使用范围特定的系数集字段执行一元函数的系统的制作方法
[0001]
本公开一般地涉及计算机开发领域,并且更具体地,涉及数据处理。
背景技术:
[0002]
处理器可以执行将一个参数作为输入并生成输出的一元函数。一元函数的示例包括超越函数(例如tanh、log2、exp2、sigmoid)、无理函数(例如sqrt、1/sqrt)以及对机器学习和神经网络有用的常见有理函数(例如1/x)。输入值(x)的某些一元函数不容易使用基本数学运算(例如加法、减法和乘法)来执行。
技术实现要素:
[0003]
根据本申请的一方面,提供了一种处理器,包括:存储器,用于存储多个条目,所述多个条目中的每个条目与输入值范围的一部分相关联,所述多个条目中的每个条目包括定义幂级数近似的系数集;以及算术引擎,包括电路,用于:基于确定浮点输入值在所述输入值范围中与所述多个条目中的第一条目相关联的一部分内,选择所述第一条目;以及通过估算所述浮点输入值处由所述第一条目的系数集定义的幂级数近似,来计算输出值。
[0004]
根据本申请的另一方面,提供了一种方法,包括:存储多个条目,所述多个条目中的每个条目与输入值范围的一部分相关联,所述多个条目中的每个条目包括定义幂级数近似的系数集;基于确定浮点输入值在所述输入值范围中与所述多个条目中的第一条目相关联的一部分内,选择所述第一条目;以及通过估算所述浮点输入值处由所述第一条目的系数集定义的幂级数近似,来计算输出值。
[0005]
根据本申请的又一方面,提供了一种系统,包括用于执行如上所述的方法的装置。
附图说明
[0006]
图1示出了根据某些实施例的使用范围特定的系数集执行一元函数的系统。
[0007]
图2示出了根据某些实施例的一元函数的多个范围。
[0008]
图3示出了根据某些实施例的第一算术引擎。
[0009]
图4示出了根据某些实施例的第二算术引擎。
[0010]
图5示出了根据某些实施例的用于使用范围特定的系数集执行一元函数的第一流程。
[0011]
图6示出了根据某些实施例的用于使用范围特定的系数集执行一元函数的第二流程。
[0012]
图7示出了根据某些实施例的示例现场可编程门阵列(fpga)。
[0013]
图8a是示出根据某些实施例的示例性顺序流水线和示例性寄存器重命名、乱序发布/执行流水线两者的框图。
[0014]
图8b是示出根据某些实施例的要被包括在处理器中的顺序架构核的示例性实施例和示例性寄存器重命名、乱序发布/执行架构核两者的框图。
[0015]
图9a/图9b示出了根据某些实施例的更具体的示例性顺序核架构的框图,该核将是芯片中的几个逻辑块之一(可能包括相同类型和/或不同类型的其他核)。
[0016]
图10是根据本公开的实施例的可以具有多于一个核、可以具有集成存储器控制器并且可以具有集成图形的处理器的框图。
[0017]
图11、图12、图13和图14是根据某些实施例的示例性计算机架构的框图;以及
[0018]
图15是根据某些实施例的对照使用软件指令转换器将源指令集中的二进制指令转换为目标指令集中的二进制指令的框图。
[0019]
在不同的附图中,相同的标号和名称表示相同的元件。
具体实施例
[0020]
一元函数可以全部或部分地利用存在于处理器中的查找表(lut)来实现。在某些系统中,lut还可以提供实现定制函数所需的灵活性。一些处理器可以提供经由指令字段可选择的多个不同的列表函数(例如,可以利用基于输入的查找的函数)。当最低精度单位(ulp)是统一的(例如,提供给函数的所有输入具有相同的ulp)时,lut可以相对容易地用于索引。例如,lut的索引可以简单地是右移的输入值,并且函数的输出可以是lut中该位置处存在的值,或者是选定值和下一值之间的线性插值。但是,在利用浮点(fp)数作为输入的处理器中,ulp是不统一的,并且列表函数的实现变得更加困难。由于fp输入的ulp的可变性质,仅输入的右移通常不是确定lut索引的可行方法。
[0021]
本公开的各种实施例提供了用于执行具有fp数作为输入的一元函数的鲁棒解决方案。在本公开的特定实施例中,一元函数通过在输入的可能值上连续布置的一组幂级数近似来实现。例如,可以通过对幂级数(例如形式为a0+a1x+a2x2)的估算来确定列表函数结果,其中x是(可能操纵的)输入值,而a0、a1和a2是来自lut的系数。在特定实施例中,系数由两级处理确定。首先,将输入fp值与连续范围进行比较。每个范围的起始值可以是任意fp数,而特定范围的终止值是比下一范围的起始值小一个ulp的fp值。其次,一旦确定了输入值的范围,则基于该范围内输入值的偏移量来选择系数集(例如a0、a1和a2)(因此,不同的范围可以与不同系列的系数集相关联,并且范围的不同分区可以与不同的系数集相关联)。每个范围的系数集的数量是灵活的(例如,0到n,其中n是任何合适的整数),并且在一些实施例中,可以在整个范围上在数值上均匀地分布(尽管非均匀分布也是可能的)。然后,系数集与输入值x结合使用,以计算一元函数的结果。如将在下面进一步详细解释的,一些函数可以具有一个或多个范围,这些范围不利用系数或者基于函数的特性而被优化。
[0022]
如上所述,一元函数的输入可以是fp数。在各种实施例中可以使用任何合适的fp数,其中fp数可以包括有效位(也称为尾数)和指数位。fp数也可以包括符号位。作为各种示例,fp数可以符合最小浮点格式(例如8位格式)、半精度浮点格式(fp16)、脑浮点格式(bfloat16)、单精度浮点格式(fp32)、双精度浮点格式(fp64)或其他合适的fp格式。
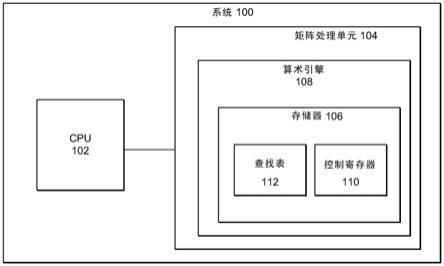
[0023]
图1示出了根据某些实施例的使用范围特定的系数集来执行一元函数的系统100。在所示实施例中,系统100包括耦合到矩阵处理单元104的中央处理单元(cpu)102。矩阵处理单元104包括存储器106和算术引擎108(在所示实施例中,存储器106在算术引擎内)。存储器包括控制寄存器110和查找表112。算术引擎108可操作为访问查找表112以获得范围特定的系数并根据控制寄存器110的配置执行一元函数。在各种实施例中,cpu 102可以执行
代码并将指令和输入发送到矩阵处理单元104,矩阵执行单元104可以执行指令并将结果发送回cpu 102。在各种实施例中,cpu 102可以请求矩阵处理单元104执行一元函数,并且该请求可以由矩阵处理单元104传递给算术引擎108,或者cpu 102可以请求某个其他操作,并且矩阵处理单元104可以确定一元函数将被执行以执行所请求的操作,并且可以指示算术引擎108执行一元函数。在各种实施例中,系统100可以允许用户对控制寄存器110进行编程以经由任何合适的接口来定义功能。
[0024]
尽管处理器100描绘了特定实施例,但是在本文中也考虑其他实施例。例如,在一些实施例中,算术引擎108不被包括在矩阵处理单元中,而是被包括在不同类型的处理器(例如,cpu 102或其他处理器)中。
[0025]
系统100的每个处理器(例如,cpu 102、矩阵处理单元104或包括算术引擎108的其他处理器)可以包括微处理器、嵌入式处理器、数字信号处理器(dsp)、网络处理器、手持处理器、应用处理器、协处理器、片上系统(soc)或其他设备来执行代码(即,软件指令)和/或执行其他处理操作。
[0026]
cpu 102可以包括一个或多个处理元件(例如,核)。在一个实施例中,处理元件是指支持软件线程的电路。硬件处理元件的示例包括:线程单元、线程插槽、线程、处理单元、上下文、上下文单元、逻辑处理器、硬件线程、核和/或能够保持处理器的状态(诸如执行状态或架构状态)的任何其他元件。换句话说,在一个实施例中,处理元件是指能够独立地与诸如软件线程、操作系统、应用或其他代码的代码相关联的任何硬件。
[0027]
核可以指位于集成电路上的能够维持独立架构状态的逻辑,其中,每个独立维持的架构状态与至少一些专用执行资源相关联。硬件线程可以指位于集成电路上的能够维持独立架构状态的任何逻辑,其中独立维持的架构状态共享对执行资源的访问。可以看出,当某些资源被共享而其他资源专用于架构状态时,硬件线程和核的命名法之间的界线重叠。然而,核和硬件线程被操作系统视为单独的逻辑处理器,其中操作系统能够单独地调度每个逻辑处理器上的操作。
[0028]
在各种实施例中,可以被包括在处理器中的处理元件还可以包括一个或多个算术逻辑单元(alu)、浮点单元(fpu)、缓存、指令流水线、中断处理硬件、寄存器或其他硬件以促进处理元件的操作。
[0029]
矩阵处理单元104可以包括执行用于加速与矩阵相关联的计算的功能的电路(例如,用于深度学习应用)。在各种实施例中,矩阵处理单元104可以执行向量-向量运算、矩阵-向量运算和矩阵-矩阵运算中的一个或多个。在特定实施例中,矩阵处理单元104可以对矩阵执行逐元素运算,诸如乘法和除法、加法和减法、逻辑运算符(例如,|、&、^、)、算术和逻辑移位、比较运算符(>、<、==、!=)、随机数生成和可编程函数中的一者或多者。在一些实施例中,矩阵处理单元104还可以对矩阵的元素执行操作,诸如行/列/矩阵中的最大值和索引、行/列/矩阵中的最小值和索引、以及跨行/列/矩阵的求和中的一者或多者。。
