千人千面门户的智能推荐方法及系统与流程
[0001]
本发明涉及智能推荐技术领域,尤其涉及一种基于机器学习及协同过滤的千人千面门户的智能推荐方法及系统。
背景技术:
[0002]
警务工作门户是大数据平台的综合型门户,也是民警登录大数据平台的入口,更是大数据平台建设完成之后主要的成果展示入口;大数据平台获取了大量业务系统资源数据和用户行为数据,用户对大数据平台的使用,使两类数据之间发生了关联;在大数据研究领域中,用户行为分析是较为关注的一个热点,但很少应用在门户系统中;如能将资源数据与用户行为数据进行融合,用于对用户行为的分析预测,并通过门户系统表现出来,则将能更好地满足用户个性化需求,实现知识与信息的共享。
技术实现要素:
[0003]
本发明的目的在于克服现有技术的不足,本发明提供了一种基于机器学习及协同过滤的千人千面门户的智能推荐方法,对用户数据进行分析预测,实现个性化服务,以满足用户的个性化需求,并实现知识的分享和创造。
[0004]
为了解决上述技术问题,本发明实施例提供了一种基于机器学习及协同过滤的千人千面门户的智能推荐方法,所述方法包括:
[0005]
基于用户的pki/pmi信息、权限信息、访问日志和关注信息获得用户数据;
[0006]
基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析,获取用户数据与平台资源数据的关联度信息;
[0007]
基于协同过滤算法对用户数据与平台资源数据的关联度信息进行过滤分析,获得过滤分析后的关联度信息;
[0008]
基于所述过滤分析后的关联度信息获取待推荐信息,将所述待推荐信息进行排序并向用户推荐。
[0009]
可选的,所述用户数据包括:用户存储信息、用户关注信息、用户导入数据、用户调查分析数据、用户统计分析数据、用户月度及年度评分数据、用户档案信息数据和用户输入记录信息数据。
[0010]
可选的,基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析之前,包括:
[0011]
基于机器学习对所述用户数据进行学习,并根据机器学习的学习结果实时调整、更新和修正nlp算法模型。
[0012]
可选的,所述基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析,获取用户数据与平台资源数据的关联度信息,包括:
[0013]
基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据依次进行文本分词、数据对比、关系抽取、相似性检索和调整匹配处理,获取用户数据与平台资源数据的
关联度信息。
[0014]
可选的,所述基于协同过滤算法对用户数据与平台资源数据的关联度信息进行过滤分析,获得过滤分析后的关联度信息,包括:
[0015]
基于所述协同过滤算法采用用户自定义推荐标准和算法控制标准剔除用户数据与平台资源数据的关联度信息中用户随机行为数据,获得过滤分析后的关联度信息。
[0016]
可选的,所述基于所述过滤分析后的关联度信息获取待推荐信息,包括:
[0017]
基于所述过滤分析后的关联度信息获得与用户行为偏好相近的相似用户的偏好信息作为待推荐信息;和/或,
[0018]
基于所述过滤分析后的关联度信息计算用户关注事项和历史事项相似度,获得相似性事项信息作为待推荐信息。
[0019]
可选的,所述将所述待推荐信息进行排序并向用户推荐,包括:
[0020]
获取所述待推荐信息,并识别所述待推荐信息为偏好信息和/或相似性事项信息;
[0021]
基于所述偏好信息和/或相似性事项信息分别进行排序,获取排序结果;
[0022]
按照排序结果向用户进行智能推荐。
[0023]
另外,本发明实施例还提供了一种基于机器学习及协同过滤的千人千面门户的智能推荐系统,所述系统包括:
[0024]
用户数据获取模块:用于基于用户的pki/pmi信息、权限信息、访问日志和关注信息获得用户数据;
[0025]
数据关联度分析模块:用于基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析,获取用户数据与平台资源数据的关联度信息;
[0026]
协同过滤模块:用于基于协同过滤算法对用户数据与平台资源数据的关联度信息进行过滤分析,获得过滤分析后的关联度信息;
[0027]
