太赫兹知识图谱构建方法及系统与流程
本发明涉及知识图谱技术领域,更具体地,涉及一种太赫兹知识图谱构建方法及系统。
背景技术:
近年来,随着链接开放数据源(如wikipedia)的出现,以及google于2012年首次提出“知识图谱”这一概念,以图形表示通用世界知识引起了各方的关注。知识图谱具有能够通过将应用数学、信息可视化技术等学科的理论与方法与计量学引文分析、共现分析等方法结合,利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构,揭示知识领域的动态发展规律的特点,通过知识图谱技术,可以挖掘更多的事物间的关联关系,同时知识图谱技术也是知识驱动型智能技术的基础。目前,这一新兴技术的研究正在如火如荼地开展中,以通用领域知识图谱为例:yahoo和google的图谱在语义搜索上已经得到了很好的应用;ibm的watson和wolfram的alpha在智能问答方面展现出了卓越的性能;国内美团、阿里巴巴等商业公司的餐饮、电商知识图谱在推荐系统等方面也得到了很好的应用。同时,在行业知识图谱方面也有大量相关的研究,如:华东师范大学提出的农业领域知识图谱、中国中医科学院中医药信息研究所提出的中医药知识图谱、上海交通大学提出的acemap等。
现有的学术领域知识图谱的构建都是从文献出发,主要侧重于文献、文献作者、文献发表机构信息的整合与挖掘,而没有学术信息与研发信息结合的图谱构建。对于研究者来说,在进行产、学、研结合的相关工作时,使用这种图谱在信息的获取上比较局限。同时,对于从事相关工作的非学术人员来说,这种图谱适用性比较低。
技术实现要素:
鉴于上述问题,本发明提供一种适用于太赫兹领域的太赫兹知识图谱构建方法及系统。
根据本发明的一个方面,提供一种太赫兹知识图谱构建方法,包括:
数据采集,包括:构建知识图谱的整体框架,所述整体框架包括实体类别、属性类别及各实体类别间的关系,将实体类别划分为第一实体类别、第二实体类别和第三实体类别,第一实体类别是从数据源直接采集所有实体属性信息的实体类别,第二实体类别是从第一实体类别采集到的信息中抽取得到实体,而后通过第三方数据源进一步扩充实体属性的实体类别,第三实体类别为根据现有信息给定的实体,按照是否存在子实体类别分别将第二实体类别和第三实体类别划分为第二单实体类别、第二多实体类别、第三单实体类别和第三多实体类别,通过第一实体类别对应数据源采集信息,其中,实体是客观存在并可相互区分的事物,所述实体类别是同类实体的集合,所述属性类别是一个类别的实体具有的属性信息,所述实体类别间的关系是设定的实体类别间符合语义逻辑的关系;
知识抽取,对采集的信息根据所述整体框架进行数据抽取;
知识融合,对整体框架及其对应的抽取的数据进行融合,形成知识图谱;
其中,所述知识抽取的步骤包括:
实体抽取,基于整体框架中实体类别间的关系,找到与采集信息对应的第一实体类别有关系的其他第一实体类别、第二单实体类别和第三单实体类别,根据第一实体类别、第二单实体类别和第三单实体类别的属性类别对采集的信息进行实体抽取,包括:将采集的信息中的数据进行分类,所述分类包括结构化数据、半结构化数据和非结构化数据;对于结构化数据通过其数据字段得到实体;对于非结构化数据基于规则的最大正向匹配法识别实体;对于半结构化的数据采用基于正则表达式和模板的方式提取实体;
关系抽取,采用模式匹配的方式在结构化数据和半结构化数据上抽取实体间的关系;对于非结构化数据,基于实体抽取时的规则采用模式匹配的方式抽取实体间的关系,所述实体间的关系属于所述实体类别间的关系;
关系和实体分类,基于整体框架中实体类别间的关系,找到与采集信息对应的第一实体类别有关系的第二多实体类别和第三多实体类别,基于双向lstm的多标签分类法获得所述信息所属的第二多实体类别和第三多实体类别的子实体类别。
优选地,在所述知识抽取步骤之前还包括数据清洗的步骤,所述数据清洗的步骤包括:
删除重复数据和无效数据,获得有效记录字段,所述无效数据是针对实体类别的关键字段缺失的数据,所述关键字段是实体类别必不可少的信息;
剔除有效记录字段中的杂质数据,所述杂质数据为类乱码和无关符号的数据;
对齐异构数据源数据字段;
统一数据编码格式。
优选地,所述知识融合步骤之后还包括知识推理步骤,所述知识推理步骤采用通过演绎推理对实体间的关系进行挖掘。
优选地,所述知识融合的步骤包括:
对实体的形式进行统一;
通过数据库对实体和相关字段的映射关系进行数据融合,获得实体的属性。
进一步,优选地,还包括知识图谱可视化的步骤,所述知识图谱可视化的步骤包括:
在显示终端通过web应用框架显示知识图谱,包括:
