基于多任务卷积神经网络的人脸识别及属性分类方法与流程
本发明涉及计算机视觉技术,具体涉及一种基于多任务卷积神经网络的人脸识别及属性分类方法。
背景技术:
人脸识别是一种基于计算机的生物特征识别技术,与指纹识别、虹膜识别、声纹识别等其它生物特征识别技术的共同特点是用来识别的特征都是唯、并且不容易发生变化,可保证信息的不易伪造和不易混淆。人脸识别具有贴近人脸的视觉感知且容易获取并可以进行事后的检索等特点,因此已经广泛应用在安防监控、网上支付、门禁考勤等各个领域。属性作为识别目标的中间层表示,它提供了介于低维特征和高维标签之间的一个抽象功能。当人脸因为不同角度光照等外在元素产生大幅度变化时,许多人脸属性却并没有受到影响,因此通过提取人脸属性中不容易变化的语义信息,能提升人脸识别的准确率,同时人脸特征中所包含的全局信息与身份信息,也能进一步提升属性识别的准确率。
深度神经网络在人脸识别任务和属性分类任务上都达到了极高的准确率,但却很难设计一个多任务网络同时进行这两个任务,这其中最大的难点就是如何将人脸特征与属性特征进行融合。目前基于深度学习的多任务融合方式主要有两种,分别为基于聚合的方法和基于子空间学习的方法。
基于聚合的方法是利用网络提取属性特征和身份鉴别特征,然后在特征层面上进行简单连接。该方法往往要限定聚合的特征具有相同的维度,再进行元素求平均或者相乘的操作,得到融合后的特征。基于子空间学习的方法是将这两种特征串联起来,再将串联后的特征映射到一个更适合的子空间,然后采用相关算法来学习映射的参数。神经网络中经常使用全连接层来进行映射,全连接的参数则由模型的损失通过梯度下降算法进行优化。
这两种方法将属性特征与人脸特征进行融合后直接进行人脸识别任务,都没考虑到人脸特征所包含的身份信息对属性分类任务的帮助。同时人脸的属性相差很大,从局部特征(比如:嘴巴大小)到整体特征(比如:性别)与人脸识别任务的相关性显然并不一致。这两种方法对各个属性以等权重的方式融合进人脸识别任务中,会加入不少与任务无关的噪音,让模型难以同时在多个任务上达到较高精确度。
技术实现要素:
本发明所要解决的技术问题是:提出一种基于多任务卷积神经网络的人脸识别及属性分类方法,在人脸识别任务和属性分类任务上同时达到较高的精确度。
本发明解决上述技术问题采用的技术方案是:
基于多任务卷积神经网络的人脸识别及属性分类方法,包括以下步骤:
s1、对人脸图像样本进行预处理;
s2、通过设计的多任务卷积神经网络模型对预处理后的人脸图像样本提取出属性特征和人脸全局特征;
s3、基于注意力机制计算不同属性与人脸识别任务的相关度,并根据相关度将属性特征融合进人脸特征中;
s4、多任务卷积神经网络模型同时进行人脸识别任务和属性分类任务,并通过计算损失来训练优化模型;
s5、利用优化后的模型对输入的人脸图像同时进行属性分类和人脸识别任务。
作为进一步优化,步骤s1具体包括:
s11、获取人脸图像样本数据集;
s12、对人脸图像样本数据集中的人脸图像样本进行人脸属性和身份的标注;
s13、将标注后的人脸图像样本按照比例划分为训练数据集和验证数据集;
s14、对所有的人脸图像样本进行人脸检测和对齐,并设置统一大小。
作为进一步优化,步骤s2中,所述设计的多任务卷积神经网络模型包括基础特征提取层、与基础特征提取层的输出连接的多个属性分类子模型和一个人脸识别子模型、与各个属性分类子模型的输出连接的注意力结构,与所述注意力结构的输出和人脸识别子模型的输出均连接的全连接层。
作为进一步优化,步骤s2具体包括:
s21、对于输入的每一张人脸图像样本,通过模型的基础特征层提取到其基础特征;
s22、提取得到基础特征后,通过各个子模型学习相应的任务;
s23、通过计算感受野的方式得到不同尺度的人脸全局特征,并将这些特征通过串联方式嵌入到属性分类子模型中,为其提供额外的全局信息与身份信息;
s24、获得属性分类子模型输出的属性特征ai和人脸识别子模型输出的人脸全局特征f。
作为进一步优化,步骤s3具体包括:
s31、初始化多任务卷积神经网络模型的模型参数wi与全连接层fc;
s32、对获得的所有的属性特征ai都进行映射和归一化操作:vi=norm(ai*wi),并初始化属性特征ai与人脸全局特征f的关系度bi=0;
s33、通过关系度bi计算属性特征与人脸全局特征的耦合系数:
s34、融合属性特征与人脸特征:u=concatenate(s,f),并通过全连接映射变换得到包含属性特征中语义信息的人脸特征:fs=fc(u);
s35、对所有的属性特征,计算人脸特征与其相似度,并更新关系度,bi=bi+dot(vi,fs),dot表示点乘操作;
s36、重复执行步骤s33-s35共n次,获得不同人脸属性对于人脸全局特征的权重和最终包含相关语义信息的人脸特征,其中n为模型总共进行的任务数。
作为进一步优化,步骤s4中,所述通过计算损失来训练优化模型,具体包括:
(1)采用交叉熵损失函数来计算属性分类任务的损失:
yj表示样本j在属性i上所属于标签,分别用0和1表示负类和正类,y′j则表示模型在该处预测为正类的可能性,范围在0-1之间,其值越大,可能性就越大;
通过对所有的属性分类任务的损失进行相加,获得人脸属性分类任务的总体损失:
其中,k为属性分类任务的数量;
(2)采用三元组损失函数计算人脸识别任务的损失,该函数通过同时最小化anchor和positive之间的距离并且最大化anchor和negative之间的距离来进行优化,公式为:
其中,α为一个超参数,取值0.2;
(3)多任务卷积神经网络模型最终的损失函数如下:
l=λ×la+lf
λ是一个超参数,取值0.4;
(4)基于最终的损失函数采用梯度下降算法对模型进行优化。
本发明的有益效果是:
将具有不同感受野大小的人脸全局特征融合属性分类子模型中,通过为其提供人脸全局信息与身份信息来提高属性分类的准确率,在得到属性特征后,再通过一个注意力结构自适应计算不同属性与人脸识别任务的相关性来将更为有效的语义信息提供给人脸识别子模型;
基于此方案,本发明能很好的解决人脸识别模型与属性分类模型特征交互不够和不同属性与人脸识别任务的相关性不一致的问题。本发明提出的多任务模型不仅能同时输出人脸识别和属性分类结果,还充分利用它们之间的相关性,互相提升了其准确率。
附图说明
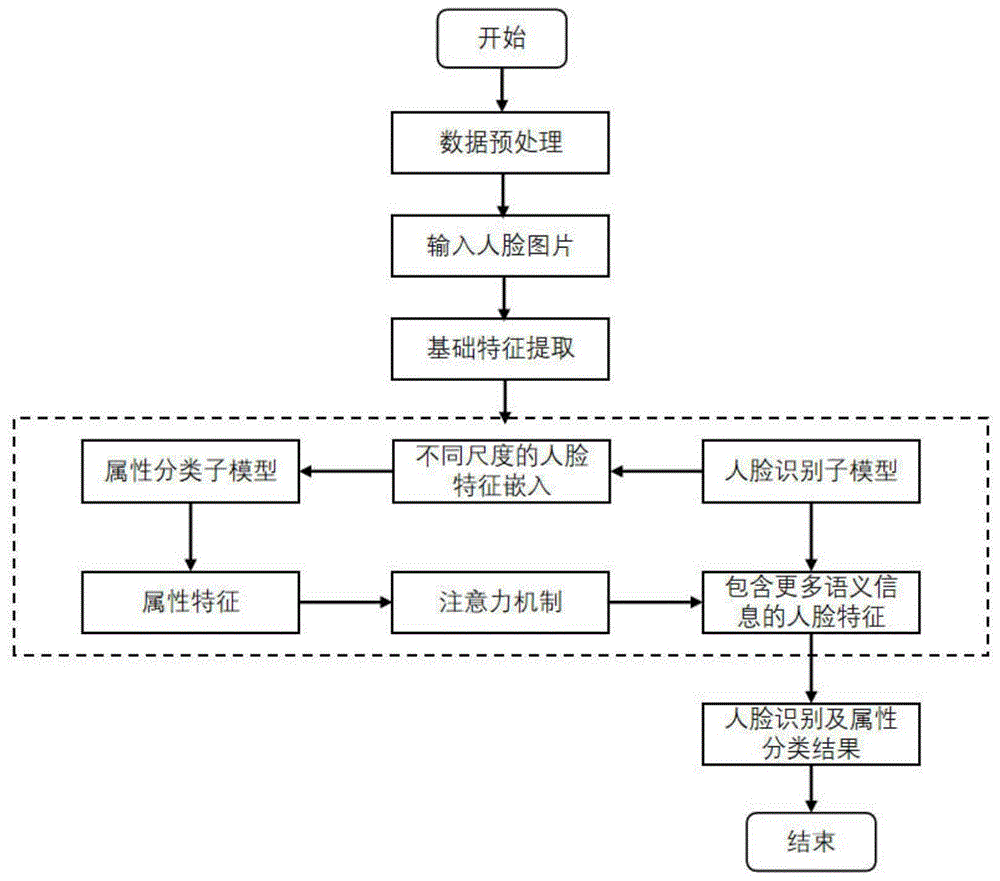
图1为本发明基于多任务卷积神经网络的人脸识别及属性分类算法流程图;
图2为本发明所设计的多任务卷积神经网络模型的结构图;
图3为模型中的注意力算法示意图。
具体实施方式
本发明旨在提出一种基于多任务卷积神经网络的人脸识别及属性分类方法,在人脸识别任务和属性分类任务上同时达到较高的精确度。其核心思想是:针对现有的相关多任务方法在人脸识别任务与属性分类任务上缺乏足够的交互,以及没考虑不同属性与人脸识别任务相关性不一致的问题,设计了一个新的多任务网络模型。该模型先将具有不同感受野大小的人脸全局特征融合属性分类子模型中,通过为其提供人脸全局信息与身份信息来提高属性分类的准确率,在得到属性特征后,在通过一个注意力结构自适应的计算不同属性与人脸识别任务的相关性来将更为有效的语义信息提供给人脸识别子模型,最后对模型进行联合训练。
