基于恒等快捷映射的深层卷积神经网络自动层位追踪方法与流程
本发明涉及一种基于恒等快捷映射的深层卷积神经网络自动层位追踪方法。
背景技术:
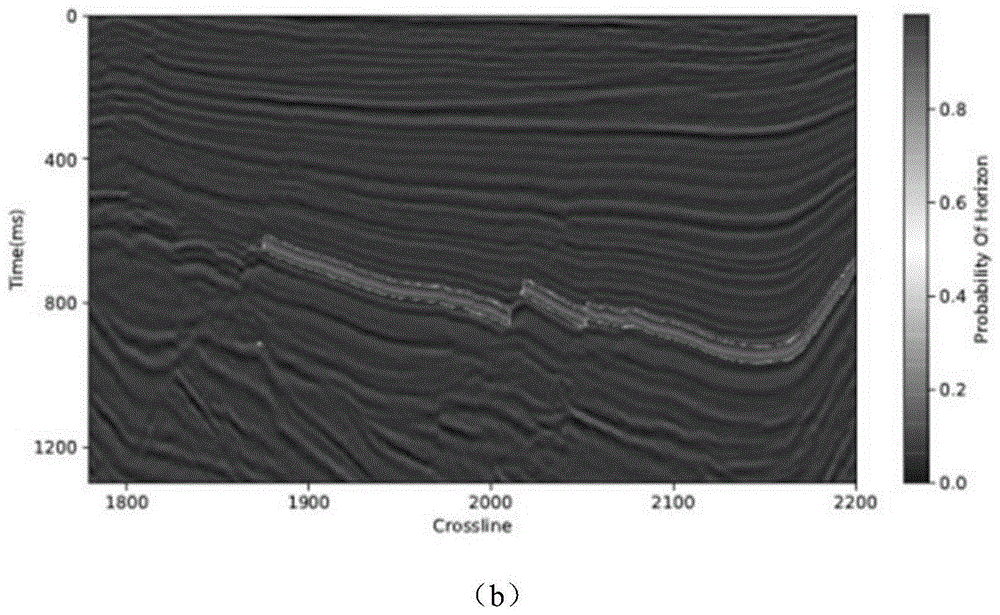
:地震层位解释与层序地层划分有着十分重要的相关性,准确的层位信息是地震解释基础工作,而层位的识别和跟踪是地震层位解释的重要组成部分,研究者们一直着力于解决同相轴的自动跟踪。地震数据是由炸药或地震车对地面通过爆炸或者重击产生地震波,其在遇到地表下的地层时会发生发射形成反射波并被地表的检波器接收信号,最终得到了地震振幅等反射数据。通常地震解释人员认为地震数据的剖面中的波峰或者波谷是同相轴经过的位置。常规人工层位标记是通过地震剖面的波峰和波谷确定同相轴的位置并进行连接,最终将各个剖面标记的层位连接形成同相轴的面。由于人工标记本身需要的成本及时间较大,研究者们又发展了自动层位追踪的手段。基于上述的原理,研究者们通过计算波形相关系数或者相干性等来寻找一定范围内的相似点,并将其作为同相轴经过的点,最终划定同相轴。但是在断层或分叉等情况出现时,容易出现计算误差导致最终标记出现问题。三维地震数据能够大概反映探测区域的地表下复杂地层情况,由于地下结构大多是层状分布的,在地下的不同深度有着不同年代产生的不同地层,且由于地层本身性质不同所带来的密度的不同导致地震波在此处传播的速度不同,最终使人们能够得到具有差异的地震反射数据。地层密度也叫岩石密度,其和声波在岩石上传播速度共同被称为岩石物理特性,简称岩性参数。不同地层的岩性参数差别很大,波阻抗为上述两者的乘积,这意味着波阻抗在不同地层上也会出现显著的变化。由于岩性参数的差距,声波在传播到两个地层交界处时会发生反射,最终这样的反射被地表的传感器接收生成了各种各样的波形,而变化强烈且一致并互相邻接的波形被称为同相轴,也就是层位。所以研究者们认为层位能够表达地下的层序划分,并能表示地下的岩性分布结构状况。层位一般是由多个点组成,每个点有对应的线号以及时间(深度),一般情况下勘探区域得到的三维地震体会存在多个层位,但是需要对所有层位点找到其对应所属的层位,这就体现了层位追踪的重要性以及意义。目前主要有以下几种层位追踪方法:(1)基于相关的自动层位追踪它是一种传统的自动层位追踪技术,主要利用过去提出的相干算法进行施展,该种类方案通过两道或多道之间的相关性对同相轴进行追踪并标记得到层位,其鲁棒性及对噪声的抵抗性能较好,但对算力的需求相当大,而且当邻近的两个层位的波形非常近似的情况下,极易产生串层的情况,这可能导致得到的结果不够准确。(2)基于图像的自动跟踪方法hale和naeini等人在层位追踪以及断层识别领域使用了结构张量,通过一些带方向的滤波器,得到了具体特征的方向,最后能够获得层位延伸及育成的主要方位。这种方式计算的功效较高,但是若遇到结构复杂的地层,追中的精度以及稳定程度无法得到确保。(3)基于神经网络的自动跟踪方法huang,lu等人发表了使用自组织映射网络的无监督自动层位跟踪方法,但是该方案的成败取决于自组织映射网络的初始化,这和结果的好坏直接相关。alberts、huang等人通过人工神经网络来对层位进行追踪,这种方法需要较多的训练数据,且对数据代表性有要求,但得到的效果不错。由于人工智能本身及深度学习的快速发展背后,数据仓库和图形处理器等算力相关的技术也得到快速发展,卷积神经网络的提出使其被运用到了图像识别,nlp,回归等常见的应用,在这之中alex等人将cnn运用到图像分类中取得了良好的效果,进一步引爆了深度学习的火热。(4)基于相干的同相轴自动追踪方法目前地震勘探领域已经发展到了第三代相干技术,通过某种方式计算地震道与相邻道之间的某种内在的物理联系,或者说相似度,被称为相干性。