[0030]
算术引擎108包括用于执行一个或多个一元函数的电路。在各种实施例中,算术引擎108也可用于执行二元函数(例如,基于两个输入执行操作的函数)。在特定实施例中,算术引擎108可操作以在由矩阵处理单元104进行矩阵乘法之前对输入数据执行二元函数,以及在执行矩阵乘法之后对输出数据执行二元和一元函数。在特定实施例中,算术引擎可以按逐个元素的方式每个周期处理32个bfloat16元素或16个fp32元素,尽管在其他实施例
中,算术引擎可以适配为每个周期处理其他数量的元素。
[0031]
算术引擎108可以包括存储器106。在其他实施例中,算术引擎108可以访问不是算术引擎108的一部分的存储器106。存储器106可以包括任何非易失性存储器和/或易失性存储器。存储器106可以包括任何合适类型的存储器,并且在各种实施例中不限于存储器的特定速度、技术或形状因数。在所示实施例中,存储器106包括控制寄存器110和查找表112。在其他实施例中,控制寄存器110和查找表112可以被存储在单独的存储器中。
[0032]
查找表112可以包括一个或多个一元函数的系数集。例如,对于第一一元函数,查找表112可以包括多个表条目,其中每个条目包括用于第一一元函数的输入值范围的相应部分的系数。因此,用于第一一元函数的第一表条目可以包括当该函数的输入值在输入值的第一范围的第一部分内时要使用的系数集,用于第一一元函数的第二条目可以包括当函数的输入值在输入值的第一范围的第二部分内时要使用的不同的系数集,依此类推。类似地,查找表112可以包括用于第一函数的第二范围的单独的一系列系数集、用于第一函数的第三范围的另一系列系数集等。类似地,查找表112可以包括用于其他函数的独立系列的系数集。在各种实施例中,条目可以存储压缩或未压缩的系数。
[0033]
系数可以用于定义用于基于输入值来计算一元函数的输出值的幂级数。在特定实施例中,幂级数采用a0+a1x+a2x2的形式,其中x是输入值,并且a0、a1和a2是从查找表112中检索的系数集。在其他实施例中,可以使用不同的幂级数。例如,幂级数可以采用a0+a1x+a2x2+a3x3的形式。可以使用具有更高阶的类似幂级数,但是由于计算输出所需的附加逻辑以及要存储在查找表112中的系数的数量增加,随着幂级数变得更复杂,算法引擎108所占的空间量会增大。
[0034]
查找表中存储的范围和相应条目的数量可以根据一元函数的复杂性而变化。例如,高度优化的函数可消耗很少的条目(例如,16个或更少的系数集),而曲线和非对称函数(例如,s形)可能会使用更多的条目(例如,约90个系数集)。
[0035]
图2示出了根据某些实施例的一元函数tanh的多个范围。在一些实施例中,所描绘的范围(202、204、206、208和210)可以各自与一个或多个系数集相关联(其中范围可以各自利用任何合适数量的系数集,并且不同范围可以具有不同数量的系数集)。区域的每个分区(其中分区被描绘为包括两条细垂直线之间的输入值的区域)可以由不同的系数集控制。在各种实施例中,范围内的分区具有相同的大小。例如,一个系数集可以适用于-2.0至-1.8的x值,下一系数集可以适用于-1.8至-1.6的x值,依此类推。
[0036]
通常,对于具有较高非线性的范围,采样密度(即,每单位输入值区域的系数集的数量)较高。因此,用于范围204和208的系数集的数量比用于其他范围的系数集的数量高得多。因为范围202渐近于-1(即,在该范围的输入值上具有常数输出值-1),所以整个范围可以利用a0=-1、a1=0和a2=0的单个系数集(假设幂级数形式为a0+a1x+a2x2)。类似地,因为范围210渐近于1,所以整个范围还可以利用a0=1、a1=0和a2=0的单个系数集。范围206是线性的,因此也可以利用a0=0、a1=1和a2=0的单个系数集,使得在该范围中输出方程简单地为x(即,输出等于输入)。
[0037]
图2所示的范围仅是示例。在其他实施方式中,一元函数可以被分解为更多或更少的区域。如下所述,可以进行进一步的优化以减少所存储的系数的数量。例如,由于tanh函数关于原点对称,因此范围208的系数集可被重新用于范围204(具有合适的符号改变),并
且因此落在范围204中的输入值可导致与范围208相关联的系数集的查找。作为另一示例,对于其中输出值是常数的区域(例如202和210)或其中输出值等于输入值的区域(例如206),该范围可以与指定输出值的模式相关联,并且当在该范围内的输入处估算函数时,查询表112不需要被访问。因此,可以在不存储相关系数集的情况下实现这样的区域。可选地,可以根据以上示例利用系数集来实现这样的区域。
[0038]
再次参考图1,存储器106还包括多个控制寄存器110。这些控制寄存器定义由算术引擎108实现的一元函数的每一者的操作。下面定义了可能的控制寄存器的示例,尽管本公开涵盖下文或其他控制寄存器的任何合适的变型以实现本文描述的功能。每个寄存器的实际位数可以根据具体实现方式而变化。在特定实施例中,实现的每个函数与专用于该函数的相应的寄存器集相关联。
[0039]
使能寄存器
–
该寄存器可以被设置为使能函数。在特定实施例中,当该寄存器未被设置并且执行函数的请求被接收到时,输出值被设置为非数字(nan)。
[0040]
范围数量寄存器
–
该寄存器定义针对函数使能的范围数量。当范围数量被限制为8时,3位可以用于该寄存器,尽管其他实施例可能允许更多或更少的范围。如果函数被使能,则至少一个范围是有效的。每个函数可以具有相关联的范围数量寄存器。
[0041]
范围模式寄存器
–
该寄存器指定范围的模式,因此可以存在多个这些寄存器,每个寄存器对应于函数的不同范围。在特定实施例中,可用于选择的模式是查找、常数和等同。查找模式指定应执行表查找,并且应计算所得到的幂级数以生成函数的输出。等同模式指定输出值等于输入值(因此不需要执行查找)。常数模式指定特定常数(可以被存储在控制寄存器110之一或其他区域中)将作为输出值被返回(因此不需要执行查找)。
[0042]
起始值寄存器
–
该寄存器指定范围的起始值(例如,可能包含起始值),其中起始值是范围内的最低输入值x。可以存在多个这些寄存器,每个寄存器对应于函数的不同范围。在特定实施例中,起始值采用fp32格式,尽管可以使用本文或其他地方描述的其他格式。起始值寄存器可以使得能够确定输入值落入哪个范围(例如,可以将fp输入值与各种起始值进行比较以确定哪个范围包括该输入值)。
[0043]
基地址寄存器
–
该寄存器指定查找表中分配给特定范围的表条目的基地址。因此,可以存在多个这些寄存器,每个寄存器对应于函数的不同范围。基地址可以与输入值在范围内的位置结合使用,以确定包括相应系数集的相关表条目的地址。
[0044]
偏移值寄存器-该寄存器存储偏移值(例如,用户提供的预先计算的整数值),该偏移值用于导出输入值在范围内的偏移量。在一实施例中,可以从输入值中减去预先计算的整数值,以确定输入值在范围内的偏移量。因此,偏移值可以是整数格式的范围的起始。可以存在多个这些寄存器,每个寄存器对应于该函数的不同范围。在特定实施例中,当范围被设置为常数模式时,可以将常数(或指向常数的指针)代替偏移值存储在偏移值寄存器中。
[0045]
指数跨度寄存器
–
该寄存器存储表示范围的指数“跨度”的值(例如,落入范围内的输入值的最大可能指数值,因为在某些情况下范围可能跨越多个指数)。当函数利用归约运算(reduction operation)时,该值可以为零,因为在查找之前输入被标准化为1和2之间的数。存储在指数跨度寄存器中的值可以允许将范围内的输入值转换为相同的指数,使得可以将偏移值(可以是整数)应用于任何输入值,而不管输入值是否具有不同的指数值。可以存在多个这些寄存器,每个寄存器对应于函数的不同范围。
[0046]
移位寄存器
–
该寄存器存储表示应用于输入值在范围内的偏移量的移位量的值(例如,从输入值中减去偏移值之后得到的值)。在一些实施例中,该值可以由用户提供。在特定实施例中,该值基于范围内的系数集的数量。例如,当2
z
表示范围内的系数集的数量并且实际移位量通过从另一个数y(例如,指示表示尾数或标准化尾数的位数)中减去z来确定时,写入移位寄存器的值可以是z。可以存在多个这些寄存器,每个寄存器对应于函数的不同范围。
[0047]
对称模式寄存器
–
该寄存器指定函数的对称性。例如,对称模式可以是无对称、y轴对称或原点对称。一些一元函数(例如,一些深度学习函数)具有对称性,因此,代替针对对应的负范围和正范围存储系数集,可以针对这两个范围存储单一系列的系数集。当对称模式为无对称时,不应用对称优化。当对称模式为y轴对称时,可以使用输入值的绝对值来估算函数。当对称模式为原点对称时,可以使用输入值的绝对值来估算函数,并且如果原始输入为负,则输出的符号被反转以产生最终输出。每个函数可以具有其自己的对称模式寄存器。
[0048]
