一种实体关系自动发现方法与系统与流程
本发明属于信息处理技术领域,尤其涉及一种实体关系自动发现方法与系统。
背景技术:
大数据,it行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
在传统的业务平台中,数据之间的关系基本上是依靠人工建立关联字段和关联信息,并通过关系型数据库进行实体的存储,通过关系表进行实体之间关系的存储,但在当今大数据时代环境下,对海量、多变的数据进行梳理时仍是通过人工进行,在不断增加数据之间的关联关系下,已经变得力不从心,也不现实,将需要消耗大量的人力、物力和财力,因此,现阶段市场上亟需一种实体关系自动发现方法与系统来解决上述问题。
技术实现要素:
本发明的目的在于:为了解决在当今大数据时代环境下,对海量、多变的数据进行梳理时仍是通过人工进行,在不断增加数据之间的关联关系下,已经变得力不从心,也不现实,将需要消耗大量人力、物力和财力的问题,而提出的一种实体关系自动发现方法与系统。
为了实现上述目的,本发明采用了如下技术方案:
一种实体关系自动发现方法,所述实体关系自动发现方法包括如下步骤:
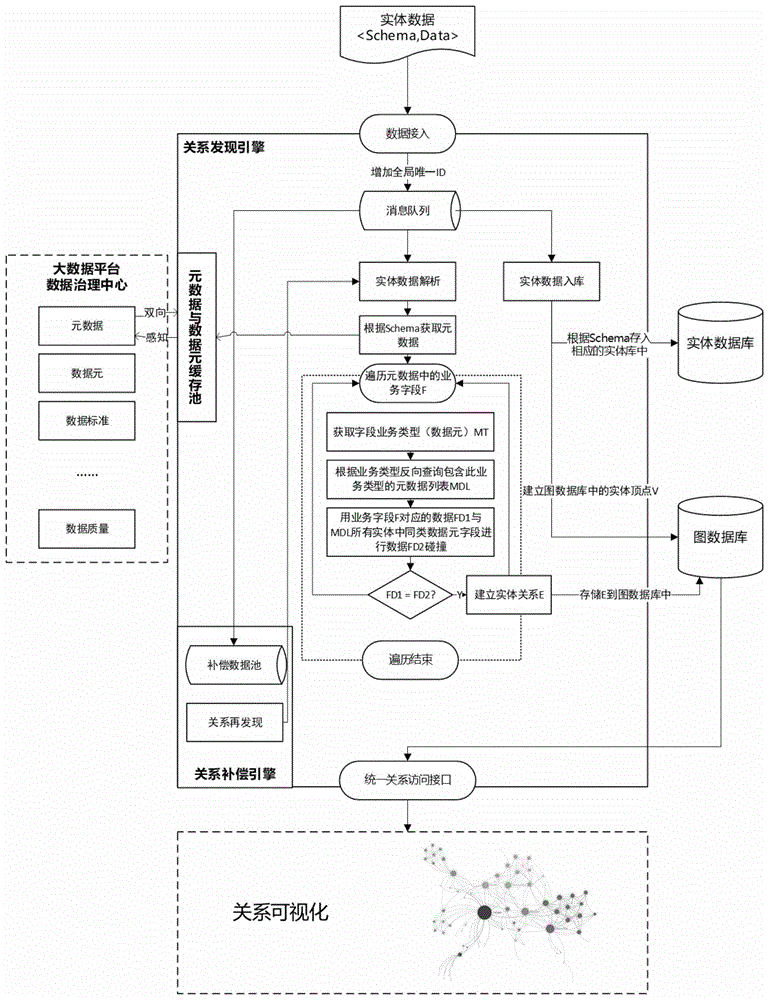
步骤s1:数据接入,接收外部实体数据(schema,data)进入关系引擎消息队列,在接入过程中,对所接入的实体数据(schema,data)增加其全局唯一id;
步骤s2:实体数据入库,从消息队列取出数据,根据实体类型(schema)存入相应的实体数据库中;
步骤s3:从消息队列取出数据,根据实体类型(schema)建立图数据库中的实体定点v,并以顶点的形式存储于图数据库中;
步骤s4:从消息队列取出数据,存入关系补偿引擎中的补偿数据池;
步骤s5:从消息队列取出数据,同时还需从关系再发现中提出数据,并对所提取的实体数据(schema,data)进行解析,然后根据实体类型(schema)从解析后的实体数据(schema,data)中获取元数据,并将所获取的元数据存储至元数据与数据元缓存池内;
步骤s6:关系补偿,根据实体类型(schema)所获取的元数据同时进入多项实体数据时,有可能在刚刚进入的实体之间存储数据关系发现盲点,因此将新进数据按时间周期存储到补偿数据池中;
步骤s7:通过统一关系访问接口访问图数据库,并进行关系可视化。
作为上述技术方案的进一步描述:
所述步骤s5中根据元数据中的字段定义遍历元数据中的所有业务字段f。
作为上述技术方案的进一步描述:
所述步骤s5中根据字段f的业务类型(元数据)mt反向查询所有拥有同业务类型的所有元数据,得到一个元数据列表清单mdl。
作为上述技术方案的进一步描述:
所述根据字段f对应的此项实体数据中的数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对。
作为上述技术方案的进一步描述:
所述数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对结果如果相同,则表示这两个实体基于f字段具有fd1=fd2的关系,这样则在图数据库中存储一条实体关系边e,建立实体关系e,并存储e至图数据库中。
作为上述技术方案的进一步描述:
所述数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对结果如果不相同,则不做任何处理。
作为上述技术方案的进一步描述:
所述数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对结果无论是否具有fd1=fd2的关系,均继续遍历,直到所有字段均遍历完后遍历结束。