相干程度的计算能够表现地层内的横向变化,若该值较大,则说明此处的横向变化较小,邻近的道间相似度较大,相干性较强。而出现该值较小的地方,说明可能存在断层或异常体,岩层横向变化较大,该处相干性较弱。基于相干的自动层位追踪通过使用相干技术对地震反射进行运算并最终得到相干体,该相干体能够解释岩性参数的变化。通过对相干体特定区域进行特征提取,最后再运用插值技术得到完整的层位,这就是目前商业上较为受欢迎的基于相干的自动层位追踪技术。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种以深层卷积神经网络为骨干搭建模型,以恒定快捷连接为核心,改变了传统网络的梯度流,更有效地提取了地震反射中的特征,实现了地震相位特征的深度级联聚合,能够更精确地追踪目标层位的基于恒等快捷映射的深层卷积神经网络自动层位追踪方法。本发明的目的是通过以下技术方案来实现的:基于恒等快捷映射的深层卷积神经网络自动层位追踪方法,包括以下步骤:s1、对地震剖面图像进行预处理;s2、使用恒等快捷连接卷积神经网络对地震反射特征进行提取、压缩和精炼;s3、对步骤s2提取的信息进一步采集局部特征以及全局特征;s4、将采集的特征进行分类计算。进一步地,所述步骤s1具体包括以下子步骤:s11、将整个地震剖面划分成多个小图像块,每个小图像块大小为32×32;s12、将标签分配给每个小图像块,具体实现方法为:判断每个小图像块的中心是否位于层位上,若是则将该图像块标记为1,否则标记为0;s13、将图像块数据进行二分类训练,以判别该图像块的中心位置是否处于层位上;s14、对非层位数据进行处理:设定遗失概率来降低得到的非层位图像块的数量,设置遗失概率为0.5,即随机选取50%的非层位数据进行舍弃;同时在层位上设定偏差值,若一个小图像快的中心点与某个确定的层位的距离在偏差值范围内,即使该数据被人工标记标定为非层位,也认定该数据为层位数据,标记为1;s15、从层位数据集合中提取20%作为验证数据,用于对模型超参数进行调整;其余数据作为训练数据;s16、对数据进行归一化处理:使用min-max规范化方法,使数据尺度被规范化到0-1范围内;min-max规范化方法通过以下公式实现:其中xnor为规范化后的数据,x为原始的地震数据,xmax和xmin分别为地震振幅中的极大值和极小值。本发明的有益效果是:1、本发明以数据挖掘特征分类为出发点,提出了基于恒定快捷连接的深层卷积神经网络自动层位追踪方法。以深层卷积神经网络为骨干搭建模型,以恒定快捷连接为核心,改变了传统网络的梯度流,更有效地提取了地震反射中的特征,实现了地震相位特征的深度级联聚合。本发明对于复杂多断裂带大倾角层位以及弱地震振幅反射层位均有良好的追踪效果,提高了层位分辨的准确率。2、本发明针对运用数据驱动的方法解决层位追踪问题易发生数据不均衡的问题,提出了数据预处理与后处理的新思路,在出现连续断层以及大倾角的情况下,能够更精确地追踪目标层位。3、相比普通卷积神经网络模型,本发明的模型在数据分布相较原始数据分布差异更大的情况下,拥有更强的泛化性能,具有更好的特征表达能力,更加适用于追踪复杂目标层位。附图说明图1为神经网络连接方式对比;图2为卷积过程示意图;图3为残差函数f(x)示意图;图4为本发明提出的模型框架结构;图5为本发明的基于恒等快捷映射的深层卷积神经网络自动层位追踪方法的流程图;图6为西南某工区三维地震数据体图像;图7为小图像块划分示意图;图8为层位数据和非层位数据示意图;图9为西南某工区inline1760二维剖面图;图10为西南某工区inline1762二维剖面图;图11为西南某工区inline1762层位概率分布图;图12为三种方法在西南某工区inline1762的比较图;图13为图12中方框部分的放大图;图14为西南某工区inline1775二维剖面图;图15为西南某工区inline1775层位概率分布图;图16为三种方法在西南某工区inline1775的比较图;图17为图16中方框部分的放大图。