一种面向投影增强的基于机器视觉的手势交互方法与流程
本发明属于人机交互技术领域,具体涉及一种面向投影增强的基于机器视觉的手势交互方法。
背景技术:
随着信息技术的快速发展,人与各种计算机系统的交互活动已经变得不可避免,因此人机交互技术受到了越来越多的重视。像vr这种新技术新设备如雨后春笋般出现,同时,与这些设备进行高效的、人性化的操作也成为技术难点和重要的研究方向。相比于鼠标、键盘和触摸屏,手势具有灵活、直观和非接触性等特点;手势识别不仅在vr中扮演重要角色,在ar、无人机控制、智能家居和手语识别等众多领域都有广泛应用,而且发挥着越来越重要的作用。在航空宇航制造领域,由于飞机等重大装备在装配方面存在零部件多和手工装配多,容易造成错装漏装等问题,这些问题极大的影响日后乘客的安全。而基于增强现实的智能装配引导系统可以很好的解决上述问题,在实际装配中,投影增强现实系统更加适应装配现场,但是却存在交互不自然的问题。
在投影增强现实系统中,传统的交互方式是键盘鼠标交互,通过敲击键盘和点击鼠标实现交互,并将装配引导信息进行显示,然而在装配现场无法安装计算机设备,这就大大限制了投影增强现实系统的应用。随着计算机等技术的发展,有专家学者提出了利用kinect和leapmotion等设备实现手势交互,然而,这些设备的使用距离太近,影响工人装配操作。
中国文献“基于视觉的手势识别及其交互应用研究[d].南京理工大学,2017”对基于机器视觉的手势识别和交互进行研究,首先提出了现场肤色建模,解决了复杂光照环境下肤色检测的问题,紧接着提出了两种目标再检测机制,有效的解决了目标丢失的问题,然后,对传统帧差法进行改进,提高了手势检测效率,最后,使用傅里叶描述子作为手势特征,基于knn算法实现了静态手势的识别,基于统计计数识别方法实现了动态手势的识别,并最终模拟鼠标功能,实现出单目视觉下自然人手的人机交互。上述现有技术中的手势分割是基于肤色模型,当人手与人脸或类肤色区域重合时,就会造成分割不准确,严重影响后期的特征提取与手势识别,同时,识别的静态手势和动态手势都比较少,限制条件较多,只能模拟鼠标的若干功能,达不到以最自然的方式与机器交互。
技术实现要素:
本发明的目的就是针对上述现有技术的不足,提供一种在投影增强现实系统中实现更自然的人机交互,提高系统的适用性,交互的宜人性以及装配效率的面向投影增强的基于机器视觉的手势交互方法。
本发明采用的技术方案如下:
一种面向投影增强的基于机器视觉的手势交互方法,步骤如下:
步骤1:投影仪与相机进行联合标定,先利用实体的非对称圆标定板对相机进行标定,接着利用非实体的棋盘格标定板对投影仪进行标定,使非实体的棋盘格标定物与实体的非对称圆标定物在同一块标定板上,并通过相机同时捕获非对称圆标定板和棋盘格标定板,从而使投影仪与相机在同一个坐标系;
步骤2:打开相机并手动调节相机的光圈大小和曝光时间,接着设置相机帧率和图像尺寸,然后进行无手势图像的采集;
步骤3:将采集到的无手势图像转换为背景图像,并通过预处理对背景图像中的噪点和无关的信息进行消除,恢复背景图像中有用的真实信息;
步骤4:利用相机采集虚拟场景中的当前图像,将当前图像与背景图像通过帧差法进行做差,消除当前图像中的背景信息且得到其绝对值,从而获取当前图像中的手势信息,然后通过现有的canny算子对手势信息进行边缘轮廓检测,从而获取手势轮廓;
步骤5:对获取的手势轮廓通过opencv进行遍历像素点,然后对像素点的坐标进行判断,获取最高点,从而提取出手势轮廓中的指尖点坐标;
