一种基于快速核独立成分分析的精馏塔故障检测方法与流程
本发明涉及一种化工过程运行状态监测方法,特别涉及一种基于快速核独立成分分析的精馏塔故障检测方法。
背景技术:
由于计算机技术与先进测量仪表技术广泛应用于化工生产,化工生产过程中的温度,压力,流量等数据信息可以被实时测量并存储起来,这些海量样本数据为当前化工智能系统的设计提供了坚实的数据基础。近十几年来,利用采样数据来检测化工过程运行中出现的异常状态在安全化工生产领域受到了越来越多的重视。经过十几年的发展,化工过程异常状态监测已经建立起了一套以主成分分析(principalcomponentanalysis,缩写:pca)与独立成分分析(independentcomponentanalysis,缩写:ica)等多变量分析算法为基础的数据驱动故障检测方法。这些数据驱动的方法技术的核心本质在于对采样数据进行潜在特征的挖掘。换句话说,所建立的数据驱动模型都是旨在提取采样数据数据中潜藏的特征。
精馏塔设备是石油化工生产中应用极为广泛的一种传质传热装置,其主要作用是实现对物质的分离目的。因此,实时监测精馏塔设备是否出现故障对于整个化工生产具有重要的意义。精馏塔中各层塔板的温度,回流流量等数据信息都可以反应出精馏塔设备是否工作在正常工况上。考虑到精馏塔设备采样数据之间的非线性特征,可使用基于核pca(kernelpca,缩写:kpca)模型或核ica(kernelica,缩写:kica)模型的故障检测方法。相比于kpca方法,kica在非线性的基础上更进一步的考虑到了数据变化的非高斯性,能够同时提取非线性非高斯的特征用于故障检测。此外,现有专利与科研文献中皆发现,在数据高斯分布情况下,kica方法其实就退化成了kpca。因此,kpca实际上是kica方法的一种特例。换句话说,使用kica对精馏塔实施运行状态的故障检测通常能取得更优越于使用pca方法所能取得的故障检测效果。
值得注意的是,数据驱动的方法技术有一个共同特点,就是训练数据越多越好。但是,训练数据越多,却给使用核学习技巧的kica方法带来了在线计算的压力。这主要是因为kica方法完成离线建模后,再对新采样数据实施特征变换时,其在线的计算量是和离线建模阶段所用数据量直接成正比例关系的。简单来说,离线所有训练数据越多,在线计算量越大。因此,如何降低kica方法的在线计算量,从而实现快速kica是一个很值得关注的问题,尤其是在采样间隔很短的精馏塔运行状态的故障检测上。
技术实现要素:
本发明所要解决的主要技术问题是:如何在基本不影响kica的故障检测效果的前提下,降低使用kica方法实施故障检测时的在线计算量。具体来讲,本发明方法通过样本选择的方式从大量的训练样本数据中构造出合适的样本数据来建立kica模型,从而使在线的计算量得到大幅度的降低。此外,在利用基于距离的监测指标进行故障检测时,本发明方法没有完全抛弃未被选中的训练样本。从而起到了既降低在线计算量,又充分利用所有样本数据的作用。
本发明方法解决上述问题所采用的技术方案为:一种基于快速核独立成分分析的精馏塔故障检测方法,包括以下步骤:
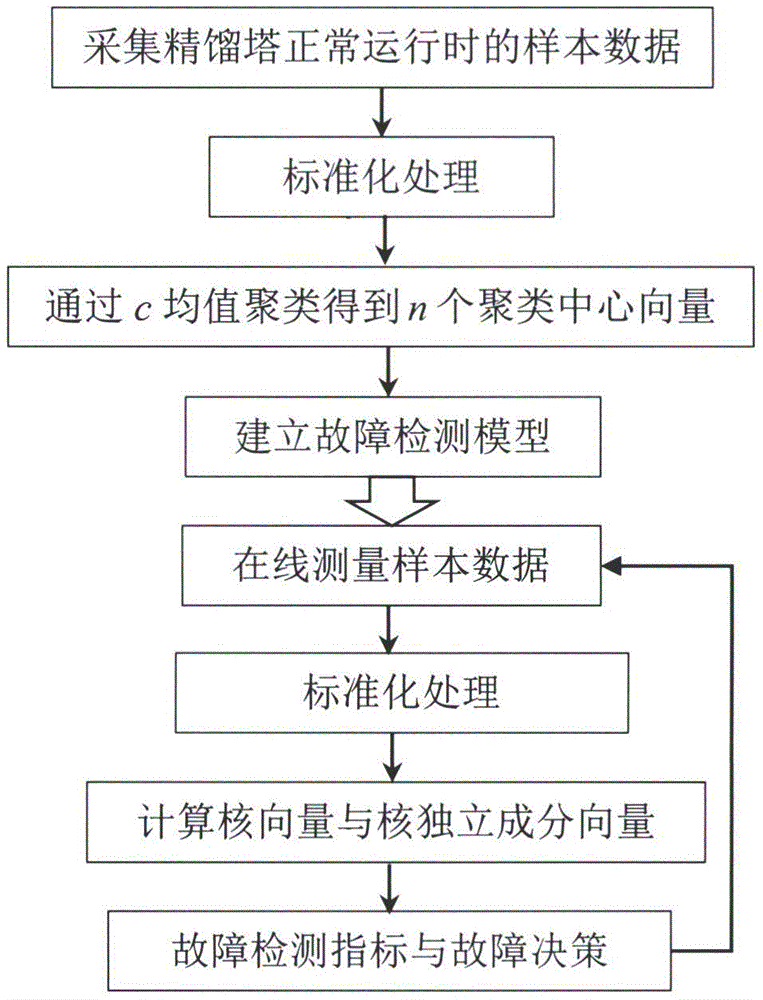
步骤(1):利用精馏塔设备所安装的测量仪表,在精馏塔正常运行状态时采集n个样本数据x1,x2,…,xn,其中第i个采样时刻的样本数据xi∈rm×1由m个采样数据组成,具体包括:塔釜液位、塔釜压力,塔釜底部产品流量,进料流量,进料温度,顶部回流流量,冷凝器液位,和各层塔板的温度,i∈{1,2,…,n}。
步骤(2):对n个样本数据x1,x2,…,xn实施标准化处理,得到n个m×1维的数据向量
步骤(3):对n个数据向量
步骤(3.1):初始化k=0,j=0,和c=m。
步骤(3.2):根据c均值聚类算法对n个数据向量
