信息处理装置、信息处理方法和计算机可读存储介质与流程
1.本公开涉及信息处理领域,具体涉及信息处理装置、信息处理方法和计算机可读存储介质。
背景技术:
2.随着机器学习的发展,基于机器学习获得的分类模型也获得日益广泛的关注,并且在图像处理、文本处理、时序数据处理等各种领域获得越来越多的实际应用。
3.在机器学习中,许多学习任务基于以下假设:训练数据集和测试数据集来自同一分布。实际上,这种假设可能不成立,尤其在迁移学习任务中。在迁移学习中,由于环境变化、采样方法、数据模态等诸多因素,从不同域收集的数据会发生强烈的域偏移(domain shift),从而导致分类模型的分类精度劣化。因此,期望提供一种在迁移学习任务中能够改进分类模型的分类精度的方法。
技术实现要素:
4.在下文中给出了关于本公开的简要概述,以便提供关于本公开的某些方面的基本理解。但是,应当理解,这个概述并不是关于本公开的穷举性概述。它并不是意图用来确定本公开的关键性部分或重要部分,也不是意图用来限定本公开的范围。其目的仅仅是以简化的形式给出关于本公开的某些概念,以此作为稍后给出的更详细描述的前序。
5.本公开的目的是提供一种改进的信息处理装置、信息处理方法和计算机可读存储介质,其至少使得能够提高分类模型的分类精度。
6.根据本公开的一方面,提供了一种信息处理装置,包括:源数据集筛选单元,被配置成对源数据集进行筛选,以去除所述源数据集中的属于非共享类别的源数据中的部分源数据,其中,所述源数据集的真实类别是已知的,所述非共享类别是所述源数据集所包括的类别中的除共享类别之外的类别;以及模型训练单元,被配置成利用目标数据集和所述源数据集中的经过所述源数据集筛选单元进行筛选之后的剩余的源数据,对预先训练的分类模型进行进一步训练,以使综合损失符合预定条件,从而得到最终模型。其中,所述目标数据集的真实类别是未知的,所述目标数据集所包括的类别是所述源数据集所包括的类别的子集,并且所述共享类别是指所述子集中的类别;其中,所述综合损失包括所述预先训练的分类模型的分类损失和修正损失,以及其中,所述修正损失用于表征所述目标数据集中的第一目标数据的、通过所述预先训练的分类模型所得到的分类结果的误差。其中,所述第一目标数据是指所述目标数据集中的、通过所述预先训练的分类模型被分类为所述非共享类别的目标数据。
7.根据本公开的另一方面,提供了一种信息处理方法,包括:源数据集筛选步骤,用于对源数据集进行筛选,以去除所述源数据集中的属于非共享类别的源数据中的部分源数据,其中,所述源数据集的分类结果是已知的,所述非共享类别是所述源数据集所包括的类别中的除共享类别之外的类别;以及模型训练步骤,用于利用目标数据集和所述源数据集
中的经过所述源数据集筛选步骤进行筛选之后的剩余的源数据,对预先训练的分类模型进行进一步训练,以使综合损失符合预定条件,从而得到最终模型,其中,所述目标数据集的真实类别是未知的,所述目标数据集所包括的类别是所述源数据集所包括的类别的子集,并且所述共享类别是指所述子集中的类别;其中,所述综合损失包括所述预先训练的分类模型的分类损失和修正损失,以及其中,所述修正损失用于表征所述目标数据集中的第一目标数据的、通过所述预先训练的分类模型所得到的分类结果的误差,其中,所述第一目标数据是指所述目标数据集中的、通过所述预先训练的分类模型被分类为所述非共享类别的目标数据。
8.根据本公开的其它方面,还提供了用于实现上述根据本公开的方法的计算机程序代码和计算机程序产品,以及其上记录有该用于实现上述根据本公开的方法的计算机程序代码的计算机可读存储介质。
9.在下面的说明书部分中给出本公开实施例的其它方面,其中,详细说明用于充分地公开本公开实施例的优选实施例,而不对其施加限定。
附图说明
10.本公开可以通过参考下文中结合附图所给出的详细描述而得到更好的理解,其中在所有附图中使用了相同或相似的附图标记来表示相同或者相似的部件。所述附图连同下面的详细说明一起包含在本说明书中并形成说明书的一部分,用来进一步举例说明本公开的优选实施例和解释本公开的原理和优点。其中:
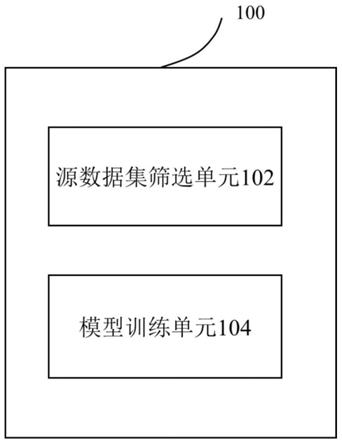
11.图1是示出根据本公开的实施例的信息处理装置的功能配置示例的框图;
12.图2是示出根据本公开的实施例的信息处理装置的一种具体实现方式的架构示例的框图;
13.图3a和图3b示出预先训练的分类模型和根据本公开的实施例的信息处理装置获取的最终模型的分类精度之间的比较;
14.图3c示出根据本公开的实施例的信息处理装置的不同功能模块对最终模型的分类精度的影响;
15.图4是示出根据本公开的另外的实施例的信息处理装置的功能配置示例的框图;
16.图5是示出根据本公开的另外的实施例的信息处理装置的一种具体实现方式的架构示例的框图;
17.图6a、图6b、图6c和图6d是示出根据本公开的另外的实施例的信息处理装置的一种具体操作示例的示意图;
18.图7是示出根据本公开的实施例的信息处理方法的流程示例的流程图;
19.图8是示出根据本公开的另外的实施例的信息处理方法的流程示例的流程图;以及
20.图9是示出作为本公开的实施例中可采用的个人计算机的示例结构的框图。
具体实施方式
21.在下文中将结合附图对本公开的示范性实施例进行描述。为了清楚和简明起见,在说明书中并未描述实际实施方式的所有特征。然而,应该了解,在开发任何这种实际实施
例的过程中必须做出很多特定于实施方式的决定,以便实现开发人员的具体目标,例如,符合与系统及业务相关的那些限制条件,并且这些限制条件可能会随着实施方式的不同而有所改变。此外,还应该了解,虽然开发工作有可能是非常复杂和费时的,但对得益于本公开内容的本领域技术人员来说,这种开发工作仅仅是例行的任务。
22.在此,还需要说明的一点是,为了避免因不必要的细节而模糊了本公开,在附图中仅仅示出了与根据本公开的方案密切相关的设备结构和/或处理步骤,而省略了与本公开关系不大的其它细节。