排序推荐模块:用于基于所述过滤分析后的关联度信息获取待推荐信息,将所述待推荐信息进行排序并向用户推荐。
[0028]
可选的,所述协同过滤模块:还用于基于所述协同过滤算法采用用户自定义推荐标准和算法控制标准剔除用户数据与平台资源数据的关联度信息中用户随机行为数据,获得过滤分析后的关联度信息。
[0029]
可选的,所述排序推荐模块包括:
[0030]
待推荐信息获取单元:用于基于所述过滤分析后的关联度信息获得与用户行为偏好相近的相似用户的偏好信息作为待推荐信息;和/或,基于所述过滤分析后的关联度信息计算用户关注事项和历史事项相似度,获得相似性事项信息作为待推荐信息;
[0031]
识别单元:用于获取所述待推荐信息,并识别所述待推荐信息为偏好信息和/或相似性事项信息;
[0032]
排序单元:用于基于所述偏好信息和/或相似性事项信息分别进行排序,获取排序结果;
[0033]
推荐单元:用于按照排序结果向用户进行智能推荐。
[0034]
在本发明实施中,通过采用机器学习更新的nlp算法模型以及协同过滤算法对用户行为数据进行分析预测,并调用相应模块实现个性化服务,突出大数据的服务与应用功能,以满足用户的个性化需求,并实现知识的分享和创造。
附图说明
[0035]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见的,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
[0036]
图1是本发明实施例中的千人千面门户系统的结构组成示意图;
[0037]
图2是本发明实施例中的千人千面门户的智能推荐方法的流程示意图;
[0038]
图3是本发明实施例中的千人千面门户的智能推荐系统的结构组成示意图。
具体实施方式
[0039]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0040]
实施例
[0041]
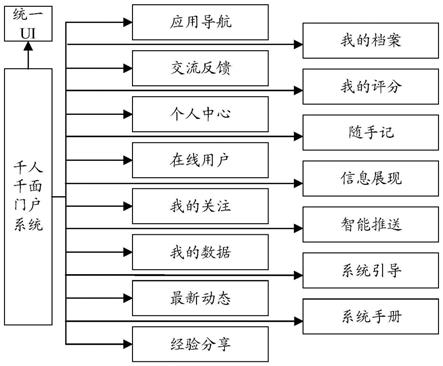
请参阅图1,图1是本发明实施例中的千人千面门户系统的结构组成示意图。
[0042]
如图1所示,千人千面门户系统包括:统一ui、应用导航、交流反馈、个人中心、在线用户、我的关注、我的数据、最新动态、经验分享、我的档案、我的评分、随手记、信息展现、智能推送、系统引导和系统手册十六部分组成;其中,
[0043]
统一ui主用于实现所涉及的大数据、数据治理、数据应用和各业务应用的统一登录和逻辑集成,通过制定统一ui,以便在用户看来可到达整齐划一,视觉兼容的效果,而不是错综复杂,分门别类。
[0044]
应用导航用于提供常用应用集中展示、推广、交流的入口;包括自主添加常用应用、按应用分类进行检索、应用评价打分功能。
[0045]
交流反馈主要是提供留言发布、问题反馈等功能,授权身份与数字证书绑定的用户在平台上发布应用功能使用经验和问题答疑等。
[0046]
个人中心用于系统提供一个保存信息的个人空间。个人中心中会显示修改用户信息的选项,同时用户可以在本界面内看到自己以前的操作记录,可以对以前中断的工作继续进行。
[0047]
在线用户用于查看目前在系统内的用户,支持通过角色的方式进行查看,支持按照用户名方式进行检索。
[0048]
我的关注用于基于基层民警用户主动获取关注信息需求,提供关注服务,通过信息关注,信息获取由被动型服务向主动型发生转变,结合信息推送方式的动态性、时效性,可以将变化的信息方便及时地推送给个人用户,并将有变化的结果通过短信、终端、系统消息提醒(系统消息需同短信平台、终端实现对接)等多种形式推送给关注人,并在“我的关注”中进行集中展现。
[0049]
我的数据用于集中展示我的数据,包括我的导入数据、调查分析结果数据、统计分析数据和基于app采集的数据等。数据列表支持列表维护(包括增加计算字段、修改现有字段等)、二维分析(包括饼图、棒图和区域地图分析等)、交叉分析等功能;同时支持对导入数
据和贡献程度进行积分。
[0050]
最新动态用于实现系统更新的相关提醒,提醒内容可以以消息框的方式展现,也可以在系统顶部滚动显示。
[0051]
经验分享用于各业务警种可以根据自己使用的大数据分析研判、人员管控、模型制作和侦察破案的it实战经验进行分享,一是可以帮助别的民警更加深刻的理解如何使用大数据平台,二是可以通过经验分享获取积分;支持图片分享、文档分享和文章发布分享,支持点赞、评分和回复评论等操作。
