一种基于扩充高质量脑电样本的情绪识别方法与流程
本发明属于计算机应用技术领域,具体涉及一种基于扩充高质量脑电样本的情绪识别方法。
背景技术:
情绪识别作为人工智能领域的研究热点,受到了越来越多研究者的关注。情绪识别为防止疲劳驾驶,精神疾病诊断,监测个人健康状况提供了科学依据。因此,情绪识别研究具有十分重要的研究意义。传统的情绪识别技术大多采用有监督的机器学习方法,但是在这种方法中,情绪识别的准确率取决于脑电样本的数量和质量。然而脑电样本的采集耗时耗力而且经过采集得到的脑电样本质量参差不齐。当待识别者的脑电样本数量较少时,该类方法情绪识别的准确率较低。
技术实现要素:
本发明针对上述背景技术中存在的不足之处,提供了一种基于扩充高质量脑电样本的情绪识别方法。
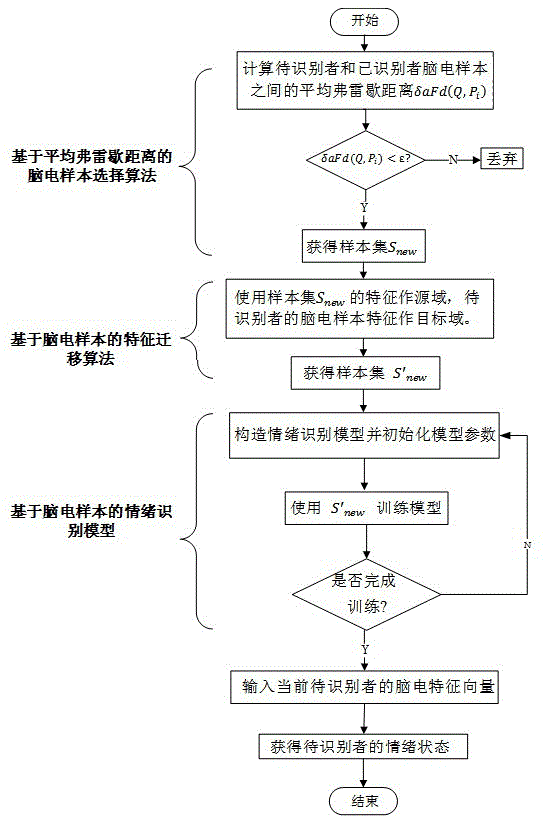
一种基于扩充高质量脑电样本的情绪识别方法,包括如下步骤:
步骤s1:基于情绪状态已识别者及其脑电信号和对应的情绪状态、待识别者的部分脑电信号和对应的情绪状态,对于已识别者和待识别者的脑电信号进行特征提取,并分别形成已识别者和待识别者的脑电样本集合;
步骤s2:计算已识别者和待识别者脑电样本之间的平均弗雷歇距离,使用基于平均弗雷歇距离的脑电样本选择算法筛选出已识别者高质量脑电样本;
步骤s3:以筛选后得到的已识别者高质量脑电样本的特征作源域,待识别者脑电样本的特征作目标域,使用基于脑电样本的特征迁移算法得到待识别者和已识别者合并之后的脑电样本集合;
步骤s4:建立基于回声状态网络的情绪识别模型,用迁移后得到的脑电样本集合训练情绪识别模型;
步骤s5:将训练好的基于回声状态网络的情绪识别分类模型对待识别者当前的脑电信号的特征进行识别,得到待识别者的当前情绪状态。
进一步地,步骤s1中,待识别者q的脑电样本表示为pq,表示为:
pq={(xq,yq)}={(xq(1),yq(1)),(xq(2),yq(2)),...,(xq(a),yq(a)),...,(xq(m),yq(m))}
已识别者的脑电样本表示为p={p1,p2,...,pi,...,pd},第i位已识别者的脑电样本pi进一步表示为:
pi={(xi,yi)}={(xi(1),yi(1)),(xi(2),yi(2)),...,(xi(b),yi(b)),...,(xi(n),yi(n))}
其中,xq(a)和yq(a)分别是待识别者第a个脑电样本的特征向量和情绪状态;xi(b)和yi(b)分别是第i位已识别者第b个脑电样本的特征向量和情绪状态;每个脑电样本中的特征向量是脑电信号经过特征提取后的特征,包括脑电信号的峰值平均值、均方值、方差、最大功率谱频率、最大功率谱密度、功率和、香农熵、功率谱熵;m和n分别是待识别者q和第i位已识别者的脑电样本数量;yq(a),yi(b)∈{0,1,2},其中,0,1,2分别代表悲观,平静和乐观。
进一步地,所述步骤s2的筛选已识别者高质量脑电样本步骤如下:
步骤s21:计算待识别者q的脑电样本pq和第i位已识别者的脑电样本pi的平均弗雷歇距离δafd(q,pi),计算公式如下:
其中,
其中,δdf(xq(a),xi(b))是xq(a)和xi(b)之间的最短弗雷歇距离之和,xq(a)表示为xq(a)={xq(1),xq(2),...,xq(k),...,xq(r)},xi(b)表示为xi(b)={xi(1),xi(2),...,xi(t),...,xi(r)},其中xq(k)是待识别者q的第a个脑电样本中的第k个特征向量,xi(t)是第i位已识别者的第b个脑电样本中的第t个特征向量;r是每个脑电样本中特征向量的维数;
步骤s22:规定一个阈值ε,若δafd(q,pi)<ε,则说明第i位已识别者的脑电样本pi是高质量的;
步骤s23:对通过步骤s22筛选得到的不同已识别者的高质量脑电样本集pnew={p1,...,pf},根据情绪状态均匀分布的原则进一步筛选得到新的脑电样本集:
snew={(xnew,ynew)}={(xnew(1),ynew(1)),(xnew(2),ynew(2)),...,(xnew(i),ynew(i)),...,(xnew(g),ynew(g))}
