一种医疗机器人手术视频运动放大方法与流程
本发明属于医疗机器人领域,特别涉及一种医疗机器人手术视频运动放大方法。
背景技术:
现有的微创外科手术因其恢复快,并发症少等特点,已经代替传统的开腔手术成为主流的手术方式之一。但微创外科手术也存在一些缺陷。在传统开腔手术中,医生能够凭借视觉和触觉感知来定位手术环境中的神经血管束。然而在微创外科手术中医生无法使用触觉感知手术环境中的神经血管束,而仅凭肉眼又无法定位内窥镜视频中的神经血管束,因此在微创外科手术的过程中易误伤神经血管束。虽然传统的一些介入性成像方法可以在微创外科手术中帮助医生定位血管,比如超声与荧光造影,但这些方法不仅在手术室中增加了额外且复杂的配置,而且由于信号的不足不能达到良好的定位效果。
现有的视频放大技术中比较主流的是欧拉运动放大法。欧拉运动放大法将视频运动(即脉动)放大分解为三个过程。首先,将视频(originalvideo)的每一帧进行一个空间分解,获取运动表达(motionrepresentation);其次,对所有运动表达的相同位置组成的信号进行时域滤波处理,提出感兴趣频率的运动分量(motioncomponent);最后,将感兴趣频率分量进行放大并结合到运动表达中,将放大之后的运动表达重组为运动放大后的视频(magnifiedvideo)。
对于空间分解,有学者通过拉普拉斯金字塔(laplacianpyramid)进行空间分解,该方法通过基于强度值的分解方式,直接放大强度值来进行运动放大,造成放大视频中出现许多的噪声和失真。还有学者通过复值可操纵金字塔(complexsteerablepyramid)进行空间分解,将每一帧分解为基于相位的运动表达,即通过相位的变化来表示运动,之后放大相位信号以放大运动。比起基于强度值的方法,基于相位的方法能够有效的减少噪声和失真,但是会引入较多的伪影。此外还有专家使用基于深度学习的分解方式,通过神经网络(neuralnetwork)对视频帧进行分解。该方法通过神经网络对训练数据的学习,使得分解出来的运动表达能够较好的表示视频中存在的运动,因此不会产生噪声与伪影。
对于时域滤波,通常所使用的都是带通滤波bp(bandpassfiltering),该滤波能够较好的提取信号中某个感兴趣频率的分量。但是由于其基于傅立叶变换,所提取的分量是纯正弦波的形式,所以在手术视频运动放大的应用中其提取的分量丢失了原脉动的特征。有人分析了脉动的特征,提出高斯三阶导滤波或者说第三阶高斯滤波tog(third-ordergaussianfiltering)来提取信号中的脉动分量,该滤波提取的分量能够突出脉动的特征,使得放大之后的内镜视频中血管的脉动与原视频一致。但是该方法在非脉动位置会引入额外的噪声。
技术实现要素:
针对上述问题,本发明提供一种医疗机器人手术视频运动放大方法。
一种医疗机器人手术视频运动放大方法,包括步骤:
a、对输入视频的所有帧{f1,f2…fn}进行空间分解,得到纹理的数据集合{s1,s2…sn}和形状的数据集合{r1,r2…rn},n为大于1的正整数;
b、对所述形状的数据集合{r1,r2…rn}进行混合时域滤波处理;
c、对通过所述步骤b得到的数据集合进行放大并重组视频。
进一步,
在所述步骤a中,每一个所述帧fi均分解为对应的纹理数据si和形状数据ri,1≤i≤n。
进一步,
在所述步骤a中,通过神经网络算法对所述输入视频的所有帧{f1,f2…fn}进行所述空间分解。
进一步,
