一种基于并行框架的时态频繁子图挖掘方法
1.本发明属于计算机科学与技术领域,特别涉及一种基于并行框架的时态频繁子图挖掘方法
背景技术:
2.近年来,大量的研究集中在对网络的分析上,包括书目数据库的演变网络、社会网络中的信息传播网络和其他信息网络。现有的对这些网络的研究大多采用各种图挖掘算法,如grami。grami算法是在单个图上挖掘频繁子图的最有效的单机算法之一。将频繁子图挖掘问题转化为约束满足问题(csp)。然而,grami算法是一种独立的算法,在大规模的图运算中效率较低,难以实现对于较低支持度频繁子图的挖掘。而且,现有的在分布式环境下挖掘单个子图的频繁子图的算法都是针对有向图的,需要指定子图k的顶点个数,不支持子图增长模式的挖掘。其他分布式频繁子图挖掘算法大多基于mapreduce框架,在迭代计算过程中需要多次读写磁盘,导致大量的输入输出i/o、序列化和反序列化开销,也不能移植到单个图上进行挖掘。基于上述缺陷,最近有研究者提出了基于spark的频繁子图挖掘算法fsmbus和基于spark的单图挖掘ssigram算法。但上述基于spark的算法未考虑时态图中的时间信息属性。
3.文献综述表明,现有的图挖掘算法大多不考虑图中的时态信息,导致无法利用时态属性来检测重要的时态模式。因此,本发现尝试以最小支持度的fsmbus演算方法来分析时态频繁子图,并融合时态属性计算其频率。此外,基于fsmbus的结果,本发明也尝试使用增量式更新策略来计算时态频繁子图。
技术实现要素:
4.本发明所解决的问题是,针对现有技术的不足,提供一种spark平台下的时态频繁子图挖掘方法,该方法对spark框架下单个大图中的频繁子图挖掘方法fsmbus进行拓展,根据用户自定义的最小支持度实现时态频繁子图挖掘。
5.本发明所提供的技术方案为:
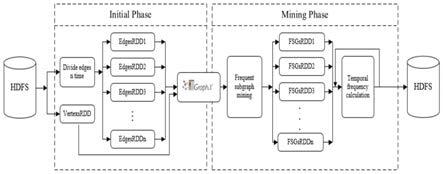
6.一种基于并行框架的时态频繁子图挖掘方法,包括两个阶段。第一阶段为系统从hdfs中加载具有时间属性的图数据,并按时间序列对边进行划分,为同一时间片生成单个rdds并计算频繁的边;第二阶段又分为频繁子图挖掘和时频计算两个子阶段,频繁子图挖掘阶段接收频繁子图edgesrdd并迭代挖掘子图,而时频计算则从频繁子图挖掘阶段接收第一个fsgsrdd并计算所有子图的时间频率,最后将结果写入hdfs。
7.第一阶段具体步骤为:
8.步骤1:edgerdds基于输入边数据集的附加时间属性形成,根据图的边和顶点的组合,将它们组合生成图,然后将最小支持度小于给定最小支持度的边直接过滤为不频繁边。以三元组(srclabel,attr,dstlabel)格式存储的剩余频繁边,其中srclabel是源顶点标签,attr是边标签,dstlabel是目标顶点标签。这些频繁边是由cams构成的次优树的第一层
频繁子图,树的根是一个空矩阵。
9.步骤2:根据频繁边遍历原始图,得到与顶点id关联的所有频繁边。在映射频繁边和顶点id之后,它被存储为一个域。因为在频繁子图挖掘的迭代过程中,这个频繁edgerdd将被用来扩展候选子图,并且将被直接缓存以加快扩展速度。这种存储结构的优点是可以直接用来计算候选子图的支持度。
10.第二部分的步骤为:
11.步骤1:在i-1迭代中,利用广度优先搜索(bfs)策略,通过ffsm连接和ffsm扩展,生成所有候选频繁子图,新的候选子图相当于在父子图中添加一条边,称为扩展边。新的候选子图的数据结构包括其父图的id,以及它的拓扑结构,这些拓扑结构可以帮助候选子图构造候选子图,并在频繁边图数据中进行搜索和支持。
12.步骤2:当子图扩展后,所有新生成的子图都被发送到下一个支持度评估过程中,并采用约束满足问题csp模型作为mni支持度计算策略,这是寻找子图同构的有效途径。它采用了rdd的迭代增量设计和spark的双连接方法,保存了每个生成子图的csp域数据。第一个连接操作将新生成的子图和频繁边结合起来得到扩展边,而第二个连接操作将新生成的子图和扩展边结合起来生成搜索方式。
