基于深度学习和判别式模型训练的目标跟踪方法及存储器与流程
本发明涉及计算机视觉和模式识别领域,具体涉及一种基于深度学习和判别式模型训练的目标跟踪方法及存储器。
背景技术:
视觉目标跟踪是计算机视觉中的热门研究课题之一,也是基于计算机视觉的模式识别应用的一个重要研究方向。在一个视频序列中,给定第一帧中感兴趣的目标物体的状态(位置和尺寸),目标跟踪算法需要对整个视频序列中目标物体的状态进行估计。
当前,基于在线判别式模型训练的目标跟踪算法在多个公开数据库上取得了良好的精度和速度的平衡,因此,得到科研人员的广泛关注。现有的该类目标跟踪算法大多使用在目标分类任务中训练的深度卷积神经网络(例如imagenet预训练模型)进行特征提取。然而,由于目标分类任务和目标跟踪任务存在本质的区别,因此在目标分类任务中训练的深度卷积神经网络所提取的特征对目标跟踪任务并不是最优的。具体地,目标分类任务要求深度卷积神经网络对同一类别的不同实例物体输出相近的特征,然而在目标跟踪任务中要求深度卷积神经网络对视频不同帧图像中的同一实例物体(即目标跟踪物体)输出相近的特征,且与整个视频中其他所有实例物体间输出差距较大的特征,即使某一实例物体与目标跟踪物体属于同一类别。这一对特征特性需求上本质的区别严重阻碍了当前使用目标分类任务中训练的深度卷积神经网络进行特征提取的基于在线判别式模型训练的目标跟踪算法的精度提升。
技术实现要素:
为了解决现有技术中的上述问题,本发明提出了一种基于深度学习和判别式模型训练的目标跟踪方法及存储器,有效提高了目标跟踪算法的定位精度。
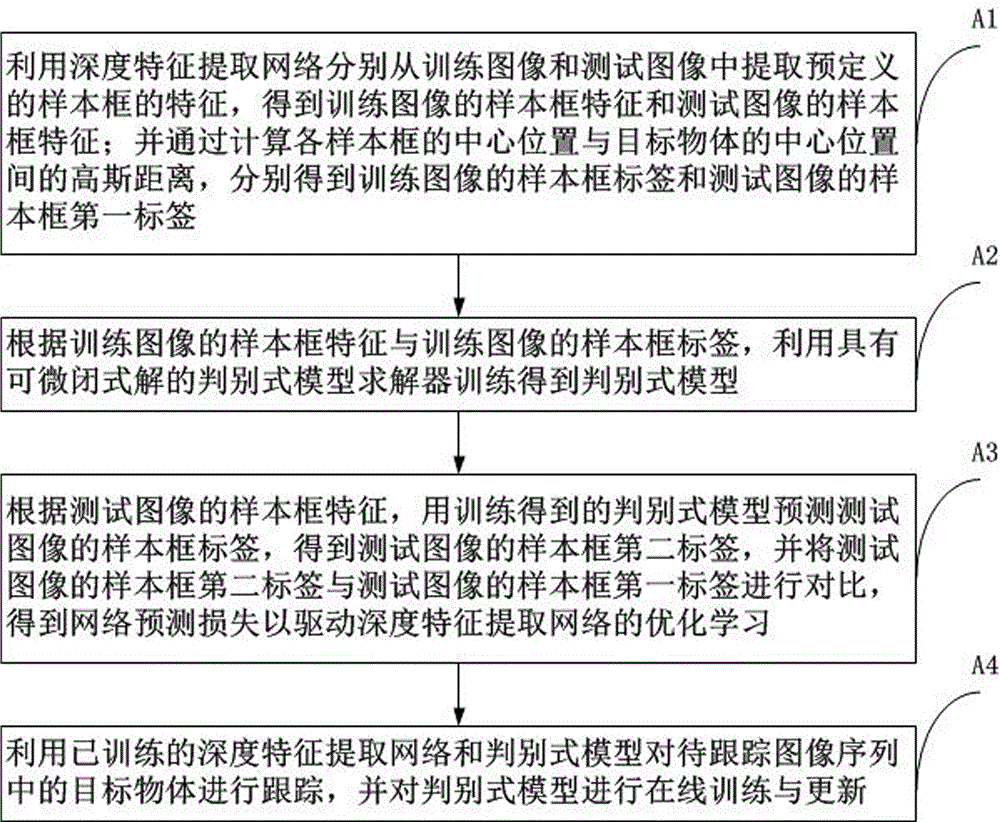
本发明的一方面,提出一种基于深度学习和判别式模型训练的目标跟踪方法,所述方法包括:离线训练阶段和在线跟踪阶段;
所述离线训练阶段包括:
利用深度特征提取网络分别从训练图像和测试图像中提取预定义的样本框的特征,得到所述训练图像的样本框特征和所述测试图像的样本框特征;并通过计算各样本框的中心位置与目标物体的中心位置间的高斯距离,分别得到所述训练图像的样本框标签和所述测试图像的样本框第一标签;
根据所述训练图像的样本框特征与所述训练图像的样本框标签,利用具有可微闭式解的判别式模型求解器训练得到判别式模型;
根据所述测试图像的样本框特征,用训练得到的所述判别式模型预测所述测试图像的样本框标签,得到所述测试图像的样本框第二标签;并将所述测试图像的样本框第二标签与所述测试图像的样本框第一标签进行对比,得到网络预测损失以驱动所述深度特征提取网络的优化学习;
所述在线跟踪阶段包括:
利用已训练的所述深度特征提取网络和所述判别式模型对待跟踪图像序列中的目标物体进行跟踪,并对所述判别式模型进行在线训练与更新。
优选地,所述深度特征提取网络包括:深度卷积神经网络、池化层和全连接层;
所述深度特征提取网络从输入图像中提取样本框特征的步骤包括:
使用所述深度卷积神经网络从所述输入图像中提取特征图;
使用所述池化层进行基于感兴趣区域的池化操作,在提取的特征图中对定义在所述输入图像中的样本框提取特征,以保证任意尺度的样本框输出相同维度的特征图;
使用所述全连接层将所述特征图映射为样本框特征向量,作为所述输入图像的样本框特征。
优选地,“根据所述训练图像的样本框特征与所述训练图像的样本框标签,利用具有可微闭式解的判别式模型求解器训练得到判别式模型”的步骤包括:
使用岭回归模型求解器作为判别式模型求解器,训练所述岭回归模型将所述训练图像的样本框特征拟合到所述训练图像的样本框标签上,并利用woodbury公式加速所述岭回归模型的训练。
优选地,所述岭回归模型为:
其中,
优选地,“利用woodbury公式加速所述岭回归模型的训练”的步骤包括:
利用下式等价地求解
优选地,“根据所述测试图像的样本框特征,用训练得到的所述判别式模型预测所述测试图像的样本框标签,得到所述测试图像的样本框第二标签,并将所述测试图像的样本框第二标签与所述测试图像的样本框第一标签进行对比,得到网络预测损失以驱动所述深度特征提取网络的优化学习”的步骤包括:
用训练得到的所述判别式模型对所述测试图像的样本框标签进行预测,得到所述测试图像的样本框第二标签;
根据所述测试图像的样本框第二标签与所述测试图像的样本框第一标签,使用收缩函数计算网络预测损失;
根据所述网络预测损失,使用深度学习优化器对所述深度特征提取网络的模型参数进行更新。
优选地,“利用已训练的所述深度特征提取网络和所述判别式模型对待跟踪图像序列中的目标物体进行跟踪,并对所述判别式模型进行在线训练与更新”的步骤包括:
使用已训练的所述深度特征提取网络从待跟踪图像序列的第一帧图像中提取相应的样本框特征,进而用岭回归模型求解器训练得到岭回归模型;
使用已训练的所述深度特征提取网络从所述待跟踪图像序列的后续帧图像中提取相应的样本框特征,进而用基于二次收敛的迭代方法对上一帧的岭回归模型进行更新。
优选地,“根据所述测试图像的样本框第二标签与所述测试图像的样本框第一标签,使用收缩函数计算网络预测损失”的步骤包括:
利用下式计算所述测试图像的样本框特征第二标签
其中,a为收缩系数,c为收缩起点。
优选地,“使用已训练的所述深度特征提取网络从所述待跟踪图像序列的后续帧图像中提取相应的样本框特征,进而用基于二次收敛的迭代方法对上一帧的岭回归模型进行更新”的步骤包括:
给定由第t帧图像的样本框特征向量构成的矩阵
其中,y为第t帧图像的样本框标签构成的向量,
本发明的另一方面,提出一种存储器,其中存储有程序,所述程序适于由处理器加载并执行,以实现上面所述的基于深度学习和判别式模型训练的目标跟踪方法。
与最接近的现有技术相比,本发明具有如下有益效果:
(1)本发明所设计的深度特征提取网络经过离线训练后,可以学习得到适合基于在线判别式模型训练的目标跟踪算法的特征空间。相比于以往基于在线判别式模型训练的目标跟踪算法使用在目标分类任务中训练的深度卷积神经网络进行特征提取,本发明所学习的深度特征提取网络更适合于目标跟踪任务,所提取的特征对目标跟踪过程中目标物体的变化(尤其是显著形变和光照变化)的鲁棒性更强,因此可以在在线跟踪中提升目标跟踪算法的定位精度。
(2)本发明中利用woodbury公式加速岭回归模型的训练,时间复杂度更低,求解更高效。
(3)使用收缩函数代替常用的均方误差函数来计算网络预测损失,缓解了正负样本不平衡的问题。
(4)在离线训练中使用adam优化器对深度特征提取网络的模型参数进行更新,adam优化器不但具有收敛速度快的特点,而且对学习率的敏感度较低,因此可以保证高效的离线网络训练。
(5)使用基于gauss-seidel的二次收敛的迭代方法在在线跟踪中可以明显提升跟踪器的运行速度。
附图说明
图1是本发明的基于深度学习和判别式模型训练的目标跟踪方法实施例的主要步骤示意图;
图2是本发明实施例中深度特征提取网络的构成示意图;
图3是本发明实施例中步骤a41的主要步骤示意图;
