合,得到新的特征图;新的特征图将会进行与尺度为8×8的特征图相同的变换,然后得到16×16×90的预测结果;同时,将会进一步与尺度为32×32的特征图进行特征融合;依次对特征提取网络得到的五个特征图进行上述变换,最后将得到128×128×90、64×64×90、32×32×90、16×16×90、8×8×90五个不同尺度的预测结果;
最终的预测结果会分别将输入图像分割成了128×128、64×64、32×32、16×16、8×8个网格,每个网格会产生三个预测框;预测框是由该网格对应的先验框通过回归过程得到的;每个预测框又由30个参数构成;参数分别为预测框中心的相对位置(x_offset,y_offset)、预测框的长宽(h,w)、预测置信度和25个类别的分类结果。
所述的步骤三中的训练步骤如下:
依据训练集和验证集的所有样本中出现次数是否大于500,将所有类别分为多类和少类,并分别保存出现过多类和少类的样本序号;先用步骤三中的神经网络训练多类序号的样本,同时也要训练这些样本中出现的少类目标;训练多类的步骤如下:
1)将多类序号的样本按照3:1的比例分离出训练集和验证集,两者都需参加训练;而验证集是通过训练网络的超参数来提高网络的识别准确度;
2)将训练集和验证集的xml格式的标定文件转换成训练所需的文件格式并保存;
3)设置训练超参数中的class为所有类别的class,输入预先搭建好的预训练模型,并解冻模型的所有层,设置为可训练;
4)设计损失函数等于位置预测损失函数、置信度预测损失函数和类别预测损失函数之和,其值大小为预测结果和标定的真实结果之间的差距大小;
5)设置初始学习率和学习率衰减策略,训练中选择用adam算法作为优化器来自动调整神经网络的权重参数,来使损失函数值不断减小;
6)将输入图像尺寸调整为512×512,并输入到神经网络中进行50轮的迭代训练;直到达到训练次数或损失函数的变化量小于阈值,则停止训练,得到并保存为过渡模型。
步骤四:按步骤三的训练方法训练少类,得到最终模型;
少类样本训练步骤如下:
1)将少类序号的样本按照3:1的比例分离出训练集和验证集;
2)将训练集和验证集的xml格式的标定文件转换成训练所需的文件格式并保存;
3)设置训练超参数中的class为所有类别的class,输入过渡模型作为预训练模型,并解冻模型的最后七层,设置为可训练;
4)设计损失函数等于位置预测损失函数、置信度预测损失函数和类别预测损失函数之和,其值大小为预测结果和标定的真实结果之间的差距大小;
5)设置初始学习率和学习率衰减策略;训练中选择用adam算法作为优化器来自动调整神经网络的权重参数,来使损失函数值不断减小;
6)将输入图像尺寸调整为512×512,并输入到神经网络中进行100轮的迭代训练;训练时,也要训练少类样本中出现的多类目标;直到达到训练次数或损失函数的变化量小于阈值,则停止训练,得到并保存为最终模型。
步骤五:识别时将待识别图像输入最终模型,可得到图像相应位置上的识别结果。
识别具体步骤为:将待识别的交通信号标志图像或视频输入到最终模型中,经过特征提取、上采样、特征融合,神经网络模型最终将会输出五个不同尺度的预测结果,从预测结果中可以得知每个预测框的位置、大小信息以及框内出现各类别的概率;将所有预测框聚集在一起,通过nms算法去除冗余的预测框,最终可在图像或视频的相应位置上框出识别出的交通信号标志类别;
上述的nms算法具体步骤如下:
1)设定预测结果中每个预测框的预测置信度与其预测出的每类分类结果的乘积最大值作为该预测框的得分,而该最大值对应的类别即是该预测框预测出的框内所属类别;
2)设定得分阈值,将得分低于得分阈值的所有预测框剔除,保留得分高于得分阈值的所有预测框;