23.下面结合附图详细说明根据本公开的实施例。
24.首先,将参照图1和图2描述根据本公开的实施例的信息处理装置100的实现示例。图1是示出根据本公开的实施例的信息处理装置100的功能配置示例的框图。图2是示出根据本公开的实施例的信息处理装置100的一种具体实现方式的架构示例的框图。在图2中,xs和x
t
分别表示源数据和目标数据,ys和y
t
分别表示源数据和目标数据的通过预先训练的分类模型(下文中,可以称为“基础模型”)的分类结果,gf(xs)和gf(x
t
)分别表示源数据和目标数据的通过预先训练的分类模型所提取的特征,gy(xs)和gy(x
t
)分别源数据和目标数据作为输入时预先训练的分类模型的输出。
25.如图1和图2所示,根据本公开的实施例的信息处理装置100可以包括源数据集筛选单元102和模型训练单元104。
26.源数据集筛选单元102可以被配置成对源数据集进行筛选,以去除源数据集中的属于非共享类别的源数据中的部分源数据,其中,源数据集的真实类别(即,标签)是已知的,非共享类别是源数据集所包括的类别中的除共享类别之外的类别。
27.例如,源数据集筛选单元102可以利用表示源数据集所包括的各个类别是否是共享类别或者源数据集所包括的各个类别是共享类别的概率的共享类别分布来对源数据集进行筛选。例如,可以通过luo y,wang z,huang z,et al.progressive graph learning for open-set domain adaptation[j].(icml 2020)中所公开的技术来获得共享类别分布为了防止将源数据集中的某个类别的所有数据均去除,可以引入随机种子来控制筛选处理。例如,筛选处理可以用下式(1)来表示:
[0028][0029]
其中,是筛选矩阵,可以基于和λ1而输出0或1。λ1是超参数,可以用于控制对源数据集的去除率。xs和ds分别是源数据和源数据集。
[0030]
模型训练单元104可以被配置成利用目标数据集和源数据集中的经过源数据集筛选单元102进行筛选之后的剩余的源数据,对预先训练的分类模型进行进一步训练,以使综合损失符合预定条件,从而得到最终模型。其中,目标数据集的真实类别是未知的,目标数据集所包括的类别是源数据集所包括的类别的子集,并且共享类别是指上述子集中的类别。也就是说,共享类别是源数据集和目标数据集两者均包括的类别。综合损失l包括预先训练的分类模型的分类损失lm和修正损失l
sa
。修正损失用于表征目标数据集中的第一目标数据的、通过预先训练的分类模型所得到的分类结果的误差,其中,第一目标数据是指目标数据集中的、通过预先训练的分类模型被分类为非共享类别的目标数据。
[0031]
作为示例,上述预定条件是以下中之一:综合损失达到最小值;综合损失小于或等
于预定阈值;以及训练达到预定次数。
[0032]
例如,模型训练单元104可以利用目标数据集和源数据集中的经过源数据集筛选单元102进行筛选之后的剩余的源数据,在使综合损失最小化或者小于或等于预定阈值的基础上,对预先训练的分类模型进行进一步训练,从而得到最终模型。此外,例如,模型训练单元104可以利用目标数据集和源数据集中的经过源数据集筛选单元102进行筛选之后的剩余的源数据,在使综合损失减小的基础上,对预先训练的分类模型训练预定次数,从而得到最终模型。注意,在图2中,未做标记的箭头所对应的处理是针对所有类别执行的处理,标记为
①
和
②
的箭头所对应的处理分别是仅针对共享类别执行的处理和仅针对非共享类别执行的处理。另外,在图2中,虚线框所对应的功能模块(即,l
sa
)不是必需的。
[0033]
预先训练的分类模型可以是任意分类模型,包括但不限于领域对抗神经网络(domain-adversarial neural network,dann)模型(参见ganin y,ustinova e,ajakan h,et al.domain-adversarial training of neural networks[j].the journal of machine learning research,2016,17(1):2096-2030)、卷积神经网络(convolutional neural network,cnn)模型等。此外,预先训练的分类模型可以是预先使用任意数据集进行训练而得到的。例如,预先训练的分类模型可以是预先使用包括源数据的所有类别的数据集进行训练而得到的。
[0034]
作为示例,可以基于预先训练的分类模型的、针对所述第一目标数据的第一输出和第二输出来计算修正损失。第一输出是在第一目标数据用作预先训练的分类模型的输入的情况下,预先训练的分类模型的输出。第二输出是在第一目标数据用作预先训练的分类模型的输入且将第一目标数据的通过预先训练的分类模型的分类结果固定为如下类别的情况下,预先训练的分类模型的输出:该类别是共享类别中的、属于该类别的源数据的特征的分布的中心距第一目标数据的特征最近的类别。
[0035]
例示而非限定,预先训练的分类模型的输出可以是预先训练的分类模型的损失层之前的一层所提取的输入数据的特征。例如,在预先训练的分类模型是包括全连接层和至少一个卷积层的卷积神经网络模型的情况下,预先训练的分类模型的输出可以是通过全连接层所提取的输入数据的特征。此外,在预先训练的分类模型是上述卷积神经网络模型的情况下,目标数据的特征可以是通过全连接层或一个卷积层所提取的目标数据的特征。
[0036]
例如,可以通过下式(2)获得共享类别中的、属于其的源数据的特征的分布的中心距第一目标数据的特征最近的类别y
mdcs
(x
t
)。
[0037]ymdcs
(x
t
)=i,for i∈cs,select min(‖sc[i]-gf(x
t
)‖2)
ꢀꢀ
(2)
[0038]
在式(2)中,gf(x
t
)是目标数据x
t