步骤6:通过矩阵转换并以世界坐标系为中转,将虚拟场景中的交互区域坐标和交互按钮坐标与指尖点坐标进行位置和时间判断,当指尖点的位置长时间位于某一个交互按钮上,即激活交互操作,然后将判断结果传输至计算机;
步骤7:分析判断结果,然后根据预先定义的交互操作的交互类型,计算机执行相应的操作。
步骤1中,所述相机的标定原理表示为:
步骤1中,所述投影仪与相机进行联合标定,来获取投影仪与相机的内参矩阵,所述内参矩阵表示为:
步骤1中,所述投影仪与相机进行联合标定,来获取投影仪与相机的外参矩阵,所述外参矩阵表示为:
步骤3中,所述无手势图像转化为背景图像的具体步骤如下:(1)先通过相机获取3-5张无手势图像;(2)将获取的无手势图像进行读取且转换为矩阵形式,接着利用opencv中的相关函数进行求和,然后求解均值;(3)将求解出均值的无手势图像作为背景图像。
所述背景图像上设有矩形状的交互按钮,便于投影仪在背景图像上进行投影。
步骤3中,所述预处理包括灰度化、几何变化以及增强步骤。
步骤2中,所述相机的帧率为大于等于5帧。
本发明的有益效果有:
(1)本发明在装配现场时,装配工人只需要简单手势就可以实现交互,不需要配戴设备,真正实现了自然交互,提高系统的实用性;
(2)本发明通过选择兴趣区域可以缩短手势检测的时间,提高手势判断的时间和精度以及缩短程序响应时间,从而提高了交互效率。
附图说明
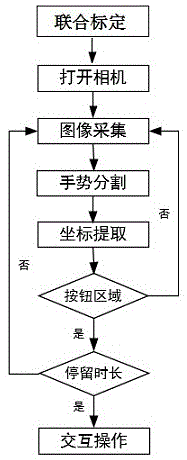
图1为本发明的流程图。
具体实施方式
通过以下说明和实施例对本发明的面向投影增强的基于机器视觉的手势交互方法作进一步的说明。
如图1所示,本发明它包括:
步骤1:投影仪与相机进行联合标定,先利用实体的非对称圆标定板对相机进行标定,接着利用非实体的棋盘格标定板对投影仪进行标定,使非实体的棋盘格标定物与实体的非对称圆标定物在同一块标定板上,并通过相机同时捕获非对称圆标定板和棋盘格标定板,从而使投影仪与相机在同一个坐标系;该投影仪与相机进行联合标定用于为后续的坐标提取和手势判断提供数据,其中非对称圆标定板对相机进行标定时,需将非对称圆标定板相对于相机成像平面保持45度,便于保证相机标定的精度。
所述利用实体的非对称圆标定板对相机进行标定的具体步骤为:(1)先通过相机对虚拟场景进行多角度采集图像;(2)利用opencv中的相关算法进行计算来获取图像中的圆心角点坐标,并对应其图像坐标和世界坐标,计算出线性模型的内参矩阵;(3)利用内参矩阵计算出非线性模型的畸变参数,并重新计算线性参数,反复进行迭代,从而求得内部参数和畸变参数,并根据内部参数和畸变参数求得外参矩阵。
所述联合标定时通过相机多角度采集24-26张图像,然后利用相机的内参和外参矩阵计算出投影仪的棋盘格角点的世界坐标,并根据投影仪的内参和外参矩阵计算出棋盘格角点坐标,匹配其世界坐标,从而求出投影仪与相机共同的内部和外部参数,使投影仪和相机在同一个坐标系。
步骤2:打开相机并手动调节相机的光圈大小和曝光时间,接着设置相机帧率和图像尺寸,然后进行无手势图像的采集;该相机通过调用opencv中的videocapture函数打开,其中相机帧率为大于等于5帧。
步骤3:将采集到的无手势图像转换为背景图像,并通过预处理对背景图像中的噪点和无关的信息进行消除,恢复背景图像中有用的真实信息;其中预处理包括灰度化、几何变化以及增强步骤。
步骤4:利用相机采集虚拟场景中的当前图像,将当前图像与背景图像通过帧差法进行做差,消除当前图像中的背景信息且得到其绝对值,从而获取当前图像中的手势信息,然后通过现有的canny算子对手势信息进行边缘轮廓检测,从而获取手势轮廓;该相机通过调用opencv中的videocapture函数打开。