[0052]
我的档案用于依据用户权限,综合展示个人的档案信息,包括基础信息、工作履历信息、系统使用情况信息等;严格按照用户权限控制民警档案数据的查看,保障民警信息安全。同时,在民警档案浏览窗口中,针对不同的用户角色提供相应的档案信息维护功能,如民警可以新增工作履历、查看个人工作履历、修改基础信息等,评分专家可以进行履行评分。
[0053]
我的评分用于通过对案件侦破、绩效管控和其它指标获取的民警的年度、当月积分、消费积分,可进行展示,也可进一步获取个人评分明细信息、履历详情信息,帮助用户对民警评分情况进行深入了解。
[0054]
随手记用于在系统的主要界面中提供悬浮小图标,通过点击图标打开随手记功能,支持文字录入、文字编辑等功能。并且支持随手记的文件管理、内容检索、资源入库和文本信息的结构化处理,满足民警在使用系统的过程中需要随时记录相关信息。
[0055]
信息展现用于依据用户权限和关注信息不同,将不同用户关注的信息在门户上分门别类的展现,如派出所民警关注本辖区内的案件、数量,则在派出所民警的门户上以图表或表格的方式展现案件、数量,如治安警种关注治安的相关信息则在门户上展现治安的相关信息;如科信的用户关注的是运维方面的内容,则通过读取数据监测数据和服务监测数据,并以可视化的方式展现数据源是否正常、数据整合是否正常和数据服务访问是否正常,并通过调用的方式获取异常原因,备用方案等。
[0056]
智能推送用于依托pki/pmi信息、权限信息、访问日志和关注信息,同时基于机器学习、nlp技术和协同过滤等算法,实现基于用户画像的偏好、案件相关度和其它信息相关度进行信息智能推送。
[0057]
系统引导包括引导说明、智能推荐和知识分享,用于方便用户在使用系统的时候能更加快速和更加智能的使用系统。
[0058]
系统手册用于通过该功能可下载最新的用户手册,供用户熟悉和了解系统信息。
[0059]
请参阅图2,图2是本发明实施例中的千人千面门户的智能推荐方法的流程示意图。
[0060]
请参阅图2,如图2所示,一种基于机器学习及协同过滤的千人千面门户的智能推荐方法,所述方法包括:
[0061]
s11:基于用户的pki/pmi信息、权限信息、访问日志和关注信息获得用户数据;
[0062]
在本发明具体实施过程中,所述用户数据包括:用户存储信息、用户关注信息、用户导入数据、用户调查分析数据、用户统计分析数据、用户月度及年度评分数据、用户档案信息数据和用户输入记录信息数据。
[0063]
在具体实施过程中,用户数据主要从千人千面门户系统中的个人中心、我的关注、
我的数据、我的评分、我的档案和随手记中获得,其中,个人中心是千人千面门户系统为用户专门提供的一个可以保持个人信息的个人存储空间;个人中心中将存储有用户存储信息;当用户修改个人存储信息时个人中心会显示修改用户的信息的选项,同时用户可以在个人中心界面上看到自己以前的修改操作记录,也可以对以前中断的修改操作进行修改;我的关注用于基层民警用户主动获取关注需求的用户关注信息,提供关注服务,通过信息关注,信息获取由被动型服务向主动型发生转变,结合信息推送方式的动态性、时效性,可以将变化的信息方便及时地推送给个人用户,并将有变化的结果通过短信、终端、系统消息提醒(系统消息需同短信平台、终端实现对接)等多种形式推送给关注人,并在“我的关注”中进行集中展现;我的数据中包括了用户导入的用户导入数据、用户调查分析数据、用户统计分析数据以及基于app采集的数据等,这些数据中,支持列表维护(包括增加计算字段、修改现有字段等)、二维分析(包括饼图、棒图和区域地图分析等)、交叉分析等功能;同时支持对导入数据和贡献程度进行积分;我的评分包括用户通过对案件侦破、绩效管控和其它指标获得的用户月度及年度评分数据,可进行展示,也可进一步获取个人评分明细信息、履历详情信息,帮助用户对民警评分情况进行深入了解;我的档案主要是依据用户的权限,综合展示用户个人的用户档案信息数据,其中,用户档案信息数据包括基础信息、工作履历信息、系统使用情况信息等;严格按照用户权限控制民警档案数据的查看,保障民警信息安全;同时,在民警档案浏览窗口中,针对不同的用户角色提供相应的档案信息维护功能,如民警可以新增工作履历、查看个人工作履历、修改基础信息等,评分专家可以进行履行评分。
[0064]
s12:基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析,获取用户数据与平台资源数据的关联度信息;