图4本发明实施例中步骤a42的主要步骤示意图。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
需要说明的是,在本发明的描述中,术语“第一”、“第二”仅仅是为了便于描述,而不是指示或暗示所述装置、元件或参数的相对重要性,因此不能理解为对本发明的限制。
图1是本发明的基于深度学习和判别式模型训练的目标跟踪方法实施例的主要步骤示意图。如图1所示,本实施例的目标跟踪方法包括:离线训练阶段和在线跟踪阶段。
其中,离线训练阶段包括步骤a1-a3,在线跟踪阶段包括步骤a4,下面详细介绍。
在步骤a1中,利用深度特征提取网络分别从训练图像和测试图像中提取预定义的样本框的特征,得到训练图像的样本框特征和测试图像的样本框特征;并通过计算各样本框的中心位置与目标物体的中心位置间的高斯距离,分别得到训练图像的样本框标签和测试图像的样本框第一标签。
本实施例中,根据给定的训练视频数据库,在同一视频中,随机采样两帧最大间隔不超过100帧的图像,分别定义为训练图像和测试图像;在训练图像(测试图像)中,均匀采样n个尺寸为目标大小的样本框,并分别提取样本框的特征。
图2是本发明实施例中深度特征提取网络的构成示意图。如图2所示,本实施例中的深度特征提取网络包括:深度卷积神经网络、池化层和全连接层。深度特征提取网络从输入图像(训练图像或测试图像等)中提取样本框特征的步骤包括:
(1)使用深度卷积神经网络从输入图像中提取特征图。
具体地,根据给定的目标物体在输入图像中的位置和大小,以目标物体为中心,采样得到目标物体面积二十五倍大的正方形图像区域,并缩放到统一空间分辨率,从而输入到深度卷积神经网络中提取特征图。
(2)使用池化层进行基于感兴趣区域的池化操作,在步骤(1)提取的特征图中对定义在输入图像中的样本框提取特征,以保证任意尺度的样本框输出相同维度的特征图。
具体地,使用基于感兴趣区域的池化操作(例如,roipooling,roialign等)在步骤(1)提取的特征图中对定义在输入图像中的n个样本框分别提取空间分辨率大小为6×6的特征图,即样本框特征图。
(3)使用全连接层将特征图映射为样本框特征向量,作为输入图像的样本框特征。
在步骤a2中,根据训练图像的样本框特征与训练图像的样本框标签,利用具有可微闭式解的判别式模型求解器训练得到判别式模型。
具体地,使用岭回归模型求解器作为判别式模型求解器,训练岭回归模型将训练图像的样本框特征拟合到训练图像的样本框标签上。
具体地,基于岭回归模型的优化问题可以表示为公式(1):
其中,x为训练图像的样本框特征构成的矩阵,y为训练图像的样本框标签构成的向量,
其中,i为单位矩阵,
利用woodbury公式加速岭回归模型的训练。
具体地,假设训练图像样本数为n,样本框特征向量维度为d,使用公式(2)中求解
该公式的计算复杂度为
在步骤a3中,根据测试图像的样本框特征,用训练得到的判别式模型预测测试图像的样本框标签,得到测试图像的样本框第二标签,并将测试图像的样本框第二标签与测试图像的样本框第一标签进行对比,得到网络预测损失以驱动深度特征提取网络的优化学习。该步骤可以具体包括步骤a31-a33:
在步骤a31中,根据测试图像的样本框特征,用训练得到的判别式模型对测试图像的样本框标签进行预测,得到测试图像的样本框第二标签。
假设由测试图像的样本框特征构成的矩阵为z,使用步骤a2中训练得到的岭回归模型
在步骤a32中,根据测试图像的样本框第二标签与测试图像的样本框第一标签,使用收缩函数计算网络预测损失。