设所述形状三维数据集合{r1,r2…rn}对应的等价信号为i(x,t),x为所述的所有帧{f1,f2…fn}所对应的像素位置,t为时间变量,则所述步骤b包括步骤:
b1、对所述信号i(x,t)通过带通滤波进行运动分量的提取,提取到的带通滤波运动分量为ibp(x,t);
b2、对所述信号i(x,t)通过第三阶高斯滤波进行运动分量的提取,提取到的高斯三阶导滤波运动分量为itog(x,t);
b3、对所述带通滤波运动分量ibp(x,t)和高斯三阶导滤波运动分量itog(x,t)进行组合,获得所述混合时域滤波处理的结果iht(x,t)。
进一步,
所述步骤b1包括:
对于所述信号i(x,t)进行傅立叶变换,得到信号i(x,t)的频谱图;
筛选出所述频谱图中感兴趣的脉动频率所对应的运动分量;
将筛选出的所述运动分量进行逆傅立叶变换,得到所述带通滤波运动分量ibp(x,t)。
进一步,
所述步骤b2包括:
通过高斯三阶导卷积核对所述信号i(x,t)进行卷积操作,如下面公式所示:
其中,itog(x,t)为所述高斯三阶导滤波运动分量,
进一步,
所述步骤b3包括:
对所述带通滤波运动分量ibp(x,t)和高斯三阶导滤波运动分量itog(x,t)进行如下式处理:
其中,iht(x,t)为混合时域滤波运动分量,|x|为对x取绝对值,sign(x)为符号函数,所述混合时域滤波运动分量iht(x,t)对应的数据集合为
进一步,
所述步骤c中的放大处理为:
其中,
进一步,
所述步骤c中的重组视频处理包括:
将所述运动表达集合
进一步,
通过神经网络算法实现所述运动表达集合
本发明的医疗机器人手术视频运动放大方法基于视频运动放大的手术视觉增强全新算法,放大了手术视频中神经血管束的脉动。通过所述视频运动放大算法,医生可以较为容易地通过肉眼观察获悉神经血管束的位置,从而避免在手术的过程中误伤神经血管束。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所指出的结构来实现和获得。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示出了根据本发明实施例的方法流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地说明,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
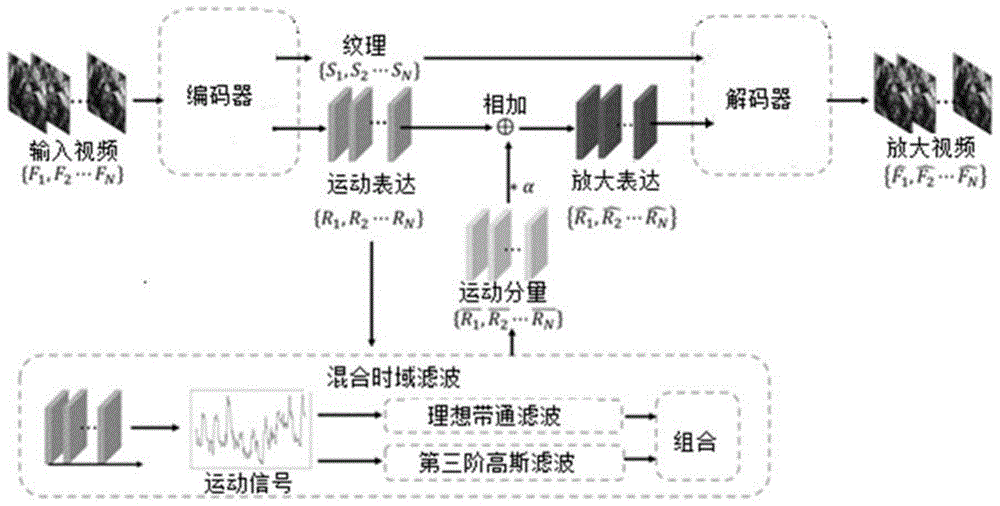
图1所示为本发明提出的医疗机器人手术视频运动放大方法的流程图。本发明的医疗机器人手术视频运动放大方法基于欧拉运动放大,主要包括三个步骤:基于深度学习的空间分解,混合时域滤波,放大运动分量并重组视频。
参见图1,本发明的医疗机器人手术视频运动放大方法,包括如下各步骤:
一、基于深度学习的空间分解
输入视频(inputvideo)的所有帧用{f1,f2…fn}来表示,n为正整数,表示所述医疗机器人手术视频运动放大方法一次所处理的帧的数量。输入视频的所有帧首先都经过一个神经网络编码器(encoder)进行空间分解,每一个视频帧fi(1≤i≤n)均分解为纹理(texture)和形态(shape)两部分数据。与各帧{f1,f2…fn}一一对应的纹理数据集合和形状的数据集合分别为{s1,s2…sn}和{r1,r2…rn}。所述视频帧的纹理数据包含了对应的视频帧的强度信息。而视频帧的形态代表了对应的视频帧的运动信息。