具体实施方式与本发明有关的技术原理:卷积神经网络卷积神经网络是一种特殊的深度前向神经网络,其由带权重和偏置的神经元组成。通过采取局部连接的方式,有效避免了全连接带来的冗余问题,且有效降低了网络的参数量,进而降低了模型对数据本身的依赖性。比如每个神经元只和10×10个像素值连接。神经网络连接方式如图1所示,(a)为原始连接(全连接),(b)为新连接方式(局部连接):卷积神经网络一般由卷积层,relu非线性激活层,池化层和全连接层组成,在这其中,根据任务本身的情况可选择是否使用池化层。卷积神经网络的默认输入的数据格式为深度×高度×宽度,若输入为图像,深度代表图像的通道数,后两者表示图像的分辨率。一般而言,使用彩色图片的通道默认为rgb三通道,使用灰度图片默认通道为1。卷积神经网络各层与前一层都采用局部连接的方式。卷积层通过卷积运算提取和收集特征,所以这一类层承担了整个神经网络的大部分计算量。在普通的卷积神经网络中,卷积层通常位于输入层或池化层之后。在进行前向传播时,使用固定尺寸的卷积核以设置的步长在输入图像上进行游走并同时卷积计算,将卷积核的权重与局部连接的对应区域相乘求和,计算输出。为更进一步的说明卷积层的工作过程,以一个实例进行说明。如图2所示,网络输入的原始图像大小5×5,使用一个3×3大小的卷积核提取图像特征,该卷积核在原始图像上的对应区域分别作点积运算,最终获得一个大小为3×3的输出。图中左边两侧和上面两行为输入的原始图像,右下角部分表示一个3×3的卷积核,右边的图像表示经过卷积核滤波后得到的网络输出。该输出值的大小由网络的步长以及填充值大小判定。可用公式计算得出,其中w为输入的原始图像的尺寸,f为卷积核尺寸,s为步长,表示卷积核每次在图像上滑动经过的像素个数。p为填充数,表示当经过卷积操作后的特征图大小与卷积核大小不满足点积运算计算要求时,将特征图外部用0进行填充补齐大小的一种方式。在卷积神经网络中,卷积的数学表达式和常规的二维卷积有些许不同,其表达如下:s(i,j)=x*w(i,j)=∑m∑nx(i+m,j+n)w(m,n)(2)当输入多通道卷积核时,函数表达式如下:其中inchannel为输入的通道数,xk代表第k个输入矩阵,wk代表卷积核的第k个子卷积核矩阵。s(i,j)即卷积核w对应的输出矩阵对应元素值。若在卷积层操作后得到的特征尺寸仍然过大,不利于后续网络构建,则可以将其输入池化层进行下采样压缩。这样的操作可以避免分辨率过大带来的参数量暴涨,同时可以一定程度上降低过拟合程度。通常的做法是选定合适的窗口大小,设置合适的步长,对窗口内数据进行取极大值,平均值或随机抽取,这三种方案分别代表最大池化,平均池化和随机池化。一般来说,最大池化是最常见的池化方法,这种方法通常能在稀释数据分辨率的情况下较好地保留原始特征,且同时降低了维度,方便计算,并增强了泛化能力。全连接层与随机丢失:在经过卷积层和池化层后,最终需要经过全连接层提取最终特征,并根据所需求的任务对最终维度进行整合。该层将特征压缩至向量,所以该层也被称作为特征向量层。由于不同于卷积层的局部连接,采用了全连接操作,这导致参数量的增加,可以采用dropout手段,通过设置一个丢失概率,对神经元进行随机选取丢失的操作,该方法可以降低过拟合的现象同时降低网络参数量,减少计算量提升训练效率。