基于多任务学习的低光照行人检测方法及系统与流程
本发明涉及计算机视觉目标检测技术领域,具体涉及一种基于多任务学习的低光照行人检测方法及系统。
背景技术:
经济的快速发展带来了不同地域、不同城市间人员的频繁往来,随之而来的公共安全隐患让相关部门耗费了不少精力。目前,作为城市安全防范系统重要组成部分的视频监控设备己被广泛应用,它们被安装在街道、学校、车站等公共区域中。这些设备主要用来记录和存储相关地点发生的事情,方便人们完成远程监控和应急指挥等需求,保障社会的公共安全。行人是视频监控中的主体,利用智能技术对行人的行为进行研究和分析是智能监控技术的重要组成部分。行人检测就是这一领域的关键技术之一。
另一方面,行人检测还在无人驾驶领域起着非常关键的作用。近年来,随着人工智能的蓬勃发展,无人驾驶车辆的研究得到了重大发展。行人检测是无人驾驶车辆研究的一个重要课题,对于提升车辆感知周围行人的能力有重要影响。
行人检测是目标检测的一个具体应用,从该角度出发,行人检测算法可以分为两类:基于锚框和基于关键点的方法。卷积神经网络(cnn)在rcnn中首次被引入到目标检测中,它可以在不需要手工设计特征的情况下进行检测。基于关键点的目标检测算法通过检测和分组关键点来生成目标边界框。这极大简化了网络的输出,消除了设计锚框的需要。cornernet和cornernet-lite是基于关键点方法的典型代表,他们通过预测目标的左上角和右下角来确定目标边界。
尽管上述行人检测算法在正常照明条件下取得了令人满意的性能,但在实际应用中,正常的照明并不总是有保证的,低光环境非常普遍。低光照环境下行人检测效果差的主要原因是低光照导致输入图像中色彩信息严重丢失,而色彩信息是行人检测的关键。为了解决低光照行人检测问题,目前研究出了红外行人检测,但红外行人检测需要在红外图像下来进行行人检测,不能直接使用原始低光照图像检测。
技术实现要素:
本发明解决的技术问题是提供一种基于多任务学习的低光照行人检测方法及系统,解决低光照环境下行人检测效果差的问题。
为解决上述技术问题,本发明提供一种基于多任务学习的低光照行人检测方法,包括以下步骤:
s1、获取正常光照行人数据集和低光照行人数据集;
s2、构建光照增强网络,光照增强网络包括分解网络和增强网络,利用正常光照行人数据集和低光照行人数据集对光照增强网络进行训练,得到光照增强预训练模型;
s3、构建行人检测网络,行人检测网络以两个沙漏网络为主干网络,并分别加入空间转换网络和挤压激励网络,利用正常光照行人数据集对行人检测网络进行训练,得到行人检测预训练模型;
s4、基于多任务学习,设计一个能够融合不同任务之间特征的多任务学习模块,对光照增强网络和行人检测网络进行特征共享,其中将增强网络的第一个3*3卷积网络的特征和行人检测网络的最后一个空间转换网络的特征进行相加并反馈给两个网络,将增强网络的最后一个3*3卷积网络的特征和行人检测网络的第一个残差模块的特征也进行相加并反馈给两个网络,从而构建多任务特征共享的低光照行人检测网络;