通过浏览器接收客户端的http请求;
将所述http请求发送给web服务器网管关口;
通过统一资源定位器指定信息位置,并发送给视图函数;
视图函数使用httprequest对象,在数据存储层请求数据;
数据存储层调用数据库数据,根据视图函数中需要的对象从数据库中提取相应数据到视图函数中,在视图函数中进行数据处理之后通过模板语言传入表现层,表现层返回http请求到浏览器,展现给用户。
优选地,所述基于双向lstm的多标签分类法获得所述信息所属的第二多实体类别和第三多实体类别的子实体类别的步骤包括:
分别设定第二多实体类别和第三多实体类别的各子实体类别的分类要使用的信息;
通过翻译接口将当前分类要使用的信息进行格式统一;
利用格式统一后的相关信息训练领域词向量库,所述领域词向量库是太赫兹领域的词向量库;
通过领域词向量库获得分类要使用的信息中每个词的词向量;
将每个样本的分类要使用的信息通过词嵌入层将表示成向量嵌入的形式;
将嵌入形式的每个样本序列输入双向lstm,获得每个样本序列的上下文信息作为分类特征;
将lstm层提取到的分类特征输入池化层和全连接层,进行特征选择和降维,保留与分类相关的核心特征;
将所述分类相关的核心特征输入分类器,获得信息与每个子实体类别的置信度;
根据预设的置信度阈值,将信息归属到超过所述置信度阈值的子实体类别。
优选地,所述知识图谱可视化的步骤还包括:
对知识图谱进行整体展示或者对知识图谱按照实体类别进行分模块展示。
优选地,所述实体类别包括文献实体类别、作者实体类别、机构实体类别、领域实体类别、产品实体类别、专利实体类别、国家实体类别、省份实体类别、关键词实体类别、基金实体类别和会议论坛实体类别,所述第一实体类别包括文献实体类别、专利实体类别、基金实体类别和产品实体类别,所述第二实体类别包括会议实体类别、关键词实体类别、机构实体类别和作者实体类别,所述第三实体类别包括国家实体类别、省份实体类别和领域实体类别,第二单实体类别包括会议实体类别、关键词实体类别和作者实体类别,第二多实体类别包括机构实体类别,第三单实体类别包括国家实体类别和省份实体类别,第三多实体类别包括领域实体类别。
根据本发明的另一个方面,提供一种太赫兹知识图谱构建系统,包括:
框架构建部,构建知识图谱的整体框架,所述整体框架包括实体类别、属性类别及各实体类别间的关系,将实体类别划分为第一实体类别、第二实体类别和第三实体类别,第一实体类别是从数据源直接采集所有实体属性信息的实体类别,第二实体类别是从第一实体类别采集到的信息中抽取得到实体,而后通过第三方数据源进一步扩充实体属性的实体类别,第三实体类别为根据现有信息给定的实体,按照是否存在子实体类别分别将第二实体类别和第三实体类别划分为第二单实体类别、第二多实体类别、第三单实体类别和第三多实体类别,通过第一实体类别对应数据源采集信息,其中,实体是客观存在并可相互区分的事物,所述实体类别是同类实体的集合,所述属性类别是一个类别的实体具有的属性信息,所述实体类别间的关系是设定的实体类别间符合语义逻辑的关系;
采集部,从数据源采集框架构建部构建的所述整体框架相关的信息;
抽取部,对采集部采集的信息根据所述整体框架进行数据抽取;
融合部,对整体框架及其对应的抽取的数据进行融合,形成知识图谱,
其中,所述抽取部包括:
实体抽取模块,基于整体框架中实体类别间的关系,找到与采集信息对应的第一实体类别有关系的其他第一实体类别、第二单实体类别和第三单实体类别,根据第一实体类别、第二单实体类别和第三单实体类别的属性类别对采集的信息进行实体抽取,包括:将采集的信息中的数据进行分类,所述分类包括结构化数据、半结构化数据和非结构化数据;对于结构化数据通过其数据字段得到实体;对于非结构化数据基于规则的最大正向匹配法识别实体;对于半结构化的数据采用基于正则表达式和模板的方式提取实体;
关系抽取模块,采用模式匹配的方式在结构化数据和半结构化数据上抽取实体间的关系;对于非结构化数据基于实体抽取时的规则采用模式匹配的方式抽取实体间的关系,所述实体间的关系属于所述实体类别间的关系;
分类模块,基于整体框架中实体类别间的关系,找到与采集信息对应的第一实体类别有关系的第二多实体类别和第三多实体类别,基于双向lstm的多标签分类法获得所述信息所属的第二多实体类别和第三多实体类别的子实体类别。
优选地,还包括:
可视化部,对融合部获得的知识图谱进行可视化,在显示终端通过web应用框架显示知识图谱
上述太赫兹知识图谱构建方法及系统构建太赫兹知识图谱的整体框架,通过数据采集、知识抽取和知识融合准确全面的获得太赫兹领域知识图谱。
附图说明