dropout也可以使用在带有权重的其它层,例如卷积层等。残差网络:深度残差网络由he等人提出,解决了因网络深度加深而导致网络性能逐渐退化的问题。根据泛逼近定理(universalapproximationtheorem),在给定足够容量的前提下,任何函数都可以通过单层前向神经网络进行表达。然而,该前提可能导致这样的层维度超乎想象的庞大,增加了过拟合现象出现的概率。因此,学界普遍认为多层网络架构优于单层大容量网络架构。alexnet在图像识别任务获得了良好的结果,从那之后最先进的网络架构逐步加深,相比之下,alexnet仅有5个卷积层。在其发展后续的vgg网络和googlenet(代号inception_v1);分别有19层和22层。但是,在梯度消失的局限下,网络层数并不能通过堆叠简易增加,同时由于上述原因,这样的网络极难训练。因为梯度迷倒导致反向传播时,越传到前面层的梯度可能在连乘下接近于0。这导致网络层数在加深到某个极限后,网络性能达到瓶颈甚至开始下降。resnet的核心思想是引入一个所谓的恒等快捷连接(identityshortcutconnection),直接跳过一个或多个层,如图3所示。残差学习单元通过恒等映射的引入在输入、输出之间建立了一条直接的关联通道,从而使强大的有参层集中精力学习输入、输出之间的残差。一般用f(x)来表示残差映射,那么输出即为:y=f(x)+x。当输入、输出通道数相同时,可以直接使用x进行相加。而当它们之间的通道数目不同时,就需要考虑建立一种有效的恒等映射函数从而可以使得处理后的输入x与输出y的通道数目相同即y=f(x)+w*x。残差网络的出现,使得人们构建更深层的网络成为可能,同时使用了恒定快捷连接这样的“跳层”连接,达到了增加特征多样性,加快训练的效果。本发明提出的网络由两部分构成:前半部分使用恒等快捷连接卷积神经网络,对地震数据进行提取、压缩和精炼;得到一个256*8的数据体;后半部分将256*8的数据体变为4个256*4的局部结构和一个256*8的全局结构,作为输入,后半部分对提取的信息进一步采集局部特征(指是对原始输入数据整体提取的特征)以及全局特征(提取小图像块的相对原始输入的尺度比较小的特征),并将采集的最终特征用于分类计算。在前半部分网络中采用了图3中的模块结构,前半部分包括一个卷积层和五个模块结构,每个模块结构内部包含卷积层和relu操作,并伴随恒等快捷连接;每两个模块使卷积步长变为2(指卷积核的移动步长,就是说在每两个模块的计算中把卷积核的步长变为2)进行一次降维操作使维度减半;后半部分将全局结构(原始输入的一个整体数据)的1/4理解为局部结构,对每个局部结构以及全局结构进行如3所示的模块化操作,得到4个256*4的局部结构和一个256*8的全局结构;然后再进行平均池化,得到维度为1×1×256的五个向量,分别代表四个局部特征以及一个全局特征,将上述特征进行连接操作,得到最后用于分类的特征向量,输入全连接层进一步降维,并使用softmax函数进行二分类。本发明提出的模型框架结构如图4所示。表1是整个网络的内部架构预览。表1基于恒等快捷连接的深度卷积层位追踪网络架构input输入数据维度为time×xline,逗号后为channel;kernel内表示均为卷积核大小,block使用中括号表示连续两个卷积层;stride为2表示该block的第一层卷积步长为2,余下为1;block6_local*表示提取对应部分的局部信息,block6_global提取整体信息;avg_pool_concat表示对所有数据体进行平均池化后连接;fc表示全连接层;softmax将输出映射到[0,1]区间内;该表未完全按照信息流顺序表示,信息流遵照图5所示。