在特定实施例中,该寄存器(或其他寄存器)中的值可以针对函数指定其他定制模式。例如,neg_as_nan模式可以指定如果输入值为负,则不应执行查找,而应将nan作为输出返回(例如,当函数是sqrt(x)或不对负数进行操作的其他函数时,这种模式可能是有用的)。
[0049]
特例寄存器
–
这些寄存器可以指定在接收到函数的特定输入值(例如,精确为零,+无穷大或
–
无穷大)时是否应当应用特例处理。例如,对于特定的输入值,特例寄存器可以指定不应用特殊处理,或者应将缓存的预定义常数作为输出值返回而不执行查找。可选地,特例寄存器可以指定应返回nan(例如,当函数为倒数运算且输入为0时)。
[0050]
函数模式寄存器
–
指定特定于函数的优化(如果有的话)。例如,对于一些公知的函数(例如sqrt(x)、1/x、1/sqrt(x)、log2(x)、2
x
),结果的指数(或与其非常接近的值)可以利用合理琐碎的额外逻辑(例如8位整数加法)用算法导出。在这种情况下,可以将查找操作和幂级数计算限制为覆盖输入尾数(相应地,可以经由归约运算将输入值归约到1和2之间的值)或输入值的其他部分,这可以显著地减少函数所需的查找表条目的数量。在某些情况下,函数模式可以优先于通过控制寄存器指定的其他模式(例如,对于函数1/x,对称模式可以被强制为原点对称,而不考虑对称模式的设置)。将结合图4更详细地描述特定于函数的优化的操作。
[0051]
压缩模式
–
该寄存器针对查找表条目指定解压缩算法(如果系数在查找表中被压缩)。在特定实施例中,使用两种压缩模式。第一压缩模式对系数的范围进行限制,但是生成精确的输出,而第二压缩模式不限制系数的范围,因此允许全范围的浮点输入,代价是输出不精确。在特定实施例中,查找表的每个条目包括根据指定的解压缩算法解压缩(例如,从64位到96位)的三个系数的数据。
[0052]
图3描绘了根据某些实施例的算术引擎300。算术引擎300可以包括算术引擎108的任何特性,反之亦然。在所示实施例中,算术引擎300包括两级融合的乘法加法器(fma)302和304。每级具有n个fma,其中n是任何合适的整数,并且每个fma可以对单独的输入值x进行操作(例如,向量或矩阵的元素),因此,可以并行地处理n个独立的lut(例如,经由单个指令、多数据simd方法)。
[0053]
在所示实施例中,所实现的幂级数的形式为a0+a1x+a2x2,其等效于所示的结果(a0+(a1+a2x)*x)。从查找表112获得lut系数306。输入x和系数a1+a2被提供给第一级以产生中间结果(a1+a2x)。然后,该中间结果与输入x和系数a0一起被提供给第二级,以生成最终结果。
[0054]
尽管描绘了特定实施例,但是其他实施例可以包括任何其他合适的电路来计算幂级数结果。例如,可以使用除fma之外的电路。如上所述,其他实施例可以估算不同的幂级数。例如,fma的另一级可以被添加到算术引擎300以估算幂级数a0+a1x+a2x2+a3x3。通常,包括n级fma的算术引擎108可以根据到n次幂的幂级数来计算输出值。
[0055]
图4示出了根据某些实施例的算术引擎400。算术引擎400可以包括算术引擎108的任何特征,反之亦然。所描绘的算术引擎400包括一元引擎402和二元引擎404。在各种实施例中,一元引擎402可以包括专用于执行一元函数的电路,而二元引擎404可以包括可以支持一元函数以及二元函数的电路(尽管未示出,但是当执行二元函数时,单精度(sp)fma406和408的输入也可以耦合到其他输入)。在其他实施例中,示出的组件可以被包括在任何合适的算术引擎或其他系统或设备内(例如,二元引擎404内示出的组件不一定需要被包括在二元引擎内)。
[0056]
在实施例中,一元引擎402可以产生系数(在该实施例中为a0、a1和a2)并执行由上述控制寄存器指定的优化。在所示实施例中,一元引擎402可以包括查找表410(其可以具有查找表112的任何特征)。尽管未示出,但是一元引擎402还可以包括控制寄存器(例如,控制寄存器110中的任何一个)。
[0057]
在所示实施例中,一元引擎402还包括控制模块412。控制模块412可以接收输入值x和关于要对x执行的一元函数的指示。控制模块412可以访问控制寄存器(csr)以确定如何处理输入。例如,控制模块412可以确定输入值对应于哪个范围(例如,通过将输入值和与一元函数相关联的一个或多个起始值寄存器进行比较)。控制模块412还可以确定范围特定的行为。例如,控制模块412可以确定是否要执行查找。如果要执行查找,则控制模块412基于输入值x和控制寄存器中可用的信息来计算进入lut 410的地址(描述为“表索引”)。该地址被传递到lut 410,并且从lut 410中检索相应的系数。控制模块412还可操作为在不执行查找时(例如,当输入落入具有单个输出的范围内时)检索常数或其他值(例如,nan),或者当控制寄存器针对范围指定等同模式时输出输入值(或者指示后处理模块414这样做)。
[0058]
在一些实施例中,控制模块412可以确定是否要执行归约运算。例如,如上所述,对于一些函数,可以容易地计算结果的指数,因此幂级数可以简单地对输入值的尾数(或者输入值的其它经归约部分)进行操作,而不是对整个输入值进行操作。当控制模块412确定要执行归约运算时,控制模块412可以从输入值中提取经归约的值(例如,尾数),并将该经归约的值输出为x’。输入的指数(例如,输入x的实际指数、或基于应用于输入x以将输入x归约为例如1和2之间的值的乘数的指数)和符号也可由控制模块412输出为“边带(sideband)数据”。在一些实施例中,边带数据还可以包括任何合适的信息,以允许后处理模块414计算最终指数和符号(例如,关于一元函数的指示、或者关于要对指数和/或符号执行的操作的指示)。在一些实施例中,边带数据可以包括指示输出应当被转换特定值的信息(例如,当输出无效时为nan,例如当函数为平方根并且输入值为负时)。
[0059]
当控制模块412确定归约运算将不被执行时,控制模块412可以将输入值x输出为x'(并且边带数据可以被省略或设置为指示不存在边带数据的值)。
[0060]
fma 406和408可以以类似于上文关于fma 302和304描述的方式操作,而不管x’是实际输入值还是经归约的输入值。尽管fma 406和408被示为单精度fma,但是fma可以被配置为对任何合适的数字格式进行操作。fma 408的输出可以被提供给后处理模块414,用于在由算术引擎400输出最终输出值之前要执行的任何处理。
[0061]
在各种实施例中,算术引擎400能够对多种不同的输入格式执行一元函数。例如,当对具有较短格式(例如bfloat16)的输入值进行操作时,输入值可以被向上转换为较长格式(例如fp32),并且可以使用与输入值以更长的格式到达时相同的电路fma。如果对于输出期望较短的格式,则算术引擎400(例如,经由后处理模块414)可以内联向下转换结果。
[0062]
在各种实施例中,可以由算术引擎以任何合适的方式来处理异常(denormal)和nan。例如,可以在处理之前将异常输入值转换为0(例如+0),并且可以将异常范围中的最终结果刷新为有符号0(除了选定范围处于常数模式并且该常数已被编程为异常值的情况之外)。作为另一个示例,如果需要,输入的nan值可以被静默(quieted)并传播到结果中。对于各种无效处理情况(例如,当输入值未落入任何所定义的范围部分时),可以生成真实不确定类型的静默nan。
[0063]
图5示出了根据某些实施例的用于使用范围特定的系数集来执行一元函数的流程500。在各种实施例中,该流程可以由算术引擎108和/或包括电路的其他合适的逻辑来执行。
[0064]
在502处,接收函数的标识和输入值x。在504处,确定特例是否适用于输入值。例如,可以检查寄存器以查看输入值是否与适用于特例的值(例如,精确为零、+无穷大或-无穷大)相匹配。如果特例适用,则在506处输出对应的特殊值,并且流程结束。如果特例不适用,则流程移动到508。
[0065]
在508处,确定是否要对输入值应用归约。如果要应用归约,则在510处输入值被归约。在特定实施例中,这涉及提取输入值的尾数,并将输入值的指数和符号置于边带数据中以用于后续处理。在归约之后(或在不执行归约的情况下),流程移动到512。
[0066]
在512处,基于输入值识别函数的范围。在514处,确定所识别范围的模式。如果模式是等同模式,则在516处输出输入值,并且流程结束。如果模式是常数模式,则在518处检索和输出相关联的常数,并且流程结束。
[0067]
如果模式是查找模式,则在520执行查找。这可以包括基于范围的起始地址和范围内的输入值的偏移量来确定查找表的地址。查找可以返回系数集。在522处,针对输入值计算由系数定义的幂级数。在524处输出结果,并且流程结束。
[0068]
图6示出了根据某些实施例的用于使用范围特定的系数集来执行一元函数的流程600。602包括存储多个条目,多个条目中的每个条目与输入值范围的一部分相关联,多个条目中的每个条目包括定义幂级数近似的系数集。604包括基于确定浮点输入值在与多个条目中的第一条目相关联的输入值范围的一部分内来选择第一条目。606包括通过估算浮点输入值处由第一条目的系数集定义的幂级数近似来计算输出值。