步骤(3.3):判断是否满足条件j<ε;若是,则设置c=c+5后,返回步骤(3.2);若否,则得到n个聚类中心向量z1,z2,…,zn;其中,n=ε×c+(ε-1)×5,ε表示c均值聚类算法的执行次数。
步骤(4):利用z1,z2,…,zn建立基于核独立成分分析的故障检测模型,具体的实施过程包括步骤(4.1)至步骤(4.13)。
步骤(4.1):根据如下所示公式计算核矩阵k∈rn×n中第a行第b列的元素k(a,b):
其中,δ为核参数,通常可取δ=100m,a∈{1,2,…,n},b∈{1,2,…,n},rn×n表示n×n维的实数矩阵,||za-zb||2=(za-zb)t(za-zb),上标号t表示矩阵或向量的转置。
步骤(4.2):根据如下所示公式对核矩阵k进行中心化处理得到矩阵
其中,矩阵iin∈rn×n中全部元素都是1。
步骤(4.3):求解矩阵
步骤(4.4):根据公式γd=λd/(λ1+λ2+…+λn)计算特征值比例γ1,γ2,…,γn后,再确定出γ1,γ2,…,γn中大于阈值ζ的个数,该个数记为d,并将特征向量p1,p2,…,pd组建成变换矩阵p=[p1,p2,…,pd]。
步骤(4.5):根据如下所示公式计算核矩阵j∈rn×n中第i行第b列元素j(i,b):
其中,i∈{1,2,…,n},b∈{1,2,…,n}。
步骤(4.6):根据如下所示公式④对j实施中心化处理得到
上式中,矩阵iin∈rn×n中所有元素都是1,rn×n表示n×n维的实数矩阵。
步骤(4.7):将向量wg设置为d×d维单位矩阵的第g列向量。
步骤(4.8):根据如下所示公式更新向量wg:
wg=e{z0tf(z0wg)}-e{h((z0wg))}wg⑤
其中,e{}表示计算大括号内向量的均值,函数f(u)=tanh(u)与函数g(u)=sech(u)2,u为函数自变量。
步骤(4.9):对向量wg实施归一化处理wg=wg/||wg||后,判断向量wg是否收敛;若否,则返回步骤(4.8);若是,则执行步骤(4.10);其中||wg||表示计算向量wg的长度。
步骤(4.10):根据公式
步骤(4.11):根据公式a=pw(btw)-1计算载荷矩阵a后,再根据公式
步骤(4.12):根据公式q=diag{sφst}计算故障检测指标向量q∈rn×1,再使用核密度估计法计算得到在置信度等于99%条件下的控制上限qlim。
步骤(4.13):保留核矩阵k,载荷矩阵a,矩阵φ,和控制上限qlim。
本发明方法的离线建模过程至此已全部结束,接下来就是利用在线采样数据不间断地实施对多精馏塔设备运行状态的实时监测,从而及时识别出异常状态。
步骤(5):在最新采样时刻t,利用精馏塔设备所安装的测量仪表测量得到由m个采样数据组成的数据向量xt∈rm×1,并对其实施与步骤(2)中相同的标准化处理,得到新数据向量
步骤(6):根据如下所示公式计算核向量kt∈r1×n中的第b个元素kt(b):
上式中,b∈{1,2,…,n},r1×n表示1×n维的实数向量。
从上式⑧中可以看出,本发明方法针对在线测量到的每个数据,只需计算n次即可得到核向量;相比之下,传统的kica方法需要计算n次才能得到核向量;因此本发明方法的在线计算量得到了明显的降低。
步骤(7):根据如下所示公式对核向量kt实施中心化处理得到
上式中,向量iit∈r1×n中所有元素都为1。
步骤(8):根据公式
步骤(9):判断是否满足条件:qt≤qlim;若是,则当前采样时刻精馏塔运行状态正常,返回步骤(5)继续实施对下一最新采样时刻的故障检测;若否,则执行步骤(10)从而决策精馏塔是否进入故障运行状态。
步骤(10):返回步骤(5)继续实施对下一最新采样时刻样本数据的运行状态监测,若连续3个采样时刻的故障检测指标都不满足步骤(9)中的判断条件,则精馏塔进入故障工况;否则,返回步骤(5)继续实施对下一最新采样时刻的故障检测。
