基于双重注意力机制的风机叶片结冰故障预测方法与流程
本发明涉及一种基于双重注意力机制的风机叶片结冰故障预测方法,属于工业系统故障预测领域。
背景技术:
风力发电是目前最成熟、最具发展潜力的可再生能源技术。中国的风电发展举世瞩目。但风能获取的特殊性决定了大量风机需布置在高纬度、高海拔的寒冷地区。而工作在寒冷地区的风机受霜冰、雨凇和湿雪等气象条件影响,极易发生叶片结冰现象,进而引发一系列后果。导致风能捕获能力下降,发电功率损耗,风机叶片断裂,甚至造成安全事故。
所以,及时预测并预防叶片结冰故障对于延长风电设备使用寿命、预防重大安全事故具有重要意义。在实际运行中,严重的结冰一般能够被轻易检测到,并通过风机除冰系统自动除冰。但严重结冰一旦形成,对叶片性能就会产生不可逆的影响。目前主要的方法一种是利用传感器采集叶片温度数据来判断叶片是否有早期结冰的现象,再通过除冰系统进行处理,但这个方法有两个明显的缺点:一是需要额外布置传感器导致成本飞升,二是当检测到叶片结冰的时候往往已经对叶片造成损伤,能够一定程度延长叶片寿命但是作用有限。另外也有基于数据驱动的方法,应用机器学习以及深度学习算法模型,通常利用scada系统采集到的工业设备运行数据来提取工业设备信号之间复杂的非线性关系,寻找异常测量值来对结冰的风机叶片进行诊断,这种基于数据的诊断方法除了能够对结冰叶片进行有效检测,也大大降低了风场成本。尽管可以准确的检测到风机叶片的早期结冰现象从而对叶片进行维护,但是结冰仍然会影响风机叶片的物理参数,对风机发电设备造成一定的影响。而本发明的方法利用scada系统采集到的大量时序检测变量,基于cnn+lstm网络结合双重注意力机制,来预测风机叶片结冰现象,能够在叶片结冰以前,就预测到何时会发生结冰,以提前做好保护措施防止叶片的结冰,对风力发电系统的安全可靠持续运营起到更大的作用。
技术实现要素:
本发明的目的在于提出一种基于双重注意力机制的风机叶片结冰故障预测方法,创新点在于使用两种不同的注意力机制分别提取数据中时间和通道维度的特征,同时提出一个准确率较高的故障预测模型用来解决常用的基于数据驱动的叶片结冰诊断方法中,只能在叶片结冰后进行检测,不能提前防止叶片结冰,从而影响叶片和风力发电机的物理性能。本方法首先将预处理后的数据输入cnn网络,通过cnn学习到局部特征,加入注意力层帮助cnn网络重点关注数据中局部信息的重要程度,cnn网络输出的高维特征再经过lstm网络,通过lstm神经网络学习序列数据各个时间之间的依赖关系,再通过注意力层衡量对应时间段的数据在预测结冰时的重要性,最后通过历史时间的数据信息预测出下一个时间段的风机叶片结冰与否。本方法能够自适应地从scada系统采集的原始数据中提取故障特征和时序信息,能够自适应的关注到风机叶片数据中时间和通道维度的特征,能够对风机叶片结冰状态进行较为准确的预测。
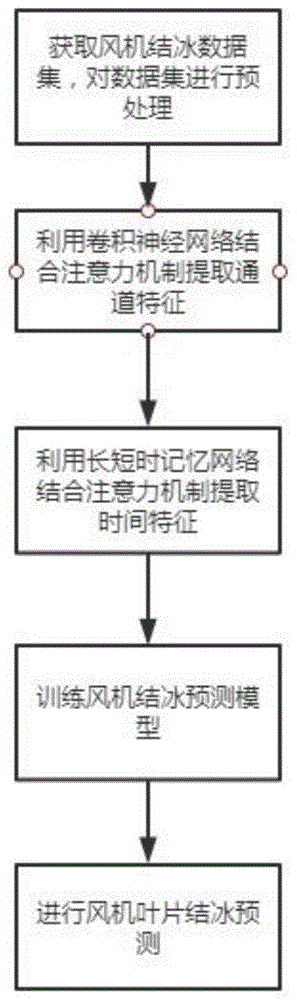
为实现上述目的,本发明采用的技术方案为基于双重注意力机制的风机叶片结冰故障预测方法:如图1所示,该方法的实现步骤如下:
步骤(1):获取风机结冰原始数据集