s5、将光照增强预训练模型和行人检测预训练模型导入到多任务特征共享的低光照行人检测网络,并利用正常光照行人数据集和低光照行人数据集对多任务特征共享的低光照行人检测网络进行训练,得到多任务特征共享的低光照行人检测模型;
s6、利用多任务特征共享的低光照行人检测模型对待检测图像进行检测,得到图像中行人的位置。
进一步地,步骤s2中:基于retinexnet卷积神经网络构建光照增强网络。光照增强网络的损失函数为:
lenh=lrecon+λirlir+λislis
式中,λir和λis为权重系数,lrecon,lir和lis分别表示重建,反射率和照明平滑度损失函数。
进一步地,步骤s3中:基于cornernet-saccade构建行人检测网络。行人检测网络的损失函数为:
lcor=ldet+δlpull+ηlpush+γloff
式中,δ,η和γ分别为lpull,lpush和loff三个损失函数的权重,
其中,
式中,ldet为角点损失,n是图像中对象的数量,α和β是控制每个角点的贡献的超参数,c,h和w分别代表输入的通道数,高度和宽度,paij为预测图像中a类的(i,j)位置处的得分,yaij为未经归一化的原始图像;
式中,loff为偏移损失,ok是偏移量,xk和yk是角点k的x和y坐标,n是下采样因子;
式中,lpull用来对角进行分组,lpush对角进行分离,m表示对象个数,
进一步地,多任务特征共享的低光照行人检测网络的总训练损失函数为:
l=ldet+lcor=ldet+δlpull+ηlpush+γloff+ζlenh
式中,l为总损失,ζ是光照增强损失lenh的权重。
本发明还提供一种用于实现上述基于多任务学习的低光照行人检测方法的基于多任务学习的低光照行人检测系统,包括:
数据集模块,用于获取正常光照行人数据集和低光照行人数据集;
光照增强模块,用于构建光照增强网络,光照增强网络包括分解网络和增强网络,利用正常光照行人数据集和低光照行人数据集对光照增强网络进行训练,得到光照增强预训练模型;
行人检测模块,用于构建行人检测网络,行人检测网络以两个沙漏网络为主干网络,并分别加入空间转换网络和挤压激励网络,利用正常光照行人数据集对行人检测网络进行训练,得到行人检测预训练模型;
多任务学习模块,用于对光照增强网络和行人检测网络进行特征共享,将增强网络的第一个3*3卷积网络的特征和行人检测网络的最后一个空间转换网络的特征进行相加并反馈给两个网络,将增强网络的最后一个3*3卷积网络的特征和行人检测网络的第一个残差模块的特征也进行相加并反馈给两个网络,构建多任务特征共享的低光照行人检测网络;
模型训练模块,用于将光照增强预训练模型和行人检测预训练模型导入到多任务特征共享的低光照行人检测网络,并利用正常光照行人数据集和低光照行人数据集对多任务特征共享的低光照行人检测网络进行训练,得到多任务特征共享的低光照行人检测模型;
图像检测模块,用于利用多任务特征共享的低光照行人检测模型对待检测图像进行检测,得到图像中行人的位置。
进一步地,基于retinexnet卷积神经网络构建光照增强网络。