其中,xnew(i)代表第i个高质量脑电样本的特征向量,ynew(i)是对应的情绪状态,g是高质量脑电样本的数量。
进一步地,所述的步骤s3的特征迁移步骤如下:
步骤s31:以已识别者的高质量脑电样本集snew的特征xnew作为源域xs,待识别者的脑电样本的特征xq作为目标域xt,将已识别者的高质量脑电样本的特征和待识别者脑电样本的特征映射到同一高维的再生核希尔伯特空间rkhs来最小化它们之间的边缘概率分布距离;采用最大均值差异mmd距离计算已识别者的高质量脑电样本的特征和待识别者脑电样本的特征之间的边缘概率分布距离,mmd距离的计算公式如下:
其中,φ表示源域xs和目标域xt之间的映射,xs是已识别者高质量脑电样本集snew的特征向量集合,xt是待识别者的特征向量集合,xnew(i)∈xs并且xq(j)∈xt,g和m分别是已识别者高质量脑电样本和待识别者脑电样本的数量;
步骤s32:通过最小化mmd距离,找到最合适的映射φ,从而实现已识别者高质量样本的特征迁移至待识别者,最后得到已识别者高质量样本与待识别者样本合并后的样本集:
s'new={(x's∪x't,ynew∪yq)}={(x'new(1),y'new(1)),(x'new(2),y'new(2)),...,(x'new(v),y'new(v)),...,(x'new(z),y'new(z))}
其中,x's=φ(xs)是迁移后的已识别者高质量脑电样本的特征向量;x't=φ(xt)是迁移后的待识别者脑电样本的特征向量,x'new(v)代表迁移后已识别者高质量脑电样本和待识别者脑电样本集合中第v个脑电样本的特征向量,y'new(v)是对应的情绪状态,z是迁移后脑电样本集合的总数。
进一步地,步骤s4中,建立基于回声状态网络的情绪识别模型步骤如下:
s41:构造一个包括r个神经元结点大小的输入层用于输入脑电样本的特征向量,n个神经结点大小的储备池用于训练输出层权重和一个3个神经元结点的输出层用于输出情绪状态;
s42:训练开始前,初始化输入层权重win和储备池权重wr;
s43:根据步骤s32中所述迁移后的脑电样本集s'new训练构造的基于回声状态网络的情绪识别分类模型。
进一步地,步骤s5根据步骤s4中训练好的情绪识别模型,输入当前待识别者的脑电特征向量x(v)进行识别,通过以下公式得到待识别者的当前情绪状态y(v);
u(v)=tanh(wru(v-1)+winx(v))
y(v)=wout(u(v-1))
其中,x(v)是输入的脑电特征向量,y(v)是得到的情绪状态,u(v)是储备池的状态,wr是储备池权重,win是输入层权重,wout是输出层权重,wout通过步骤s4中模型训练得到,tanh(·)是激活函数。
本发明的有益效果是:将迁移学习运用到脑电情绪识别中。使用平均弗雷歇距离对迁移主成分分析法进行改进,筛选出质量更高的脑电样本,扩充了脑电样本,解决了脑电样本不足的问题并提高了脑电样本的质量。
附图说明
图1为本发明实施例的具体流程图。
图2为本发明实施例的基于平均弗雷歇距离的脑电样本选择算法流程示意图。
图3为本发明实施例的基于脑电样本的特征迁移算法示意图。
图4为本发明实施例的基于回声状态网络的情绪识别模型示意图。
具体实施方式
下面结合说明书附图对本发明的技术方案做进一步的详细说明。
如图1所示,本发明的实施例的总体流程包括:
步骤s1:假设已有一些情绪状态已识别者,包含已经采集得到的已识别者的脑电信号和对应的情绪状态。并且,待识别者也已经采集得到了少量的脑电信号和对应的情绪状态。对于已识别者和待识别者的脑电信号进行特征提取,并分别形成已识别者和待识别者的脑电样本集合。
步骤s2:计算已识别者和待识别者脑电样本之间的平均弗雷歇距离,使用基于平均弗雷歇距离的脑电样本选择算法筛选出已识别者中的高质量脑电样本。
步骤s3:以筛选后的得到的已识别者高质量脑电样本的特征作源域,待识别者脑电样本的特征作目标域,使用基于脑电样本的特征迁移算法得到待识别者和已识别者合并之后的样本集。
步骤s4:建立基于回声状态网络的情绪识别模型,用迁移后得到的脑电样本集合训练模型。