本发明方法的优势与特点如下所示。
首先,本发明方法旨在降低kica方法用于精馏塔在线故障检测的计算量,通过聚类算法筛选出具有代表性的聚类中心向量进行核矩阵与核向量的计算,从而大幅度提升了计算效率;其次,本发明方法又充分发挥所有正常工况训练样本在建立故障检测模型中的作用,使用所有的样本数据来确定核独立成分模型及其控制上限;最后,通过具体的实施案例,验证本发明方法能在提升计算效率的同时,不会故障检测的能力造成负面影响。
附图说明
图1为本发明方法的实施流程示意图。
图2为精馏塔设备的实景图和组成结构示意图。
图3为本发明方法在检测多种精馏塔故障工况采样数据的检测率对比。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
如图1所示,本发明公开了一种基于快速核独立成分分析的精馏塔故障检测方法,下面结合一个具体应用实例来说明本发明方法的具体实施方式。
从图2中的精馏塔实景图可以看出,精馏塔设备不单只是单独的一个精馏设备,在底部还有配套的再沸器,顶部配套有冷凝器。从图2中的结构示意图中可以看出,该精馏塔设备测量仪表包括:流量仪表,温度仪表,液位仪表三类,对应测量的变量有17个,具体包括:塔釜液位、塔釜压力,塔釜底部产品流量,进料流量,进料温度,顶部回流流量,冷凝器液位,以及每层塔板的温度(总计有10层)。
步骤(1):利用精馏塔设备所安装的测量仪表,在精馏塔正常运行状态时采集n=1000个样本数据x1,x2,…,x1000。
步骤(2):对1000个样本数据x1,x2,…,x1000实施标准化处理,对应得到1000个17×1维的数据向量
步骤(3):按照上述步骤(3.1)至步骤(3.3)对这1000个数据向量
步骤(4):利用z1,z2,…,z395建立基于核独立成分分析的故障检测模型,保留核矩阵k,载荷矩阵a,矩阵φ和控制上限qlim,具体实施过程详见前述步骤(4.1)至步骤(4.13)。
离线建模阶段完成后,即可按照如下所示步骤不间断的对精馏塔实施在线状态监测,需要利用每个新采样时刻的样本数据。
步骤(5):在最新采样时刻t,利用精馏塔设备所安装的测量仪表测量得到由m个采样数据组成的数据向量xt∈r17×1,并对其实施与步骤(2)中相同的标准化处理,得到新数据向量
步骤(6):根据上述公式⑥计算核向量kt∈r1×395中的第b个元素kt(b)。
与传统kica方法使用n=1000个样本数据x1,x2,…,x1000建立故障检测模型不同,本发明方法只使用n=395个聚类中心向量建立故障检测模型,用于在线计算核向量的样本数大幅度减少,从而可以直接提升在线计算效率。
步骤(7):根据上述公式⑦对核向量kt实施中心化处理得到
步骤(8):根据公式
步骤(9):断是否满足条件:qt≤qlim;若是,则当前采样时刻精馏塔运行状态正常,返回步骤(5)继续实施对下一最新采样时刻的故障检测;若否,则执行步骤(10)从而决策精馏塔是否进入故障运行状态。
步骤(10):返回步骤(5)继续实施对下一最新采样时刻样本数据的故障检测,若连续3个采样时刻的故障检测指标都不满足步骤(9)中的判断条件,则精馏塔进入故障工况;否则,返回步骤(5)继续实施对下一最新采样时刻的故障检测。
在实施步骤(6)时已经说明,本发明方法通过降低训练kica模型的向量个数,起到了在线降低核向量计算量的效果,因此本发明方法能够提升在线计算效率。此外,为了进一步研究本发明方法不会对故障检测结果造成负面影响,特别针对精馏塔在冷凝水温度异常、再沸器温度异常、和回流阀门粘滞三类故障工况时的采样数据,对比分析了本发明方法与传统kica方法的故障检测成功率。从图3中可以看出,本发明方法与传统kica方法几乎差异甚微。因此,不影响本发明方法的故障检测效果。
- 还没有人留言评论。精彩留言会获得点赞!