作为上述技术方案的进一步描述:
所述步骤s6中根据设置的固定时间间隔周期性执行数据补偿任务,且所述固定时间间隔定义根据实际业务场景下对数据关系时效性的需求而定。
作为上述技术方案的进一步描述:
所述数据补偿任务的补偿业务流程即关系再发现流程,即与步骤s5的处理方法完全相同。
作为上述技术方案的进一步描述:
所述实体关系自动发现系统包括关系发现引擎及大数据平台数据治理中心、元数据与数据元缓冲池、关系补偿引擎、实体数据库以及图数据库所组成的补偿系统,且所述关系发现引擎的运行,需要元数据系统、图数据库以及实体数据库的支撑,所述元数据中的元数据用于定义数据标准结构,且所述元数据由一个个数据元组成,且所述数据元是用来描述数据属性的业务类型定义,所述图数据库用来存储发现的实体关系及关系锚点,所述实体数据库用于存储实体信息数据。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1、本发明中,海量数据环境下的实体识别、数据元识别方法、并发分布式关系发现方法以及并发关系发现可能带来的关系遗漏发现及其补偿方法,利用图形存储引擎、实体文档存储引擎,基于数据元、元数据以及数据标准体系的支撑,建立了一套自动化的关系发现算法与系统引擎,解决面对海量数据洪流,快速的发现并建立关联关系及其关系图谱的难题,相对于人工梳理的方式,其错误率明显降低,且能够削减人力、物力以及财力的消耗量。
2、本发明中,将实体关系的建立从人工编排进化为自动发现,降低了错误率的同时,也提高了工作效率,在海量数据环境下,关系自动发现,极大提高了工作效率。
3、本发明中,能够针对数据遗漏提出补偿机制,保障了实体关系的完整性。
附图说明
图1为本发明提出的一种实体关系自动发现方法与系统的示意图;
图2为本发明提出的一种实体关系自动发现方法与系统的方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1-2,本发明提供一种技术方案:一种实体关系自动发现方法,所述实体关系自动发现方法包括如下步骤:
步骤s1:数据接入,接收外部实体数据(schema,data)进入关系引擎消息队列,在接入过程中,对所接入的实体数据(schema,data)增加其全局唯一id;
步骤s2:实体数据入库,从消息队列取出数据,根据实体类型(schema)存入相应的实体数据库中;
步骤s3:从消息队列取出数据,根据实体类型(schema)建立图数据库中的实体定点v,并以顶点的形式存储于图数据库中;
步骤s4:从消息队列取出数据,存入关系补偿引擎中的补偿数据池;
步骤s5:从消息队列取出数据,同时还需从关系再发现中提出数据,并对所提取的实体数据(schema,data)进行解析,然后根据实体类型(schema)从解析后的实体数据(schema,data)中获取元数据,并将所获取的元数据存储至元数据与数据元缓存池内;
步骤s6:关系补偿,根据实体类型(schema)所获取的元数据同时进入多项实体数据时,有可能在刚刚进入的实体之间存储数据关系发现盲点,因此将新进数据按时间周期存储到补偿数据池中;
步骤s7:通过统一关系访问接口访问图数据库,并进行关系可视化。
具体的,步骤s5中根据元数据中的字段定义遍历元数据中的所有业务字段f。
具体的,步骤s5中根据字段f的业务类型(元数据)mt反向查询所有拥有同业务类型的所有元数据,得到一个元数据列表清单mdl。
具体的,根据字段f对应的此项实体数据中的数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对。