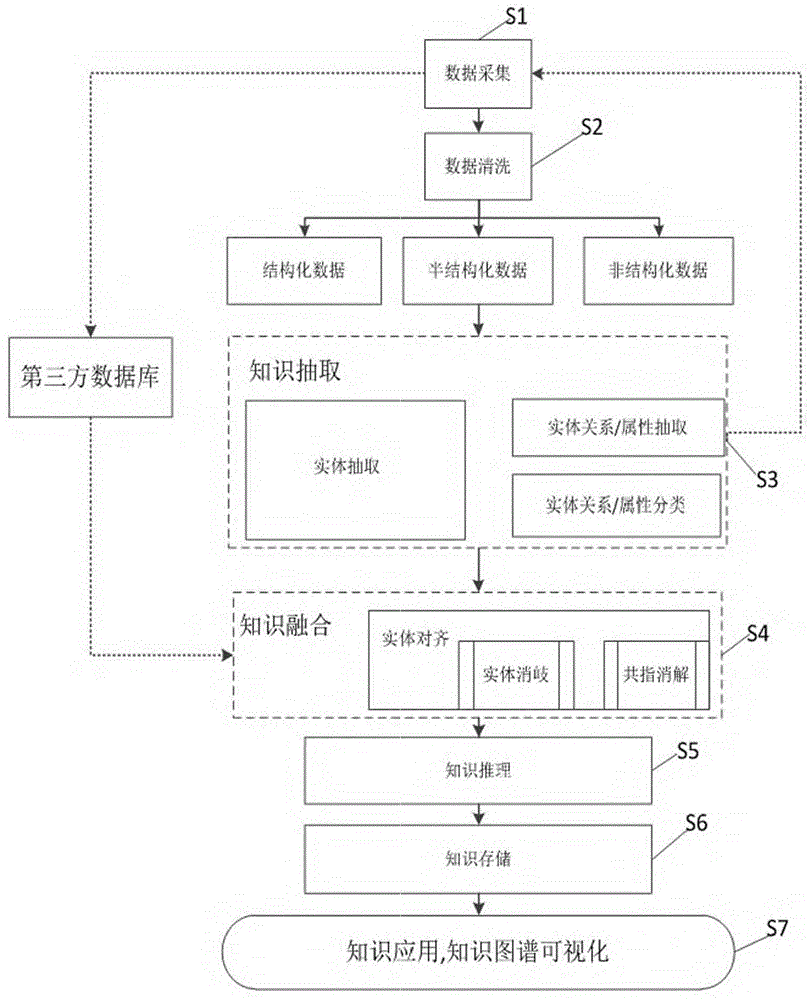
图1是本发明所述太赫兹知识图谱构建方法的流程图;
图2是本发明所述太赫兹知识图谱的整体框架的示意图;
图3a-3k是本发明所述实体的示意图;
图4是本发明所述采用基于双向lstm网络的多标签分类法的示意图;
图5是本发明所述领域实体类别的子实体类别的示意图;
图6是本发明所述运用django框架实现知识图谱可视化的流程图;
图7和图8是本发明所述太赫兹知识图谱可视化的示意图;
图9是本发明所述太赫兹知识图谱构建系统的构成框图。
具体实施方式
在下面的描述中,出于说明的目的,为了提供对一个或多个实施例的全面理解,阐述了许多具体细节。然而,很明显,也可以在没有这些具体细节的情况下实现这些实施例。在其它例子中,为了便于描述一个或多个实施例,公知的结构和设备以方框图的形式示出。
下面将参照附图来对根据本发明的各个实施例进行详细描述。
图1是本发明所述太赫兹知识图谱构建方法的流程图,如图1所示,所述太赫兹知识图谱构建方法包括:
步骤s1,数据采集,包括:构建知识图谱的整体框架,所述整体框架包括实体类别、属性类别及各实体类别间的关系,将实体类别划分为第一实体类别、第二实体类别和第三实体类别,第一实体类别是从数据源直接采集所有实体属性信息的实体类别,第二实体类别是从第一实体类别采集到的信息中抽取得到实体,而后通过第三方数据源进一步扩充实体属性的实体类别,第三实体类别为根据现有信息给定的实体,按照是否存在子实体类别分别将第二实体类别和第三实体类别划分为第二单实体类别、第二多实体类别、第三单实体类别和第三多实体类别,通过第一实体类别对应数据源采集信息,其中,实体类别是同类实体的集合,是一个抽象的概念。实体客观存在并可相互区别的事物。实体可以是具体的人、事、物,也可以是抽象的概念或联系。实体类别是根据需要获取的数据类型预先进行定义的,实体为根据定义的实体类别获取到的数据,如:需要获取文献数据,则在图谱里应该有一个实体类别为文献。实体是根据定义的实体类别获取到的数据,比如需要文献类别的实体,选择从cnki、ieee这种科学数据网站去获取相关文献信息。获取到的一篇文献信息,就算一个文献实体。属性类别的设置是从实体类别出发考虑的,首先是一个类别实体必须有的属性信息,即每个用户看到这种实体时都会需要的信息,比如:专利实体的申请时间、专利名称、专利申请编号、申请状态等;
步骤s3,知识抽取,对采集的信息根据所述整体框架进行数据抽取;
步骤s4,知识融合,对整体框架及其对应的抽取的数据进行融合,形成知识图谱。
在步骤s1中,所述数据采集步骤包括:
构建知识图谱的整体框架,如图2所示,所述实体类别包括文献实体类别、作者实体类别、机构实体类别、领域实体类别、产品实体类别、专利实体类别、国家实体类别、省份实体类别、关键词实体类别、基金实体类别和会议论坛实体类别,图中的节点代表实体类别,可以采用颜色或/和形状区分不同实体类别,节点间的连线代表实体类别间的关系,例如,作者实体类别和国家实体类别之间的“作者所在国家”的实体类别间的关系。如图3a所示,文献实体类别的属性类别至少包含:文献名、文献编号、文献doi和文献摘要,还可以包括图3a示出的其他属性信息,其中,文献编号是本地数据库中存储时的文献识别码设置,文献doi为其在网络上的电子资源唯一识别码。如图3b所示,作者实体类别的属性类别至少包含作者姓名,还可以包括图3b示出的其他属性信息。如图3c所示,机构实体类别的属性类别至少包含:机构中文名和机构英文名,优选地,所述机构实体类别包含两个子实体类别:教育类机构,所述教育类机构的属性类别可以包括:机构中文名、机构英文名、机构百科信息(包库:百科简介、百科图片、百科给出的基本属性表信息,即获取对应教育类机构的百度百科的所有信息作为补充属性);非教育类机构,非教育类机构实体类别的属性类别可以包括:机构中文名、机构英文名和机构百度企业信用信息(包括:机构统一社会信用编码、机构注册资本、机构法人、成立日期、所在地址等,即将百度企业信用提供的该机构的所有信息作为其补充属性)。如图3d所示,领域实体类别的属性类别至少包含:领域名、领域级别(一级领域级别分为:硬件和软件。各一级领域下又分别划分了几个二级领域类别等),根据太赫兹领域的研究方向领域实体类别包括多个子实体类别。