如前面所述,内部的每个block都可以用如下公式表述:y=f(x,{wi})+x(4)这里x和y是所考虑层的输入和输出向量。函数f(x,{wi})表示要学习的残存映射。其中f=w2σ(w1),σ(w1)代表激活函数,本发明使用relu作为激活函数,为了简略符号的使用,此处省略了偏差。f(x,{wi})+x通过恒等快捷连接实现,同时运用元素对应相加。在对应相加后再进行二次非线性操作σ(y)。公式(4)中的恒定快捷连接既不引入额外的参数,也不引入计算复杂性,但x和f的维度必须统一,若不统一(例如当改变通道数的时候),可以通过一个线性映射来匹配通道数:y=f(x,{wi})+wsx(5)本发明中使用1×1卷积来达到ws的效果,1×1的卷积核由于大小只有1×1,所以不需要考虑像素跟周边像素的关系,它主要用于调节通道数,对不同的通道上的像素点进行线性组合后执行非线性化操作,完成了升维和降维的功能。在本发明网络结构设计中,往往只需在某些block中才需要该项功能。可以注意到,上述公式4和公式5中的残差函数为了简单起见使用全连接层来进行表述,在实际使用中完全可以使用卷积层来进行代替。实际运用中也可以使用多个卷积层来表述f(x,{wi}),在两个特征映射上逐通道执行元素对应相加。将本发明模型的反向传播机制与常规模型进行对比,假设在执行一个普通的block时,损失针对权重的反向传播为:而当模块使用了恒定快捷连接后,梯度的反向传播为:l表示损失函数,l1表示第一层网络,l2表示第二层网络,o表示整体网络的输出,o1表示网络的第一层的输出,w表示权重矩阵。这个公式就是一个简单的二层网络的公式,主要是为了对比使用恒定连接与不使用的差别。相比于无恒定连接的模块,在w处多出了1,这将梯度不衰减地传递了回去,这使得网络能够构建更深层的地震特征,提取了常规卷积神经网络不够敏感的细微特征,使得分类效果更佳精确。下面结合附图和具体实施例进一步说明本发明的技术方案。在后续将用英文identityshortcutgloballocalconvolutionalneuralnetwork的简称isgl-net代表本发明提出的网络进行表述。如图5所示,本发明的基于恒等快捷映射的深层卷积神经网络自动层位追踪方法,包括以下步骤:s1、对地震剖面图像进行预处理;本实施例采用西南某工区三维地震体进行实验,该数据体主测线地震解释剖面(inline)由线号1760至线号2160共401道线号,联络线地震解释剖面(xline)由线号1780至线号2220共440道线号,该样本采样间隔为2ms,时间范围为0ms至1300ms。该三维地震体如图6所示。本步骤具体包括以下子步骤:s11、整个地震剖面包含了太多信息,无法直接作为输入图像。将整个地震剖面划分成多个小图像块,这样的图像块利于计算与分析;每个小图像块大小为32×32;图7展示了生成训练数据的工作流。人工标记的层位位于左侧图像的中部,在整个地震剖面上滑动一个窗口(左上角显示的小窗口)以创建大小为32×32的二维图像补丁。每幅32×32的图像的宽度和高度都为0-31,采样间隔为2ms,这代表着使用的每个图片块为32道,64ms以及一个颜色通道。s12、在提取图像块后,需要将标签分配给每个小图像块,使得具有相同标签的图像补丁共享特定特征;具体实现方法为:判断每个小图像块的中心(若每个小图像块置于二维坐标轴中,其一个顶点位于原点处,则将(15,15)的坐标点作为图片的中心)是否位于层位上,若是则将该图像块标记为1,否则标记为0;如图8所示,图中的小圆圈代表图像块的中心;s13、将图像块数据进行二分类训练,以判别该图像块的中心位置是否处于层位上;s14、在提取数据的过程中,由于层位数据本身的特性,会发生正负样本严重不均衡的现象,本发明通过以下方法对非层位数据进行处理:设定遗失概率来降低得到的非层位图像块的数量,设置遗失概率为0.5,即随机选取50%的非层位数据进行舍弃;使用遗失概率是为了缓解数据不均衡的现象,即将一半的非层位图像块数据进行舍弃,缓解了过多的数据块的中心不在层位上的情况。