实施例:
本实施例中基于设计的多任务卷积神经网络模型先提取输入人脸的基础特征,然后将人脸识别子模型所包含的全局信息与身份信息融入属性分类子模型中来帮助提升属性分类的效果,再得到人脸的属性特征后,再利用一个注意力结构自适应的计算不同属性与人脸识别任务的相关性并根据相关性来提取其语义信息,来进一步提升人脸识别的精确度。
其具体实施如图1所示,包括以下步骤:
s1、对人脸图像样本进行预处理:
本步骤中,对开源的celeba人脸数据集进行预处理操作,该数据集包含10,177个名人身份的202,599张人脸图片,每张照片不仅有所属身份标签,还有40个属性类别标签,包括:
黑头发、秃顶、刘海、金发、灰发、棕发、发际线后移、直发、戴帽子、卷发、弓眉、眼袋、浓眉、眼镜、窄眼、尖鼻、大鼻子、微笑、大嘴唇、嘴巴微张、胡茬、鬓角、双下巴、山羊胡子、小胡子、没有胡子、涂口红、高颧骨、粉脸颊、戴耳环、戴项链、打领带、有吸引力、模糊的、胖、浓妆、男性、鹅蛋脸、皮肤苍白、年轻。
具体预处理步骤为:
s11、选取属性标签:
上述40个属性标签中,部分属性标签较为稳定,短时间内不容易发生变化,比如性别、年轻等标签,其它标签则很容易在人脸的不同状态下发生变化,比如眼镜、微笑等。为了避免较易发生变化的人脸标签对人脸识别任务造成负面影响,我们只选取了部分不易发生变化的14个人脸属性进行属性分类任务,这些属性包括秃顶、发际线后移、弓眉、眼袋、浓眉、窄眼、高颧骨、尖鼻、大鼻子、大嘴唇、胖、男性、鹅蛋脸、年轻。
s12、属性和身份标签的标注:
属性分类结果均为二分类,我们分别用1和0表示属性的标签。1表示人脸图片包括该人脸属性,0表示不包括,比如:在男性标签中,1表示该样本为男性,0则表示为女性。人脸身份标签为1到10177之间的一个数字,两张人脸身份标签为同一个数字即表示他们属于同一个身份,若他们身份标签数字不同则表示他们不属于同一个身份。
s13、划分数据集:
通过随机分配的方法,将数据中的162080张人脸图片划分为训练集,将剩下的40519张图片划分为测试集。训练集中的数据将用于对模型进行训练,测试集中的数据将用于对训练的模型的性能进行评估。
s14、人脸检测和对齐:
用训练好的mtcnn算法对数据集的人脸照片进行人脸检测操作,来扩大人脸在整个图像中的占比,并利用算法检测出来的人脸五点坐标,对人脸进行一个对齐操作,再将得到的人脸图片大小设为224x224。
s2、通过设计的多任务卷积神经网络模型对预处理后的人脸图像样本提取出属性特征和人脸全局特征:
本步骤中,所述设计的多任务卷积神经网络模型如图2所示,其包括基础特征提取层、与基础特征提取层的输出连接的14个属性分类子模型和一个人脸识别子模型、与各个属性分类子模型的输出连接的注意力结构,与所述注意力结构的输出和人脸识别子模型的输出均连接的全连接层。整个网络的具体构成如下表所示:
表中conv表示卷积层,max表示最大池化层,avg表示平均池化层,fc表示全连接层。
通过向上述模型输入人脸图片xi输入模型,输出人脸全局特征与最终的人脸属性特征。
具体子流程如下:
s21、基础特征提取:
将经过处理后的大小为224x224的人脸图片输入模型,并经过模型的基础特征提取层得到其初步特征,基础特征提取层包括:一层大小为7x7,深度为64,步长为2的卷积层;一层大小为3x3,步长为2的最大池化层;4层大小为3x3,深度为64,步长为2的卷积层;一层大小为2x2,步长为2的最大池化层。人脸识别子模型与属性分类子模型共享基础特征提取层的参数,输出的特征大小为56x56,深度为64。
s22、子模型学习特定任务:
模型在提取到图片基础特征后,为避免不同任务互相干扰,模型进行了分支,分为不同的子模型,每个子模型都学习特定的任务。我们这里定义了14个属性分类任务和一个人脸识别任务,所以这里分支后有了15个子模型,其中14个属性分类子模型的网络具体结构与大小一致,但不共享参数。
s23、获取人脸特征,嵌入属性分类子模型:
人脸识别子模型经过连续8层大小为3x3,深度为128,步长为2的卷积层conv_1和大小为2x2,步长为2的最大池化层max_1,得到大小为28x28,深度为128的人脸全局特征。
属性分类子模型经过连续4层大小为3x3,深度为128,步长为2的卷积层conv_1和大小为2x2,步长为2的最大池化层max_1,得到大小为28x28,深度为128的人脸属性特征。为了在属性分类任务中加入人脸全局信息与身份信息,我们将得到的人脸全局特征通过串联的方式嵌入属性分类子模型中,最终得到的属性特征大小为28x28,深度为256。
后面的con_2和max_2与前面的计算方式基本一致,人脸识别子模型经过max_2后得到的人脸全局特征,通过串联的方式嵌入属性分类子模型中,提取到的人脸全局特征大小为14x14,深度为512,属性特征大小为14x14,深度为1024。
随后人脸识别子模型与属性分类子模型经过conv_3后得到大小都为7x7,深度为512的人脸全局特征与属性特征,再经过一个全局平均池化层avg得到大小为512的一维人脸全局特征与属性特征。再通过大小为1000的全连接层分别对人脸全局特征与属性特征进行映射后,得到大小为1000的人脸全局特征和大小为1000的属性特征。这里的属性特征再经过一个大小为1的全连接层和sigmoid激活层后,即输出属性分类的结果。
s3、基于注意力机制计算不同属性与人脸识别任务的相关度,并根据相关度将属性特征融合进人脸特征中:
本步骤中,为了从人脸属性特征中提取到与人脸识别任务更为相关的语义信息,我们设计了一个注意力算法来计算不同属性与人脸识别任务的相关度,并根据相关度将属性特征融合进人脸特征中去,如图3所示。具体的子流程如下:
s31、获得上一步模型输出的属性特征ai和人脸特征f,并初始化模型参数wi与全连接层fc;
s32、对所有的14个属性特征都进行映射和归一化操作,vi=norm(ai*wi)并初始化属性特征与人脸特征的关系度bi=0;
s33、通过关系度bi计算属性与人脸特征的耦合系数ci=softmax(bi),并且计算加权融合后的属性特征s,softmax具体计算公式如下,e为自然常数,m表示人脸身份的类别数量。
s34、融合属性特征与人脸特征,u=concatenate(s,f),并通过全连接映射变换得到包含属性特征中语义信息的人脸特征,fs=fc(u);
s35、对所有的属性特征,计算人脸特征与其相似度,并更新关系度,bi=bi+dot(vi,fs),dot表示点乘操作;
s36、将步骤s33到步骤s35重复执行n次,获得不同人脸属性对于人脸全局特征的权重和最终包含更相关的语义信息的人脸特征。
s4、多任务卷积神经网络模型同时进行人脸识别任务和属性分类任务,并通过计算损失来训练优化模型:
本步骤中,模型提取到人脸相应的属性特征与人脸特征后,就开始计算任务损失,并基于损失利用梯度下降算法对模型进行优化。
s41、属性分类任务的损失我们采用交叉熵损失函数来实现,具体公式如下:
yj表示样本j在属性i上所属于标签,分别用0和1表示负类和正类。y′j则表示模型在该处预测为正类的可能性,范围在0-1之间,其值越大,可能性就越大。交叉熵能衡量同一个随机变量中不同概率分布的差异程度,从式中可以看出,模型预测的概率值与标签差的越多交叉熵越大,反之则越小,所以我们用交叉熵来计算属性分类任务的损失函数。当分别计算出14个人脸属性的分类损失后,对它们进行相加,就得到人脸属性分类任务的总体损失。
s42、计算人脸识别任务的损失:
我们首先选取一张目标样本anchor,再选取一张与anchor属于同一类的样本positive和一张与anchor属于不同类的样本negative。当anchor与positive(正样本)的距离要小于anchor与negative之间的距离时,模型就能达到区分不同人脸的功能,为了加强模型的泛化能力,我们不仅要求anchor与negative(负样本)距离大于anchor与positive的距离,并且这个距离还要大于一个超参数α,该值我们取0.2大小时达到最好效果,公式如下:
最终的人脸识别损失函数我们采用tripletloss来实现,该loss通过同时最小化anchor和positive之间的距离并且最大化anchor和negative之间的距离来进行优化,具体计算公式如下:
anchor样本我们进行随机选择,positive样本选择与anchor距离最远的同一类样本,negative选择与anchor最近的不同类样本,但若在整个训练集里选择最近的不同类样本的话,计算量比较大,同时模型可能因为数据存在的噪音而无法收敛,所以我们只选择在一个batch里最近的不同类样本。计算anchor样本和negative样本以及positive样本距离时,若在每次模型更新参数后就进行距离计算,会极大的增加模型训练时间,若只在开始进行距离计算的话,计算出的距离随着模型参数更新又会产生变化。因此我们选取了一个折衷的训练方法,每当整个训练数据集都进行训练后,重新计算一次样本之间的距离。
s43、人脸识别及属性分类多任务模型最终的损失函数如下:
l=λ×la+lf
λ是一个超参数,经实验设为0.4时有较好效果,训练时网络的batch-size设为64,初始学习率设为0.001,采用adam优化对网络进行优化。
s5、利用优化后的模型对输入的人脸图像同时进行属性分类和人脸识别任务:
模型训练完成后,我们能随意输入一张人脸图片并同时进行属性分类和人脸识别操作,具体子流程如下:
s51、对待识别的图片进行人脸检测和对齐操作,并将处理后的图片大小全都归一化为224x224;
s52、加载训练完成后的网络模型参数;
s53、将人脸图片输入多任务模型,并得到属性分类结果与最终的人脸特征。属性分类结果若大于0.5,则表示模型对该属性的预测结果为正类,若小于等于0.5,则表示模型对于该属性预测结果为负类。进行人脸识别操作时,我们需要先定义一个人脸库,并将人脸库中的所有人脸照片都通过模型提取到相应的人脸特征后,再将待识别人脸对应的人脸特征与人脸库中的特征进行距离计算,当它们之间的距离小于一个阈值时,我们就可以判断这两张人脸为同一个身份,否则,则判断为陌生人脸。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!