一种基于在线点评数据的商户多视图特征提取及模型构建方法与流程
本发明涉及特征提取和模型构建领域,尤其涉及一种基于在线点评数据的商户多视图特征提取及模型构建方法。
背景技术:
yelp、大众点评、美团等在线点评类软件,在为商户提供宣传平台的同时,也为顾客提供了分享用户体验的平台。这些顾客们提交的评价为其他顾客选择商户提供了重要的参考。研究表明,顾客们在点评软上对商户的评价密切影响着商户的经营绩效。然而,鲜有研究者对这些商户的各类特征进行总结和提取,并基于提取的特征进行预测模型构建。此外,在特征提取时一些研究虽然涉及了语义,但也忽略了不同顾客评价之间的差异性。例如,有些顾客喜欢给几乎所有的商户打高分,而有些顾客则喜欢给低分。个性化的用词习惯也应当被考虑进来,例如,“好”被一些严格的客户用来表达满意情感,而被一些宽松的客户则用其来表达中立情感。除此之外,点评类软件规范的各种业务属性,如信用卡、wi-fi、停车场等,也应当被考虑进特征提取。最后,商户的成败不仅与自身的业务属性有关,也与其所处的商圈的兴盛程度息息相关。
技术实现要素:
为了克服上述现有技术的不足,一种基于在线点评数据的多视图餐厅经营状况预测模型构建方法,可有效解决上述问题。本发明具体采用的技术方案如下:
一种基于在线点评数据的商户多视图特征提取方法,其包括以下步骤:
s1.设定商户集合为lr=(r1;2;…;p),lr中包含p家商户;
s2.提取lr中所有商户的评论,进行预处理并执行词嵌入操作,具体包含以下子步骤:
s21.评论选取与预处理:筛选出t时间前,商户rp中点赞数最高的m条评论,并去除评论中的标点符号与停用词;
s22.构建商户评论矩阵:截取每条评论的前n个字,评论长度不足n的,以0填充至长度n,生成大小为m*n的商户评论矩阵
s23.商户评论矩阵词嵌入操作:使用词嵌入工具glove预训练的d维词向量,对评论矩阵mr进行词嵌入embedding操作,得到词嵌入评论矩阵
s24.构建评论对应评分向量:拼接每条评论对应的评分,生成长度为m的评论对应评分向量vg=(g1;gs;...;gm),其中gm代表第m条评论的评分;
s25.对lr中的所有商户执行s21至s24中的步骤,生成me的集合λe,生成vg的集合λg;
s3.训练用于获取商户语义特征的情感分类神经网络模型,具体包含以下子步骤:
s31.将λe输入至cnn卷积层中,使用μ个不同宽度的卷积核对λe进行卷积操作,过程表示为:
其中
s32.将μ个不同宽度的卷积核卷积生成的
s33.将s32生成的μ个
s34.将oa输入到全连接层中,得到情感分类的结果集合
其中w为可学习参数矩阵,
s35.通过损失函数mse不断迭代λg与
s36.对oa执行reshape变形操作,得到商户语义特征向量集合λs;
s4.商户语义特征权重计算:设某一评论的评分为ηr,收到的点赞数为vr,撰写该评论的顾客总计撰写评论ru条,平均打分为ηu,且该顾客的所有评论共收到点赞数为vu,则以i表示这一评论的权重,计算方法如下:
i=ln((vr+vu/ru)*|ηu-ηr|+1),i∈[0,1);
s5.获取商户语义特征:将λs中每个元素扩展一位,并将对应评论的i填入该空位,则得到附带权重的商户语义特征向量集合λs′;
s6.获取商户业务特征,具体包含以下子步骤:
s61.构建初始商户业务特征向量:将商户rp的所有业务属性整合为业务属性向量vb_origin=(b1;b2;...;bh),其中bh表示第h个业务属性的值,h为业务属性的数量;