的通过预先训练的分类模型所提取的特征,sc[i]表示属于第i类别的源数据的特征的分布的中心,并且cs是共享类别。
[0039]
例示而非限定,可以通过第一目标数据的第一输出和第二输出的交叉熵来计算修正损失。例如,可以通过下式(3)来计算修正损失。
[0040][0041]
在式(3)中,x
t
~t
ptap
表示目标数据x
t
选自第一目标数据的集合t
ptap
,gy(x
t
)和g
mdcs
(x
t
)表示针对目标数据x
t
的第一输出和第二输出,并且表示求和。
[0042]
注意,虽然在上面描述了基于预先训练的分类模型的、针对所述第一目标数据的
第一输出和第二输出来计算修正损失,然而本领域技术人员可以根据实际需要采用其他方式来计算修正损失,这里将不再赘述。
[0043]
在迁移学习中,除了域偏移和目标域中缺少标签(即,目标数据集的真实类别是未知的)之外,源标签分布和目标标签分布之间的差异也可能对模型造成很大的破坏。例如,在图像识别任务中,希望将使用imagenet数据集进行预先训练而得到的模型迁移到私有数据集。imagenet数据集具有1000多个类别,而私有数据集可能会缺失许多类别。由于私有数据集中没有标签,也没有缺失类的分布,因此,如果直接应用uda(unsupervised domain adaptation)方法,则私有数据集中的样本很可能会被分类为非共享类别,从而导致负迁移。鉴于此,可以使用基于puda(partial unsupervised domain adaptation)的方法,例如,pada(partial adversarial domain adaptation)、uda(universal domain adaptation)、pgl(progressive graph learning)等。
[0044]
对于puda,源数据集(即,源域)的真实类别是已知的,目标数据集(即,目标域)的真实类别是未知的,并且源数据集所包含的类别可以覆盖目标数据集所包含的类别。闭合度可以定义为ζ=n
t
/ns,其中n
t
和ns分别是目标数据集所包含的类别数目和源数据集所包含的类别数目。ζ越小意味着知识共享越少,通常带来更高的负迁移风险。在puda中,主要挑战是在源域和目标域之间对齐共享类别。ζ越小,出现对准错误的可能性越大,从而导致获得的分类模型的分类精度降低。
[0045]
根据本公开的实施例的信息处理装置100对源数据集进行筛选,利用目标数据集和经过筛选的源数据,对预先训练的分类模型进行进一步训练,并且在训练过程中引入修正损失,使得可以改进源数据集与目标数据集之间的共享类别的对齐,从而可以提高分类模型的分类精度。
[0046]
此外,根据本公开的实施例的信息处理装置100具有很强的通用性,可以容易地应用于任何方法。再者,信息处理装置100具有鲁棒性,不会发生消极迁移且可以较好地抵抗目标域由于类别缺失导致的训练难题。另外,根据本公开的实施例的信息处理装置100采用的是轻量级算法。在训练过程的每次迭代中,附加的时间复杂度为线性阶(即,所消耗的时间与数据量呈线性关系),并且附加的空间复杂度取决于一层的特征的维度和类别数目的乘积,该乘积始终比基础模型的空间复杂度小得多。
[0047]
根据本公开的实施例,综合损失还可以包括对齐损失,对齐损失用于表征目标数据集中的第二目标数据的、通过预先训练的分类模型所提取的特征的分布和源数据集中的属于共享类别的源数据的、通过预先训练的分类模型所提取的特征的分布之间的差异,以及其中,第二目标数据是指目标数据集中的、通过预先训练的分类模型被分类为共享类别的目标数据。
[0048]
例如,可以通过下式(4)来计算对齐损失:
[0049][0050]
在式(4)中,rand2表示生成平均分布随机数,其随机种子为共享类别分布λ2为超参数,用于调整最终生成的随机数的范围。此外,sc[i]表示属于第i类别的源数据的特征的分布的中心,tc[i]表示通过预先的分类模型被分类为第i类别的目标数据的特征的分布的中心,并且表示求和。
[0051]
通过如上所述的那样引入对齐损失,可以进一步提高最终模型的分类精度。
[0052]
为了更好地说明根据本公开的实施例的信息处理装置100在提高分类精度方面的有益效果,下面将参照图3a、图3b和图3c,结合基于办公室-家庭数据集的puda任务的具体示例对该有益效果进行说明。
[0053]
办公室-家庭数据集具有四个域,即art(a)、clipart(c)、product(p)和real world(r)。每个域包含相同的65个类别。在示例中,按字母顺序使用前10个类别作为共享类别,其余55个类别作为开放类别。在测试过程中,使用来自目标域的整个数据集,并且使用预先训练的dann模型作为基础模型,其中置信度低于0.5的模型输出所对应的类别被标记为未知类别。在图3a至图3c中,os*是针对共享类别的分类精度,而os是针对共享类别和未知类别的分类精度。
[0054]
图3a示出预先训练的dann模型和根据本公开的信息处理装置100对预先训练的dann模型进行进一步训练所得到的最终模型(在图3a中表示为“dann+ebb”)的、针对不同的源数据集和目标数据集的分类精度。对于a-c、a-p、a-r、c-a、c-p、c
–
r、p-a、p-c、p-r、r-a、r-c和r-p,
“-”
左边的字母的表示源数据集,并且
“-”
右边的字母表示目标数据集。例如,对于a-c,源数据集为a域,目标数据集为c域。
[0055]
从图3a可见,根据本公开的信息处理装置100对预先训练的dann模型进行进一步训练所得到的最终模型的分类精度的均值avg为74.4%,而预先训练的dann模型的分类精度的均值avg为54.9%。由此可见,根据本公开的实施例的信息处理装置100能够提高预先训练的分类模型的分类精度。
[0056]