原始数据集来自《第一届中国工业大数据竞赛》风机结冰数据集,该数据采集自工业scada系统,总长度为2个月,包含了约58万条数据,每条数据包含28个维度,包含风速、发电机转速、网侧有功功率、风向角、各叶片角度、变桨电机温度等特征维度,数据经过标准化处理。数据集中的时间以分钟为最小时间单位,每分钟大约包含6~10组测量值。
步骤(2):对数据集进行预处理
根据数据中结冰和不结冰的时间段,把原始数据分为正常数据即正样本,标签为正常,故障数据即负样本,标签为结冰,无效数据即无标签的数据;在构建训练集时,首先删除无标签的无效数据。把每分钟作为一个单位时间,取同一个单位时间内的几组测量值,用多个统计量来表示特征,对于每一个特征量,都用m种统计表示法来进行特征扩展。得到单位时间间隔的每组是(m,n)维的数据,即
步骤(3):使用cnn进行特征提取,卷积层用训练集数据通过卷积核进行卷积并生成特征,随后池化层提取最重要的局部特征。再通过attention层关注提取到的特征中不同特征的重要性。这里用到location-basedattention,关注隐藏向量本身。
输入的数据按单位时间划分为x=[x1,x2,......,xn],n表示序列长度。卷积运算的卷积核定义为w。当输入数据x时,卷积层的特征图
其中,b表示偏移量,
池化层用于进行下采样,在本方法中,下采样的形式是maxpooling:
down(·)表示池化层的下采样函数,
cnn中attention关注的是特征向量本身,设计的attention模型为:
tanh(·)表示激活函数,
vi=∑i=1αipi(6)
这里vi表示利用cnn+attention对原始数据进行特征提取后的xi的高维表示。
步骤(4):使用lstm继续步骤(3)的网络构建,lstm的结构主要分为三个主要阶段:信息遗忘、长期状态更新、和短期状态更新。结合concatenation-basedattention,来捕获上下文相关信息,以帮助预测未来。
首先信息遗忘阶段:遗忘门ft先读取先前的短期状态ht-1和当前状态xt(这里用步骤3获得的高维表示vt),并通过sigmoid函数向上一个单元ct-1输出0到1之间的值。
ft=σ(wf·ht-1+wf·vt+bf)(7)
其中(wf,bf)是遗忘门的权重向量和偏差值,σ是sigmoid函数,vt表示由步骤3获得的t时刻原始数据xi(i=t)的高维特征vi(i=t)。
长期状态(long-termstate)更新阶段:确定哪些新信息存储在长期状态单元(long-termcellstate)中。输入门it确定更新的值,输入单元gt输入当前状态:
it=σ(wi·ht-1+wi·vt+bi)(8)
gt=tanh(wg·ht-1+wg·vt+bg)(9)
然后可以得到一个新的细胞状态(cellstate)ct.
短期状态(short-termstate)更新阶段:通过输出门ot对长期状态进行filter,得到短期状态ht。
ot=σ(wo·ht-i+wo·vt+bo)(11)
在故障预测任务中,最终的目标是根据x1到xt的风机状态预测xt+1的状态,即yt。利用注意力机制来捕获上下文相关信息,以帮助预测未来。首先计算当前状态ht与之前所有状态的权重,其中,当前状态ht和之前第i状态hi的权重αti,具体计算如下:
其中,θα是要学习的参数,wα为权重矩阵.
