一种社交电商用户画像的建立方法与流程
本发明涉及数据处理技术领域,具体涉及一种社交电商用户画像的建立方法。
背景技术:
随着社交工具和移动互联网设施的不断完善,社交电商作为一种依托社交关系进行商品交易存在的电商将处于井喷式发展时期。社交电商有别于淘宝等电商平台式运营,社交销售员处于网络零售末端通过社交软件进行交易活动。同时,社交工具软件也有别于传统电商软件,没有对销售员进行统一化注册和管理以及没有对售卖产品进行系统化分类,并且对商品的描述也没有规范化术语。这导致服务商对用户(即社交电商)缺乏全面了解,不能很好地通过用户需求和市场环境对用户提供优质服务,也无法疏导商品流通渠道起到产业路由的作用。因此,如何建立高效为社交电商建立用户画像模型已经成为了业内关注的焦点问题之一.
目前现有的用户画像建立方案多是基于用户在社交网站上的行为信息。然而,此类数据只能反应该用户自身作为买家的兴趣爱好,无法反应该用户作为社交电商卖家时的用户画像。
例如,专利公布号cn106021337a公开了一种智能推荐方法,通过用户在电商应用或信息平台的行为数据进行分析,从而实现商品的推荐。该发明使用的数据相比于社交领域公开的文本信息而言存在滞后性。该数据属性大多偏向用户作为买家时的兴趣爱好,不能很好反应用户作为社交电商角色的用户画像。
例如,专利公布号cn105608171a公开了一种用户画像建立方法,通过用户上网日志与海量知识库进行匹配的方式建立用户画像。此发明用到的上网日志数据对于社交电商的用户画像而言会存在很多的干扰噪声,影响用户画像的建立。
技术实现要素:
鉴于此,本发明的目的在于克服现有技术的不足,提供一种社交电商用户画像的建立方法,进一步减少数据的干扰噪声。
为实现以上目的,本发明采用如下技术方案:
一种社交电商用户画像的建立方法,包括以下步骤:
步骤s1:在中文语料库中进行自监督训练得到预训练模型;
步骤s2:对社交电商公开文本数据集预处理后进行分类标注;
步骤s3:将预训练模型在类别标注完成的数据集上进行微调训练,得到用户画像模型。
在上述的一种社交电商用户画像的建立方法中,s2所述的公开文本数据集预处理为通过正则表达式删除文本中的表情、数字、空格和制表符。
在上述的一种社交电商用户画像的建立方法中,s1所述对中文语料库的预训练是基于transformer的双向神经网络模型在中文语料库中进行自监督学习。
在上述的一种社交电商用户画像的建立方法中,s1中的中文语料库选用数据由通用领域公开文本和社交电商领域专业文本组成。
在上述的一种社交电商用户画像的建立方法中,s1中对中文语料库预训练后参照bert进行token序列化,将token序列化的结果输入模型进行预训练。
在上述的一种社交电商用户画像的建立方法中,s1中预训练所进行的是对社交电商专业语料库的遮掩词预测和/或通用语料库的遮掩测预测和/或通用语料库的前后文预测。
在上述的一种社交电商用户画像的建立方法中,s3所述分类微调是对分类标注后的数据进行token序列化,将第一个token对应的最终应参状态以向量的形式输入值全连接层,再经过softmax层得到的数值定义为该条文本数据对应各类标签的归一化概率。
在上述的一种社交电商用户画像的建立方法中,s2的标注分类阶段,至少两人对每条数据进行标注,最终选取所有人标注相同的数据为本次实验数据集,否则重新进行标注直到相同为止。
通过对于语料库的预训练排除多余的噪声干扰,提高数据整合的精确度,提升用户画像建立的精准度。
附图说明
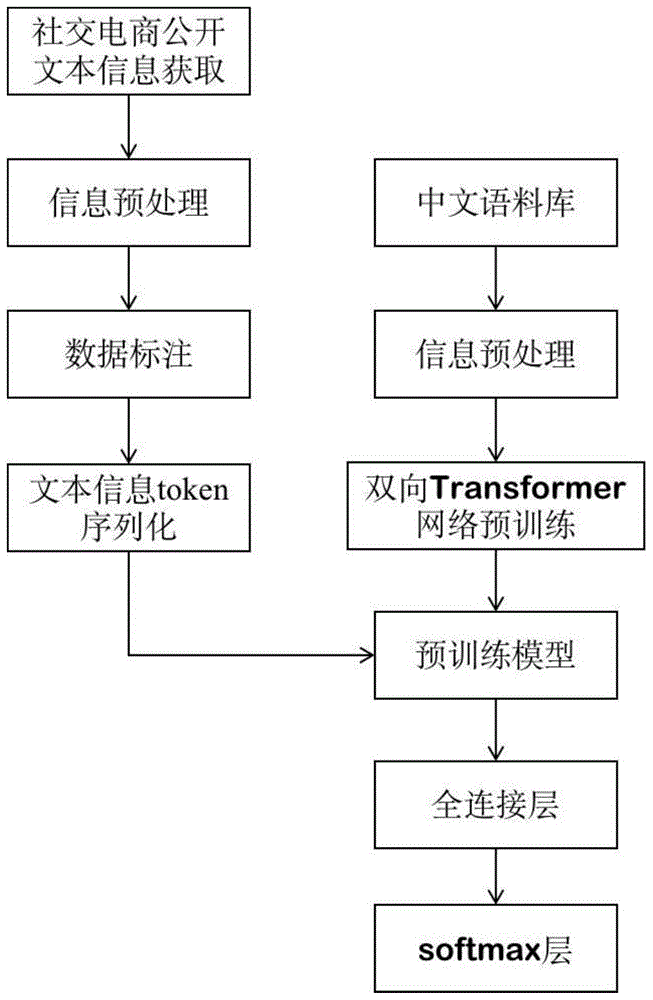
图1:本发明一实施例提供的一种社交电商用户画像的建立方法的流程示意图;
图2:数据预处理流程
图3:文本数据标记示例
图4:数据标注流程示意图
图5:预训练模型示意图
图6:文本信息token序列化示意图
图7:文本分类bert微调模型结构图
具体实施方式
以下采用本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
步骤s1:在中文语料库中进行自监督训练得到预训练模型。s1所述对中文语料库的预训练是基于transformer的双向神经网络模型在中文语料库中进行自监督学习。s1中的中文语料库选用数据由wiki中文百科、搜狐新闻、网易新闻和社交电商领域专业文本组成。s1中对中文语料库预训练后参照bert进行token序列化,将token序列化的结果输入模型进行预训练。s1中预训练所进行的是对社交电商专业语料库的遮掩词预测和/或通用语料库的遮掩测预测和/或通用语料库的前后文预测。一般来说s1预训练过程都会有两个任务,一个是遮掩词预测,另一个是与前后句预测相类似的两种任务。一般这两个任务都会要做。但是对于社交电商公开文本内容而言,更适合做第一个,所以本发明在对社交电商专业领域文本做预训练时可以选择性的只做任务一,可以根据不同的场景进行适应性的改进。作为优选地,实际预训练时,可以选择性的对社交电商专业语料库只做遮掩词预测,而通用语料库既要进行遮掩词预测也要进行前后文本预测。