13.此过程将继续进行,直到没有任何频繁项被留下,然后合并子图并发送到下一个过程以进行时间频率计算,并对edgesrdd2重复整个过程,然后对edgesrdd3重复整个过程,直到edgesrddn为止。
14.步骤3:迭代执行所有搜索,首先导入fsgsrdd1,并认为所有元素(频繁子图)在fsgsrdd1中具有频率值“1”,然后导入第二个元素(fsgsrdd2),并搜索将与fsgsrdd2中的候选频繁子图矩阵同构的子图。假设fsgsrdd中的所有元素(频繁子图)都是唯一的,且不应多于一个元素(矩阵),并且每个元素只搜索一次。当在fsgsrdd2中搜索一个候选子图(矩阵)并且矩阵匹配时,它的频率将增加“1”,并且不会搜索整个rdd,courser将被转移到fsgsrdd1的下一个迭代中。
15.步骤4:搜索完成后,将结果合并到一个rrd中,以便下次搜索fsgsrdd2,现在将对合并的rdd重复整个匹配过程,并且下一个fsgsrdd3和该过程将继续到最后一个fsgsrddn。
16.步骤5:
17.按时间粒度划分的从开始时间到最后一次的不同数据流时间段的计数次数,用t
t
表示,其中t是最后一次的值。时态频繁子图数据可以用如下公式表示:其中是在总时间t中出现i时间的单个子图的外观。例如,以年为时间粒度,开始时间为2010,结束时间为2020,t
t
=10。在此期间,数据项出现在2015年和2019年的两年内,然后,当前频率为i=2,时间为10。累积统计公式分别如下所示:
18.t
t
= t
t-1
+1
ꢀꢀꢀ
(1)
[0019][0020]
有益效果
[0021]
本发明提出了一种在并行化平台中挖掘图数据中时态频繁子图的方法。本发明运用spark对数据进行并行的时态频繁子图挖掘,在挖掘的过程中,基于最小支持度和时态更新算法实现带有时态属性的频繁子图挖掘。
[0022]
1、大多数现有频繁子图挖掘算法未考虑图中的时间信息,这导致无法利用时间属性来检测重要的时间模式。
[0023]
2、我们使用了spark分布式框架进行并行挖掘,该框架可以从大型时态图数据集中高效地计算时态频繁子图。
[0024]
3、实验结果表明时态的效果对于将来的预测和决策更好,因为它会利用时间属性使频繁子图挖掘数据更加实用和有用。
附图说明
[0025]
附图1为本发明的整体流程图;
[0026]
附图2为本发明中csp域的结构图;
[0027]
附图3为本发明中时频计算流程;
[0028]
附图4为本发明中挖掘过程时态频繁子图数量;
[0029]
附图5为本发明时态与非时态频繁子图对比;
[0030]
附图6为本发明并行时间对比
具体实施方式
[0031]
以下结合附图和具体实施方式对本发明进行进一步具体说明。
[0032]
如图1所示,本发明的主要包含两个阶段:初始阶段、挖掘阶段。过程描述为:
[0033]
(1)初始阶段
[0034]
初始阶段需要完成的主要任务是生成多个edgesrdd,收集频繁边的数据,初始化频繁的子图数据。首先,edgerdds基于输入边数据集的附加时间属性形成,如图1的初始阶段所示。根据图的边和顶点的集合,将它们组合生成图,然后将最小支持度小于给定最小支持度的边直接过滤为不频繁边。以三元组(srclabel,attr,dstlabel)格式存储的剩余频繁边,其中srclabel是源顶点标签,attr是边标签,dstlabel是目标顶点标签。这些频繁边是由cams构成的次优树的第一层频繁子图,树的根是一个空矩阵。
[0035]
然后,根据频繁边遍历原始图,得到与顶点id相关的所有频繁边。在映射频繁边和顶点id之后,它被存储为一个域(图(2)d所示)。因为在频繁子图挖掘的迭代过程中,这个频繁edgerdd将被用来扩展候选子图,并且将被直接缓存以加快扩展速度。域d的结构如图2所示。图2(a)中的结构由具有k个顶点的候选子图表示。其中,ux表示有效分配给d(1)的顶点,uy表示有效分配给d(k-2)的顶点。{k-2
→
{uy}表示d(1)的ux和d(k-2)的uy之间的联系。同时,将该算法应用于无向图的挖掘,使得d(k-2)与d(1)之间存在对称的连接信息。图2(b&c)是图2(d)的例子,图2(d)是一个无向图,根据图2(b),可以分别得到边连接。