s62.对lr中所有的商户执行s61步骤,生成vb_origin的集合λb_origin;
s63.将λb_origin输入至lightgbm模型,输出设置为λy,设定评价指标为交叉熵,当交叉熵最小时停止训练,输出各个业务属性的权重集合,记为ψ;
s64.筛选并排除业务属性中权重值小于阈值κ的业务属性,重新整合筛选后的业务属性形成新业务属性向量vb;
s65.对lr中所有的商户执行s64步骤,生成vb的集合λb;
s7.获取商户集群特征,具体包含以下子步骤:
s71.对商户集合lr,使用密度聚类方法dbscan进行商户聚类,生成商户集群集合λc=(c1;c2;...;cj),其中j为商户集群的数量;
s72.通过各个商户集群中所有商户的评论与签到数量之和,计算商户集群集合的活跃度λe=(e1;e2;...;ej),具体每个集群的活跃度计算表示为:
ej=∑(reviewα+checkinα),αincj
其中review表示商户评论数量,checkin表示商户签到数量;
s8.整合三类特征向量集合,即商户语义特征、商户业务特征、商户集群特征,得到最终的商户多视图特征λ,具体方法如下:
其中
作为优选,步骤中s23所述的预训练的词向量维度d取100。
作为优选,步骤中s31所述的μ个不同宽度l的卷积核,μ取3,宽度l取2、3、5。
作为优选,步骤s35中所述的迭代终止条件为迭代轮次达到10次或者损失函数值小于0.1%。
作为优选,步骤s64中所述的阈值κ取5。
本发明的另一目的在于提供一种基于在线点评数据的多视图商户经营状况预测模型构建方法,其包括以下步骤:
s1.基本变量设定:将lr中80%的商户分割为训练集lr_train,剩余20%分割为测试集lr_test;预测时间段为(t+span),预测开始时间为t;lr中的餐厅在(t+span)时段的真实经营情况表示为集合λy=(y1;y2;...;yp),其中yp的取值为0时,代表餐厅rp在(t+span)时段倒闭,yp的取值为1时代表餐厅rp在(t+span)时段正常经营;
s2.分割训练集与测试集:将λy分割为商户训练集lr_train对应的λy_train与商户测试集lr_test对应的λy_test;
s3.提取多视图特征:按照前述的特征提取方法对lr_train中的商户提取多视图特征得到λtrain,对lr_test中的商户提取多视图特征得到λtest;
s4.训练预测模型:将λtrain输入至lightgbm模型中,输出设置为λy_train,设定评价指标为交叉熵,当交叉熵最小时停止训练,输出模型
作为优选,对预测模型的评价采用指标为接受者操作特征曲线roc曲线与roc曲线下方的面积auc。
本发明提出的商户多视图特征提取及模型构建方法相比于传统的方法,具有如下收益:1、本发明基于在线点评软件如yelp等上的公开数据,与涉及商户经营机密相关的统计数据比具有更好的可获得性;2、本发明方法综合考虑了商户语义特征、商户业务特征和商户集群特征,其中商户的语义特征与一般方法相比特别根据不同评论者的评论习惯进行了权重设置,增加了提取的语义特征的准确性。
附图说明
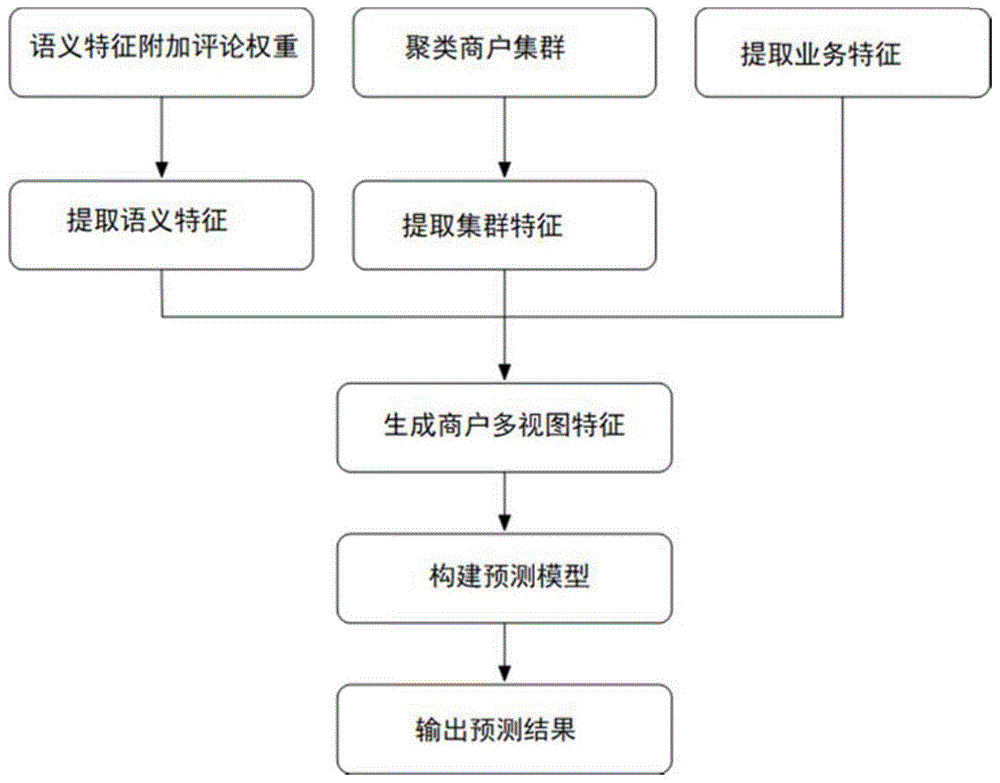
图1为本发明方法的流程图;
图2为本发明训练用于获取商户语义特征的情感分类神经网络模型并提取商户语义特征的示意图;
图3为本发明与对照方法的实验结果对比图;
图4为本发明方法在去除商户语义特征与去除商户集群特征的情况下的实验结果对比图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