进一步地,基于cornernet-saccade构建行人检测网络。
本发明还提供一种计算机存储介质,其内存储有可被计算机处理器执行的计算机程序,该计算机程序执行上述的基于多任务学习的低光照行人检测方法。
本发明的有益效果是:本发明提供了一种基于多任务学习的低光照行人检测方法及系统,能够准确、高效的在低光照的图像中检测出行人的位置;并且在行人检测网络的主干网络-沙漏网络中加入空间转换网络和挤压激励网络两个模块,提升了网络的空间和通道注意力,从而提升了检测的性能。
附图说明
图1是本发明基于多任务学习的低光照行人检测方法流程图。
图2是本发明基于多任务学习的低光照行人检测网络结构图。
图3是本发明基于多任务学习的低光照行人检测系统示意图。
图4是本发明实施例测试结果比较图。
具体实施方式
下面将结合附图对本发明的基于多任务学习的低光照行人检测方法及系统作进一步的说明:
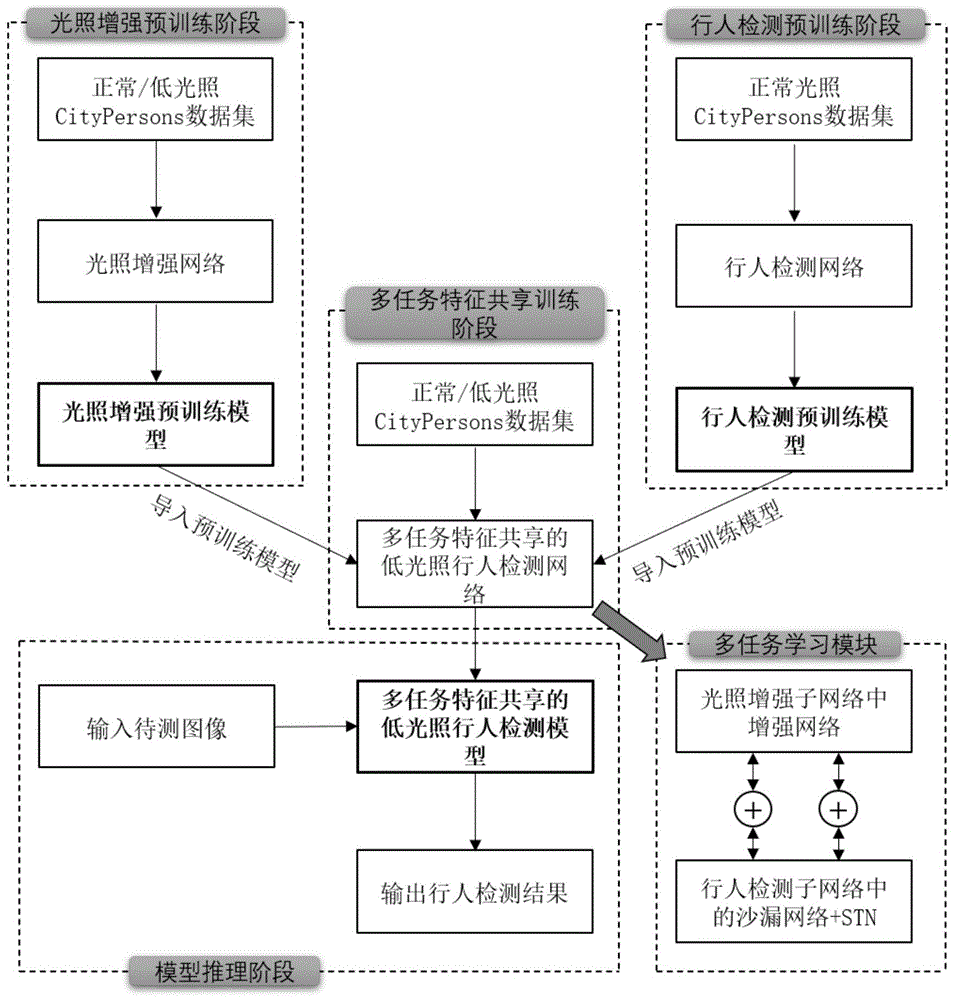
本发明主要分为四个部分:光照增强预训练模型,行人检测预训练模型,多任务特征共享的低光照行人检测模型和多任务特征共享的低光照行人检测模型从低光照图像中推理出图像中行人位置。
本发明实施例的基于多任务学习的低光照行人检测方法,如图1所示,包括以下步骤:
s1、获取正常光照行人数据集和低光照行人数据集。
可以直接通过拍照获取;也可以将citypersons(一个公开的大规模行人检测数据集)行人检测训练集和验证集降低光照,这里我们使用opencv(一个基于bsd许可(开源)发行的跨平台计算机视觉库)中的基于rgb空间亮度调整算法,此算法基于当前rgb值大小进行调整,即r、g、b值越大,调整的越大,例如:当前像素点为(100,200,50),调整系数为1.1,则调整后为(110,220,55)。在本实施例中,我们使用的调整系数为0.8。降低亮度后,我们将正常和低光照citypersons行人检测训练集和验证集作为我们的训练集和测试集。
s2、构建光照增强网络,光照增强网络包括分解网络和增强网络,利用正常光照行人数据集和低光照行人数据集对光照增强网络进行训练,得到光照增强预训练模型。
将正常和低光照行人检测训练集对光照增强网络进行单独训练100个周期,得到光照增强预训练模型。光照增强网络的网络结构如图2所示,基于retinexnet卷积神经网络构建光照增强网络,该网络引入了retinex理论。经典的retinex理论建立了人的颜色感知模型,这个理论假设观察到的图像可以分解为反射通道和照明通道两部分。令s代表源图像,则可以用s=r*i表示,其中r代表反射率分量,i代表照明分量,*代表逐元素乘法。对于损失函数,为了确保恢复光照后的图像能够在保留物体边缘信息的同时,也能保留光照信息的平滑过渡,在光照增强网络中使用了以下损失函数:
lenh=lrecon+λirlir+λislis
其中,λir和λis表示平衡反射率和照明度的系数。损失函数lrecon,lir和lis分别表示重建,反射率和照明平滑度函数。