[0036]
(2)挖掘阶段
[0037]
首先,在i-1迭代中,利用广度优先搜索(bfs)策略,通过ffsm连接和ffsm扩展,生成所有候选频繁子图,新的候选子图相当于在父子图中添加一条边,称为扩展边。新的候选子图的数据结构包括其父图的id,以及它的拓扑结构,这些拓扑结构可以帮助候选子图构造候选子图,并在频繁边图数据中进行搜索和支持。
[0038]
当子图扩展后,所有新生成的子图都被发送到下一个支持度评估过程中,并采用约束满足问题csp模型作为mni支持度计算策略,这是寻找子图同构的有效途径。它采用了
rdd的迭代增量设计和spark的双连接方法,保存了每个生成子图的csp域数据。第一个连接操作将新生成的子图和频繁边结合起来得到扩展边,而第二个连接操作将新生成的子图和扩展边结合起来生成搜索方式。此过程将继续进行,直到不留任何不常发生的情况,然后合并子图并发送到下一个过程以进行时间频率计算,并对edgesrdd2重复整个过程,然后对edgesrdd3重复整个过程,直到edgesrddn为止,如图1所示。
[0039]
根据频繁子图挖掘步骤,所有频繁子图都被有效地计算并存储在列表(fsgsrdd)中,如图1的挖掘阶段所示。所有fsgsrdd(1到n)显示不同时间段的频繁子图的排序,fsgsrdd中所有频繁子图都以矩阵的形式显示。
[0040]
在这一步中,我们将及时计算所有频繁子图的频率,这将被称为时间频繁子图。迭代执行所有搜索,首先导入fsgsrdd1,并认为所有元素(频繁子图)在fsgsrdd1中具有频率值“1”,然后导入第二个元素(fsgsrdd2),并搜索将与fsgsrdd2中的候选频繁子图矩阵同构的子图。
[0041]
假设fsgsrdd中的所有元素(频繁子图)都是唯一的,且不应多于一个元素(矩阵),并且每个元素只搜索一次。当在fsgsrdd2中搜索一个候选子图(矩阵)并且矩阵匹配时,它的频率将增加“1”,并且不会搜索整个rdd,courser将被转移到fsgsrdd1的下一个迭代中。
[0042]
搜索完成后,将结果合并到一个rrd中,以便下次搜索fsgsrdd2,现在将对合并的rdd重复整个匹配过程,并且下一个fsgsrdd3和该过程将继续到最后一个fsgsrddn。
[0043]
例如,由两个月记录和每个月组成的时态多样性信息网络数据库,其频繁子图如表1所示。数据库包含两种节点类型,包括人和位置,以及三种边类型,包括“呼叫”、“见面”和“在”。其中“呼叫”表示有人正在打电话给其他人,“在”表示有人停留在特定的地点,“见面”表示有人遇到了另一个人。
[0044]
表1社交网络中的频繁子图
[0045][0046]
有五个人(即a、b、c、d、e)和四个地点(即酒吧、实验室、餐厅、咖啡厅)。每个交互都由一组社交交互组成,这些交互在不同的日子使用四个元组项进行记录。每个元组包含一个源节点、关系、目标节点和时间戳。
[0047]
我们给出了两个月的计算频繁子图。现在我们可以使用上表中的一些频繁子图更详细地了解时间频率计算,并在图3中表示。假设“1月”中的一个fsg(a-call-b)具有“频率1”,并在“2月”中搜索它,如果它存在于“2月”中,那么它的频率将增加“1”,否则频率将保持不变,因此它的频率将更新为1。现在,fsg(b-call-d)在“第2个月”中不存在;因此,它的频率保持不变,以此类推,直到最后一个fsg,将两个月的结果结合起来。如果还有“下个月”,则相同的过程将重复,结果合并为第1个月和第2个月。因此,整个过程将重复一个月,找出哪个频繁子图fsg是时间频繁子图。这样,就可以计算出所有具有相关计算频率的时态频繁
子图的结果。
[0048]
实验分析
[0049]
本文的主要问题是利用spark框架挖掘单个图中的时态频繁子图。整个实验的环境设置如下:主机采用英特尔酷睿i7-7700hq处理器,2.40ghz,20gb内存,采用ubuntu 19.04操作系统,spark版本2.3.1,scala版本2.11。spark集群由一个主节点和两个工作节点构成,主节点配置相同,内存为8g,每个工作节点配置2g内存。