图3b示出预先训练的dann模型和通过根据本公开的信息处理装置100所获得的最终模型在不同闭合度ζ的情况下的分类精度。在图3b所示出的示例中,目标数据集为p域并且包含10个类别,源数据集为r域。从图3b可见,通过根据本公开的实施例的信息处理装置100所获得的最终模型在闭合度ζ低的情况下,也可以获得良好的分类精度。
[0057]
图3c示出根据本公开的实施例的信息处理装置100的不同功能模块对最终模型的分类精度的影响。在3c所示出的示例中,源数据集为r域,并且包含65个类别;目标数据集为a域,并且包含10个类别。此外,在图3c中,“无数据筛选单元”表示综合损失包括预先训练的分类模型的分类损失、修正损失和对齐损失但是信息处理装置100不包括源数据集筛选单元102的情况,“无对齐损失”表示信息处理装置100包括源数据集筛选单元102但是综合损失不包括对齐损失的情况,并且“无修正损失”表示信息处理装置100包括源数据集筛选单元102但是综合损失不包括修正损失的情况。
[0058]
接下来,将参照图4、图5以及图6a至图6d描述根据本公开的另外的实施例的信息处理装置。图4是示出根据本公开的另外的实施例的信息处理装置400的功能配置示例的框图。图5是示出根据本公开的另外的实施例的信息处理装置400的一种具体实现方式的架构示例的框图。图6a至图6d是示出根据本公开的另外的实施例的信息处理装置400的一种具体操作示例的示意图。
[0059]
注意,在图5中,未做标记的箭头所对应的处理是针对所有类别执行的处理,标记为
①
和
②
的箭头所对应的处理分别是仅针对共享类别执行的处理和仅针对非共享类别执行的处理。另外,在图5中,虚线框所对应的功能模块(即,l
sa
)不是必需的。
[0060]
如图4和图5所示,根据本公开的另外的实施例的信息处理装置100可以包括共享
类别确定单元402、源数据集筛选单元404和模型训练单元406。源数据集筛选单元404和模型训练单元406的功能分别与上面参照图1和图2所描述的源数据集筛选单元102和模型训练单元104的功能相似,这里将不再重复说明。
[0061]
共享类别确定单元402可以被配置成利用源数据集和目标数据集的通过预先训练的分类模型所提取的特征以及目标数据集的基于预先训练的分类模型的分类结果,来获取源数据集所包括的类别中的每个类别是共享类别的概率,并且将源数据集所包括的类别中的、作为共享类别的概率大于或等于预定阈值的类别确定为共享类别。
[0062]
作为示例,共享类别确定单元402可以进一步被配置成通过如下操作来获取源数据集所包括的类别中的每个类别是共享类别的概率:针对每个类别,计算源数据集中的属于该类别的源数据的特征的分布的边界作为该类别的源特征分布边界;以及,针对每个类别,计算目标数据集中的通过预先训练的分类模型被分类为该类别的目标数据中的、特征落入该类别的源特征分布边界内的目标数据(在下文中,将称为“锚点”)的数目,并且基于数目来计算该类别是共享类别的概率。其中,对于特定类别,上述数目越大,该类别是所述共享类别的概率越大。
[0063]
例如,共享类别确定单元402可以针对每个类别,对属于该类别的各个源数据的特征进行加权平均,将所获得的结果用作该类别的源特征分布中心,并且将以该源特征分布中心为圆心且以该类别的各个源数据的特征距源特征分布中心的距离的均值作为半径的圆的圆周用作该类别的源特征分布边界。要注意的是,计算各个类别的源特征分布边界的方式不限于此。例如,在训练过程的每次迭代中,共享类别确定单元402可以通过下式(5)来计算各个类别的源特征分布边界并且判断各个目标数据是否是相应类别的锚点:
[0064][0065]
在式(5)中,表示目标数据x
t
的特征距类别gy(x
t
)的源特征分布中心的距离,的距离,表示类别gy(x
t
)的源特征分布边界。数值“1”表示目标数据x
t
是锚点,而数值“0”表示目标数据x
t
不是锚点。此外,在式(5)中,f
dim
是矩阵sc的索引,ds是源数据集,xs是源数据,n为类别gy(x
t
)的源数据(ds∧ys=gy(x
t
))的数目。λ2为超参数,λ2越大,则类别的源特征分布边界越复杂。
[0066]
接下来,将参照图6a至图6d对根据本公开的另外的实施例的信息处理装置400的一种具体操作示例进行说明。在图6a至图6d中,不同的形状表示不同的标签(即,真实类别),填充有黑色的形状表示目标数据的特征,并且无填充的形状表示源数据的特征。例如,填充有黑色的正方形
“■”
表示真实类别为
“□”
的目标数据的特征。注意,虽然在图6a至图6d中为了方便说明,示出了目标数据的真实类别,然而在实际中,目标数据的真实类别是未知的。
[0067]
图6a示出目标数据集和源数据集的特征的分布以及目标数据集的通过预先训练
的分类模型的分类结果。图6b示出每个类别的源特征分布边界和锚点数目。在图6a和图6b中,圆点虚线表示超平面,对于特定圆点虚线,特征落入该圆点虚线所限定的范围内的目标数据表示通过预先训练的分类模型被分类为相应的类别的目标数据。例如,在图6a和图6b中,特征落入左上部的圆点虚线所限定的范围内的目标数据t1、t2和t3表示通过预先训练的分类模型被分类为类别
“○”
的目标数据。类似地,特征落入右上部的圆点虚线所限定的范围内的目标数据t4、t5和t6表示通过预先训练的分类模型被分类为类别
“☆”
的目标数据。
[0068]
从图6a和图6b可以看出,源数据集包括四个类别
“○”
、
“△”
、
“□”
和
“☆”
,目标数据集包括两个类别
“△”
和
“□”
。在图6b中,点划线所绘制的圆表示各个类别的源特征分布边界。从图6b可以看出,对于类别
“○”
、
“△”
、
“□”
和
“☆”
,锚点的数目ap分别为1、4、3和0。例如,共享类别确定单元402可以基于各个类别所包括的锚点的数目,将类别
“△”
和
“□”
确定为共享类别。
[0069]
源数据集筛选单元404可以基于共享类别确定单元402所确定的共享类别,对源数据集进行筛选,以去除源数据集中的属于非共享类别(
“○”