s3、构建行人检测网络,行人检测网络以两个沙漏网络为主干网络,并分别加入空间转换网络和挤压激励网络,利用正常光照行人数据集对行人检测网络进行训练,得到行人检测预训练模型。
将正常光照的行人检测训练集对行人检测网络进行单独训练100个周期,得到行人检测预训练模型。行人检测网络的网络结构如图2所示,基于cornernet-saccade构建行人检测网络。对于行人检测网络,参考了基于关键点的目标检测算法思想,基于关键点的目标检测算法通过检测和分组其关键点来生成对象边界框,极大地简化了网络的输出,并消除了设计锚框的需要,同时在网络中引入了注意力机制进一步提升检测性能。本专利利用沙漏网络作为行人检测网络的主干网络,并在主干网络-沙漏网络中加入空间转换网络(stn)和挤压激励网络(senet)两个模块来提升网络的空间和通道注意力,提升了检测的性能。其次,我们修剪了沙漏网络的结构,从原来的54层网络降低至36层网络结构,从而大大降低了网络的参数量,网络训练的成本降低。
对于行人检测网络的损失函数,可以使用α=2,β=4的focal损失函数,令paij为预测图像中a类的(i,j)位置处的得分,并令yaij为未经归一化的原始图像。
其中,n是图像中对象的数量,α和β是控制每个点的贡献的超参数。c,h和w分别代表输入的通道数,高度和宽度。
当输入图像通过卷积层时,输出的大小通常小于输入图像。因此,图像中的位置(x,y)映射到热图中的位置
其中,ok是偏移量,xk和yk是角点k的x和y坐标。我们预测一组偏移由所有类别的左上角共享,另一组偏移由右下角共享。为了进行训练,将偏移损失标记为loff,并应用平滑的l1损失作为偏移损失:
图像中可能存在多个对象,因此可以检测到多个左上角和右下角,所以需要确定一对左上角和右下角是否来自同一边界框。令
其中,em是
lcor=ldet+δlpull+ηlpush+γloff,
其中,δ,η和γ分别是lpull,lpush和loff三个损失函数的权重,lcor是行人检测网络总损失。
s4、基于多任务学习,设计一个能够融合不同任务之间特征的多任务学习模块,对光照增强网络和行人检测网络进行特征共享,将增强网络的第一个3*3卷积网络的特征和行人检测网络的最后一个空间转换网络的特征进行相加并反馈给两个网络,将增强网络的最后一个3*3卷积网络的特征和行人检测网络的第一个残差模块的特征也进行相加并反馈给两个网络,构建多任务特征共享的低光照行人检测网络。
多任务特征共享的低光照行人检测网络包含:光照增强网络和行人检测网络,为了使两个网络的性能进一步提升,在这基础上引入一个多任务学习模块,多任务学习模块的详细结构如图2所示。其中,分别将增强网络的特征a1和a2与沙漏网络+stn模块中的特征b1和b2进行加的操作,并把两个相加后的特征标记为f1和f2,并反馈给两网络。特征a1和a2分别来自增强网络中的第一个3*3卷积层和最后一个3*3卷积层。特征b1来自沙漏网络+stn中的最后一个stn模块,特征b2则来自第一个残差模块。同时,这些特征的大小相同。f1和f2表示为:
f1=a1+b1,f2=a2+b2.