[0065]
在本发明具体实施过程中,基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析之前,包括:基于机器学习对所述用户数据进行学习,并根据机器学习的学习结果实时调整、更新和修正nlp算法模型。
[0066]
进一步的,所述基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析,获取用户数据与平台资源数据的关联度信息,包括:基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据依次进行文本分词、数据对比、关系抽取、相似性检索和调整匹配处理,获取用户数据与平台资源数据的关联度信息。
[0067]
具体的,机器学习(machine learning,ml)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能;它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
[0068]
通过机器学习对用户的数据进行学习,并且在学习之后,根据学习的结果实时调整、更新和修正nlp算法模型,使得nlp算法模型越来越具有针对性,即,对于每一个用户,使得nlp算法模型均有一定的差异性。
[0069]
在nlp算法模型更新之后,利用更新后的nlp算法模型对对应的用户数据与千人千面门户的平台资源数据之间依次进行文本分词、数据比对、关系抽取、相似性检索和调整匹配处理,然后综合上述每一个处理的流程,按照线性加权的方式获得用户数据与平台资源
数据的关联度信息;其中线性加权的权值,可以根据用户的权限而设置,具体每个权值可以为0.2,总权重之和为1即可。
[0070]
s13:基于协同过滤算法对用户数据与平台资源数据的关联度信息进行过滤分析,获得过滤分析后的关联度信息;
[0071]
在本发明具体实施过程中,所述基于协同过滤算法对用户数据与平台资源数据的关联度信息进行过滤分析,获得过滤分析后的关联度信息,包括:基于所述协同过滤算法采用用户自定义推荐标准和算法控制标准剔除用户数据与平台资源数据的关联度信息中用户随机行为数据,获得过滤分析后的关联度信息。
[0072]
具体的,协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
[0073]
采用协同过滤算法具有一下好处:能够过滤机器难以自动内容分析的信息,如艺术品,音乐等;共用其他人的经验,避免了内容分析的不完全或不精确,并且能够基于一些复杂的,难以表述的概念(如信息质量、个人品味)进行过滤;有推荐新信息的能力;可以发现内容上完全不相似的信息,用户对推荐信息的内容事先是预料不到的;可以发现用户潜在的但自己尚未发现的兴趣偏好;推荐个性化、自动化程度高、能够有效的利用其他相似用户的回馈信息、加快个性化学习的速度。
[0074]
在本实施例中,该协同过滤算法采用了用户自定义推荐标准和算法控制两种方式进行协同过滤,这样子可有有效的过滤用户的随机行为,找到行为偏好相近的用户并将其偏好的操作行为推送向用户,或是计算用户关注事项和历史事项的相似度,向用户推荐相似度最近的几个事项。
[0075]
s14:基于所述过滤分析后的关联度信息获取待推荐信息,将所述待推荐信息进行排序并向用户推荐。
[0076]
在本发明具体实施过程中,所述基于所述过滤分析后的关联度信息获取待推荐信息,包括:基于所述过滤分析后的关联度信息获得与用户行为偏好相近的相似用户的偏好信息作为待推荐信息;和/或,基于所述过滤分析后的关联度信息计算用户关注事项和历史事项相似度,获得相似性事项信息作为待推荐信息。
[0077]
进一步的,所述将所述待推荐信息进行排序并向用户推荐,包括:获取所述待推荐信息,并识别所述待推荐信息为偏好信息和/或相似性事项信息;基于所述偏好信息和/或相似性事项信息分别进行排序,获取排序结果;按照排序结果向用户进行智能推荐。
[0078]
具体的,在采用协同过滤算法对剔除用户数据与平台资源数据的关联度信息中用户随机行为数据之后,获得的滤分析后的关联度信息包含了用户行为偏好相近的相似用户的偏好信息和用户关注事项和历史事项相似度信息;因此即可根据过滤分析后的关联度信息获得来分别获得与用户行为偏好相近的相似用户的偏好信息作为待推荐信息;和/或,计算用户关注事项和历史事项相似度,获得相似性事项信息作为待推荐信息。
