基于XML模板的数据库查询接口引擎的制作方法
本发明涉及信息技术领域,提供了基于xml模板的数据库查询接口引擎。
背景技术:
关系型数据库是各个行业数据资产的重要存储介质,而sql语句又是关系型数据库中数据检索的重要方式。现在的软件的数据检索语句穿插于代码之中,根据各种不同的调用参数形成不同的sql语句,然后发送至数据库进行查询调用。也有类似于在固定的配置文件中编写sql,做到sql与代码分离的效果。不管哪种方式,在目前都没办法能做到修改sql语句即时生效的能力。
本方案提出一种通过xml模板的方式快速构建sql语句的引擎方案,能做到简单的请求参数校验,请求参数语句判断,根据需要构建不同的返回结果,同时可以做到模板随时修改随时生效的能力。
技术实现要素:
本发明的目的在于解决目前都没办法能做到修改sql语句即时生效的问题。
未解决上述技术问题,本发明采用以下技术方案:
基于xml模板的数据库查询接口引擎:
xml模板的说明如下:
步骤s0:定义xml模板的命名规则,以.xml为后缀,名称为查询标识id加上”_”再加上版本号,例如queryuser_v05.xml
步骤s1:xml模板的根节点为<service>,其有三个属性值,分别为id:该查询语句的标识;
type:该查询语句对应的关系型数据库类型,例如oracle、mysql等;
datasource:该检索语句对应的数据源标识。数据源是按照各个数据库连接规则已经预置好的,这些数据库以对象形式缓存在内存。
步骤s2:xml的请求参数节点<request-param>,该节点定义了检索语句所支持的查询参数,其有一个type属性,仅支持一个值”map”(代表参数是一种(k,v)键值对结构)。<service>有且仅有一个<request-param>节点。
步骤s2.1:<request-param>有一个或者多个<entry>子节点,每个<entry>
节点都代表着一个参数定义说明,定义的参数的名称、类型、以及基本的校验条件。
<entry>的属性如下
key-name:参数名称
key-type:参数类型,将会对代入的参数进行校验。仅支持int、long、short、byte、float、double、bool、bigdecimal类型。
nullable:是否可以为空,代表这该参数是否必传,默认为true(必传),如非必传,则设置为false。
步骤s3:xml的sql查询语句节点<select>,它代表着查询语句的整个模块。sql查询语句则按照<service>节点的type属性值所代表的的数据库规则进行编写。
步骤s3.1:sql语句的查询条件与请求参数通过#{}插值对应。在#{}出现的地方,将被#{}中的字段值所替换。#{}中的值就是该查询条件对应的<request-param>中定义的字段名。
步骤s3.2:sql语句中的<须用<![cadata[<]]>或者&|t;代替
步骤s3.3:<select>节点中的<if>节点,代表一个判断。判断条件语句在属性“test”编写,其中
1、test语句基本格式为”操作数”“比较运算符””操作数”;
2、判断条件的比较运算符包括>、<、==、>=、<=、!=;
2、判断条件的逻辑运算符包括and、or;
3、判断条件的优先级运算符包括(、);
<if>节点可以多级嵌套,也可以嵌套<select>;
步骤s4:xml文档的<result-set>是定义返回结构的节点,xml文档有且仅有一个<result-set>节点。该节点有一个type属性,代表返回的结果集类型,其值包括
map:一种(k,v)的键值对结构
array:一种(k,v)键值对结构的数组
步骤s4.1:<entry>节点定义了返回结果集每一个字段的类型、取值方式、返
回的结果类型,其各个属性的含义如下:
key-name:返回字段的名称
value-from:字段值的取值表达式,表示的是从查询结果集中取值的方式。其表达式分为两部分,并且以#分隔,前半部分表示查询结果集的下标,
后半部分表示查询结果集的字段。如果<result-set>的type属性值为”map”,
则表达式必须是带”#”的表达式,如果<result-set>的type属性值
为”array”,则可以不用带“#”。例如o#username,表示从查询结果集数组的第一个元素取username字段值。
实现该功能需要如下步骤:
步骤0:定义模板引擎的调用入口功能parse,其接收到的参数为模板名称a,构建sql语句的参数b(b的结构为为一种k,v的键值对结构)