和
“☆”
)的源数据中的部分源数据。图6c示出经过源数据集筛选单元404进行筛选之后的源数据的示例。对比图6b和图6c可以看出,非共享类别
“○”
和
“☆”
的部分源数据被去除。
[0070]
如上面所描述的,目标数据t1、t2和t3通过预先训练的分类模型被分类为非共享类别
“○”
,目标数据t4、t5和t6通过预先训练的分类模型被分类为非共享类别
“☆”
。由于被分类为非共享类别的目标数据的分类结果的错误可能性大,为此,根据本公开的实施例的信息处理装置400在对预先训练的分类模型进行进一步训练的过程中引入了修正损失。修正损失的引入相当于对目标数据集中的通过预先训练的分类模型被分类为非共享类别的目标数据(即,第一目标数据)的分类结果进行修正,以使该目标数据尽可能地被分类为该目标数据的真实类别,从而使得可以进一步提高分类精度。
[0071]
例如,对于特定第一目标数据,可以源特征分布中心距第一目标数据的特征的距离最小(min)的共享类别确定为该第一目标数据的真实类别。例如,参照图6c,对于第一目标数据t1,相比于共享类别
“□”
的特征分布中心距第一目标数据t1的特征的距离,共享类别
“△”
的特征分布中心距第一目标数据t1的特征的距离更小,因而可以将共享类别
“△”
确定为第一目标数据t1的真实类别。
[0072]
图6d示出源数据集和目标数据集的、通过经由信息处理装置400得到的最终模型所提取的特征的分布以及目标数据集的通过该最终模型的分类结果。从图6d可以看出,目标数据通过最终分类模型均被分类为共享类别。可见,最终模型可以校正目标数据集中的通过基础模型被错误地分类为非共享类别的第一目标数据的分类结果,由此可以提高分类精度。此外,通过对源数据集和目标数据集的、经由最终模型所提取的特征的分布进行分析,发现相对于源数据集和目标数据集的、经由初始的基础模型所提取的特征,对于共享类别,源数据的特征分布中心与目标数据的特征分布中心更接近。
[0073]
与上面参照图1和图2所描述的根据本公开的实施例的信息处理装置100类似地,根据本公开的另外的实施例的信息处理装置400对源数据集进行筛选,利用目标数据集和经过筛选的源数据,对预先训练的分类模型进行进一步训练,并且在训练过程中引入修正损失,使得能够提高分类模型的分类精度。此外,根据本公开的另外的实施例的信息处理装
置400具有很强的通用性,可以容易地应用于任何方法。再者信息处理装置400具有鲁棒性,不会发生消极迁移且可以较好地抵抗目标域由于类别缺失导致的训练难题。另外,根据本公开的另外的实施例的信息处理装置400采用的是轻量级算法。在训练过程的每次迭代中,附加的时间复杂度为线性阶(即,所消耗的时间与数据量呈线性关系),并且附加的空间复杂度取决于一层的特征的维度和类别数目的乘积,该乘积始终比基础模型的空间复杂度小得多。
[0074]
此外,根据本公开的另外的实施例的信息处理装置400利用源数据集和目标数据集的通过预先训练的分类模型所提取的特征以及目标数据集的基于预先训练的分类模型的分类结果,来确定共享类别分布,使得可以进一步提高分类精度。
[0075]
注意,虽然在本文中,在描述与预先训练的分类模型相关的各种特征和处理时,均使用术语“预先训练的分类模型”,然而本领域技术人员可以理解,在对预先训练的分类模型进行进一步的训练过程中,该预先训练的分类模型是可以随着进一步训练而变化的。例如,对于修正损失,在进一步的训练过程的第一次迭代中,可以基于第一目标数据的、通过最初的预先训练的分类模型所得到的分类结果的误差来获得修正损失;在进一步的训练过程的第n≥2次迭代中,可以基于第一目标数据的、通过第n-1次迭代所获得的预先训练的分类模型所得到的分类结果的误差来获得修正损失。
[0076]
上文已经描述了根据本公开的实施例的信息处理装置,与上述信息处理装置的实施例相对应的,本公开还提供了以下信息处理方法的实施例。
[0077]
图7是示出根据本公开的实施例的信息处理方法700的流程示例的流程图。如图7所示,根据本公开的实施例的信息处理方法700可以开始于开始步骤s702,并且结束于结束步骤s710。信息处理方法700可以包括源数据集筛选步骤s706和模型训练步骤s708。
[0078]
在源数据集筛选步骤s706中,可以对源数据集进行筛选,以去除源数据集中的属于非共享类别的源数据中的部分源数据,其中,源数据集的真实类别是已知的,非共享类别是源数据集所包括的类别中的除共享类别之外的类别。例如,源数据集筛选步骤s706可以通过上文描述的源数据集筛选单元102来实施,具体细节在此不再赘述。
[0079]
在模型训练步骤s708中,可以利用目标数据集和源数据集中的经过源数据集筛选步骤s706进行筛选之后的剩余的源数据,对预先训练的分类模型进行进一步训练,以使综合损失符合预定条件,从而得到最终模型。其中,目标数据集的真实类别是未知的,目标数据集所包括的类别是源数据集所包括的类别的子集,并且共享类别是指上述子集中的类别。也就是说,共享类别是源数据集和目标数据集两者均包括的类别。综合损失包括预先训练的分类模型的分类损失和修正损失。修正损失用于表征目标数据集中的第一目标数据的、通过预先训练的分类模型所得到的分类结果的误差,其中,第一目标数据是指目标数据集中的、通过预先训练的分类模型被分类为非共享类别的目标数据。例如,模型训练步骤s708可以通过上文描述的模型训练单元104来实施,具体细节在此不再赘述。
[0080]
作为示例,上述预定条件是以下中之一:综合损失达到最小值;综合损失小于或等于预定阈值;以及训练达到预定次数。
[0081]
预先训练的分类模型可以是任意分类模型,包括但不限于dann模型、cnn模型等。此外,预先训练的分类模型可以是预先使用任意数据集进行训练而得到的。例如,预先训练的分类模型可以是预先使用包括源数据的所有类别的数据集进行训练而得到的。
[0082]