如图3e所示,产品实体类别的属性类别至少包含:产品中文名或产品英文名和产品详情,还可以包括图3e示出的其他属性信息;如图3f所示,专利实体类别的属性类别至少包含:专利名、专利发明人、专利号、专利摘要、专利状态、专利申请日期,还可以包括图3f示出的其他属性信息;如图3g所示,国家实体类别的属性类别至少包含国家中英文名还可以包括图3g示出的其他信息;图3h示出了省份实体类别的属性类别包括的信息;如图3i所示,关键词实体类别的属性类别至少包含:关键词中文名、关键词英文名,还可以包括关键词在百度百科的信息;如图3j所示,基金实体类别的属性类别至少包含:基金项目名称、项目负责人、项目申请单位、项目中文/英文摘要、项目基金批准号、项目类别和项目研究期限,还可以包括图3j示出的其他属性信息;如图3k所示,会议实体类别的属性类别至少包含:会议名、会议召开时间和会议地址,还可以包括图3k示出的其他属性信息,其中,会议出版文献数指的是在太赫兹专属会议数据库中统计得到的该会议的文献数。
构建好知识图谱的整体框架之后,确定知识图谱框架第一实体类别及其对应的数据源,确定第二实体及其对应的第三方数据源,所述数据源可以包括:文献实体数据源(如cnki和ieee网站能检索到的太赫兹相关的文献数据)、作者实体数据源(如ieee网站提供的文献对应的作者信息)、专利数据源(如万方数据库提供的太赫兹相关的专利信息)、产品数据源(如antpedia和instrument等仪器信息网站的太赫兹相关仪器数据)和基金数据源(如科学网的太赫兹相关国家自然科学基金数据),可以将百度百科和百度企业信息作为第三方数据源对实体信息进行补充,丰富实体信息,例如,所述第一实体类别包括文献实体类别、专利实体类别、基金实体类别和产品实体类别,所述第二实体类别包括会议实体类别、关键词实体类别、机构实体类别和作者实体类别,所述第三实体类别包括国家实体类别、省份实体类别和领域实体类别,第二单实体类别包括会议实体类别、关键词实体类别和作者实体类别,第二多实体类别包括机构实体类别,第三单实体类别包括国家实体类别和省份实体类别,第三多实体类别包括领域实体类别。
确定数据源后,使用网络爬虫技术来获取上述数据源的相关信息,通过python开发环境提供的requests和selenium开发接口,对网页发起请求得到网页返回的源代码,然后利用beautifulsoup和re等库对返回的网页源代码进行数据提取,得到需要的信息并通过pymysql接口将数据实时存入mysql数据库。对于输入式图片验证码的网站,通过图片ocr识别技术,先将对应的图片验证码存储到本地,而后对其进行ocr识别,再结合selenium等自动化工具将识别结果填入网页,以获取信息。
在步骤s3中,所述知识抽取的步骤包括:
步骤s31,实体抽取,基于整体框架中实体类别间的关系,找到与采集信息对应的第一实体类别有关系的其他第一实体类别、第二单实体类别和第三单实体类别,根据第一实体类别、第二单实体类别和第三单实体类别的属性类别对采集的信息进行实体抽取,包括:将采集的数据源的信息中的数据进行分类,所述分类包括结构化数据、半结构化数据和非结构化数据;对于结构化数据通过其数据字段得到实体;对于半结构化的数据采用基于正则表达式和模板的方式提取实体;对于非结构化数据基于规则的最大正向匹配法通过属性类别识别实体,以ieee的机构数据抽取为例:对原始文本为“departmentofelectricalengineeringandelectronics,theuniversityofliverpool,l693gj,uk;departmentofelectricalengineeringandelectronics,theuniversityofliverpool,l693gj,uk;departmentofelectricalengineeringandelectronics,theuniversityofliverpool,l693gj,uk”的机构数据,首先按照“;”进行分词得到三个信息段,这三个信息段分别对应三个作者所属的机构信息,而后对三个字信息段根据“,”进行分割得到n个字段,对分隔得到的最后一个字段采用预先构造的国家字典进行最大正向匹配抽取国家实体,同时对其进行缩写补齐,统一整理成完整的国家名。通过最大正向匹配法抽取国家实体,可改善由于国家名字重叠问题(如“unitedkingdomofgreatbritainandnorthernireland”中重叠的“ireland”)导致的国家实体抽取错误。对“,”分隔出的前n-1个字段首先进行关键词匹配,即判断字段中是否包含“univ”、“dept”、“lab”等机构实体标识信息,而后提取出包含实体标识信息的字段作为机构实体。按照此种方式进行抽取时,可得到一一对应的国家实体类别和机构实体类别列表,可用于后续的关系抽取,其中,所述国家字典指的是预先构造的国家信息数据表,包括:现有的所有国家的中文名信息、现有所有国家的英文名信息,国家的常见城市信息。这三个信息字段是一一对应的。国家信息数据表的数据可以从网上获取;