具体地,利用下式计算测试图像的样本框特征第二标签(即预测值)
其中,a为收缩系数,c为收缩起点。
由于在目标跟踪问题中,存在明显的正负样本不平衡的问题,因此在离线深度卷积神经网络训练中如果使用常用的均方误差函数计算测试样本框特征的预测值和测试样本标签之间的损失会导致所设计的深度特征提取网络的学习严重偏向于拟合负样本,进而导致所学习特征空间的泛化力差以及模型的收敛速度慢的问题,故本实施例中使用收缩函数来代替常用的均方误差函数以缓解正负样本不平衡的问题。
在步骤a33中,根据网络预测损失,使用深度学习优化器对深度特征提取网络的模型参数进行更新。
具体地,可以使用adam优化器在离线训练中,对深度特征提取网络的模型参数进行更新。adam优化器不但具有收敛速度快的特点,而且对学习率的敏感度较低,因此可以保证高效的离线网络训练。
在步骤a4中,利用已训练的深度特征提取网络和所述判别式模型对待跟踪图像序列中的目标物体进行跟踪,并对判别式模型进行在线训练与更新,以提升特征提取的鲁棒性,进而提升目标定位精度。该步骤可以具体包括步骤a41-a42:
图3是本发明实施例中步骤a41的主要步骤示意图。如图3所示,在步骤a41中,使用已训练的深度特征提取网络从待跟踪图像序列的第一帧图像中提取相应的样本框特征,进而用岭回归模型求解器训练得到岭回归模型。
具体地,在第1帧图像中根据要跟踪的目标物体所在位置,确定第1帧图像的样本框标签。然后将第1帧图像视为训练图像,使用已训练的深度特征提取网络从第1帧图像中提取相应的样本框特征,进而用岭回归模型求解器训练得到岭回归模型。
图4是本发明实施例中步骤a42的主要步骤示意图。如图4所示,在步骤a42中,使用已训练的深度特征提取网络从待跟踪图像序列的后续帧图像中提取相应的样本框特征,进而用基于二次收敛的迭代方法对上一帧的岭回归模型进行更新。
具体地,使用已训练的深度特征提取网络从第2帧图像中提取相应的样本框特征,然后使用第1帧训练的岭回归模型进行回归值预测,回归值最大的样本框特征所对应的样本框即为目标物体,从而确定第2帧图像的样本框标签。然后将第2帧图像视为新的训练图像,使用已训练的深度特征提取网络从第2帧图像中提取相应的样本框特征,进而用基于二次收敛的迭代方法对第1帧训练的岭回归模型进行更新。依此类推,对待跟踪图像序列中第3帧及以后各帧进行目标物定位,并更新岭回归模型。
具体地,给定由第t帧图像的样本框特征向量构成的矩阵
其中,
上述实施例中虽然将各个步骤按照上述先后次序的方式进行了描述,但是本领域技术人员可以理解,为了实现本实施例的效果,不同的步骤之间不必按照这样的次序执行,其可以同时(并行)执行或以颠倒的次序执行,这些简单的变化都在本发明的保护范围之内。
进一步地,本发明还提供了一种存储器的实施例,该存储器中存储有程序,所述程序适于由处理器加载并执行,以实现上面所述的基于深度学习和判别式模型训练的目标跟踪方法。
本领域技术人员应该能够意识到,结合本文中所公开的实施例描述的各示例的方法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明电子硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以电子硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征做出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!