作为示例,可以基于预先训练的分类模型的、针对所述第一目标数据的第一输出和第二输出来计算修正损失。第一输出是在第一目标数据用作预先训练的分类模型的输入的情况下,预先训练的分类模型的输出。第二输出是在第一目标数据用作预先训练的分类模型的输入且将第一目标数据的通过预先训练的分类模型的分类结果固定为如下类别的情况下,预先训练的分类模型的输出:该类别是共享类别中的、属于该类别的源数据的特征的分布的中心距第一目标数据的特征最近的类别。
[0083]
例示而非限定,预先训练的分类模型的输出可以是预先训练的分类模型的损失层之前的一层所提取的输入数据的特征。例如,在预先训练的分类模型是包括全连接层和至少一个卷积层的卷积神经网络模型的情况下,预先训练的分类模型的输出可以是通过全连接层所提取的输入数据的特征。此外,在预先训练的分类模型是上述卷积神经网络模型的情况下,目标数据的特征可以是通过全连接层或一个卷积层所提取的目标数据的特征。
[0084]
在puda中,主要挑战是在源域和目标域之间对齐共享类。ζ越小,出现对准错误的可能性越大,从而导致获得的分类模型的分类精度降低。
[0085]
与根据本公开的实施例的信息处理装置100类似地,根据本公开的实施例的信息处理方法700对源数据集进行筛选,利用目标数据集和经过筛选的源数据,对预先训练的分类模型进行进一步训练,并且在训练过程中引入修正损失,使得能够提高分类模型的分类精度。
[0086]
此外,根据本公开的实施例的信息处理方法700具有很强的通用性,可以容易地应用于任何方法。再者,信息处理方法700具有鲁棒性,不会发生消极迁移且可以较好地抵抗目标域由于类别缺失导致的训练难题。另外,根据本公开的实施例的信息处理方法700采用的是轻量级算法。在训练过程的每次迭代中,附加的时间复杂度为线性阶(即,所消耗的时间与数据量呈线性关系),并且附加的空间复杂度取决于一层的特征的维度和类别数目的乘积,该乘积始终比基础模型的空间复杂度小得多。
[0087]
根据本公开的实施例,综合损失还可以包括对齐损失,对齐损失用于表征目标数据集中的第二目标数据的、通过预先训练的分类模型所提取的特征的分布和源数据集中的属于共享类别的源数据的、通过预先训练的分类模型所提取的特征的分布之间的差异,以及其中,第二目标数据是指目标数据集中的、通过预先训练的分类模型被分类为共享类别的目标数据。对齐损失的引入使得可以进一步提高最终模型的分类精度。
[0088]
接下来,将参照图8描述根据本公开的另外的实施例的信息处理方法800。图8是示出根据本公开的另外的实施例的信息处理方法的流程示例的流程图。
[0089]
如图8所示,根据本公开的实施例的信息处理方法800可以开始于开始步骤s802,并且结束于结束步骤s810。信息处理方法800可以包括共享类别确定步骤s804、源数据集筛选步骤s806和模型训练步骤s808。源数据集筛选步骤s806和模型训练步骤s808中所执行的处理与上面参照图7所描述的源数据集筛选步骤s706和模型训练步骤s708中所执行的处理相似,这里将不再重复说明。
[0090]
在共享类别确定步骤s804中,可以利用源数据集和目标数据集的通过预先训练的分类模型所提取的特征以及目标数据集的基于预先训练的分类模型的分类结果,来获取源数据集所包括的类别中的每个类别是共享类别的概率,并且将源数据集所包括的类别中的、作为共享类别的概率大于或等于预定阈值的类别确定为共享类别。例如,共享类别确定
步骤s804可以通过上文描述的共享类别确定单元402来实施,具体细节在此不再赘述。
[0091]
作为示例,在共享类别确定步骤s804中,可以通过如下操作来获取源数据集所包括的类别中的每个类别是共享类别的概率:针对每个类别,计算源数据集中的属于该类别的源数据的特征的分布的边界作为该类别的源特征分布边界;以及,针对每个类别,计算目标数据集中的通过预先训练的分类模型被分类为该类别的目标数据中的、特征落入该类别的源特征分布边界内的目标数据的数目,并且基于数目来计算该类别是共享类别的概率。其中,对于特定类别,上述数目越大,该类别是所述共享类别的概率越大。
[0092]
与根据本公开的实施例的信息处理装置400类似地,根据本公开的另外的实施例的信息处理方法800对源数据集进行筛选,利用目标数据集和经过筛选的源数据,对预先训练的分类模型进行进一步训练,并且在训练过程中引入修正损失,使得能够提高分类模型的分类精度。此外,根据本公开的另外的实施例的信息处理方法800具有很强的通用性,可以容易地应用于任何方法。再者,信息处理方法800具有鲁棒性,不会发生消极迁移且可以较好地抵抗目标域由于类别缺失导致的训练难题。另外,根据本公开的另外的实施例的信息处理方法800采用的是轻量级算法。在训练过程的每次迭代中,附加的时间复杂度为线性阶(即,所消耗的时间与数据量呈线性关系),并且附加的空间复杂度取决于一层的特征的维度和类别数目的乘积,该乘积始终比基础模型的空间复杂度小得多。
[0093]
此外,根据本公开的另外的实施例的信息处理方法800利用源数据集和目标数据集的通过预先训练的分类模型所提取的特征以及目标数据集的基于预先训练的分类模型的分类结果,来确定共享类别分布,使得可以进一步提高分类精度。
[0094]
应指出,尽管以上描述了根据本公开的实施例的信息处理装置和信息处理方法的功能配置和操作,但是这仅是示例而非限制,并且本领域技术人员可根据本公开的原理对以上实施例进行修改,例如可对各个实施例中的功能模块和操作进行添加、删除或者组合等,并且这样的修改均落入本公开的范围内。
[0095]
此外,还应指出,这里的方法实施例是与上述装置实施例相对应的,因此在方法实施例中未详细描述的内容可参见装置实施例中相应部分的描述,在此不再重复描述。
[0096]
此外,本公开还提供了存储介质和程序产品。应理解,根据本公开的实施例的存储介质和程序产品中的机器可执行的指令还可以被配置成执行上述信息处理方法,因此在此未详细描述的内容可参考先前相应部分的描述,在此不再重复进行描述。