[0079]
在获得待推荐信息之后,首先需要识别该待推荐信息属于偏好信息和/ 或相似性事项信息;然后根据所述的信息分类(偏好信息火折子相似性信息)进行分类,然后在每一类上再进行相应的排序,该排序可以采用顺序排序、倒叙排序、字体大小排序或颜色深浅排
序等排序方式;在排序之后,选取排序靠前的排序结果向用户进行智能推荐。
[0080]
在本发明实施中,通过采用机器学习更新的nlp算法模型以及协同过滤算法对用户行为数据进行分析预测,并调用相应模块实现个性化服务,突出大数据的服务与应用功能,以满足用户的个性化需求,并实现知识的分享和创造。
[0081]
实施例
[0082]
请参阅图3,图3是本发明实施例中的千人千面门户的智能推荐系统的结构组成示意图。
[0083]
如图3所示,一种基于机器学习及协同过滤的千人千面门户的智能推荐系统,所述系统包括:
[0084]
用户数据获取模块11:用于基于用户的pki/pmi信息、权限信息、访问日志和关注信息获得用户数据;
[0085]
在本发明具体实施过程中,所述用户数据包括:用户存储信息、用户关注信息、用户导入数据、用户调查分析数据、用户统计分析数据、用户月度及年度评分数据、用户档案信息数据和用户输入记录信息数据。
[0086]
在具体实施过程中,用户数据主要从千人千面门户系统中的个人中心、我的关注、我的数据、我的评分、我的档案和随手记中获得,其中,个人中心是千人千面门户系统为用户专门提供的一个可以保持个人信息的个人存储空间;个人中心中将存储有用户存储信息;当用户修改个人存储信息时个人中心会显示修改用户的信息的选项,同时用户可以在个人中心界面上看到自己以前的修改操作记录,也可以对以前中断的修改操作进行修改;我的关注用于基层民警用户主动获取关注需求的用户关注信息,提供关注服务,通过信息关注,信息获取由被动型服务向主动型发生转变,结合信息推送方式的动态性、时效性,可以将变化的信息方便及时地推送给个人用户,并将有变化的结果通过短信、终端、系统消息提醒(系统消息需同短信平台、终端实现对接)等多种形式推送给关注人,并在“我的关注”中进行集中展现;我的数据中包括了用户导入的用户导入数据、用户调查分析数据、用户统计分析数据以及基于app采集的数据等,这些数据中,支持列表维护(包括增加计算字段、修改现有字段等)、二维分析(包括饼图、棒图和区域地图分析等)、交叉分析等功能;同时支持对导入数据和贡献程度进行积分;我的评分包括用户通过对案件侦破、绩效管控和其它指标获得的用户月度及年度评分数据,可进行展示,也可进一步获取个人评分明细信息、履历详情信息,帮助用户对民警评分情况进行深入了解;我的档案主要是依据用户的权限,综合展示用户个人的用户档案信息数据,其中,用户档案信息数据包括基础信息、工作履历信息、系统使用情况信息等;严格按照用户权限控制民警档案数据的查看,保障民警信息安全;同时,在民警档案浏览窗口中,针对不同的用户角色提供相应的档案信息维护功能,如民警可以新增工作履历、查看个人工作履历、修改基础信息等,评分专家可以进行履行评分。
[0087]
数据关联度分析模块12:用于基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析,获取用户数据与平台资源数据的关联度信息;
[0088]
在本发明具体实施过程中,基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析之前,包括:基于机器学习对所述用户数据进行学习,并根据机器学习的学习结果实时调整、更新和修正nlp算法模型。
[0089]
进一步的,所述基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据进行数据关联度分析,获取用户数据与平台资源数据的关联度信息,包括:基于nlp算法模型对所述用户数据与千人千面门户的平台资源数据依次进行文本分词、数据对比、关系抽取、相似性检索和调整匹配处理,获取用户数据与平台资源数据的关联度信息。
[0090]
具体的,机器学习(machine learning,ml)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能;它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