3)设定交并比阈值,在剩下的预测框中选取得分最高的预测框为标准,剔除所有与该预测框交并比大于交并比阈值的预测框;
4)重复步骤3),直到完成对所有预测框的处理。
本发明的步骤二通过gmm来进行先验框聚类,使聚类结果可以拥有任意椭圆的形状,更加符合实际情况。这样做提高了聚类的灵活性,明显降低了聚类误差,加快了训练和识别过程中预测框的回归过程,从而提高了神经网络的识别准确度、训练速度和识别速度。
本发明的步骤三提出了基于特征金字塔的五尺度识别网络。其中,8×8尺度的特征图有最大感受野,能够很好地检测图像中的大目标,而128×128尺度的特征图有最小的感受野,对图像中的小目标具有很好的识别效果。所以,本发明方法解决了现有的基于single-stage的交通信号标志识别方法无法较好识别小目标的问题,达到了很好的小目标识别效果。
本发明的步骤四将多类训练得到的过渡模型作为预训练模型,且用更多的训练次数迭代训练少类样本并得到最终模型。最后实现了对数据样本少的类别也能达到较好的识别效果,提高了整体识别准确度。
本发明的具体实施例:
实验图像共有10000张,所收集到的交通信号灯和交通标志牌类别包括:直行红灯、直行绿灯、左转红灯、左转绿灯、右转红灯、右转绿灯、直行车道、左转车道、右转车道、禁止停车、禁止驶入、禁止货车通行、禁止机动车通行、禁止掉头、禁止左右转、禁止左转、限重40吨、注意前方学校、注意人行横道、限速30、限速60、限速80、右侧通行、减速让行、停车让行,各类别的数据样本数量不均匀。随机选取2000张样本图片作为测试集,不参与神经网络的训练,只用来测试神经网络的性能。剩下的8000张样本图片被分为6000张训练样本和2000张验证样本后,需要参与神经网络模型的训练。
本实施例典型的样本图像如图4,图4(a)、(b)、(c)、(d)分别为不同地点拍摄的交通信号灯和交通标志牌图像。
本发明的实验环境为:cpu为
使用测试集得到的不同识别算法的识别性能对比如表1所示:
表1不同识别算法性能的客观评价
其中,map50和map75分别是iou的阈值大于0.5和大于0.75时的平均均值准确度,是评判识别准确度的重要指标,其值越大说明识别准确度越高。aps、apm和apl分别是识别网络在识别小目标、中目标和大目标时的均值准确度。fps是识别网络每秒能识别的图像数,其值越大则说明识别速度越快。
从表1中的数据可知,相比于现有的single-stage识别方法和two-stage识别方法,本发明提出的方法在识别准确率、训练速度和识别速度方面均具备一定的优势。特别的,本发明提出的方法在识别小目标和大目标时都提高了较大的识别准确度。具体来说,通过使用gmm聚类,不仅在一定程度上提高识别准确度,还缩短了训练和识别过程的耗时。通过使用五尺度识别网络,提高了对小目标和大目标的识别准确度。最后,通过采用迁移学习,进一步提高了网络的识别准确度。
本发明方法的识别检测结果示意如图5所示,其中,图5(a)、(b)、(c)、(d)、(e)、(f)分别是对图4(a)、(b)、(c)、(d)、(e)、(f)中交通信号灯和交通标志牌的识别结果图。
在图5中可以看到,在拍摄地点不同、交通信号灯和交通标志牌大小不一的情况下,本发明方法也能够准确快速地定位与识别出测试图像中相应位置上的交通信号灯和交通标志牌类别,这可以满足实时动态识别交通信号灯和交通标志牌的要求,也可以有效的应对一些复杂的环境状况。
由此可见,本发明能够实现交通信号标志的快速定位与正确识别,具有较高的准确度,并且具有网络训练速度快,识别速度快,小目标识别效果好等优点,能够应用于自动识别交通信号标志系统。
上述具体实施方式用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!