步骤1:根据a读取模板文件,得到其内容为doc
步骤2:解析doc的<request-param>,验证b的有效性,其验证规则如下
步骤2.1:获取<request-param>的所有<entry>子节点列表entrylist
步骤2.2:遍历entrylist,对entrylist的每个元素temp做如下操作
步骤2.2.1:获取temp的”key-name”属性keyname,获取temp的”value-type”属性valuetype,获取temp的”nullable”属性nullable
步骤2.2.2:从b中获取属性为keyname的值keyvalue
步骤2.2.3:如果nullable为false,并且keyvalue为空,则调用失败,否则继续执行2.2.4。
步骤2.2.4:如果keyvalue的类型不是valuetype,则将b中属性值为keyname的元素删除。
步骤3:解析doc的<select>,构建查询语句sql,其步骤如下:
步骤3.1:创建字符串变量sql;
步骤3.2:获取<select>的每一行内容t;
步骤3.3:如果t是文本或者是cdata,则直接将t与sql拼接;
步骤3.4:如果t是<if>节点,则做如下处理,得到执行结果ifr;
步骤3.4.1:获取t的“test”属性值test,该值其实是一个判断语句;
步骤3.4.2:解析test判断语句,得到语句列表explist,具体步骤如下:
步骤3.4.2.1:将test用空格拆分,得到新数组strarr;
步骤3.4.2.2:遍历strarr,对每一个元素e做如下处理;
步骤3.4.2.3:如果e含有“(”、“)”,则将e拆分成“(”、“)”以及字符串tt,将tt、“(”、“)”按照顺序放入列表explist
步骤3.4.2.4:如果e没有“(”和“)”,则直接将e放入explist
步骤3.4.3:执行explist中的语句,具体步骤如下:
步骤3.4.3.1:创建临时栈stack;
步骤3.4.3.2:遍历explist,得到每一个元素exp;
步骤3.4.3.2:如果exp是”(”,或者逻辑运算符,则将exp压栈;
步骤3.4.3.3:如果exp是”)”,或者exp是explist的最后一个元素,则做如下步骤:
步骤3.4.3.3.1:stack连续出栈三个元素,分别是o1,o2,o3,o1是用于比较的第一个操作数,o2是比较运算符,o3用于比较的第二个操作:
步骤3.4.3.3.2:o1、o2、o3做三元比较操作,得到结果rb;
步骤3.4.3.3.3:如果exp是explist的最后一个元素,且此时stack已空,则返回rb执行结束;否则对stack做出栈操作,再将rb压栈;
步骤3.4.3.3.4:重复3.4.3.3.1至3.4.3.3.3操作,直至stack为空;
步骤3.4.3.4:如果exp是比较运算符,则做如下操作:
步骤3.4.3.4.1:从stack中出栈一个元素ss,从b中取名为ss的元素值ssv;
步骤3.4.3.4.2:从explist中获取exp的下一个元素expn,从b中取名为expn的元素值expnv;
步骤3.4.3.4.3:对ssv、exp、expnv做三元比较运算,得到结果rrb;
步骤3.4.3.4.3:将rrb压栈;
步骤3.4.3.5:如果exp为其他值,则直接压栈stack;
步骤3.5:ifr为”true”,则获取<if>节点的ift,执行如下操作;
步骤3.5.1:如果ift是文本值,则对ift做如下处理后,将ift拼接到sql;
步骤3.5.1.1:如果ift含有#{},则获取{}中的值cd;
步骤3.5.1.2:从b中获取名为cd的元素值cdv;
步骤3.5.1.3:将ift中的#{}插值用cdv代替;
步骤3.5.2:如果ift是<if>节点,则执行步骤3.4;
步骤3.5.2:如果ift是<select>节点,则执行步骤3;
步骤4:获取<service>节点”datasource”属性值ds,从内置数据源映射表中获取名为ds的数据源,执行sql语句得到执行结果sqlresult;
步骤5:获取<result-set>节点的”type”属性值rtype,对sqlresult、rtype做如下操作得到结果returnobj;
步骤5.1:如果<result-set>的type属性rtype值等于”map”,则创建一个(k,v)结构的结果变量rmp,继续如下操作后,返回rmp,rmap就是步骤5中的returnobj;