步骤s32,关系抽取,采用模式匹配的方式在结构化数据和半结构化数据上抽取实体间的关系,例如,根据预先定义的头实体类别和尾实体类别以及二者间的关系,将关系数据表的实体通过模板一一进行映射,得到对应的实体-关系-实体三元组信息;对于非结构化数据,基于实体抽取时的规则采用模式匹配的方式抽取实体间的关系,所述实体间的关系属于所述实体类别间的关系,例如,以实体抽取得到的机构数据与国家数据为例,由于在进行抽取时保证了实体间的一一对应关系,则通过制定规则,如:按照机构实体类别和国家实体类别在各自列表中的位置,即可实现两种实体的一一对应,此时就可以根据两种实体类别结合知识图谱的整体框架进行模式匹配(预先定义的整体框架中说明两类实体类别间的关系,确定两个实体且知道各自的类别后,将其匹配到整体框架中得到关系)得到对应的实体-关系-实体信息,例如,由原始非结构化数据“instituteofradiophysicsandelectronics,universityofcalcutta,1,girishvidyaratnalane,kolkata700009,westbengal,india;internationalinstituteofinformationtechnology,x-1,8/3,blockep,sectorv,saltlakeelectronicscomplex,kolkata,700091,westbengal,india”经实体抽取得到国家实体列表[‘india’,’india’]和机构实体列表[‘universityofcalcutta’,’internationalinstituteofinformationtechnology’]抽取时保证列表中元素的一一对应,若出现抽取结果为空,则用占位符如“##”保证对应顺序,如此,根据机构实体类别和国家实体类别在各自列表中的位置,即可实现两种实体的一一对应,此时就可以根据两种实体类别结合知识图谱的整体框架进行模式匹配。如根据:机构类实体——机构所属国家——国家,这一匹配模式得到:universityofcalcutta——机构所属国家——india;internationalinstituteofinformationtechnology——机构所属国家——india;
步骤s33,基于整体框架中实体类别间的关系,找到与采集信息对应的第一实体类别有关系的第二多实体类别和第三多实体类别,基于双向lstm的多标签分类法获得所述信息所属的第二多实体类别和第三多实体类别的子实体类别。
在步骤s31中,所述对于非结构化数据基于规则的最大正向匹配法识别实体的步骤包括:
设定最大匹配字数为num=max(实体长度集和),例如,num=max(国家名长度集和);
从实体对应的词典中获得实体名集合,按照长度由大到小的顺序对实体名进行排序,例如,匹配词典为{国家名集合},将词典中国家按国家名长度由大到小进行排序。
对采集的文本进行分段,获得每个字段的单词书,例如,对于第n个字段,
判断字段的字数是否不大于最大匹配字数;
如果字段的字数不大于最大匹配字数,则对字段从前往后取最大匹配字数的子字段,判断在实体名集中是否存在匹配结果,如果存在获得实体;如果不存在,减掉一个字(优选地,减掉最前面或最后面一个字),依次减少子字段的字数,重复匹配过程,直到获得实体,例如,若m<=num,则对
如果字段的字数大于最大匹配字数,则对字段从前往后取最大匹配字数的子字段,判断在实体名集中是否存在匹配结果,如果存在获得实体;如果不存在,减掉一个字,再从前往后取最大匹配字数的子字段,重复截取子字段和匹配,直到获得实体,例如,若m>num,则对in的前m个单词按第一种情况先检查是否有命中的国家实体,若检测到,则结束匹配。若在前m个单词中没有检测到国家实体,则更新取词范围为第(1,m+1)个单词,再次检测。重复更新、检测的步骤直到检测到国家实体或更新范围到in的最大范围。
以“theunitedkingdomofgreatbritainandnorthernireland”,为例,假设词典中包含的国家名为{“unitedkingdomofgreatbritainandnorthernireland”,“ireland”}
则,num=8,m=9。