同时在层位上设定偏差值,若一个小图像快的中心点与某个确定的层位的距离在偏差值范围内,即使该数据被人工标记标定为非层位,也认定该数据为层位数据,标记为1,本实施例所使用的偏差值为10个数据点;分类问题中,当不同类别的样本量差异很大,即类分布不平衡时,很容易影响分类结果。因此需要进行校正。具体方法为:对训练集里的每个类别加权,从而使模型更加关注样本数量少的类别。使用权重法,也就是样本数量多的类权重低,反之权重高,对损失进行分配。本发明中使用的权重为类对应的样本数量的倒数;这里的类就是标记为1的层位数据以及标记为0的非层位数据。例如,标记为0的数据数量为90,则其权重为1/90;标记为1的数据的数量为10,则其权重为1/10。在后续实验中发现,上述方案能够极大减弱正负样本不均衡的现象,并能够极大提升模型的准确性。s15、从层位数据集合中提取20%作为验证数据,用于对模型超参数进行调整(根据验证损失(用这20%的训练数据进行验证时得到的验证误差)来调整参数,也可以在训练的时候在checkpoint设置保留性能最好的模型);其余数据作为训练数据;s16、对数据进行归一化处理:数据归一化是机器学习数据准备过程中必不可少的步骤。归一化是指将所有维度上的输入数据规范化在固定尺度内。3d地震数据的振幅属性的范围为-32767到32767,然而如果relu激活函数接收到任何负输入,则它返回0,这样就不会在此零值区域中进行学习。一旦单位变成负数,它们就不会在区分输入中起任何作用,并且基本上是无用的。如果输入值太大,则会影响神经网络的收敛。因此,需要对输入数据进行归一化以提高收敛速度和训练效率。本实施例使用min-max规范化方法,使数据尺度被规范化到0-1范围内;min-max规范化方法通过以下公式实现:其中xnor为规范化后的数据,x为原始的地震数据,xmax和xmin分别为地震振幅中的极大值和极小值。s2、使用恒等快捷连接卷积神经网络对地震反射特征进行提取、压缩和精炼;将预处理完成后的实验数据输入模型,本发明使用的实验训练处理器为nvidiageforcegtx1050(4g),相比使用中央处理器,使用图形处理器能够加速涉卷积神经网络的模型训练。s3、对步骤s2提取的信息进一步采集局部特征以及全局特征;s4、将采集的特征进行分类计算。下面使用准备好的数据进行测试,并通过结果进行分析。本实施例选择了西南某工区受断层严重干扰以及附带大倾角特征的层位,认为该层位具有典型代表性,如图9展示了目标层位的反射模式,图9为西南某工区inline1760二维剖面,分别标记了原始层位,断层以及大倾角。首先使用了与训练数据较邻近的剖面inline1762的层位如图10所示,图10为西南某工区inline1762二维剖面,分别标记了原始层位,断层以及大倾角。并与普通深度卷积神经网络与传统自动层位追踪方法进行了比较,可以看到由于剖面位置较邻近,该层位与剖面inline1760十分相似。图10为cnn和isgl-net两个方法在inline1762上的层位概率分布,可以看到两者对于两个断层以及大倾角的处理都较好,在层位最左侧开头处以及第一个断层处,常规cnn出现了部分瑕疵(图11(a)),isgl-net(图11(b))相对常规卷积神经网络总体来看更加清晰与干净。