步骤5.1.1:获取<result-set>的<entry>节点列表entrylist;
步骤5.1.2:遍历entrylist列表,得到每一个元素entryele;
步骤5.1.3:获取entryele的“key-name”属性值kn;
步骤5.1.4:获取entryele的“value-from”属性值vf;
步骤5.1.4.1:将vf用#分隔,得到值index,rfiled;
步骤5.1.4.2:获取sqlresult中第index个元素名为rfiled的值rfiledvv,获取entryele的“value-type”属性值vt,将rfiledvv转换成ct类型,得到结果rfiledv;
步骤5.1.4.3:将kn、rfiledv以(k,v)键值对的形式放入rmp;
步骤5.2:如果rtype值等于”array”,则创建一个(k,v)结构的数组结果变量rar,继续如下操作后,返回rar;
步骤5.2.1:获取<result-set>的<entry>节点列表entrylist;
步骤5.2.2:遍历entrylist列表,得到每一个元素entryele;
步骤5.2.3:获取entryele的“key-name”属性值kn;
步骤5.2.4:获取entryele的“value-from”属性值vf;
步骤5.2.4.1:将vf用#分隔,得到值index,rfiled;
步骤5.2.4.2:获取sqlresult中第index个元素名为rfiled的值rfiledvv,获取entryele的“value-type”属性值vt,将rfiledvv转换成ct类型,得到结果rfiledv;
步骤5.2.4.3:创建(k,v)结构变量m,将kn、rfiledv以(k,v)键值对的形式放入m;
步骤5.2.4.4:将m放入rar,返回rar,rar就是步骤5中的returnobj;
步骤6:将returnobj返回,至此整个调用结束。
因为本发明采用了上述技术方案,因此具备以下有益效果:
1、通过编写xml模板的方式实现数据库查询接口,能够达到快速开发部署的效果,极大的提高了接口的开发效率。由于xml是通过模板引擎即时解析的,所以接口的变更和修改不需要经过传统开发模式的编译打包的操作,在完成接口模板的开发和修改之后可以即时生效,对生产的运行和维护效率是一种极大的提升。
2、天生具备了一定的路由能力,模板中的datasouce属性决定了sql语句发往的数据库,datasource的变更就代表路由的变更。
3、数据总线是这样一种应用:数据总线是将机构内的数据资产(各个数据库)以接口的形式向外输出的应用。其内容包括请求参数封装、字段校验、语句生成、数据路由、数据库调用、结果封装等一系列功能。该方案通过模板引擎的方式一站式解决了数据总线类应用的功能,同时还能做到快速开发,随时部署,7x24小时不停服务的能力。
附图说明
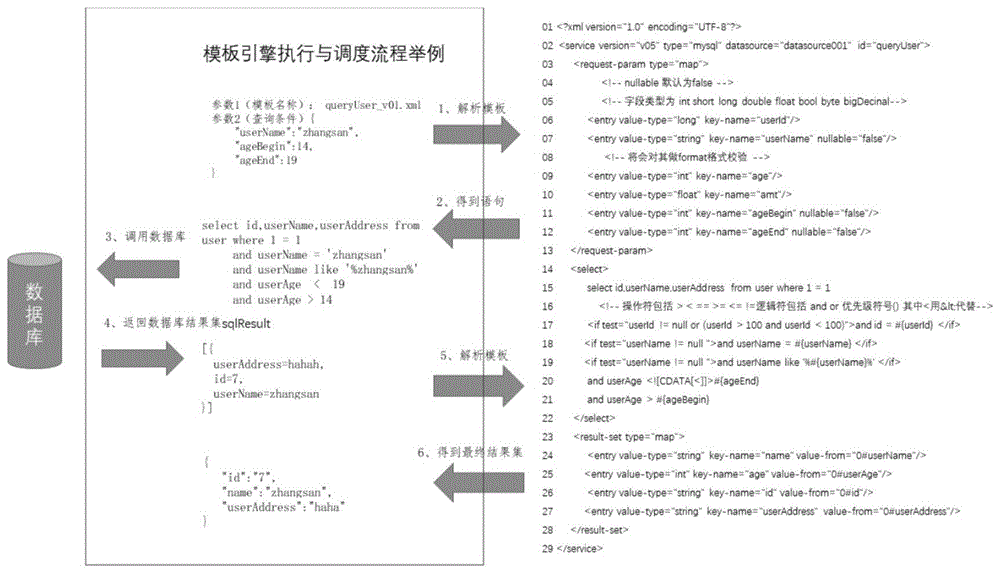
图1为模板引擎执行与调度流程示例图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,术语“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本发明公开了一种基于xml模板的数据库查询接口引擎:
xml模板的说明如下:
步骤s0:定义xml模板的命名规则,以.xml为后缀,名称为查询标识id加上”_”再加上版本号,例如queryuser_v05.xml
步骤s1:xml模板的根节点为<service>,其有三个属性值,分别为
id:该查询语句的标识;
type:该查询语句对应的关系型数据库类型,例如oracle、mysql等;
datasource:该检索语句对应的数据源标识。数据源是按照各个数据库连接规则已经预置好的,这些数据库以对象形式缓存在内存。
步骤s2:xml的请求参数节点<request-param>,该节点定义了检索语句所支持的查询参数,其有一个type属性,仅支持一个值”map”(代表参数是一种(k,v)键值对结构)。<service>有且仅有一个<request-param>节点。
步骤s2.1:<request-param>有一个或者多个<entry>子节点,每个<entry>
节点都代表着一个参数定义说明,定义的参数的名称、类型、以及基本的校验条件。
<entry>的属性如下
key-name:参数名称
key-type:参数类型,将会对代入的参数进行校验。仅支持int、long、short、byte、float、double、bool、bigdecimal类型。