先检查“theunitedkingdomofgreatbritainandnorthern”中的匹配情况,可以发现检测不到匹配实体,因此更新取词范围为“unitedkingdomofgreatbritainandnorthernireland”,此时将先匹配到“unitedkingdomofgreatbritainandnorthernireland”这个实体,而不会误识别“ireland”。
在步骤33中,如图4所示,包括:
设定第二多实体类别和第三多实体类别的各子实体类别的分类要使用的信息;
通过翻译接口将当前分类要使用的信息进行格式统一,所述信息包括文献、专利和产品的关键词和标题,如:文献标题、文献摘要、文献关键词统一成英文格式,以第三多实体类别为例,所述信息分类要使用的信息可能包括文献的标题、关键词等;
利用格式统一后的相关信息训练领域词向量库,所述领域词向量库是太赫兹领域的词向量库,可以使用获取到的所有文献的英文标题、英文摘要、英文关键词作为训练材料,通过genism库提供的word2vec模型训练得到的每个词的词向量构成的词向量库;
通过领域词向量库获得分类要使用的信息中每个词的词向量,优选地,对所有文献信息的最长长度、最短长度、平均长度、长度众数进行统计,根据统计结果,取合适的长度值(由于长度过短会导致部分文献信息输入不全,而长度过长会导致信息较短的文献信息由于补零操作造成信息模糊。因此在长度选取时,保证95%的文献都能有完整信息输入的前提下,对超出选取长度的文献进行截断,如:经统计95%的文献信息长度均小于150,则取150作为标准长度)为标准长度值,在文本数字化过程中对长度值不够的数据采取补零操作,长度超出标准长度的数据进行截断操作;
将每个样本的分类要使用的信息通过词嵌入层将表示成向量嵌入的形式;
将嵌入形式的每个样本序列输入双向lstm,获得每个样本序列的上下文信息作为分类特征;
将lstm层提取到的分类特征输入池化层和全连接层,进行特征选择和降维,保留与分类相关的核心特征;
将所述分类相关核心特征输入分类器(例如采用sigmoid分类器进行多标签分类),获得信息与每个子实体类别的置信度;
根据预设的置信度阈值,将信息归属到超过所述置信度阈值的子实体类别,例如,双向lstm的输入是“用于提取分类特征的文本信息”,如,判断文献是否属于某个研究领域时,将文献的标题、摘要和关键词作为输入;输入信息经过词嵌入后,每个单词都会表示成词向量,通过向量间的相似度理解文本信息。分类器的输出是对应的置信度。
在一个优选实施例中,如图5所述,子实体类别可以分级,例如所述领域实体类别,将硬件和软件作为第一级子实体类别,硬件第一级子实体类别包括太赫兹源、二极管、探测器、调制器、材料、晶体管和天线等第二级子实体类别,软件第一级子实体类别可以包括太赫兹成像、分辨率、扫描、筛选和算法等第二级子实体类别,12个领域的第二级子实体类别,通过分类器来判断某篇文献与这些第二级子实体类别的关系,即:“文献属于该领域”或者“文献不属于该领域”。通过分类器我们可以得到文献是否属于这些领域的第二级子实体类别的置信度,12个领域的第二级子实体类别即有12个置信度数值与之一一对应。置信度范围在0~1之间,默认大于等于0.5即为存在对应关系,否则视为不存在该关系,将文献归属于存在关系的第二级子实体类别。
以文献实体和领域实体为例,文献实体的数量与数据采集得到的文献数量有关是不固定的,而领域实体是太赫兹这一领域下具体的研究方向,数量是固定的。采用双向lstm网络的多标签分类法判断文献所属领域时,若同时存在中文文献和英文文献,则先通过翻译接口将中文文献的文献名、关键词和摘要信息都转化为英文形式。采用英文形式作为统一形式,利用英文文本天然的空格分隔可避免训练词向量时的分词不当带来的噪声。
而后将文献名、摘要和关键词作为训练语料,通过gensim的word2vec接口训练领域词向量。词的语意越相近,在向量空间中的距离就越接近。以余弦相似度为相似度计算公式:
其中,a、b表示训练后得到的词向量,n表示词向量的维度。
而后,将待分类样本按照(
由于此处的分类属于多标签分类,因此在输出层采用sigmoid函数作为激活函数,并采用二元交叉熵损失作为损失函数,
其中,
在步骤s4中,所述知识融合的步骤包括:
对实体的形式进行统一,针对英文实体的不同时态、单复数形式、不同词性形式,借助翻译接口(百度翻译平台的开放api)对英文实体进行翻译,通过翻译结果完成上述形式造成的异形同义状况的消歧;对实体的大小写形式也进行了统一,避免大小写不一致导致的信息冗余,例如,如实体“thz”,“thz”,“terahertz”,“terahertz”经翻译后,统一表示为“太赫兹”这一实体;
