一种基于机器学习的软件味道检测方法与流程
本发明属于计算机软件技术领域,尤其涉及一种基于机器学习的软件味道检测方法。
背景技术:
软件维护是一项在软件产品交付后能够提高其执行效率以及可理解性和可维护性的活动,是在不改变代码外在行为的前提下,对代码做出修改,以改善程序的内部结构。在对一个软件模块实施重构活动之前首先需要确定需要重构的代码模块具体在什么位置,即软件重构点定位。
软件重构点定位是维护活动首先需要解决的问题,定位的质量直接影响后续的重构效果。将重构点称之为“坏味道”(badsmell)。通过软件味道倾向性检测,有助于确定软件重构点位置。
实际工程应用中的复杂软件系统,其重构点数量庞大且类型繁多。依靠人工进行重构点识别分析困难重重,考虑到机器学习在数据分析与挖掘、模式识别等领域的优势,形成基于机器学习的软件味道检测方法。有助于高效、自动的进行软件味道倾向性检测,为软件重构点的确定奠定基础。
技术实现要素:
为了解决上述问题,本发明提出一种基于机器学习的软件味道检测方法,。
一种基于机器学习的软件味道检测方法,包括以下步骤:
步骤1、确定待重构软件代码,选取所述待重构软件参与机器学习的软件代码味道类型;
步骤2、依据待重构软件模块特性,通过软件历史仓库抽取相应的相关软件模块,作为机器学习数据训练的源头;
步骤3、确定抽取的软件模块后,依据软件模块本身特性,选取软件度量指标,并进行标记;
步骤4、确定软件度量指标后,针对不同度量属性进行软件模块度量并标记结果形成分类器:具有代码味道或者不具备代码味道;
步骤5、待重构的新的软件模块选取步骤3中相应的软件度量指标,进行软件度量后并进行数据预处理;
步骤6、使用步骤5中数据预处理后结果,结合步骤4中的分类器,采用机器学习算法选取模型评价指标,并输出软件味道分类结果,为软件代码重构提供依据和定位。
优选的,所述代码味道类型包括但不限于dataclass(数据类)、largeclass(大类)、featureenvy(相恋情节)、longmethod(长函数)。
优选的,所述软件度量指标包括但不限于复杂度、内聚、规模、耦合度。
优选的,所述待重构软件的模块特性分为文件、包、类和函数。
优选的,所述预处理包括但不限于噪音移除、数据归一化、降维。
优选的,所述模型评价指标包括但不限于准确率、查全率、查准率。
本发明的有益效果:
在软件使用维护重构开发背景下,针对工程实践中大型复杂系统软件重构点定位困难问题,结合机器学习和软件味道检测技术,形成基于机器学习的软件味道检测方法,有助于高效、自动识别软件重构点,提高软件维护重构开发的效率,具有较强的工程实用性。
附图说明
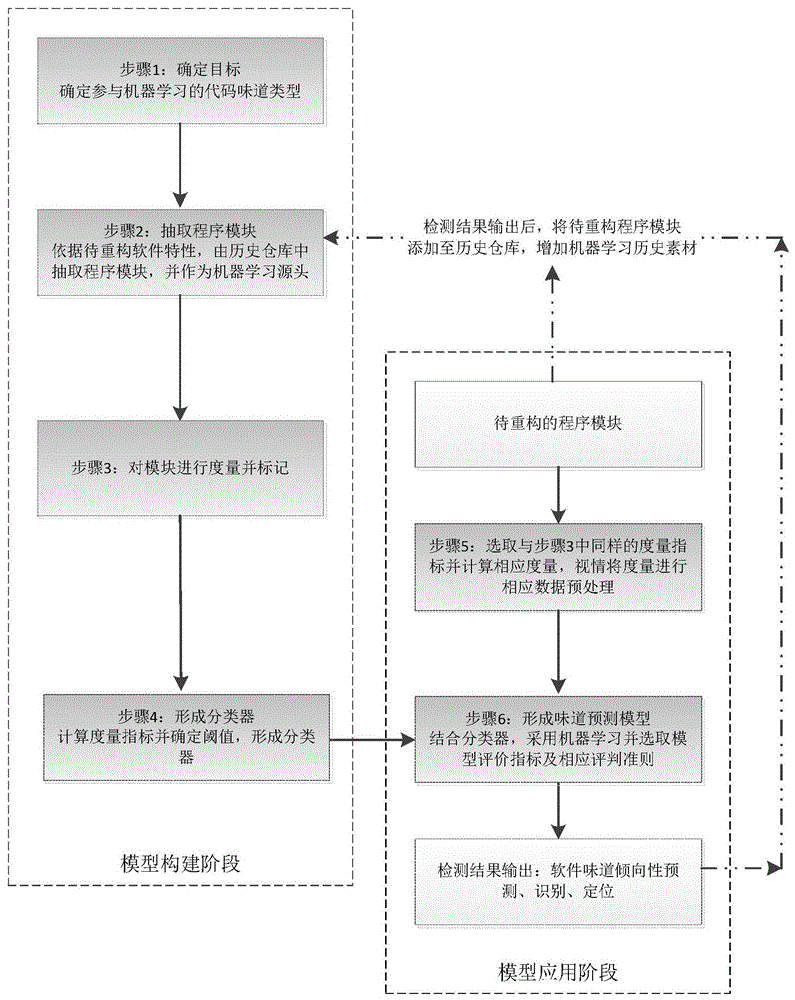
图1为本发明基于机器学习的软件味道检测方法流程示意图。
具体实施方式
现结合附图对本发明作进一步详细说明:
实施例1
本实施例提供一种基于机器学习的软件味道检测方法,包括以下步骤:
步骤1、确定目标(待重构软件代码),选取参与机器学习的代码味道类型,例如dataclass(数据类),largeclass(大类),featureenvy(相恋情节),longmethod(长函数);
步骤2、依据待重构软件模块特性,可以按照软件模块颗粒度:文件、包、类、函数,通过软件历史仓库抽取相应的相关软件模块,作为机器学习数据训练的源头;
步骤3、确定抽取的软件模块后,依据软件模块本身特性,选取合适的度量指标,例如复杂度,内聚,规模,耦合度等并进行标记。如表1所示。
表1代码味道类型及度量属性说明
步骤4、确定软件度量后,针对不同度量属性进行相应计算软件模块度量并标记结果形成分类器:具有代码味道或者不具备代码味道;
步骤5、待重构的新的程序模块选取步骤3中相应的软件度量指标,进行软件度量并视情进行数据预处理:噪音移除、数据归一化、降维等;
步骤6、使用步骤5中数据预处理后结果,结合步骤4中的分类器,采用机器学习算法选取模型评价指标:准确率、查全率、查准率等,输出软件味道分类结果。形成坏味道预测模型,并输出不同软件味道分类结果:待重构的代码具备或者不具备某种代码味道倾向,为代码重构提供依据和定位,定位于所选择的软件模块:文件、包、类、函数等。
实施例2
本实施例提供一种基于机器学习的软件味道检测方法,包括以下步骤:
步骤1中,确定目标(待重构软件代码),选取进行机器学习的代码味道类型,例如dataclass(数据类),largeclass(大类),featureenvy(相恋情节),longmethod(长函数)。
步骤2中,以软件味道倾向性设置检测目标,由软件历史仓库中抽取程序模块。挖掘面向对象软件系统历史仓库,从中提取软件模块。软件模块的粒度按照检测的目标可分为文件、包、类和函数,有助于检测软件味道倾向并定位。
步骤3中,对抽取的程序模块进行度量并标记。其中软件模块的度量属性包括函数、类、包和项目级别,比如复杂度、内聚、规模、耦合度等。
步骤4中,将步骤3中选取的软件度量作为机器学习的特征空间,并确定相应的阈值,具形成分类器:具备某种代码味道倾向或者不具有某种代码味道倾向。
步骤5中,针对待重构的程序模块,选择步骤3中同样的软件度量指标,并计算相应的度量,构建味道检测数据集,并进行数据预处理(噪音移除、数据归一化、降维等);
步骤6中,利用步骤5中味道检测数据集,并结合步骤4中的分类器,选取相应的评价指标:准确率、查准率、查全率等,输出软件味道预测结果,为代码重构提供依据和定位。同时考虑历史数据积累,完成预测后,将待重构代码添加至历史仓库,作为数据训练的素材。
综上所述,本发明在软件使用维护重构开发背景下,针对工程实践中大型复杂系统软件重构点定位困难问题,结合机器学习和软件味道检测技术,形成基于机器学习的软件味道检测方法,有助于高效、自动识别软件重构点,提高软件维护重构开发的效率,具有较强的工程实用性。是一种将机器学习方法与软件味道检测相结合,高效、自动进行程序重构点确定的方法。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!