[0091]
通过机器学习对用户的数据进行学习,并且在学习之后,根据学习的结果实时调整、更新和修正nlp算法模型,使得nlp算法模型越来越具有针对性,即,对于每一个用户,使得nlp算法模型均有一定的差异性。
[0092]
在nlp算法模型更新之后,利用更新后的nlp算法模型对对应的用户数据与千人千面门户的平台资源数据之间依次进行文本分词、数据比对、关系抽取、相似性检索和调整匹配处理,然后综合上述每一个处理的流程,按照线性加权的方式获得用户数据与平台资源数据的关联度信息;其中线性加权的权值,可以根据用户的权限而设置,具体每个权值可以为0.2,总权重之和为1即可。
[0093]
协同过滤模块13:用于基于协同过滤算法对用户数据与平台资源数据的关联度信息进行过滤分析,获得过滤分析后的关联度信息;
[0094]
在本发明具体实施过程中,所述协同过滤模块13:还用于基于所述协同过滤算法采用用户自定义推荐标准和算法控制标准剔除用户数据与平台资源数据的关联度信息中用户随机行为数据,获得过滤分析后的关联度信息。
[0095]
具体的,协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
[0096]
采用协同过滤算法具有一下好处:能够过滤机器难以自动内容分析的信息,如艺术品,音乐等;共用其他人的经验,避免了内容分析的不完全或不精确,并且能够基于一些复杂的,难以表述的概念(如信息质量、个人品味)进行过滤;有推荐新信息的能力;可以发现内容上完全不相似的信息,用户对推荐信息的内容事先是预料不到的;可以发现用户潜在的但自己尚未发现的兴趣偏好;推荐个性化、自动化程度高、能够有效的利用其他相似用户的回馈信息、加快个性化学习的速度。
[0097]
在本实施例中,该协同过滤算法采用了用户自定义推荐标准和算法控制两种方式进行协同过滤,这样子可有有效的过滤用户的随机行为,找到行为偏好相近的用户并将其偏好的操作行为推送向用户,或是计算用户关注事项和历史事项的相似度,向用户推荐相似度最近的几个事项。
[0098]
排序推荐模块14:用于基于所述过滤分析后的关联度信息获取待推荐信息,将所述待推荐信息进行排序并向用户推荐。
[0099]
在本发明具体实施过程中,所述排序推荐模块14包括:待推荐信息获取单元:用于
基于所述过滤分析后的关联度信息获得与用户行为偏好相近的相似用户的偏好信息作为待推荐信息;和/或,基于所述过滤分析后的关联度信息计算用户关注事项和历史事项相似度,获得相似性事项信息作为待推荐信息;识别单元:用于获取所述待推荐信息,并识别所述待推荐信息为偏好信息和/或相似性事项信息;排序单元:用于基于所述偏好信息和/ 或相似性事项信息分别进行排序,获取排序结果;推荐单元:用于按照排序结果向用户进行智能推荐。
[0100]
具体的,在采用协同过滤算法对剔除用户数据与平台资源数据的关联度信息中用户随机行为数据之后,获得的滤分析后的关联度信息包含了用户行为偏好相近的相似用户的偏好信息和用户关注事项和历史事项相似度信息;因此即可根据过滤分析后的关联度信息获得来分别获得与用户行为偏好相近的相似用户的偏好信息作为待推荐信息;和/或,计算用户关注事项和历史事项相似度,获得相似性事项信息作为待推荐信息。
[0101]
在获得待推荐信息之后,首先需要识别该待推荐信息属于偏好信息和/ 或相似性事项信息;然后根据所述的信息分类(偏好信息火折子相似性信息)进行分类,然后在每一类上再进行相应的排序,该排序可以采用顺序排序、倒叙排序、字体大小排序或颜色深浅排序等排序方式;在排序之后,选取排序靠前的排序结果向用户进行智能推荐。
[0102]
在本发明实施中,通过采用机器学习更新的nlp算法模型以及协同过滤算法对用户行为数据进行分析预测,并调用相应模块实现个性化服务,突出大数据的服务与应用功能,以满足用户的个性化需求,并实现知识的分享和创造。
[0103]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,random access memory)、磁盘或光盘等。
[0104]
另外,以上对本发明实施例所提供的一种基于机器学习及协同过滤的千人千面门户的智能推荐方法及系统进行了详细介绍,本文中应采用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1