[0097]
相应地,用于承载上述包括机器可执行的指令的程序产品的存储介质也包括在本发明的公开中。该存储介质包括但不限于软盘、光盘、磁光盘、存储卡、存储棒等等。
[0098]
另外,还应该指出的是,上述系列处理和装置也可以通过软件和/或固件实现。在通过软件和/或固件实现的情况下,从存储介质或网络向具有专用硬件结构的计算机,例如图9所示的通用个人计算机900安装构成该软件的程序,该计算机在安装有各种程序时,能够执行各种功能等等。
[0099]
在图9中,中央处理单元(cpu)901根据只读存储器(rom)902中存储的程序或从存储部分908加载到随机存取存储器(ram)903的程序执行各种处理。在ram 903中,也根据需要存储当cpu 901执行各种处理等时所需的数据。
[0100]
cpu 901、rom 902和ram 903经由总线904彼此连接。输入/输出接口905也连接到总线904。
[0101]
下述部件连接到输入/输出接口905:输入部分906,包括键盘、鼠标等;输出部分907,包括显示器,比如阴极射线管(crt)、液晶显示器(lcd)等,和扬声器等;存储部分908,包括硬盘等;和通信部分909,包括网络接口卡比如lan卡、调制解调器等。通信部分909经由网络比如因特网执行通信处理。
[0102]
根据需要,驱动器910也连接到输入/输出接口905。可拆卸介质911比如磁盘、光盘、磁光盘、半导体存储器等等根据需要被安装在驱动器910上,使得从中读出的计算机程序根据需要被安装到存储部分908中。
[0103]
在通过软件实现上述系列处理的情况下,从网络比如因特网或存储介质比如可拆卸介质911安装构成软件的程序。
[0104]
本领域的技术人员应当理解,这种存储介质不局限于图9所示的其中存储有程序、与设备相分离地分发以向用户提供程序的可拆卸介质911。可拆卸介质911的例子包含磁盘(包含软盘(注册商标))、光盘(包含光盘只读存储器(cd-rom)和数字通用盘(dvd))、磁光盘(包含迷你盘(md)(注册商标))和半导体存储器。或者,存储介质可以是rom902、存储部分908中包含的硬盘等等,其中存有程序,并且与包含它们的设备一起被分发给用户。
[0105]
以上参照附图描述了本公开的优选实施例,但是本公开当然不限于以上示例。本领域技术人员可在所附权利要求的范围内得到各种变更和修改,并且应理解这些变更和修改自然将落入本公开的技术范围内。
[0106]
例如,在以上实施例中包括在一个单元中的多个功能可以由分开的装置来实现。替选地,在以上实施例中由多个单元实现的多个功能可分别由分开的装置来实现。另外,以上功能之一可由多个单元来实现。无需说,这样的配置包括在本公开的技术范围内。
[0107]
在该说明书中,流程图中所描述的步骤不仅包括以所述顺序按时间序列执行的处理,而且包括并行地或单独地而不是必须按时间序列执行的处理。此外,甚至在按时间序列处理的步骤中,无需说,也可以适当地改变该顺序。
[0108]
另外,根据本公开的技术还可以如下进行配置。
[0109]
附记1.一种信息处理装置,包括:
[0110]
源数据集筛选单元,被配置成对源数据集进行筛选,以去除所述源数据集中的属于非共享类别的源数据中的部分源数据,其中,所述源数据集的真实类别是已知的,所述非共享类别是所述源数据集所包括的类别中的除共享类别之外的类别;以及
[0111]
模型训练单元,被配置成利用目标数据集和所述源数据集中的经过所述源数据集筛选单元进行筛选之后的剩余的源数据,对预先训练的分类模型进行进一步训练,以使综合损失符合预定条件,从而得到最终模型,
[0112]
其中,所述目标数据集的真实类别是未知的,所述目标数据集所包括的类别是所述源数据集所包括的类别的子集,并且所述共享类别是指所述子集中的类别;
[0113]
其中,所述综合损失包括所述预先训练的分类模型的分类损失和修正损失,以及
[0114]
其中,所述修正损失用于表征所述目标数据集中的第一目标数据的、通过所述预先训练的分类模型所得到的分类结果的误差,其中,所述第一目标数据是指所述目标数据集中的、通过所述预先训练的分类模型被分类为所述非共享类别的目标数据。
[0115]
附记2.根据附记1所述的信息处理装置,还包括共享类别确定单元,被配置成利用所述源数据集和所述目标数据集的通过所述预先训练的分类模型所提取的特征以及所述
目标数据集的基于所述预先训练的分类模型的分类结果,来获取所述源数据集所包括的类别中的每个类别是所述共享类别的概率,并且将所述源数据集所包括的类别中的、作为所述共享类别的概率大于或等于预定阈值的类别确定为所述共享类别。
[0116]
附记3.根据附记1或2所述的信息处理装置,其中,所述综合损失还包括对齐损失,所述对齐损失用于表征所述目标数据集中的第二目标数据的、通过所述预先训练的分类模型所提取的特征的分布和所述源数据集中的属于共享类别的源数据的、通过所述预先训练的分类模型所提取的特征的分布之间的差异,以及
[0117]
其中,所述第二目标数据是指所述目标数据集中的、通过所述预先训练的分类模型被分类为所述共享类别的目标数据。
[0118]
附记4.根据附记2所述的信息处理装置,其中,所述共享类别确定单元进一步被配置成通过如下操作来获取所述源数据集所包括的类别中的每个类别是所述共享类别的概率:
[0119]
针对每个类别,计算所述源数据集中的属于该类别的源数据的特征的分布的边界作为该类别的源特征分布边界;以及
[0120]
针对每个类别,计算所述目标数据集中的通过所述预先训练的分类模型被分类为该类别的目标数据中的、特征落入该类别的源特征分布边界内的目标数据的数目,并且基于所述数目来计算该类别是所述共享类别的概率,
[0121]
其中,对于特定类别,所述数目越大,该类别是所述共享类别的概率越大。
[0122]