具体的,数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对结果如果相同,则表示这两个实体基于f字段具有fd1=fd2的关系,这样则在图数据库中存储一条实体关系边e,建立实体关系e,并存储e至图数据库中。
具体的,数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对结果如果不相同,则不做任何处理。
具体的,数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对结果无论是否具有fd1=fd2的关系,均继续遍历,直到所有字段均遍历完后遍历结束。
具体的,步骤s6中根据设置的固定时间间隔周期性执行数据补偿任务,且所述固定时间间隔定义根据实际业务场景下对数据关系时效性的需求而定。
具体的,数据补偿任务的补偿业务流程即关系再发现流程,即与步骤s5的处理方法完全相同。
具体的,实体关系自动发现系统包括关系发现引擎及大数据平台数据治理中心、元数据与数据元缓冲池、关系补偿引擎、实体数据库以及图数据库所组成的补偿系统,且所述关系发现引擎的运行,需要元数据系统、图数据库以及实体数据库的支撑,所述元数据中的元数据用于定义数据标准结构,且所述元数据由一个个数据元组成,且所述数据元是用来描述数据属性的业务类型定义,所述图数据库用来存储发现的实体关系及关系锚点,所述实体数据库用于存储实体信息数据。
工作原理:使用时,数据接入,接收外部实体类型(schema,data),完成增加实体数据全局唯一id后进入关系引擎消息队列,实体数据入库,提取消息列队中的数据,根据实体类型(schema)存入相应的实体数据库中,提取消息列队中的数据,根据实体类型(schema)建立图数据库中的实体定点v,并以顶点的形式存储于图数据库中,提取消息列队中的数据,直接存入补偿数据池,提取消息列队中的数据,根据实体类型(schema)获取元数据定义,根据元数据中的字段定义遍历所有业务字段f,并获取字段业务类型(元数据)mt,根据字段f的业务类型(元数据)查询所有拥有同业务类型的所有元数据,这样可以得到一个元数据列表清单mdl,根据字段f对应的此项实体数据中的数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对,数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对结果如果相同,则表示这两个实体基于f字段具有fd1=fd2的关系,这样则在图数据库中存储一条实体关系边e,数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对结果如果不相同,则不做任何处理,数据fd1与所有拥有同业务类型的实体进行同业务类型的字段数据fd2碰撞比对结果无论是否具有fd1=fd2的关系,均继续遍历,直到所有字段均遍历完,关系补偿,根据实体类型(schema)所获取的元数据同时进入多项实体数据时,有可能在刚刚进入的实体之间存储数据关系发现盲点,因此将新进数据按时间周期存储到补偿数据池中,根据设置的固定时间间隔周期性执行数据补偿任务,且所述固定时间间隔定义根据实际业务场景下对数据关系时效性的需求而定,数据补偿任务的补偿业务流程即关系再发现流程,即与提取消息列队中的数据,根据实体类型(schema)获取元数据定义的处理方法完全相同。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!