[0069]
在图2-6中描述的流程仅表示在特定实施例中可能发生的操作。在其他实施例中,可以执行附加操作。本公开的各种实施例考虑了用于实现本文描述的功能的任何合适的信令机制。在适当的情况下,图2-6中所示的一些操作可以被重复、组合、修改或省略。另外,在不脱离特定实施例的范围的情况下,可以以任何合适的顺序执行操作。
[0070]
下面的附图详细描述用于实现上述实施例的示例性架构和系统。例如,矩阵处理单元104和/或算术引擎108可以被包括在下面示出的任何处理器或系统之内或耦合到该处理器或系统。在一些实施例中,上面描述的一个或多个硬件组件和/或指令如下面所详述地被仿真,或者被实现为软件模块。
[0071]
图7示出了根据某些实施例的现场可编程门阵列(fgpa)700。在特定实施例中,算术引擎108可以由fpga 700实现(例如,算术引擎108的功能可以由操作逻辑704的电路来实现)。fpga可以是包括可配置逻辑的半导体器件。可以经由具有定义如何配置fpga的逻辑的任何合适格式的数据结构(例如,位流)来对fpga进行编程。在制造fpga之后,可以对fpga重新编程任何次数。
[0072]
在所示实施例中,fpga 700包括可配置逻辑702、操作逻辑704、通信控制器706和存储器控制器710。可配置逻辑702可以被编程为实现一个或多个核。核可以包括fpga的所配置的逻辑,该fpga可以接收一个或多个输入的集合、使用所配置的逻辑处理输入的集合,并提供一个或多个输出的集合。核可以执行任何合适类型的处理。在各种实施例中,核可以包括前缀解码器引擎。一些fpga 700可被限制为一次执行单个核,而其他fpga可能够同时执行多个核。可配置逻辑702可以包括任何合适逻辑,例如任何适当类型的逻辑门(例如,与门、异或门)或逻辑门的组合(例如,触发器、查找表、加法器、乘法器、复用器、解复用器)。在一些实施例中,通过fpga的逻辑组件之间的可编程互连来(至少部分地)配置逻辑。
[0073]
操作逻辑704可以访问定义核的数据结构,并基于该数据结构配置可配置逻辑702,并执行fpga的其他操作。在一些实施例中,操作逻辑704可以基于该数据结构将控制位写入fpga 700的存储器(例如,基于非易失性闪存或基于sram的存储器),其中控制位用于配置逻辑(例如,通过激活或去激活可配置逻辑的各部分之间的特定互连)。操作逻辑704可以包括任何合适的逻辑(其可以以可配置逻辑或固定逻辑来实现),例如包括任何合适类型的存储器(例如,随机存取存储器(ram))的一个或多个存储器设备、一个或多个收发器、时钟电路、位于fpga上的一个或多个处理器、一个或多个控制器或其他合适的逻辑。
[0074]
通信控制器706可以使fpga 700能够与计算机系统的其他组件(例如,压缩引擎)通信(例如,接收用于压缩数据集的命令)。存储器控制器710可以使fpga能够从计算机系统的存储器读取数据(例如,操作数或结果)或向计算机系统的存储器写入数据。在各种实施例中,存储器控制器710可以包括直接存储器访问(dma)控制器。
[0075]
处理器核可以用不同的方式实现,可以被实现用于不同的目的,并且可以在不同的处理器中实现。例如,这种核的实现方式可以包括:1)用于通用计算的通用顺序核;2)用于通用计算的高性能通用乱序核;3)主要用于图形和/或科学(吞吐量)计算的专用核。不同处理器的实现方式可以包括:1)cpu,其包括旨在用于通用计算的一个或多个通用顺序核和/或旨在用于通用计算的一个或多个通用乱序核;2)协处理器,包括主要用于图形和/或科学(吞吐量)的一个或多个专用核。这种不同的处理器导致不同的计算机系统架构,其可以包括:1)在与cpu不同的芯片上的协处理器;2)在与cpu相同的封装中的单独管芯(die)上的协处理器;3)在与cpu相同的管芯上的协处理器(在这种情况下,这种协处理器有时被称为专用逻辑(例如,集成图形和/或科学(吞吐量)逻辑)或被称为专用核);4)片上系统,其可以在同一管芯上包括所描述的cpu(有时被称为(一个或多个)应用核或(一个或多个)应用处理器)、以上描述的协处理器、和附加功能。接下来描述示例性核架构,之后描述示例性处
理器和计算机架构。
[0076]
图8a是示出根据本公开的实施例的示例性顺序流水线和示例性寄存器重命名、乱序发布/执行流水线两者的框图。图8b是示出根据本公开的实施例的要被包括在处理器中的顺序架构核和示例性寄存器重命名、乱序发布/执行架构核两者的示例性实施例的框图。图8a-b中的实线框示出了顺序流水线和顺序核,而可选择添加的虚线框示出了寄存器重命名、乱序发布/执行流水线和核。假定顺序方面是乱序方面的子集,将描述乱序方面。
[0077]
在图8a中,处理器流水线800包括提取阶段802、长度解码阶段804、解码阶段806、分配阶段808、重命名阶段810、调度(也被称为调派或发布)阶段812、寄存器读取/存储器读取阶段814、执行阶段816、写回/存储器写入阶段818、异常处理阶段822、和提交阶段(commit stage)824。
[0078]
图8b示出了处理器核890,其包括耦合到执行引擎单元850的前端单元830,并且执行引擎单元850和前端单元830两者都耦合到存储器单元870。核890可以是精简指令集计算(risc)核、复杂指令集计算(cisc)核、超长指令字(vliw)核、或混合或替代的核类型。作为另一种选择,核890可以是专用核,例如,网络或通信核、压缩和/或解压缩引擎、协处理器核、通用计算图形处理单元(gpgpu)核、图形核等。
[0079]
前端单元830包括耦合到指令缓存单元834的分支预测单元832,指令缓存单元834耦合到指令转换后备缓冲器(tlb)836,指令转换后备缓冲器836耦合到指令提取单元838,指令提取单元838耦合到解码单元840。解码单元840(或解码器)可以解码指令,并且生成作为输出的一个或多个微操作、微代码入口点、微指令、其他指令、或其他控制信号,它们解码自原始指令或以其他方式反映原始指令或导出自原始指令。可以使用各种不同的机制来实现解码单元840。合适机制的示例包括但不限于查找表、硬件实现方式、可编程逻辑阵列(pla)、微代码只读存储器(rom)等。在一个实施例中,核890包括微代码rom或存储用于某些宏指令的微代码的其他介质(例如,在解码单元840中或在前端单元830内)。解码单元840耦合到执行引擎单元850中的重命名/分配器单元852。
[0080]
执行引擎单元850包括重命名/分配器单元852,其耦合到引退(retirement)单元854和一组一个或多个调度器单元856。(一个或多个)调度器单元856表示任意数目的不同调度器,包括,预留站(reservations station)、中央指令窗等。(一个或多个)调度器单元856耦合到(一个或多个)物理寄存器文件单元858。每个物理寄存器文件单元858表示一个或多个物理寄存器文件,这些物理寄存器文件中的不同的物理寄存器文件存储一个或多个不同的数据类型,例如,标量整数、标量浮点、打包整数、打包浮点、向量整数、向量浮点、状态(例如,作为要执行的下一指令的地址的指令指针)等。在一个实施例中,(一个或多个)物理寄存器文件单元858包括向量寄存器单元、写入掩码寄存器单元、和标量寄存器单元。这些寄存器单元可以提供架构向量寄存器、向量掩码寄存器、和通用寄存器。(一个或多个)物理寄存器文件单元858与引退单元854重叠,以说明寄存器重命名和乱序执行可以被实现的各种方式(例如,使用(一个或多个)重新排序缓冲器和(一个或多个)引退寄存器文件;使用(一个或多个)未来文件、(一个或多个)历史缓冲器、和(一个或多个)引退寄存器文件;使用寄存器图和寄存器池;等等)。引退单元854和(一个或多个)物理寄存器文件单元858耦合到(一个或多个)执行集群860。(一个或多个)执行集群860包括一组一个或多个执行单元862和一组一个或多个存储器访问单元864。执行单元862可以对各种类型的数据(例如,标量浮
点、打包整数、打包浮点、向量整数、向量浮点)执行各种操作(例如,移位、加法、减法、乘法)。虽然一些实施例可以包括专用于特定功能或功能集的多个执行单元,但是其他实施例可以仅包括一个执行单元或者全部执行所有功能的多个执行单元。(一个或多个)调度器单元856、(一个或多个)物理寄存器文件单元858、和(一个或多个)执行集群860被示为可能是多个,因为某些实施例针对某些类型的数据/操作创建单独的流水线(例如,标量整数流水线、标量浮点/打包整数/打包浮点/向量整数/向量浮点流水线、和/或存储器访问流水线,其中每个流水线都有自己的调度器单元、物理寄存器文件单元、和/或执行集群-并且在单独的存储器访问流水线的情况下,其中仅该流水线的执行集群具有(一个或多个)存储器访问单元864的某些实施例被实现)。还应理解,在使用单独的流水线的情况下,这些流水线中的一个或多个可以是乱序发布/执行而其余的是有序发布/执行的。
[0081]