虽然常规cnn出现了上述小部分瑕疵,实验结果仍然处于能够令人接受的状态,这样的结果是可以预见的,这是因为训练剖面与测试剖面的物理位置较接近,使训练数据与测试数据的分布较接近。接下来将两者设定阈值并去除偏差值与传统层位追踪方法的结果进行比较,本实施例所设定阈值为0.9,如图12所示。conventional代表传统方法;manual代表人工进行标记,可以看到,在纵向变化不大的前部区域,cnn/isgl-net以及传统的基于波形相似同相轴追踪方法都有不错的表现。在最后部分的大倾角区域,几种方法都有不错的表现。将图12中方框部分放大,如图13所示。从图13可以看到传统层位追踪方法在第一断层处发生了严重的误判,追踪到了相邻层位,并且在第二个断层处仍然处于误判,而在该区域,cnn与isgl-net仍然与人工标记保持不错的一致性;接下来将各个方法以人工标记层位作为标准进行误差量化,本文使用绝对误差(absoluteerror)和平均绝对误差(meanabsoluteerror)来对距离误差进行衡量。公式如下:其中m为测试集采样点个数。各方法以人工标记层位为准,在断层处的判定错误,给与每个判定点的惩罚值为20,对于inline1762层位的误差如表2所示。表2西南某工区inline1762层位误差比较aemaecnn10023.13isgl-net9683.03conventional1149359综合图12以及表1可知,isgl-net效果相对其余两者效果更加优异,cnn效果与isgl-cnn接近,然而传统层位追踪方法在实际表现以及量化结果均不如人意。由于inline1762与训练数据inline1760物理距离相对较近,这导致两者数据分布较为接近,为了测试模型的泛化性能,本实施例选取相对原始训练数据物理实际位置更远的inline1775进行测试。inline1775及层位标定如图14所示可以看到该剖面数据分布与inline1760差异较大。图15为西南某工区inline1775层位概率分布图像,其中(a)为,cnn处理结果,(b)为isgl-net处理结果。可以看到cnn在如图15方框所标记的两处断层处都进行了较大的错误预判,而本发明提出的isgl-net在第一处断层进行了较为成功的断层检测,在第二处断层出现了预判失误,但从分辨效果来看仍然优于cnn。在纵向变化轻微以及大倾角部分,两者分辨效果均较为不错。同理,接下来仍然对结果进行设定阈值并去偏差值操作,并与传统层位追踪方法进行比较,结果如图16所示。在纵向变化不大的前部区域,cnn/isgl-net以及传统层位追踪方法都有不错的表现。在最后部分的大倾角区域,三个方法都有不错的表现。接下来将大方框框标记部分放大。如图17所示,可以观察到,在方框标记范围内,传统层位追踪方法在两个断层处出现了连续的追踪错误,均追踪到了邻近层位,包含断层在内一共出现了四处追踪错误;在第一处蓝框标记范围内,可以观察到,cnn在第一处横向断层出现了严重的预判错误,而isgl-net在此处表现良好;在第二处蓝框标记范围内,在第二处断层,cnn与isgl-net均出现了不同程度的追踪失误,但总体来看,isgl-net的效果仍优于cnn。接下来对各个方法以inline1775人工标记层位为标准量化追踪误差,误差如表3所示。表3西南某工区inline1775层位误差较aemaecnn13254.14sgl-net11623.63conventional1496468综上所述,在物理距离距原始训练数据较远,数据分布差距较大的情况下,isgl-net具有比cnn更好的泛化性能。isgl-net与cnn和传统基于波形相似的层位追踪方法相比,追踪效果更加良好。本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1