通过数据库对实体和相关字段的映射关系进行数据融合,获得实体的属性,例如,在第三方库的融合部分选取了百度百科数据和百度企业信用数据作为数据源,进行数据融合时主要根据实体名称和相关字段的映射关系进行数据的融合。
优选地,当子实体类别分别度高、类别互斥时,基于预定义的关键词和关键词与所定义的实体类别间的关系采用词匹配法获得所述信息所属的子实体类别,例如,如图3c所示,第二实体类别中的机构实体类别包括教育类机构和非教育类机构两个子实体类别,直接对实体名字(关键词)采用词匹配法分类,分类简单快速,以“communicationunivofchina”这一机构为例,根据词匹配法,匹配到关键词univ后,将其归类到“教育类机构”。
在一个实施例中,在步骤s3之前还包括步骤s2,数据清洗的步骤,所述数据清洗的步骤包括:
删除重复数据和无效数据,获得有效记录字段,所述无效数据是针对实体类别的关键字段缺失的数据,所述关键字段是实体类别必不可少的信息,例如,缺少文献名称的文献数据,属于无效数据;缺少专利号的专利数据,属于无效数据,优选地,使用pandas库,对csv数据表的重复行进行了剔除工作,同时对获取到的部分缺失主要标识符或无关的数据进行删除,标识符缺失数据的删除主要通过对定义的标识符字段进行空值判断来处理;
剔除有效记录字段(删除重复数据和无效数据后的数据)中的杂质数据,所述杂质数据为类乱码和无关符号的数据,如以下文献标题:“high-<formulaformulatype="inline"><tex>$t_{c}$</tex></formula>josephsonsquare-lawdetectorsandhilbertspectroscopyforsecurityapplications”中的“<formulaformulatype="inline"><tex>”等符号,这些符号是网页中的格式控制符,不算是文献标题内容的一部分,杂质数据的判断通常在完成数据获取后,通过数据观察判断得出结论;优选地,采用正则表达式库re,通过总结杂质数据的出现规则,定义相应的正则表达式,对杂质数据进行了剔除,例如,在杂质数据的完成判断后,通过筛选出的所有杂质数据,分析其出现规则,如:标题中出现“<”和”</”这种尖括号对时,说明有网页格式控制符存在;
对齐异构数据源数据字段,优选地,采用字段映射的方式对齐异构数据源数据字段,以cnki与ieee的文献数据为例,二者的作者字段分别表示成“作者-author”和“author”,通过建立字段映射表,将异构数据源的字段进行映射,从而整合成同种格式的数据;
统一数据编码格式,优选地,针对数据中不同的编码格式进行处理将其统一成utf-8形式的编码;针对unicode字符,通过htmlparser库进行转换;其他形式的编码通过读取和写入文件时指定对应的编码格式来实现转换。
在一个实施例中,上述太赫兹知识图谱构建方法还包括以下步骤中的一个或多个:
步骤s5,知识推理步骤,所述知识推理步骤采用通过演绎推理对实体间的关系进行进一步挖掘,
如:作者实体a1发表的文献信息为da1={d1,d2,d5},作者实体a2发表的文献信息为da2={d2,d3,d6},作者实体a1属于机构实体i1,作者实体a2属于机构实体i2。aco表示作者合作发表的文献,ico表示机构合作发表的文献,由
则
步骤s6,数据存储,例如,采用了turtle格式作为数据的主要存储形式,同时配合关系数据库mysql。采用的turtle格式是简化的rdf格式。基于python的rdflib实现关系数据库向turtle格式数据的转化。
在一个实施例中,还包括步骤s7,知识图谱可视化的步骤,所述知识图谱可视化的步骤包括在显示终端通过web应用框架显示知识图谱,包括:
通过浏览器接收客户端的http请求;
将所述http请求发送给web服务器网管关口;
通过统一资源定位器指定信息位置,并发送给视图函数;
视图函数使用httprequest对象,在数据存储层请求数据;
数据存储层调用数据库数据,根据视图函数中需要的对象从数据库中提取相应数据到视图函数中,在视图函数中进行数据处理之后通过模板语言传入表现层,表现层返回http请求到浏览器,展现给用户。
优选地,所述知识图谱可视化的步骤还包括:
对知识图谱进行整体展示或者对知识图谱按照实体类别进行分模块展示。
在一个具体实施例中,如图6所示,运用django框架实现知识图谱可视化,具体地,包括:
基于django框架,构建太赫兹知识图谱网站,网站的展示页面架构组成如图7所示,包括主页、研究文献、作者人物、产品专利、研究机构、会议论坛、研究领域、基金、实体词典、组合检索和个人中心等模块。
构建网站的功能性架构如图8所示,包括:
分布地图、关系图的展示:地图、关系图应用echarts和javascript图表库;
表格展示:表格应用javascript脚本语言和css层叠样式表,由javascript实现表格翻页功能、css实现表格的美化功能;
用户登录注册功能;
搜索功能,包括模糊搜索和组合搜索,所述模糊搜索是在各个分页面都嵌入搜索器,只能搜索本页面的相关内容,并显示出搜索结果;所述组合搜索,以第一搜索为主体,第二搜索为条件进行搜索,可搜索出相应符合条件的结果。优选地,在django框架中搜索功能的实现步骤包括:在models.py中从数据库提取所需数据;获取页面输入数据形成目标url;views.py中获取目标url中的数据;views.py中引入models中已提取的数据,并在其中提取目标url的相关内容;返回目标页面需要的数据;html页面接收views.py传来的数据。
信息添加与修改功能,不同账户设置不同的修改权限,例如:普通账户可修改自身信息;专家账户可修改自身信息,可提交并添加文献、作者、机构等专业信息。专家用户可添加系统中暂无的数据,有选填和必填项,提交后台审核后加入数据库。
本发明所述太赫兹知识图谱构建方法构建了太赫兹领域知识图谱,针对互联网领域捕获的太赫兹领域相关信息,如:太赫兹机构、太赫兹相关文献等根据构建的太赫兹知识图谱框架,通过数据预处理、数据标准化、数据融合与挖掘,提取数据间关系等流程构造领域知识图谱,最终以网站的形式进行可视化呈现,并允许用户通过网站提交现有图谱中的缺失数据,经核验后用于进一步完善图谱。
上述太赫兹知识图谱构建方法划分了不同实体类别,使得采集的信息能够快速准确的分类到各实体类别,快速丰富了知识图谱的内容。
图9是本发明所述太赫兹知识图谱构建系统的构成框图,如图9所示,所述太赫兹知识图谱构建系统包括:
框架构建部1,构建知识图谱的整体框架,所述整体框架包括实体类别、属性类别及各实体类别间的关系,将实体类别划分为第一实体类别、第二实体类别和第三实体类别,第一实体类别是从数据源直接采集所有实体属性信息的实体类别,第二实体类别是从第一实体类别采集到的信息中抽取得到实体,而后通过第三方数据源进一步扩充实体属性的实体类别,第三实体类别为根据现有信息给定的实体,按照是否存在子实体类别分别将第二实体类别和第三实体类别划分为第二单实体类别、第二多实体类别、第三单实体类别和第三多实体类别,通过第一实体类别对应数据源采集信息,其中,实体是客观存在并可相互区分的事物,所述实体类别是同类实体的集合,所述属性类别是一个类别的实体具有的属性信息,所述实体类别间的关系是设定的实体类别间符合语义逻辑的关系;
采集部2,从数据源采集框架构建部构建的所述整体框架相关的信息;
抽取部3,对采集部采集的信息根据所述整体框架进行数据抽取;
融合部4,对整体框架及其对应的抽取的数据进行融合,形成知识图谱,
其中,所述抽取部3包括:
实体抽取模块31,基于整体框架中实体类别间的关系,找到与采集信息对应的第一实体类别有关系的其他第一实体类别、第二单实体类别和第三单实体类别,根据第一实体类别、第二单实体类别和第三单实体类别的属性类别对采集的信息进行实体抽取,包括:将采集的信息中的数据进行分类,所述分类包括结构化数据、半结构化数据和非结构化数据;对于结构化数据通过其数据字段得到实体;对于非结构化数据基于规则的最大正向匹配法识别实体;对于半结构化的数据采用基于正则表达式和模板的方式提取实体;
关系抽取模块32,采用模式匹配的方式在结构化数据和半结构化数据上抽取实体间的关系;对于非结构化数据基于实体抽取时的规则采用模式匹配的方式抽取实体间的关系,所述实体间的关系属于所述实体类别间的关系;
分类模块33,基于整体框架中实体类别间的关系,找到与采集信息对应的第一实体类别有关系的第二多实体类别和第三多实体类别,基于双向lstm的多标签分类法获得所述信息所属的第二多实体类别和第三多实体类别的子实体类别。
在一个实施例中,还包括:
可视化部5,对融合部获得的知识图谱进行可视化,在显示终端通过web应用框架显示知识图谱。
本发明所述太赫兹知识图谱构建系统针对互联网领域的太赫兹领域相关的信息进行采集、处理整合和通过网站的方式进行可视化呈现。
尽管前面公开的内容示出了本发明的示例性实施例,但是应当注意,在不背离权利要求限定的范围的前提下,可以进行多种改变和修改。根据这里描述的发明实施例的方法权利要求的功能、步骤和/或动作不需以任何特定顺序执行。此外,尽管本发明的元素可以以个体形式描述或要求,但是也可以设想具有多个元素,除非明确限制为单个元素。
- 还没有人留言评论。精彩留言会获得点赞!