该组存储器访问单元864耦合到存储器单元870,存储器单元870包括耦合到数据缓存单元874的数据tlb单元872,其中数据缓存单元874耦合到2级(l2)缓存单元876。在一个示例性实施例中,存储器访问单元864可以包括加载单元、存储地址单元、和存储数据单元,其中的每个单元耦合到存储器单元870中的数据tlb单元872。指令缓存单元834还耦合到存储器单元870中的2级(l2)缓存单元876。l2缓存单元876耦合到一个或多个其他级别的缓存并最终耦合到主存储器。
[0082]
作为示例,示例性寄存器重命名的乱序发布/执行核架构可以按如下方式实现流水线800:1)指令提取838执行提取和长度解码阶段802和804;2)解码单元840执行解码阶段806;3)重命名/分配器单元852执行分配阶段808和重命名阶段810;4)(一个或多个)调度器单元856执行调度阶段812;5)(一个或多个)物理寄存器文件单元858和存储器单元870执行寄存器读取/存储器读取阶段814;执行集群860执行执行阶段816;6)存储器单元870和(一个或多个)物理寄存器文件单元858执行写回/存储器写入阶段818;7)异常处理阶段822中可能涉及各个单元;8)引退单元854和(一个或多个)物理寄存器文件单元858执行提交阶段824。
[0083]
核890可以支持一个或多个指令集(例如,x86指令集(具有已经添加有较新版本的一些扩展);美国加利福尼亚州桑尼维尔市的mip technologies的mips指令集;美国加利福尼亚州桑尼维尔市的arm holdings的arm指令集(具有可选的附加扩展,例如,neon)),包括本文所描述的(一个或多个)指令。在一个实施例中,核890包括支持打包数据指令集扩展(例如,avx1、avx2)的逻辑,从而允许要使用打包数据来执行的许多多媒体应用所使用的操作。
[0084]
应理解,核可以支持多线程(执行两个或更多个并行的操作集或线程集),并且可以以各种方式这样做,这些方式包括时间分片多线程、同时多线程(其中,单个物理核为该物理核正在同时进行多线程的每个线程提供逻辑核)、或它们的组合(例如,时间分片的提取和解码以及此后同时的多线程,例如,在超线程技术中)。
[0085]
虽然在乱序执行的上下文中描述了寄存器重命名,但应理解,寄存器重命名可以用在顺序架构中。虽然所示处理器的实施例还包括单独的指令和数据缓存单元834/874以及共享的l2缓存单元876,但替代实施例可以具有用于指令和数据两者的单个内部缓存,例如,1级(l1)内部缓存、或多级内部缓存。在一些实施例中,系统可以包括内部缓存和外部缓存的组合,其中外部缓存在核和/或处理器外部。替代地,全部缓存可以在核和/或处理器外
部。
[0086]
图9a-b示出了更具体的示例性顺序核架构的框图,其中核将是芯片中的若干逻辑块(可能包括相同类型和/或不同类型的其他核)中的一个逻辑块。逻辑块通过高带宽互连网络(例如,环形网络)与某固定功能逻辑、存储器i/o接口、和其他必要的i/o逻辑通信,这取决于应用。
[0087]
图9a是根据本公开实施例的单个处理器核以及其与管芯上互连网络902的连接以及其在2级(l2)缓存904的本地子集的框图。在一个实施例中,指令解码单元900支持具有打包数据指令集扩展的x86指令集。l1缓存906允许低等待时间的访问以将存储器缓存到标量和向量单元中。虽然在一个实施例中(为了简化设计),标量单元908和向量单元910使用单独的寄存器组(分别为标量寄存器912和向量寄存器914),并且它们之间传输的数据被写入到存储器然后从1级(l1)缓存906中读回,但是本公开的替代实施例可以使用不同的方法(例如,使用单个寄存器组或包括允许数据在两个寄存器文件(file)之间传输而不被写入和读回的通信路径)。
[0088]
l2缓存的本地子集904是全局l2缓存的一部分,全局l2缓存被划分为分开的本地子集(在一些实施例中,每个处理器核一个本地子集)。每个处理器核具有到其自己的l2缓存的本地子集904的直接访问路径。由处理器核读取的数据被存储在其l2缓存子集904中并且可以与访问它们自己的本地l2缓存子集的其他处理器核并行地被快速访问。由处理器核写入的数据被存储在其自己的l2缓存子集904中,并且在需要的情况下被从其他子集冲刷(flushed)。环形网络确保共享数据的一致性。环形网络是双向的,以允许诸如处理器核、l2缓存、和其他逻辑块之类的代理在芯片内彼此通信。在特定实施例中,每个环形数据路径在每个方向上为1012位宽。
[0089]
图9b是根据实施例的图9a中的处理器核的一部分的展开图。图9b包括l1缓存906的l1数据缓存906a部分,以及关于向量单元910和向量寄存器914的更多细节。具体地,向量单元910是16宽的向量处理单元(vpu)(参见16宽的alu 928),它执行整数、单精度浮点、和双精度浮点指令中的一个或多个。vpu支持通过调配单元920对寄存器输入进行调配,使用数字转换单元922a-b进行数字转换,以及使用复制单元924对存储器输入进行复制。写入掩码寄存器926允许预测得到向量写入。
[0090]
图10是根据各种实施例的可具有不止一个核、可具有集成存储器控制器、且可具有集成图形的处理器1000的框图。图10中的实线框示出了具有单核1002a、系统代理1010、和一组一个或多个总线控制器单元1016的处理器1000;但虚线框的可选添加示出了具有以下各项的替代处理器1000:多个核1002a-n、系统代理单元1010中的一组一个或多个集成存储器控制器单元1014、以及专用逻辑1008。
[0091]
因此,处理器1000的不同实现方式可以包括:1)具有专用逻辑1008的cpu(其中专用逻辑是集成图形和/或科学(吞吐量)逻辑(其可以包括一个或多个核)),以及核1002a-n(其是一个或多个通用核(例如,通用顺序核、通用乱序核、或两者的组合);2)具有核1002a-n的协处理器(其中核1002a-n是主要用于图形和/或科学(吞吐量)的大量专用核);3)具有核1002a-n的协处理器(其中核1002a-n是大量通用顺序核)。因此,处理器1000可以是通用处理器、协处理器、或专用处理器,例如,网络或通信处理器、压缩和/或解压缩引擎、图形处理器、gpgpu(通用图形处理单元)、高吞吐量的许多集成核(mic)协处理器(例如,包括30个
或更多个核)、嵌入式处理器、或者执行逻辑操作的其它固定或可配置逻辑。处理器可以在一个或多个芯片上实现。处理器1000可以是一个或多个衬底的一部分和/或可以通过使用多种工艺技术(例如,bicmos、cmos或nmos)中的任何一种来在一个或多个衬底上实现。
[0092]
在各种实施例中,处理器可以包括可以是对称的或不对称的任何数量的处理元件。在一个实施例中,处理元件是指支持软件线程的硬件或逻辑。硬件处理元件的示例包括:线程单元、线程插槽、线程、处理单元、上下文、上下文单元、逻辑处理器、硬件线程、核和/或能够保持处理器的状态(诸如执行状态或架构状态)的任何其他元件。换句话说,在一个实施例中,处理元件是指能够独立地与诸如软件线程、操作系统、应用或其他代码之类的代码相关联的任何硬件。物理处理器(或处理器插槽)通常是指集成电路,其可能包括任意数量的其他处理元件(例如核或硬件线程)。
[0093]
核可以指位于集成电路上的能够维持独立架构状态的逻辑,其中,每个独立维持的架构状态与至少一些专用执行资源相关联。硬件线程可以指位于集成电路上的能够维持独立架构状态的任何逻辑,其中独立维持的架构状态共享对执行资源的访问。可以看出,当某些资源被共享而其他资源专用于架构状态时,硬件线程和核的命名法(nomenclature)之间的界线重叠。然而,核和硬件线程经常被操作系统视为单独的逻辑处理器,其中操作系统能够单独地调度每个逻辑处理器上的操作。
[0094]
存储器层级包括核内的一个或多个级别的缓存、一组或一个或多个共享缓存单元1006、以及耦合到该组集成存储器控制器单元1014的外部存储器(未示出)。该组共享缓存单元1006可以包括一个或多个中级缓存(例如,2级(l2)、3级(l3)、4级(l4)),或其他级别的缓存、最后级别缓存(llc)、和/它们的组合。虽然在一个实施例中,基于环的互连单元1012对专用逻辑(例如,集成图形逻辑)1008、该组共享缓存单元1006、以及系统代理单元1010/(一个或多个)集成存储器控制器单元1014进行互连,但替代实施例可以使用任何数目的众所周知的技术来互连这些单元。在一个实施例中,在一个或多个缓存单元1006和核1002a-n之间维持一致性。
[0095]
在一些实施例中,核1002a-n中的一个或多个核能够进行多线程。系统代理1010包括协调和操作核1002a-n的那些组件。系统代理单元1010可以包括例如电源控制单元(pcu)和显示单元。pcu可以是或可以包括调节核1002a-n和专用逻辑1008的功率状态所需的逻辑和组件。显示单元用于驱动一个或多个外部连接的显示器。
[0096]
核1002a-n在架构指令集方面可以是同构的或异构的;也就是说,核1002a-n中的两个或更多个核可能能够执行相同的指令集,而其他核可能能够执行仅该指令集的子集或不同的指令集。
[0097]