步骤s2:对社交电商公开文本数据集预处理后进行分类标注。s2所述的公开文本数据集预处理为通过正则表达式删除文本中的表情、数字、空格和制表符。s2的标注分类阶段,至少两人对每条数据进行标注,最终选取所有人标注相同的数据为本次实验数据集,否则重新进行标注直到相同为止。
步骤s3:将预训练模型在类别标注完成的数据集上进行微调训练,得到用户画像模型。s3所述分类微调是对分类标注后的数据进行token序列化,将第一个token对应的最终应参状态以向量的形式输入值全连接层,再经过softmax层得到的数值定义为该条文本数据对应各类标签的归一化概率。s3中的保存方式以“标签+tab+文本信息”的进行标注保存。
本发明先在大规模中文语料库上进行预训练,然后用标注完成的社交电商公开社交本文信息进行分类微调,以达到按社交电商所售卖产品属性的不同建立用户画像的目的。本发明方法流程示意图如图1所示。
本发明按照社交电商售卖商品属性的不同对其公开社交文本内容进行分类标注,标签包括:电子产品、服饰、食品、汽车、房产、美容、美妆个护、培训、首饰、推广、医药保健、话费充值、金融、卡类、香烟、杂文、加粉软件、旅游、书画其他等,共计20类。
本发明文本信息预处理是通过正则表达式以unicode编码查询的方式删除文本中的emoji表情、数字、空格和制表符。其中,emoji表情主要描述情绪方面信息,数字主要描述商品的份数、价格和尺寸,这些内容在以商品特征属性对社交电商建立用户画像时为数据噪声,空格和制表符亦是如此。数据预处理流程如图2所示。
本发明使用的微调数据以“标签+tab+文本信息”的形式进行标注保存。标注形式如图3所示。
在数据标注阶段,三名社交电商领域资深研究人员同时对每条数据进行标注,最终选取三人标注部分相同的数据为本次的实验数据集。数据标注流程示意图如图4所示。
本发明的模型训练采用预训练加微调的迁移学习方式。预训练阶段选用基于transformer的双向神经网络模型在中文语料库中进行自监督学习。模型示意图如图5所示。
transformer作为一种基于注意力机制的encoder-decoder模型,解决了rnn无法处理长距离依赖和模型无法并行的问题,在提升模型性能的同时不丧失准确性。预训练时选用的数据为wiki中文百科、搜狐新闻、网易新闻等通用文本和社交电商领域专业文本组成的语料库。语料库中的文本经上述方法预处理后参照谷歌提出的bert进行token序列化,将token序列化后结果输入模型进行预训练。文本token序列化示意图如图6所示。在第一个句首增加一个特殊的tokencls,在句尾增加tokensep表示句子结束。
预训练阶段进行的任务为语料库的遮掩词预测和前后文本预测,任务执行参数参照谷歌提出的bert模型的预训练流程。其中,在对wiki中文百科、搜狐新闻、网易新闻等通用语料库进行预训练时,采用遮掩词预测和前后文本预测两种任务相结合的形式;而在对社交电商领域相关语料库进行预训练时任务仅执行遮掩词预测任务。这部分区别是因为考虑到社交电商领域文本多由单一句子组成,不适合执行与上下文有关的任务,如前后文本预测等。
模型预训练完成后进入微调阶段。微调阶段使用的数据集为标注完成的数据。该数据集按照和预训练阶段同样的方式进行token序列化。然后,将第一个token[cls]对应的最终隐藏状态以向量形式输入至全连接层,再经过softmax层得到的数值定义为该条文本数据对应各类标签的归一化概率。模型微调结构示意图如7所示。
我们选取38981条数据,按照6:4比例划分为训练集和验证集,即训练集23,388条,验证集15,593条。实验结果表明,本发明文本分类准确率为96.22%。结果如下表所示.
此外,我们额外选取了9542条社交电商的公开社交文本数据对此模型进行测试,模型准确率依然高达90.3%。因此,本发明可以通过对社交电商公开的社交文本内容分类的形式建立社交电商的用户画像,为信息服务商实现产业路由功能提供技术支撑。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!