所述当前图像与步骤2中采集的无手势图像通过帧差法进行做差,若做差结果为0,则表明当前图像中没有手势信息,然后重新采集虚拟场景中的当前图像,直到能顺利做差,获取当前图像中的手势信息。
步骤5:对获取的手势轮廓通过opencv进行遍历像素点,然后对像素点的坐标进行判断,获取最高点,从而提取出手势轮廓中的指尖点坐标;
步骤6:通过矩阵转换并以世界坐标系为中转,将虚拟场景中的交互区域坐标和交互按钮坐标与指尖点坐标进行位置和时间判断,当指尖点的位置长时间位于某一个交互按钮上,即激活交互操作,然后将判断结果传输至计算机;
所述位置和时间判断表示指尖点坐标的位置要在交互区域和交互按钮区域里,并持续一定相机帧率。其中交互按钮的形状为矩形状,交互按钮的各个顶点的坐标以及每个交互按钮的交互操作都是预先设计定义的。
步骤7:分析判断结果,然后根据预先定义的交互操作的交互类型,计算机执行相应的操作。
步骤1中,所述相机的标定原理表示为:
其中相机标定的相机焦距为f,u轴和v轴的尺度因子分别为f/dx和f/dy,旋转矩阵为r,平移向量为t以及比例因子为zc,相机图像的中心点坐标为(u0,v0)。
步骤1中,所述投影仪与相机进行联合标定,来获取投影仪与相机的内参矩阵,所述内参矩阵表示为:
步骤1中,所述投影仪与相机进行联合标定,来获取投影仪与相机的外参矩阵,所述外参矩阵表示为:
步骤3中,所述无手势图像转化为背景图像的具体步骤如下:(1)先通过相机获取3-5张无手势图像;(2)将获取的无手势图像进行读取且转换为矩阵形式,接着利用opencv中的相关函数进行求和,然后求解出均值;(3)将求解出均值的无手势图像作为背景图像。
实施例:
步骤1:投影仪与相机进行联合标定,先利用实体的非对称圆标定板对相机进行标定,来获取相机的内参和外参矩阵,接着利用非实体的棋盘格标定板对投影仪进行标定,来获取投影仪的内参和外参矩阵,使非实体的棋盘格标定物与实体的非对称圆标定物在同一块标定板上,并通过相机同时捕获非对称圆标定板和棋盘格标定板,从而使投影仪与相机在同一个坐标系;
步骤2:通过调用opencv中的videocapture函数打开相机,并手动调节相机的光圈大小和曝光时间,接着设置相机帧率和图像尺寸,然后进行无手势图像的采集;
步骤3:将采集到的无手势图像进行读取且转换为矩阵形式,并利用opencv中的相关函数进行求和,接着求解均值,其中求解出均值的无手势图像作为背景图像,然后对背景图像进行灰度化、几何变化以及增强步骤的预处理,从而对背景图像中的噪点和无关的信息进行消除;
步骤4:利用opencv中的videocapture函数打开相机来采集虚拟场景中的当前图像,将当前图像与背景图像通过帧差法进行做差,消除当前图像中的背景信息且得到其绝对值,从而获取当前图像中的手势信息,然后通过现有的canny算子对手势信息进行边缘轮廓检测,从而获取手势轮廓;
步骤5:对获取的手势轮廓通过opencv进行遍历像素点,然后对像素点的坐标进行判断,获取最高点,从而提取出手势轮廓中的指尖点坐标;
步骤6:通过矩阵转换并以世界坐标系为中转,将虚拟场景中的交互区域坐标和交互按钮坐标与指尖点坐标进行位置和时间判断,当指尖点的位置长时间位于某一个交互按钮上,即激活交互操作,然后将判断结果传输至计算机;
步骤7:分析判断结果,然后根据预先定义的交互操作的交互类型,计算机执行相应的操作,从而完成此次手势交互。
本发明涉及的其它未说明部分与现有技术相同。
- 还没有人留言评论。精彩留言会获得点赞!