图11-14是示例性计算机架构的框图。用于膝上型计算机、台式计算机、手持式pc、个人数字助理、工程工作站、服务器、网络设备、网络集线器、交换机、嵌入式处理器、数字信号处理器(dsp)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备、和各种其他电子设备的本领域已知的其他系统设计和配置也适合用于执行本公开中所描述的方法。通常,能够结合本文所公开的处理器和/或其他执行逻辑的各种各样的系统或电子设备通常是合适的。
[0098]
图11示出了根据本公开的一个实施例的系统1100的框图。系统1100可以包括一个或多个处理器1110、1115,其耦合到控制器集线器1120。在一个实施例中,控制器集线器
1120包括图形存储器控制器集线器(gmch)1190和输入/输出集线器(ioh)1150(可以在分开的芯片或相同芯片上);gmch 1190包括耦合到存储器1140和协处理器1145的存储器和图形控制器;ioh 1150将输入/输出(i/o)设备1160耦合到gmch 1190。替代地,存储器和图形控制器中的一个或两个被集成在处理器内(如本文所描述的),存储器1140和协处理器1145直接耦合到处理器1110,并且控制器集线器1120是包括ioh 1150的单个芯片。
[0099]
图11中用虚线表示附加处理器1115的可选性质。每个处理器1110、1115可以包括本文所描述的处理核中的一个或多个,并且可以是处理器1000的某个版本。
[0100]
存储器1140可以是例如动态随机存取存储器(dram)、相变存储器(pcm)、其它合适的存储器、或这两者的组合。存储器1140可以存储任何适当的数据,例如由处理器1110、1115使用以提供计算机系统1100的功能的数据。例如,与处理器1110、1115执行的程序或访问的文件相关联的数据可以被存储在存储器1140中。在各种实施例中,存储器1140可以存储由处理器1110、1115使用或执行的数据和/或指令序列。
[0101]
在至少一个实施例,控制器集线器1120经由多点总线(multi-drop bus)与(一个或多个)处理器1110、1115通信,该多点总线例如是前端总线(fsb)、诸如quickpath互连(qpi)之类的点对点接口、或类似的连接1195。
[0102]
在一个实施例中,协处理器1145是专用处理器,例如,高吞吐量mic处理器、网络或通信处理器、压缩和/或解压缩引擎、图形处理器、gpgpu、嵌入式处理器等。在一个实施例中,控制器集线器1120可以包括集成图形加速器。
[0103]
在物理资源1110、1115之间在包括架构特性、微架构特性、热特性、功耗特性等的指标度量的范围方面可存在各种差异。
[0104]
在一个实施例中,处理器1110执行控制一般类型的数据处理操作的指令。嵌入在指令内的可以是协处理器指令。处理器1110将这些协处理器指令识别为应该由所附接的协处理器1145执行的类型。因此,处理器1110将这些协处理器指令(或表示协处理器指令的控制信号)发布到协处理器总线或其它互连上,以到协处理器1145。(一个或多个)协处理器1145接受并执行所接收的协处理器指令。
[0105]
图12示出了根据本公开的实施例的第一更具体的示例性系统1200的框图。如图12所示,多处理器系统1200是点对点互连系统,并且包括经由点对点互连1250耦合的第一处理器1270和第二处理器1280。处理器1270和1280中的每一个处理器可以是处理器1000的某个版本。在本公开的一个实施例中,处理器1270和1280分别是处理器1110和1115,而协处理器1238是协处理器1145。在另一个实施例中,处理器1270和1280分别是处理器1110和协处理器1145。
[0106]
处理器1270和1280被示出为分别包括集成存储器控制器(imc)单元1272和1282。处理器1270还包括作为其总线控制器单元的一部分的点对点(p-p)接口1276和1278;类似地,第二处理器1280包括p-p接口1286和1288。处理器1270、1280可以使用p-p接口电路1278、1288经由点对点(p-p)接口1250来交换信息。如图12所示,imc 1272和1282将处理器耦合到相应的存储器(即,存储器1232和存储器1234),这些存储器可以是本地附接到相应处理器的主存储器的一部分。
[0107]
处理器1270、1280可以各自使用点对点接口电路1276、1294、1286、1298经由各个p-p接口1252、1254来与芯片集1290交换信息。芯片集1290可以可选地经由高性能接口1239
来与协处理器1238交换信息。在一个实施例中,协处理器1238是专用处理器,例如,高吞吐量mic处理器、网络或通信处理器、压缩和/或解压缩引擎、图形处理器、gpgpu、嵌入式处理器等。
[0108]
共享缓存(未示出)可以被包括在任一处理器中,或者在两个处理器外部但经由p-p互连与处理器连接,使得在处理器进入低功率模式的情况下,任一或两个处理器的本地缓存信息可以被存储在共享缓存中。
[0109]
芯片集1290可以经由接口1296耦合到第一总线1216。在一个实施例中,第一总线1216可以是外围组件互连(pci)总线,或诸如pci express总线或另一第三代i/o互连总线之类的总线,但本公开的范围不限于此。
[0110]
如图12所示,各种i/o设备1214可以耦合到第一总线1216,以及将第一总线1216耦合到第二总线1220的总线桥1218。在一个实施例中,一个或多个附加处理器1215(例如,协处理器、高吞吐量mic处理器、gpgpu、加速器(例如,图形加速器或数字信号处理(dsp)单元)、现场可编程门阵列、或任何其他处理器)耦合到第一总线1216。在一个实施例中,第二总线1220可以是低引脚数(lpc)总线。在一个实施例中,各种设备可以耦合到第二总线1220,包括,例如键盘和/或鼠标1222、通信设备1227、和诸如磁盘驱动器或其他大容量存储设备之类的存储装置1228(其可以包括指令/代码和数据1230)。此外,音频i/o 1224可以耦合到第二总线1220。注意,本公开预期有其他架构。例如,代替图12的点对点架构,系统可以实现多点(multi-drop)总线或其他这样的架构。
[0111]
图13示出了根据本公开的实施例的第二更具体的示例性系统1300的框图。图12和13中的相似的元件具有相似的附图标记,并且图12中的某些方面已从图13中省略,以避免模糊图13的其他方面。
[0112]
图13示出了处理器1270、1280可以分别包括集成存储器和i/o控制逻辑(“cl”)1272和1282。因此,cl 1272、1282包括集成存储器控制器单元并包括i/o控制逻辑。图13示出了不仅存储器1232、1234耦合到cl 1272、1282,而且i/o设备1314也耦合到控制逻辑1272、1282。传统(legacy)i/o设备1315耦合到芯片集1290。
[0113]
图14示出了根据本公开的实施例的soc 1400的框图。图14中的相似的元件具有相似的附图标记。此外,虚线框是更高级soc上的可选功能。在图14中,(一个或多个)互连单元1402耦合到以下各项:应用处理器1410,其包括一组一个或多个核1002a-n和(一个或多个)共享缓存单元1006;系统代理单元1010;(一个或多个)总线控制器单元1016;(一个或多个)集成存储器控制器单元1014;一组或一个或多个协处理器1420,其可以包括集成图形逻辑、图像处理器、音频处理器和视频处理器;静态随机存取存储器(sram)单元1430;直接存储器存取(dma)单元1432;以及显示单元1440,用于耦合到一个或多个外部显示器。在一个实施例中,(一个或多个)协处理器1420包括专用处理器,例如,网络或通信处理器、压缩和/或解压缩引擎、gpgpu、高吞吐量mic处理器、嵌入式处理器等。
[0114]
在一些情况下,指令转换器可用于将指令从源指令集转换为目标指令集。例如,指令转换器可以转换(例如,使用静态二进制转换,包括动态编译的动态二进制转换)、变形、仿真或以其他方式将指令转换为要由核处理的一个或多个其他指令。指令转换器可以用软件、硬件、固件或其组合来实现。指令转换器可以在处理器上、处理器外或者部分在处理器上、部分在处理器外。
[0115]