附记5.根据附记1或2所述的信息处理装置,其中,基于所述预先训练的分类模型的、针对所述第一目标数据的第一输出和第二输出来计算所述修正损失,
[0123]
其中,所述第一输出是在所述第一目标数据用作所述预先训练的分类模型的输入的情况下,所述预先训练的分类模型的输出,以及
[0124]
其中,所述第二输出是在所述第一目标数据用作所述预先训练的分类模型的输入且将所述第一目标数据的通过所述预先训练的分类模型的分类结果固定为如下类别的情况下,所述预先训练的分类模型的输出:该类别是所述共享类别中的、属于该类别的源数据的特征的分布的中心距所述第一目标数据的特征最近的类别。
[0125]
附记6.根据附记5所述的信息处理装置,其中,通过所述第一目标数据的第一输出和第二输出的交叉熵来计算所述修正损失。
[0126]
附记7.根据附记1或2所述的信息处理装置,其中,所述预先训练的分类模型包括领域对抗神经网络模型和/或卷积神经网络模型。
[0127]
附记8.根据附记1或2所述的信息处理装置,其中,所述预定条件是以下中之一:所述综合损失达到最小值;所述综合损失小于或等于预定阈值;以及训练达到预定次数。
[0128]
附记9.根据附记5所述的信息处理装置,其中,所述预先训练的分类模型包括卷积神经网络模型,所述卷积神经网络模型包括全连接层和至少一个卷积层;
[0129]
其中,所述预先训练的分类模型的输出是指通过卷积神经网络模型的全连接层所提取的数据的特征。
[0130]
附记10.一种信息处理方法,包括:
[0131]
源数据集筛选步骤,用于对源数据集进行筛选,以去除所述源数据集中的属于非共享类别的源数据中的部分源数据,其中,所述源数据集的真实类别是已知的,所述非共享
类别是所述源数据集所包括的类别中的除共享类别之外的类别;以及
[0132]
模型训练步骤,用于利用目标数据集和所述源数据集中的经过所述源数据集筛选步骤进行筛选之后的剩余的源数据,对预先训练的分类模型进行进一步训练,以使综合损失符合预定条件,从而得到最终模型,
[0133]
其中,所述目标数据集所包括的类别是所述源数据集所包括的类别的子集,并且所述共享类别是指所述子集中的类别;
[0134]
其中,所述综合损失包括所述预先训练的分类模型的分类损失和修正损失,以及
[0135]
其中,所述修正损失用于表征所述目标数据集中的第一目标数据的、通过所述预先训练的分类模型所得到的分类结果的误差,其中,所述第一目标数据是指所述目标数据集中的、通过所述预先训练的分类模型被分类为所述非共享类别的目标数据。
[0136]
附记11.根据附记10所述的信息处理方法,还包括共享类别确定步骤,用于利用所述源数据集和所述目标数据集的通过所述预先训练的分类模型所提取的特征以及所述目标数据集的基于所述预先训练的分类模型的分类结果,来获取所述源数据集所包括的类别中的每个类别是所述共享类别的概率,并且将所述源数据集所包括的类别中的、作为所述共享类别的概率大于或等于预定阈值的类别确定为所述共享类别。
[0137]
附记12.根据附记10或11所述的信息处理方法,其中,所述综合损失还包括对齐损失,所述对齐损失用于表征所述目标数据集中的第二目标数据的、通过所述预先训练的分类模型所提取的特征的分布和所述源数据集中的属于共享类别的源数据的、通过所述预先训练的分类模型所提取的特征的分布之间的差异,以及
[0138]
其中,所述第二目标数据是指所述目标数据集中的、通过所述预先训练的分类模型被分类为所述共享类别的目标数据。
[0139]
附记13.根据附记11所述的信息处理方法,其中,在所述共享类别确定步骤中,通过如下操作来获取所述源数据集所包括的类别中的每个类别是所述共享类别的概率:
[0140]
针对每个类别,计算所述源数据集中的属于该类别的源数据的特征的分布的边界作为该类别的源特征分布边界;以及
[0141]
针对每个类别,计算所述目标数据集中的通过所述预先训练的分类模型被分类为该类别的目标数据中的、特征落入该类别的源特征分布边界内的目标数据的数目,并且基于所述数目来计算该类别是所述共享类别的概率,
[0142]
其中,对于特定类别,所述数目越大,该类别是所述共享类别的概率越大。
[0143]
附记14.根据附记10或11所述的信息处理方法,其中,基于所述预先训练的分类模型的、针对所述第一目标数据的第一输出和第二输出来计算所述修正损失,
[0144]
其中,所述第一输出是在所述第一目标数据用作所述预先训练的分类模型的输入的情况下,所述预先训练的分类模型的输出,以及
[0145]
其中,所述第二输出是在所述第一目标数据用作所述预先训练的分类模型的输入且将所述第一目标数据的通过所述预先训练的分类模型的分类结果固定为如下类别的情况下,所述预先训练的分类模型的输出:该类别是所述共享类别中的、属于该类别的源数据的特征的分布的中心距所述第一目标数据的特征最近的类别。
[0146]
附记15.根据附记14所述的信息处理方法,其中,通过所述第一目标数据的第一输出和第二输出的交叉熵来计算所述修正损失。
[0147]
附记16.根据附记10或11所述的信息处理方法,其中,所述预先训练的分类模型包括领域对抗神经网络模型和/或卷积神经网络模型。
[0148]
附记17.根据附记10或11所述的信息处理方法,其中,所述预定条件是以下中之一:所述综合损失达到最小值;所述综合损失小于或等于预定阈值;以及训练达到预定次数。
[0149]
附记18.根据附记14所述的信息处理方法,其中,所述预先训练的分类模型包括卷积神经网络模型,所述卷积神经网络模型包括全连接层和至少一个卷积层;
[0150]
其中,所述预先训练的分类模型的输出是指通过卷积神经网络模型的全连接层所提取的数据的特征。
[0151]
附记19.一种存储有程序指令的计算机可读存储介质,当所述程序指令被计算机执行时用于执行附记10至18中任一项所述的方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1