二、混合时域滤波(hybridtemporalfiltering)
在进行所述空间分解之后,对于运动表达(motionrepresentations)下的每一个像素位置对应的信号(以下称为运动信号)都进行时域滤波的处理,以提取出感兴趣的脉动分量或者说运动分量。设在运动表达下,某个像素位置x处的运动信号为i(x,t),t为时间变量,i(x,t)等价于数据集合{r1,r2…rn}。所述运动信号表达了输入视频中有脉动的像素位置的运动信息。
本发明提出采用像素级的混合时域滤波的方法来提取所述运动信号中的分量,包括两个步骤:
(1)对信号i(x,t)使用理想带通滤波(idealbandpassfiltering)即理想bp和第三阶高斯滤波tog分别进行运动分量的提取,所提取到的运动分量用ibp(x,t)和itog(x,t)表示。
(2)对理想bp和tog提取的运动分量进行组合,获得混合时域滤波的结果iht(x,t)。
在步骤(1)中,通过理想bp基于傅立叶变换提取运动分量。首先,对于信号i(x,t)进行傅立叶变换,得到信号i(x,t)的频谱图;其次,筛选出频谱图中感兴趣的脉动频率所对应的运动分量;最后,将经过筛选处理后的频谱图通过逆傅立叶变换,得到所需要的带通滤波运动分量ibp(x,t)。由于在手术环境中存在许多呼吸等频率较低的运动,因此只有对足够的视频帧进行bp处理,才能准确的提取信号中的感兴趣频率的分量,一般需要处理50-500帧的视频帧,优选处理200帧的视频帧。
通过tog提取运动分量的过程是通过高斯三阶导卷积核对信号i(x,t)进行卷积操作,如下面公式所示:
其中,itog(x,t)为高斯三阶导滤波运动分量,
在步骤(2)中,tog提取的运动分量,可以突出脉动的特征,使得放大之后的脉动信号与原视频保持一致。但是tog会引入额外的噪声,特别是在非脉动位置,噪声就比较明显。我们观察到理想bp所提取的运动分量在相同的脉动位置与tog所提取的运动分量大小一致,而在非脉动位置又不会引入额外的噪声。因此,通过理想bp得到的带通滤波运动分量ibp(x,t)来约束tog所提取到的高斯三阶导滤波运动分量itog(x,t),就能使得在脉动位置提取的运动分量保持不变,同时减少了非脉动位置提取的分量的噪声。本步骤中通过一个简单的公式来实现利用理想bp对tog进行约束,即实现对理想bp和tog的结合(combine),如下式所示:
其中,iht(x,t)为混合时域滤波运动分量,|x|为对x取绝对值,sign()为符号函数。当所有像素位置的信号都提取出感兴趣的运动分量之后,就得到运动分量的数据集合
三、放大运动分量并重组视频
经过步骤二的混合时域滤波处理之后,得到感兴趣频率的运动分量的数据集合
其中,
最后,类似于空间分解,通过神经网络的解码器(decoder)将放大表达的数据集合
本发明将基于深度学习的空间分解方式与所提出的混合时域滤波相结合,得到手术视频脉动信号放大全新算法。比起基于强度值与基于相位的空间分解方式,基于深度学习的空间分解方式能有效的减少噪声与伪影。比起带通滤波与高斯三阶导滤波,本发明所提出的混合时域滤波在手术视频脉动放大的应用中能起到更好的效果。对于脉动位置,其放大的效果能够与tog一样突出脉动的特征,而在非脉动位置,其又能像bp一样不引入额外的噪声。
尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!