图15是根据本公开实施例的对照使用软件指令转换器将源指令集中的二进制指令转换为目标指令集中的二进制指令的框图。在所示实施例中,指令转换器是软件指令转换器,但替代地,指令转换器可以用软件、固件、硬件、或其各种组合来实现。图15示出了采用高级语言1502的程序可以使用x86编译器1504来编译以生成x86二进制代码1506,其可以由具有至少一个x86指令集核的处理器1516本地执行。具有至少一个x86指令集核的处理器1516表示可以通过进行以下操作来执行与具有至少一个x86指令集核的intel处理器基本上相同的功能,从而实现与具有至少一个x86指令集核的intel处理器基本上相同的结果的任何处理器:兼容地执行或以其他方式处理(1)intel x86指令集核的指令集的大部分或者(2)目标为在具有至少一个x86指令集核的intel处理器上运行的应用或其他软件的目标代码版本。x86编译器1504表示可操作以生成x86二进制代码1506(例如,目标代码)的编译器,其中二进制代码可以在具有或不具有附加链接处理的情况下在具有至少一个x86指令集核的处理器1516上被执行。类似地,图15示出了采用高级语言1502的程序可以使用替代指令集编译器1508来编译以生成替代指令集二进制代码1510,该二进制代码可以由没有至少一个x86指令集核的处理器1514(例如,具有执行美国加利福尼亚州桑尼维尔市的mips technologies的mips指令集和/或执行美国加利福尼亚州桑尼维尔市的arm holdings的arm指令集的核的处理器)本地执行。指令转换器1512用于将x86二进制代码1506转换为可由不具有x86指令集核的处理器1514本地执行的代码。该转换后的代码不太可能与替代指令集二进制代码1510相同,因为很难制造出能够实现它的指令转换器;但是,转换后的代码将完成一般操作,并由来自替代指令集的指令组成。因此,指令转换器1512表示通过仿真、模拟、或任何其他过程来允许不具有x86指令集处理器或核的处理器或其他电子设备执行x86二进制代码1506的软件、固件、硬件、或其组合。
[0116]
设计可经过各种阶段,从创建到仿真再到制造。表示设计的数据可按若干种方式来表示设计。首先,正如在仿真中有用的,可利用硬件描述语言(hardware description language,hdl)或者另外的功能性描述语言来表示硬件。此外,在设计过程的一些阶段可产生具有逻辑和/或晶体管门的电路级模型。另外,大多数设计在某个阶段达到表示硬件模型中的各种器件的物理布置的数据的级别。在使用传统的半导体制造技术的情况下,表示硬件模型的数据可以是为用于产生集成电路的掩模指定不同掩模层上的各种特征的存在与否的数据。在一些实现方式中,这种数据可被存储在数据库文件格式中,例如图形数据系统ii(graphic data system ii,gds ii)、开放原图系统交换标准(open artwork system interchange standard,oasis)或者类似的格式。
[0117]
在一些实现方式中,基于软件的硬件模型以及hdl和其他功能性描述语言对象可包括寄存器传送语言(register transfer language,rtl)文件,以及其他示例。这种对象可以是机器可解析的,使得设计工具可接受hdl对象(或模型),针对所描述的硬件的属性解析hdl对象,并且从该对象确定物理电路和/或片上布局。设计工具的输出可用于制造物理器件。例如,设计工具可从hdl对象确定各种硬件和/或固件元件的配置,例如总线宽度、寄存器(包括大小和类型)、存储器块、物理链路路径、结构拓扑以及为了实现在hdl对象中建模的系统将会实现的其他属性。设计工具可包括用于确定片上系统(soc)和其他硬件器件的拓扑和结构配置的工具。在一些情况中,hdl对象可被用作用于开发模型和设计文件的基础,这些模型和设计文件可被制造设备用来制造所描述的硬件。实际上,hdl对象本身可作
为输入被提供到制造系统软件以导致所描述的硬件的制造。
[0118]
在设计的任何表示中,表示设计的数据可被存储在任何形式的机器可读介质中。存储器或者例如盘之类的磁或光存储装置可以是机器可读介质来存储经由光波或电波传输的信息,这些光波或电波被调制或者以其他方式生成来传输这种信息。当指示或携带代码或设计的电载波被传输时,就执行电信号的拷贝、缓冲或重传而言,新的拷贝被做出。从而,通信提供者或网络提供者可在有形机器可读介质上至少临时存储体现本公开的实施例的技术的物品,例如被编码到载波中的信息。
[0119]
在各种实施例中,存储设计的表示的介质可被提供到制造系统(例如,能够制造集成电路和/或有关组件的半导体制造系统)。设计表示可指示系统制造能够执行上文描述的功能的任何组合的设备。例如,设计表示可指示系统关于要制造哪些组件、组件应当如何被耦合在一起、组件应当被放置在设备上的何处和/或关于与要制造的设备有关的其他适当规格。
[0120]
因此,至少一个实施例的一个或多个方面可以通过存储在机器可读介质上的代表性指令来实现,该代表性指令表示处理器内的各种逻辑,当由机器读取时使得机器构造逻辑以执行本文所描述的技术。这种通常被称为“ip核”的表示可以被存储在非暂态有形机器可读介质上,并被提供给各种客户或制造设施,以加载到制造逻辑或处理器的制造机器中。
[0121]
本文公开的机制的实施例可以用硬件、软件、固件或这些实现方式的组合来实现。本公开的实施例可以被实现为在可编程系统上执行的计算机程序或程序代码,这些可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。
[0122]
诸如图12中所示的代码1230之类的程序代码可被应用于输入指令以执行本文所述的功能并生成输出信息。可以用已知方式将输出信息应用于一个或多个输出设备。为了本申请的目的,处理系统包括具有处理器的任何系统,处理器例如数字信号处理器(dsp)、微控制器、专用集成电路(asic)或微处理器。
[0123]
程序代码可以用高级过程或面向对象的编程语言来实现,以与处理系统通信。如果需要,程序代码也可以用汇编或机器语言来实现。实际上,本文描述的机制在范围上不限于任何特定的编程语言。在各种实施例中,语言可以是经编译的或经解析的语言。
[0124]
上述方法、硬件、软件、固件或代码的实施例可以经由存储在机器可访问、机器可读、计算机可访问或计算机可读介质上的指令或代码来实现,这些指令或代码可以由处理元件执行(或以其他方式访问)。机器可访问/可读介质包括以诸如计算机或电子系统的机器可读的形式提供(即,存储和/或发送)信息的任何机制。例如,机器可访问介质包括随机存取存储器(ram)(例如静态ram(sram)或动态ram(dram));只读存储器(rom);磁或光存储介质;闪存设备;电存储设备;光学存储设备;声学存储设备;其他形式的存储设备,用于保持从瞬态(传播)信号(例如,载波、红外信号、数字信号)接收的信息等,这区别于可以从其接收信息的非暂态介质。
[0125]
用于对逻辑进行编程以执行本公开的实施例的指令可以被存储在系统中的存储器内,例如dram、缓存、闪存或其他存储装置。此外,可以经由网络或通过其他计算机可读介质来分发指令。因此,机器可读介质可以包括用于以机器(例如,计算机)可读的形式存储或传输信息的任何机制,但不限于软盘、光盘、紧致盘只读存储器(cd-rom)、磁光盘、只读存储
器(rom)、随机存取存储器(ram)、可擦除可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom)、磁卡或光卡、闪存、或在经由电、光、声或其它形式的传播信号(例如,载波、红外信号、数字信号等)在因特网上传输信息中使用的有形机器可读存储装置。因此,计算机可读介质包括适于以机器(例如计算机)可读的形式存储或传输电子指令或信息的任何类型的有形机器可读介质。
[0126]
任何合适的逻辑可以用于实现各种组件的任何功能,各种组件例如cpu 102、矩阵处理单元104、算术引擎104、存储器106、fma 302、304、406和408、控制模块412、查找表112或410、控制寄存器110、后处理模块414、fpga 700、本文所述的其他组件、或这些组件中任何一个的任何子组件。“逻辑”可以指用于执行一个或多个功能的硬件、固件、软件和/或二者的组合。作为示例,逻辑可以包括与非暂态介质相关联的硬件(例如微控制器或处理器)以存储适于由微控制器或处理器执行的代码。因此,在一个实施例中,对逻辑的引用是指被具体配置为识别和/或执行要保存在非暂态介质上的代码的硬件。此外,在另一实施例中,逻辑的使用是指包括代码的非暂态介质,其特别适于由微控制器执行以执行预定操作。并且可以推断,在又一实施例中,术语逻辑(在该示例中)可以指硬件和非暂态介质的组合。在各种实施例中,逻辑可以包括微处理器或其他处理元件,其可操作以执行软件指令、诸如专用集成电路(asic)的离散逻辑、诸如现场可编程门阵列(fpga)的经编程逻辑设备、包含指令的存储器设备、逻辑设备的组合(例如,在印刷电路板上可以找到的)或其他合适的硬件和/或软件。逻辑可以包括一个或多个门或其他电路组件,其可以由例如晶体管来实现。在一些实施例中,逻辑也可以完全体现为软件。软件可以体现为记录在非暂态计算机可读存储介质上的软件包、代码、指令、指令集和/或数据。固件可以体现为被硬编码(例如,非易失性)在存储器设备中的代码、指令或指令集和/或数据。通常,被分开示出的逻辑边界通常是变化的并可能重叠。例如,第一和第二逻辑可以共享硬件、软件、固件或其组合,同时可能保留一些独立的硬件、软件或固件。
[0127]