如图1所示,一种基于在线点评数据的商户多视图特征提取方法,其特征在于包括以下步骤:
s1.基本变量设定:设商户集合为lr=(r1;r2;...;rp),lr中包含p家商户;
s2.提取lr中所有商户的评论,进行预处理并执行词嵌入操作,具体包含以下子步骤:
s21.评论选取与预处理:筛选出t时间前,商户rp中点赞数最高的m条评论,并去除评论中的标点符号与停用词;
s22.构建商户评论矩阵:截取每条评论的前n个字,评论长度不足n的,以0填充至长度n,生成大小为m*n的商户评论矩阵
s23.商户评论矩阵词嵌入操作:使用词嵌入工具glove预训练的100维词向量,对评论矩阵mr进行词嵌入embedding操作,得到词嵌入评论矩阵
s24.构建评论对应评分向量:拼接每条评论对应的评分,生成长度为m的评论对应评分向量vg=(g1;gs;...;gm),其中gm代表第m条评论的评分;
s25.对lr中的所有商户执行s21至s24中的步骤,生成me的集合λe,生成vg的集合λg;
s3.训练用于获取商户语义特征的情感分类神经网络模型,具体包含以下子步骤:
s31.将λe输入至cnn卷积层中,使用3个不同宽度的卷积核对λe进行卷积操作,过程表示为:
其中
s32.将μ个不同宽度的卷积核卷积生成的
s33.将s32生成的μ个
s34.将oa输入到全连接层中,得到情感分类的结果集合
其中w为可学习参数矩阵,
s35.通过损失函数mse不断迭代λg与
s36.对oa执行reshape变形操作,得到商户语义特征向量集合λs;
s4.商户语义特征权重计算:设某一评论的评分为ηr,收到的点赞数为vr,撰写该评论的顾客总计撰写评论ru条,平均打分为ηu,且该顾客的所有评论共收到点赞数为vu,则以i表示这一评论的权重,计算方法如下:
i=ln((vr+vu/ru)*|ηu-ηr|+1),i∈[0,1);
s5.获取商户语义特征:将λs中每个元素扩展一位,并将对应评论的i填入该空位,则得到附带权重的商户语义特征向量集合λs′;
s6.获取商户业务特征,具体包含以下子步骤:
s61.构建初始商户业务特征向量:将商户rp的所有业务属性整合为业务属性向量vb_origin=(b1;b2;...;bh),其中bh表示第h个业务属性的值,h为业务属性的数量;
s62.对lr中所有的商户执行s61步骤,生成vb_origin的集合λb_origin;
s63.将λb_origin输入至lightgbm模型,输出设置为λy,设定评价指标为交叉熵,当交叉熵最小时停止训练,输出各个业务属性的权重集合,记为ψ;
s64.筛选并排除业务属性中权重值小于阈值5的业务属性,重新整合筛选后的业务属性形成新业务属性向量vb;
s65.对lr中所有的商户执行s64步骤,生成vb的集合λb;
s7.获取商户集群特征,具体包含以下子步骤:
s71.对商户集合lr,使用密度聚类方法dbscan进行商户聚类,生成商户集群集合λc=(c1;c2;...;cj),其中j为商户集群的数量;
s72.通过各个商户集群中所有商户的评论与签到数量之和,计算商户集群集合的活跃度λe=(e1;e2;...;ej),具体每个集群的活跃度计算表示为:
ej=∑(reviewα+checkinα),αincj
其中review表示商户评论数量,checkin表示商户签到数量;
s8.整合三类特征向量集合,即商户语义特征、商户业务特征、商户集群特征,得到最终的商户多视图特征λ,具体方法如下:
其中