nullable:是否可以为空,代表这该参数是否必传,默认为true(必传),如非必传,则设置为false。
步骤s3:xml的sql查询语句节点<select>,它代表着查询语句的整个模块。sql查询语句则按照<service>节点的type属性值所代表的的数据库规则进行编写。
步骤s3.1:sql语句的查询条件与请求参数通过#{}插值对应。在#{}出现的地方,将被#{}中的字段值所替换。#{}中的值就是该查询条件对应的<request-param>中定义的字段名。
步骤s3.2:sql语句中的<须用<![cadata[<]]>或者&it;代替
步骤s3.3:<select>节点中的<if>节点,代表一个判断。判断条件语句在属性“test”编写,其中
1、test语句基本格式为”操作数”“比较运算符””操作数”;
2、判断条件的比较运算符包括>、<、==、>=、<=、!=
2、判断条件的逻辑运算符包括and、or
3、判断条件的优先级运算符包括(、)
<if>节点可以多级嵌套,也可以嵌套<select>
步骤s4:xml文档的<result-set>是定义返回结构的节点,xml文档有且仅有
一个<result-set>节点。该节点有一个type属性,代表返回的结果集类型,其值包括
map:一种(k,v)的键值对结构
array:一种(k,v)键值对结构的数组
步骤s4.1:<entry>节点定义了返回结果集每一个字段的类型、取值方式、返
回的结果类型,其各个属性的含义如下:
key-name:返回字段的名称
value-from:字段值的取值表达式,表示的是从查询结果集中取值的方式。其表达式分为两部分,并且以#分隔,前半部分表示查询结果集的下标,
后半部分表示查询结果集的字段。如果<result-set>的type属性值为”map”,
则表达式必须是带”#”的表达式,如果<result-set>的type属性值
为”array”,则可以不用带“#”。例如o#username,表示从查询结果集数组的第一个元素取username字段值。
实现该功能需要如下步骤:
步骤0:定义模板引擎的调用入口功能parse,其接收到的参数为模板名称a,构建sql语句的参数b(b的结构为为一种k,v的键值对结构)
步骤1:根据a读取模板文件,得到其内容为doc
步骤2:解析doc的<request-param>,验证b的有效性,其验证规则如下
步骤2.1:获取<request-param>的所有<entry>子节点列表entrylist
步骤2.2:遍历entrylist,对entrylist的每个元素temp做如下操作
步骤2.2.1:获取temp的”key-name”属性keyname,获取temp的”value-type”属性valuetype,获取temp的”nullable”属性nullable
步骤2.2.2:从b中获取属性为keyname的值keyvalue
步骤2.2.3:如果nullable为false,并且keyvalue为空,则调用失败,否则继续执行2.2.4。
步骤2.2.4:如果keyname字段值的类型不是valuetype,则将b中属性值为keyname的元素删除。keyname是这个字段的名称。比如参照图1中第6行,b中有一个名称”userld”的字段,按照xml规则,这个字段值应该是”long”类型。模板引擎在获取到”userld”字段值之后,会检查这个值是否为long类型,如果不是,则将该字段从b中删除。
步骤3:解析doc的<select>,构建查询语句sql,其步骤如下:
步骤3.1:创建字符串变量sql;
步骤3.2:获取<select>的每一行内容t;
步骤3.3:如果t是文本或者是cdata,则直接将t与sql拼接;
步骤3.4:如果t是<if>节点,则做如下处理,得到执行结果ifr;
步骤3.4.1:获取t的“test”属性值test,该值其实是一个判断语句;
步骤3.4.2:解析test判断语句,得到语句列表explist,具体步骤如下:
步骤3.4.2.1:将test用空格拆分,得到新数组strarr;
步骤3.4.2.2:遍历strarr,对每一个元素e做如下处理;
步骤3.4.2.3:如果e含有“(”、“)”,则将e拆分成“(”、“)”以及字符串tt,将tt、“(”、“)”按照顺序放入列表explist
步骤3.4.2.4:如果e没有“(”和“)”,则直接将e放入explist
步骤3.4.3:执行explist中的语句,具体步骤如下:
步骤3.4.3.1:创建临时栈stack;
步骤3.4.3.2:遍历explist,得到每一个元素exp;
步骤3.4.3.2:如果exp是”(”,或者逻辑运算符,则将exp压栈;
步骤3.4.3.3:如果exp是”)”,或者exp是explist的最后一个元素,则做如下步骤:
步骤3.4.3.3.1:stack连续出栈三个元素,分别是o1,o2,o3,o1是用于比较的第一个操作数,o2是比较运算符,o3用于比较的第二个操作:
步骤3.4.3.3.2:o1、o2、o3做三元比较操作,得到结果rb;
步骤3.4.3.3.3:如果exp是explist的最后一个元素,且此时stack已空,则返回rb执行结束;否则对stack做出栈操作,再将rb压栈;
步骤3.4.3.3.4:重复3.4.3.3.1至3.4.3.3.3操作,直至stack为空;
步骤3.4.3.4:如果exp是比较运算符,则做如下操作:
步骤3.4.3.4.1:从stack中出栈一个元素ss,从b中取名为ss的元素值ssv;
步骤3.4.3.4.2:从explist中获取exp的下一个元素expn,从b中取名为expn的元素值expnv;
步骤3.4.3.4.3:对ssv、exp、expnv做三元比较运算,得到结果rrb;
步骤3.4.3.4.3:将rrb压栈;
步骤3.4.3.5:如果exp为其他值,则直接压栈stack;
步骤3.5:ifr为”true”,则获取<if>节点的ift,执行如下操作;
步骤3.5.1:如果ift是文本值,则对ift做如下处理后,将ift拼接到sql;
步骤3.5.1.1:如果ift含有#{},则获取{}中的值cd;
步骤3.5.1.2:从b中获取名为cd的元素值cdv;
步骤3.5.1.3:将ift中的#{}插值用cdv代替;
步骤3.5.2:如果ift是<if>节点,则执行步骤3.4;
步骤3.5.2:如果ift是<select>节点,则执行步骤3;
步骤4:获取<service>节点”datasource”属性值ds,从内置数据源映射表中获取名为ds的数据源,执行sql语句得到执行结果sqlresult;
步骤5:获取<result-set>节点的”type”属性值rtype,对sqlresult、rtype做如下操作得到结果returnobj;
步骤5.1:如果rtype值等于”map”,则创建一个(k,v)结构的结果变量rmp,继续如下操作后,返回rmp,rmap就是步骤5中的returnobj;
步骤5.1.1:获取<result-set>的<entry>节点列表entrylist;
步骤5.1.2:遍历entrylist列表,得到每一个元素entryele;
步骤5.1.3:获取entryele的“key-name”属性值kn;
步骤5.1.4:获取entryele的“value-from”属性值vf;
步骤5.1.4.1:将vf用#分隔,得到值index,rfiled;
步骤5.1.4.2:获取sqlresult中第index个元素名为rfiled的值rfiledvv,获取entryele的“value-type”属性值vt,将rfiledvv转换成ct类型,得到结果rfiledv;
步骤5.1.4.3:将kn、rfiledv以(k,v)键值对的形式放入rmp;
步骤5.2:如果rtype值等于”array”,则创建一个(k,v)结构的数组结果变量rar,继续如下操作后,返回rar;
步骤5.2.1:获取<result-set>的<entry>节点列表entrylist;
步骤5.2.2:遍历entrylist列表,得到每一个元素entryele;
步骤5.2.3:获取entryele的“key-name”属性值kn;
步骤5.2.4:获取entryele的“value-from”属性值vf;
步骤5.2.4.1:将vf用#分隔,得到值index,rfiled;
步骤5.2.4.2:获取sqlresult中第index个元素名为rfiled的值rfiledvv,获取entryele的“value-type”属性值vt,将rfiledvv转换成ct类型,得到结果rfiledv;
步骤5.2.4.3:创建(k,v)结构变量m,将kn、rfiledv以(k,v)键值对的形式放入m;
步骤5.2.4.4:将m放入rar,返回rar,rar就是步骤5中的returnobj;
步骤6:将returnobj返回,至此整个调用结束。
- 还没有人留言评论。精彩留言会获得点赞!