然后根据上述αti得到注意力向量αt,具体计算公式如下:
αi=softmax([αt1,αt2,...,αti])(14)
最后根据注意力向量αt和隐藏状态h1到ht-1,计算得到包含上下文注意力信息的向量vt:
预测阶段:结合上下文向量vt和当前隐藏状态ht两个向量的信息,生成一个向量
wc是权重矩阵。注意力向量
ws是权重矩阵,bs是偏移量。
目标函数:计算真实状态yt和预测状态
网络经过正向传播和反向传播,不断修改、更新各层神经元的参数值以及连接权重,验证集用于确定参数的最佳值,使误差值达到最小,直到满足迭代停止条件,得到训练好的模型。
利用步骤(2)中经过预处理的测试集对模型进行测试,选择准确率(accuracy)作为评价准则,可以验证该模型的预测准确率。
步骤(5)利用训练好的模型进行故障预测。
从scada系统中采集待预测数据集,将待预测数据集输入模型,可以通过历史的风机状态信息,预测未来时间段风机是否结冰。
该发明有益效果:
本发明利用scada系统采集到的大量检测变量通过卷积神经网络和长短期记忆网络结合双重注意力机制,对风机叶片结冰进行预测,在叶片结冰以前,就预测到何时会发生结冰,以提前做好保护措施防止叶片的结冰,对风力发电系统的安全可靠持续运营起到更大的作用。本方法首先将预处理后的数据输入cnn网络,通过cnn学习到局部特征,加入注意力层帮助cnn网络重点关注数据中局部信息的重要程度,cnn网络输出的高维特征再经过lstm网络,通过lstm神经网络学习序列数据各个时间之间的依赖关系,再通过注意力层衡量对应时间段的数据在预测结冰时的重要性,最后通过历史时间的数据信息预测出下一个时间段的风机叶片结冰与否。本方法能够自适应地从scada系统采集的原始数据中提取故障特征和时序信息,能够自适应的关注到风机叶片数据中时间和通道维度的特征,能够对风机叶片结冰状态进行较为准确的预测。
附图说明
图1为整体流程图。
图2为训练过程流程图。
图3为模型结构图
具体实施方式
本方法采用基于双注意力机制的风机叶片结冰预测方法,该方法的实现过程如下:
步骤(1):获取风机结冰原始数据集
原始数据集来自《第一届中国工业大数据竞赛》风机结冰数据集,该数据采集自工业scada系统,总长度为2个月,包含了约58万条数据,每条数据包含28个维度,包含风速、发电机转速、网侧有功功率、风向角、各叶片角度、变桨电机温度等特征维度,数据经过标准化处理。数据集中的时间以分钟为最小时间单位,每分钟大约包含6~10组测量值。
步骤(2):对数据集进行预处理
根据数据中结冰和不结冰的时间段,把原始数据分为正常数据即正样本,标签为正常,故障数据即负样本,标签为结冰,无效数据即无标签的数据;在构建训练集时,首先删除无标签的无效数据。把每分钟作为一个单位时间,取同一个单位时间内的几组测量值,对每个单位时间内的若干组测量值,分别用均值(mean)、方差(samplevariance)、标准差(standarddeviation)、变异系数(coefficientofvariation,cv)、标准误(standarderror)、偏度(skewness)、峰度(kurtosis)、中位数(median)、四分位数(quartile)来取代原始测量数据,对于每一个特征量,都用m种统计表示法来进行特征扩展。得到单位时间间隔的每组是(m,n)维的数据,即
步骤(3):使用cnn进行特征提取,卷积层用训练集数据通过卷积核进行卷积并生成特征,随后池化层提取最重要的局部特征。再通过attention层关注提取到的特征中不同特征的重要性。这里用到location-basedattention,关注隐藏向量本身。
输入的数据按单位时间划分为x=[x1,x2,......,xn],n表示序列长度。卷积运算的卷积核定义为w。当输入数据x时,卷积层的特征图
其中,b表示偏移量,
池化层用于进行下采样,在本方法中,下采样的形式是maxpooling:
down(·)表示池化层的下采样函数,
cnn中attention关注的是特征向量本身,设计的attention模型为:
tanh(·)表示激活函数,
vi=∑i=1αipi(6)
这里vi表示利用cnn+attention对原始数据进行特征提取后的xi的高维表示。
步骤(4):使用lstm继续步骤(3)的网络构建,lstm的结构主要分为三个主要阶段:信息遗忘、长期状态更新、和短期状态更新。结合concatenation-basedattention,来捕获上下文相关信息,以帮助预测未来。
首先信息遗忘阶段:遗忘门ft先读取先前的短期状态ht-1和当前状态xt(这里用步骤3获得的高维表示vt),并通过sigmoid函数向上一个单元ct-1输出0到1之间的值。
ft=σ(wf·ht-1+wf·vt+bf)(7)
其中(wf,bf)是遗忘门的权重向量和偏差值,σ是sigmoid函数,vt表示由步骤3获得的t时刻原始数据xi(i=t)的高维特征vi(i=t)。
长期状态(long-termstate)更新阶段:确定哪些新信息存储在长期状态单元(long-termcellstate)中。输入门it确定更新的值,输入单元gt输入当前状态:
it=σ(wi·ht-1+wi·vt+bi)(8)
gt=tanh(wg·ht-1+wg·vt+bg)(9)
然后可以得到一个新的细胞状态(cellstate)ct.
短期状态(short-termstate)更新阶段:通过输出门ot对长期状态进行filter,得到短期状态ht。
ot=σ(wo·ht-1+wo·vt+bo)(11)
在故障预测任务中,最终的目标是根据x1到xt的风机状态预测xt+1的状态,即yt。利用注意力机制来捕获上下文相关信息,以帮助预测未来。在故障预测任务中,最终的目标是根据x1到xt的风机状态预测xt+1的状态,即yt。利用注意力机制来捕获上下文相关信息,以帮助预测未来。首先计算当前状态ht与之前所有状态的权重,其中,当前状态ht和之前第i状态hi的权重αti,具体计算如下:
其中,θα是要学习的参数,wα为权重矩阵.
然后根据上述αti得到注意力向量αt,具体计算公式如下:
αi=softmax([αt1,αt2,...,αti])(14)
最后根据注意力向量αt和隐藏状态h1到ht-1,计算得到包含上下文注意力信息的向量vt:
预测阶段:结合上下文向量vt和当前隐藏状态ht两个向量的信息,生成一个向量
wc是权重矩阵,注意力向量
ws是权重矩阵,bs是偏移量。
目标函数:计算真实状态yt和预测状态
本发明所述的技术方案从网络结构的角度进行描述具体如下:卷积网络的输入为26x9的矩阵,经过卷积→池化→卷积→池化,卷积核设置为2x9,再经过lstm网络,设置lstm隐藏层特征数为128,输出层为2。网络经过正向传播和反向传播,不断修改、更新各层神经元的参数值以及连接权重。验证集用于确定参数的最佳值,设置迭代次数为100次,设置学习率为0.001,使误差值达到最小,直到满足迭代停止条件,得到训练好的模型。
利用步骤(2)中经过预处理的测试集对模型进行测试,选择准确率(accuracy)作为评价准则,可以验证该模型的预测准确率。
步骤(5)利用训练好的模型进行叶片早期结冰故障检测。
从实际风力场的scada系统中采集待预测数据集,其中包括时间戳、风速、发电机转速、网侧有功功率(kw)、对风角(°)、25秒平均风向角、偏航位置、偏航速度、叶片1角度、叶片2角度、叶片3角度、叶片1速度、叶片2速度、叶片3速度、变桨电机1温度、变桨电机2温度、变桨电机3温度、x方向加速度、y方向加速度、环境温度、机舱温度、ng51温度、ng52温度、ng53温度、ng51充电器直流电流、ng52充电器直流电流、ng53充电器直流电流。
将待预测数据集输入模型,可以通过历史的风机状态信息,预测未来时间段风机是否结冰。
- 还没有人留言评论。精彩留言会获得点赞!