一种基于在线点评数据的多视图商户经营状况预测模型构建方法,其特征在于包括以下步骤:
1)基本变量设定:将lr中80%的商户分割为训练集lr_train,剩余20%分割为测试集lr_test;预测时间段为(t+span),预测开始时间为t;lr中的餐厅在(t+span)时段的真实经营情况表示为集合λy=(y1;y2;...;yp),其中yp的取值为0时,代表餐厅rp在(t+span)时段倒闭,yp的取值为1时代表餐厅rp在(t+span)时段正常经营;
2)分割训练集与测试集:将λy分割为商户训练集lr_train对应的λy_train与商户测试集lr_test对应的λy_test;
3)提取多视图特征:按照前述s1~s8提供的特征提取方法对lr_train中的商户提取多视图特征得到λtrain,对lr_test中的商户提取多视图特征得到λtest;
4)训练预测模型:将λtrain输入至lightgbm模型中,输出设置为λy_train,设定评价指标为交叉熵,当交叉熵最小时停止训练,输出模型
5)评价模型预测结果:将λtest输入至模型
下面基于上述方法流程,通过实施例进一步展示其技术效果。
实施例
本实施例步骤与具体实施方式前述步骤相同,在此不再进行赘述。下面就部分实施过程和实施结果进行展示:
本实施例所用的原始数据为yelp的公开数据集,地点为美国拉斯维加斯与加拿大多伦多市。根据相关机构统计,餐饮业对gdp的贡献极高,因此本实施例主要以餐厅为例进行相关实验。通过预处理,关联每个餐厅的经纬度、评论、签到、业务属性;关联每条评论的评论文本、评论时间、评论点赞数量、评论人历史评论量、评论人历史评论获赞量、评论人历史评论平均评分。至此形成许多条餐厅数据σ1=<餐厅编号,经度,维度,评论数量,签到数量,业务属性>,及其对应的评论数据σ2=<评论编号,评论时间,评论文本,评论点赞数量、评论人历史评论量、评论人历史评论获赞量、评论人历史评论平均评分>。将σ1与σ2按照本方法权利要求1所述的方法进行多视图特征的提取,并将特征输入模型中进行训练,最后使用训练好的模型进行结果预测。
实验将本方法(简称sbcm)与若干传统预测方法进行了比较,作为对照的预测方法有:(1)svm:支持向量机是一类对数据进行二元分类的广义线性分类器;(2)xgboost:一种强大的基于增强树的方法,目前广泛应用于数据挖掘领域。实验以接受者操作特征曲线(roc曲线)与roc曲线下方的面积(auc)作为预测准确度指标。
拉斯维加斯与多伦多市的实验结果如图3所示,本发明在两座城市不同年份的预测表现中均取得了最优的结果。本发明在auc的表现上,分别平均比svm和xgboost高出14.0%和3.4%。此外,在四个数据集上的auc结果也表明,本发明的auc浮动范围最小仅为0.05,最为稳定。一般情况下,如果一个模型的auc高于0.7,则认为是一个“公平模型”,而本发明的平均auc为0.78,高于标准。综上,该结果表明本发明提出的方法预测精度(roc、auc)明显优于传统机器学习方法与集成学习相关方法。
此外图4给出了本发明方法在去除商户语义特征与去除商户集群特征的情况下的实验结果对比图,结果表明,商户语义特征和商户集群特征对于预测模型的构建都具有重要的作用。具体来说,本发明在auc方面的表现,分别比本发明不添加商户语义特征和不添加商户集群特征高出8.0%和2.0%。结合以上结果,证明了本发明方法的有效性。
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!