对短语“用来”或者“被配置为”的使用在一个实施例中指的是布置、装配、制造、许诺销售、进口和/或设计装置、硬件、逻辑或元件来执行指定或确定的任务。在此示例中,未在操作的装置或其元件仍“被配置为”执行指定的任务,如果它被设计、耦合和/或互连来执行所述指定任务的话。作为纯说明性示例,逻辑门在操作期间可提供0或1。但“被配置为”向时钟提供使能信号的逻辑门并不包括可提供1或0的每一个可能逻辑门。反而,逻辑门是以在操作期间1或0输出会使能时钟的某种方式耦合的那种门。再次注意对术语“被配置为”的使用不要求操作,而是聚焦于装置、硬件和/或元件的潜在状态,其中在潜在状态中,装置、硬件和/或元件被设计为当该装置、硬件和/或元件在操作时执行特定的任务。
[0128]
此外,在一个实施例中对短语“能够”和/或“可操作来”的使用指的是以使能以指定方式使用装置、逻辑、硬件和/或元件的方式设计的某种装置、逻辑、硬件和/或元件。与上文一样要注意在一个实施例中对“用来”、“能够”或者“可操作来”的使用指的是装置、逻辑、硬件和/或元件的潜在状态,其中装置、逻辑、硬件和/或元件未在操作,但按照使能以指定方式使用装置的方式被设计。
[0129]
本文使用的值包括数字、状态、逻辑状态或者二元逻辑状态的任何已知表示。通常,对逻辑电平、逻辑值或逻辑值的使用也被称为1和0,这简单地就是表示二元逻辑状态。例如,1指的是高逻辑电平,0指的是低逻辑电平。在一个实施例中,存储单元,例如晶体管或
闪存单元,可能够保存单个逻辑值或多个逻辑值。然而,使用了计算机系统中的值的其他表示。例如,十进制数字10也可被表示为二进制值1010和十六进制字母a。因此,值包括能够被保存在计算机系统中的信息的任何表示。
[0130]
另外,状态可由值或值的部分来表示。作为示例,第一值,例如逻辑一,可表示默认或初始状态,而第二值,例如逻辑零,可表示非默认状态。此外,术语重置和设置在一个实施例中分别指的是默认的和更新后的值或状态。例如,默认值可能包括高逻辑值,即重置,而更新后的值可能包括低逻辑值,即设置。注意,值的任何组合可被利用来表示任何数目的状态。
[0131]
以下示例涉及根据本说明书的实施例。示例1是一种处理器,包括:存储器,用于存储多个条目,多个条目中的每个条目与输入值范围的一部分相关联,多个条目中的每个条目包括定义幂级数近似的系数集;算术引擎,包括电路,用于:基于确定浮点输入值在输入值范围中与多个条目中的第一条目相关联的一部分内,来选择第一条目;以及通过估算浮点输入值处由第一条目的系数集定义的幂级数近似来计算输出值。
[0132]
示例2可以包括示例1的主题,算术引擎用于:基于确定第二浮点输入值在输入值范围中与多个条目中的第二条目相关联的一部分内,来选择第二条目;以及通过估算第二浮点输入值处由第二条目的系数集定义的幂级数近似来计算第二输出值。
[0133]
示例3可以包括示例1-2中任一项的主题,其中,所估算的幂级数近似为a0+a1x+a2x2,其中x是浮点输入值,并且a0、a1和a2是第一条目的系数集。
[0134]
示例4可以包括示例1-3中任一项的主题,其中,所述范围是多个范围中的第一范围,并且其中,算术引擎用于通过将浮点输入值与多个范围的多个起始值进行比较来确定浮点输入值在第一范围内。
[0135]
示例5可以包括示例4的主题,其中,存储器用于存储第二多个条目,第二多个条目中的每个条目与第二输入值范围的一部分相关联,第二多个条目中的每个条目包括定义幂级数近似的系数集。
[0136]
示例6可以包括示例1-5中任一项的主题,其中,第一条目的选择还基于确定请求指定由算术引擎可执行的多个一元函数中的第一一元函数。
[0137]
示例7可以包括示例6的主题,其中,所述算术引擎用于响应于指定多个一元函数中的第二一元函数的请求而从第二浮点输入中提取尾数;以及针对所提取的尾数而不包括第二浮点输入的指数和符号,估算幂级数近似,其中,幂级数近似由基于第二浮点输入值从存储器中检索的系数定义。
[0138]
示例8可以包括示例1-7中任一项的主题,其中,算术引擎用于确定第二浮点输入值对应于特例并输出对应于特例的值。
[0139]
示例9可以包括示例1-8中任一项的主题,其中,所述范围是与一元函数相关联的多个范围中的第一范围,并且算术引擎用于:确定第二浮点输入在多个范围中的第二范围内;确定第二范围被指定为在常数模式下操作;以及输出与第二范围相关联的常数作为第二输出值。
[0140]
示例10可以包括示例1-9中任一项的主题,其中,所述范围是与一元函数相关联的多个范围中的第一范围,并且算术引擎用于:确定第二浮点输入在多个范围中的第二范围内;确定第二范围被指定为在等同模式下操作;以及输出第二浮点输入作为第二输出值。
[0141]
示例11是一种方法,包括:存储多个条目,多个条目中的每个条目与输入值范围的一部分相关联,多个条目中的每个条目包括定义幂级数近似的系数集;基于确定浮点输入值在输入值范围中与多个条目中的第一条目相关联的一部分内,选择第一条目;通过估算浮点输入值处由第一条目的系数集定义的幂级数近似来计算输出值。
[0142]
示例12可以包括示例11的主题,该方法还包括:基于确定第二浮点输入值在输入值范围中与多个条目的第二条目相关联的一部分内,来选择第二条目;以及通过估算第二浮点输入值处由第二条目的系数集定义的幂级数近似来计算第二输出值。
[0143]
示例13可以包括示例11-12中任一项的主题,其中估算的幂级数近似为a0+a1x+a2x2,其中x是浮点输入值,并且a0、a1和a2是第一条目的系数集。
[0144]
示例14可以包括示例11-13中的任一项的主题,其中,所述范围是多个范围中的第一范围,并且还包括通过将浮点输入值与多个范围的多个起始值进行比较来确定浮点输入值在第一范围内。
[0145]
示例15可以包括示例14的主题,还包括存储第二多个条目,第二多个条目中的每个条目与第二输入值范围的一部分相关联,第二多个条目中的每个条目包括定义幂级数近似的系数集。
[0146]
示例16可以包括示例11-15中任一项的主题,其中,第一条目的选择还基于确定请求指定由算术引擎可执行的多个一元函数中的第一一元函数。
[0147]
示例17可以包括示例16的主题,还包括:响应于指定多个一元函数中的第二一元函数的请求来从第二浮点输入中提取尾数;以及针对所提取的尾数而不包括第二浮点输入的指数和符号,估算幂级数近似,其中,幂级数近似由基于第二浮点数输入检索的系数定义。
[0148]
示例18可以包括示例11-17中任一项的主题,还包括:确定第二浮点输入值对应于特例并且输出对应于特例的值。
[0149]
示例19可以包括示例11-18中任一项的主题,其中,所述范围是与一元函数相关联的多个范围中的第一范围,并且还包括:确定第二浮点输入在多个范围中的第二范围内;确定第二范围被指定为在常数模式下操作;以及输出与第二范围相关联的常数作为第二输出值。
[0150]
示例20可以包括示例11-19中的任一项的主题,其中,所述范围是与一元函数相关联的多个范围中的第一范围,并且还包括:确定第二浮点输入在多个范围中的第二范围内;确定第二范围被指定为在等同模式下操作;以及输出第二浮点输入作为第二输出值。
[0151]
示例21是一种系统,包括:第一存储器,该第一存储器包括用于指定多个一元函数的配置的多个配置寄存器;第二存储器,用于存储与多个一元函数中的第一一元函数相关联的多个条目,多个条目中的每个条目与输入值范围的一部分相关联,多个条目中的每个条目包括定义幂级数近似的系数集;以及算术引擎,用于:基于确定浮点输入值在输入值范围中与多个条目中的第一条目相关联的一部分内,来选择第一条目;并通过估算浮点输入值处由第一条目的系数集定义的幂级数近似来计算输出值。
[0152]
示例22可以包括示例21的主题,其中,第二存储器用于存储与多个一元函数中的第二一元函数相关联的第二多个条目,第二多个条目中的每个条目与第二输入值范围的一部分相关联,第二多个条目中的每个条目包括定义幂级数近似的系数集。
[0153]
示例23可以包括示例21-22中任一项的主题,还包括包含算术引擎的矩阵处理单元。
[0154]
示例24可以包括示例21-23中任一项的主题,其中,算术引擎包括多个融合的乘法加法器以估算幂级数近似。
[0155]
示例25可以包括示例21-24中任一项的主题,还包括:通信地耦合到包括算术引擎的处理器的电池、通信地耦合到处理器的显示器、或者通信地耦合到处理器的网络接口。
[0156]
在整个说明书中对“一个实施例”或“实施例”的引用意味着结合该实施例描述的特定特征、结构或特性被包括在本公开的至少一个实施例中。因此,在整个说明书中各处出现的短语“在一个实施例中”或“在实施例中”不一定都指同一实施例。此外,在一个或多个实施例中,可以以任何合适的方式组合特定的特征、结构或特性。
[0157]
在前述说明书中,参考特定示例性实施例给出了详细描述。然而,将显而易见的是,在不脱离所附权利要求书中所阐述的本公开的更广泛精神和范围的情况下,可以对其进行各种修改和改变。因此,说明书和附图应被认为是说明性的而不是限制性的。此外,实施例和其他示例性语言的前述使用不一定是指相同的实施例或相同的示例,而是可以指不同且独特的实施例以及潜在地相同的实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1