最后,多任务特征共享的低光照行人检测网络的训练损失函数l如下:
l=ldet+δlpull+ηlpush+γloff+ζlenh,
其中δ,η和γ分别是lpull,lpush和loff三个损失函数的权重。ζ是光照增强损失lenh的权重。我们将δ和η设置为0.1,将γ设置为1,将ζ设置为0.05。
s5、将光照增强预训练模型和行人检测预训练模型导入到多任务特征共享的低光照行人检测网络,并利用正常光照行人数据集和低光照行人数据集对多任务特征共享的低光照行人检测网络进行训练,得到多任务特征共享的低光照行人检测模型。
将正常和低光照行人检测训练集对多任务特征共享的低光照行人检测网络进行训练,同时导入之前训练好的光照增强预训练模型和行人检测预训练模型,训练100个周期,得到多任务特征共享的低光照行人检测模型。
s6、利用多任务特征共享的低光照行人检测模型对待检测图像进行检测,得到图像中行人的位置。将低光照的测试集图片输入到训练好的多任务特征共享的低光照行人检测模型进行推理,并在图像中框出行人的位置。
本发明还提供一种用于实现上述基于多任务学习的低光照行人检测方法的基于多任务学习的低光照行人检测系统,如图3所示,包括:
数据集模块101,用于获取正常光照行人数据集和低光照行人数据集;
光照增强模块102,用于构建光照增强网络,光照增强网络包括分解网络和增强网络,利用正常光照行人数据集和低光照行人数据集对光照增强网络进行训练,得到光照增强预训练模型;
行人检测模块103,用于构建行人检测网络,行人检测网络以两个沙漏网络为主干网络,并分别加入空间转换网络和挤压激励网络,利用正常光照行人数据集对行人检测网络进行训练,得到行人检测预训练模型;
多任务学习模块104,用于对不同任务之间的特征进行融合,对光照增强网络和行人检测网络进行特征共享,将增强网络的第一个3*3卷积网络的特征和行人检测网络的最后一个空间转换网络的特征进行相加并反馈给两个网络,将增强网络的最后一个3*3卷积网络的特征和行人检测网络的第一个残差模块的特征也进行相加并反馈给两个网络,构建多任务特征共享的低光照行人检测网络;
模型训练模块105,用于将光照增强预训练模型和行人检测预训练模型导入到多任务特征共享的低光照行人检测网络,并利用正常光照行人数据集和低光照行人数据集对多任务特征共享的低光照行人检测网络进行训练,得到多任务特征共享的低光照行人检测模型;
图像检测模块106,用于利用多任务特征共享的低光照行人检测模型对待检测图像进行检测,得到图像中行人的位置。
进一步地,基于retinexnet卷积神经网络构建光照增强网络;基于cornernet-saccade构建行人检测网络。
本发明还提供一种计算机存储介质,其内存储有可被计算机处理器执行的计算机程序,该计算机程序执行上述的基于多任务学习的低光照行人检测方法。
本发明最后提供一个测试实施例,采用正常和低光照citypersons数据集,包括正常和低光照训练集各2975张图片,正常和低光照测试集各500张图片。实验在pytorch中实现,并使用2张rtx2080ti显卡进行训练,同时应用adam优化算法。实验参数的选择上,设置的学习率为0.0001。评估指标遵循加州理工学院的评估标准:每幅图像的对数平均未命中率(mr-2),mr-2的值越低,表示算法性能越好。通过mr-2评价指标,与其他优秀的行人检测算法进行对比来证明本发明的优越性。表1通过mr-2评价指标展示了对比的结果,图4为行人位置检测结果对比图。
选择作为对比的行人检测方法包括:csp、alfnet和cornernet-saccade。alfnet是行人检测中最具代表性的基于锚框的算法,csp是行人检测中使用中心点法的最佳算法。同时,cornernet-saccade是目标检测中基于关键点方法的最佳算法。在csp中提出了两种不同的模型,一种是考虑偏移量的cspoff模型,另一种是不考虑偏移量的cspnooff模型。表1中的前四行算法均将正常和低光照训练集对算法进行训练,因此所有这些行人检测网络都具有处理低光照图像的能力,保证了实验的公平。此外,为了进一步说明本专利算法中多任务学习模块的作用,表1中第五行算法采用级联的方式将retinexnet光照增强算法和cornernet-saccade检测算法级联在一起。可以从表中结果可知,级联方法的指标仍然没有优于本发明的算法,证明了多任务学习模块起到了很重要的作用。
表1本发明与五种优秀算法比较结果表
从以上表格实验结果可以看出,本算法与其他五种方法相比,取得了很明显的优势。
说明书中未阐述的部分均为现有技术或公知常识。本实施例仅用于说明该发明,而不用于限制本发明的范围,本领域技术人员对于本发明所做的等价置换等修改均认为是落入该发明权利要求书所保护范围内。
本领域的技术人员容易理解,以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!