[0050]
在我们的工作中,所涉及的主要图数据是单个大图形。为了展示我们的解决方案的准确性和效率,我们在java中对随机函数生成的包含时间信息的仿真数据进行了不同的实验处理。此外,本研究将整个模拟数据分为11年,从2000年到2010年,共有10万个节点和100个不同的标签,组合的边总数(关系)为1080298个,年度数据的规模见表2。
[0051]
表2数据规模
[0052][0053]
1、具有时间频率的频繁子图的有效性
[0054]
为了验证时频的有效性,我们比较了频繁子图和时间频率的结果。我们给出了频率子图(非时态频率)和频率子图(时态频率又称时态频繁子图)与去年的比较结果。为了评估时态和非时态频繁子图的有效性,我们使用三个不同的最小支持值计算频繁子图,相应的结果如表3所示。每一行表示每年发生的与最小支持值相关的频繁子图的数量,支持值5、6和7分别被使用并放置在表的标题中,用于所有实验结果分析。
[0055]
表3每年的频繁子图数量
[0056][0057]
利用频繁子图挖掘技术提取2000-2010年的数据,并相应地计算出每年的时间频率。例如,在2001年的时频计算中,我们取2000年的频繁子图分别搜索,即2001年的频繁子图出现了多少次,并对不同最小支持度计算的不同数据重复此过程。所有结果如图4(a)所
示,其中x轴由具有2001-2010年值的时段组成,y轴显示相应年份数据的时间子图出现次数。如图所示,当最小支持值减小时,我们可以看到显著的变化,这使得频繁子图和时间频繁子图的数量成指数增加。
[0058]
也可以在表3中找到。用最小支持度-7计算的频繁子图数据的平均数小于用支持度-6计算的频繁子图数据的平均数,远小于用支持度-5计算的频繁子图数据的平均数。然而,最小支持度7和支持度6的时间频繁子图的平均精度(2.69%和8.39%)与最小支持度5计算的时间频繁子图的平均精度(17.01%)很低。
[0059]
2、频繁子图与时间频繁子图的对比实验
[0060]
图5中举例说明了2006-2010年时间频繁子图和非时间频繁子图的对比效果,其中y轴表示时态频繁子图和非时态频繁子图的出现次数,x轴由分别具有2006-2010年值的时间段组成。对时态频繁子图和非时态频繁子图的预测结果进行了对比试验,将过去5年的预测结果压缩到当年,如我们用2001年到2005年的2006年的挖掘,用2007年的挖掘,因此,我们在2002年至2006年期间采用了相同的挖掘方法。我们使用了20作为阈值,这是每五年最低的最小支持值,并且每年使用阈值“5”。从图5可以看出,时间频繁子图的数量逐渐增加,预测2011年数据集中的时间频率更多。研究还表明,时态频繁子图的出现次数小于非时态频繁子图的出现次数,说明排除了许多无意义的子图。五组数据的时频预测的平均子图数比非时间频率预测低59.91%。因此,时频的预测效果在未来的决策中会更好,因为它积累了时间,使得频繁子图挖掘数据更加实用和有用。
[0061]
3、spark并行能力的影响
[0062]
基于spark的时态频繁子图算法的可扩展性实验以评估spark集群中执行器的时间效应,该算法建立在一台主机上,主机配置有ubuntu19.04、2.80ghz的intel core i7-7700hq cpu、20gb的ram和4个附加的虚拟节点,采用相同的2gb内存配置。计算节点与主节点并行连接。算法的时间性能是针对所有年份的组合时间频率分别计算最小支持值(5,6,7),实验结果如图6所示。其中(a)显示所有支持值的结果,(b)仅显示支持6和支持7的结果,以获得更好的执行差异。
[0063]
如图6(a)所示,在时间频率计算的阈值下,算法所占用的运行时间在减少,执行器的数量在增加。随着执行器数量的增加,算法所消耗的时间减少,曲线开始变慢。同时,当执行数相同,且时间频率计算的阈值不同时。但是,由于所有工作节点的核心进程数量都在增加,并且数据计算量不变,运行时间仍然在不断减少,这验证了分布式环境的效率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1