步骤s5:将训练好的基于回声状态网络的情绪识别分类模型对待识别者当前的脑电信号的特征进行识别,得到待识别者的当前情绪状态。
如图2所示,本发明实施例公开了一种基于平均弗雷歇距离的脑电样本选择算法流程示意图。包括:
步骤s21:假设已有一些已识别者p={p1,p2,...,pi,...,pd},包含已经采集得到的脑电信号和对应的情绪状态。待识别者q包含采集得到的少量的脑电信号和对应的情绪状态。对已识别者和待识别者的脑电信号进行特征提取,具体提取了9种时频特征包括:峰值平均值、均方值、方差、霍斯参数:活动性、霍斯参数:移动性、霍斯参数:复杂性、最大功率谱频率、最大功率谱密度、功率和。9种非线性动力系统特征包括:近似熵、c0复杂性、关联维数、科尔莫戈洛夫熵、李雅普诺夫指数、排列熵、奇异熵、香农熵、功率谱熵。
步骤s22:计算待识别者q和已识别者pi脑电样本之间的平均弗雷歇距离δafd(q,pi)。并规定一个阈值ε=6,若δafd(q,pi)<6,则说明已识别者pi的脑电样本是高质量的。
步骤s23:为了进一步提升脑电样本的分类精度,对步骤s22筛选得到不同已识别者的高质量脑电样本集pnew={pnew,...,pf}根据情绪状态均匀分布的原则进一步筛选得到新的脑电样本集snew={(xnew,ynew)}={(xnew(1),ynew(1)),(xnew(2),ynew(2)),...,(xnew(i),ynew(i)),...,(xnew(g),ynew(g))},g是高质量脑电样本的数量。
如图3所示,本发明实例公开了一种基于脑电样本的特征迁移算法示意图。包括:
步骤s31:以步骤s23中已识别者的高质量脑电样本集snew的特征xnew作为源域xs,待识别者的脑电样本的特征xq作为目标域xt。将已识别者的高质量脑电样本的特征和待识别者脑电样本的特征映射到同一高维的再生核希尔伯特空间rkhs(reproducingkernelhilbertspace)来最小化它们之间的边缘概率分布距离。采用最大均值差异mmd(maximummeandiscrepancy)距离计算已识别者的高质量脑电样本的特征和待识别者脑电样本的特征之间的边缘概率分布距离,mmd距离的计算公式如下:
其中,φ表示源域xs和目标域xt之间的映射,xs是已识别者高质量脑电样本集snew的特征向量集合,xt是待识别者的特征向量集合,xnew(i)∈xs并且xq(j)∈xt,g和m分别是已识别者高质量脑电样本和待识别者脑电样本的数量。
步骤s32:通过最小化mmd距离,找到最合适的映射φ,从而实现已识别者高质量样本的特征迁移至待识别者。最后得到已识别者高质量样本与待识别者样本合并后的样本集
s'new={(x's∪x't,ynew∪yq)}={(x'new(1),y'new(1)),(x'new(2),y'new(2)),...,(x'new(v),y'new(v)),...,(x'new(z),y'new(z))}。
其中,x's=φ(xs)是迁移后的已识别者高质量脑电样本的特征向量;x't=φ(xt)是迁移后的待识别者脑电样本的特征向量,x'new(v)代表迁移后已识别者高质量脑电样本和待识别者脑电样本集合中第v个脑电样本的特征向量,y'new(v)是对应的情绪状态,z是迁移后脑电样本集合的总数。
如图4所示,本发明实例公开了一种基于回声状态网络的情绪识别模型示意图。建立基于回声状态网络的情绪识别模型步骤如下:
s41:构造一个包括r个神经元结点大小的输入层用于输入脑电样本的特征向量,n个神经结点大小的储备池用于训练输出层权重和一个3个神经元结点的输出层用于输出情绪状态。
s42:训练开始前,初始化输入层权重win和储备池权重wr。
s43:根据步骤s32中所述迁移后的脑电样本集s'new训练构造的基于回声状态网络的情绪识别分类模型。
进一步的,所述步骤s5中的识别待识别者当前情绪状态的步骤如下,根据步骤s4中训练好的情绪识别模型,输入当前待识别者的脑电特征向量x(v)进行识别,通过以下公式得到待识别者的当前情绪状态y(v)。
u(v)=tanh(wru(v-1)+winx(v))
y(v)=wout(u(v-1))
其中,x(v)是输入的脑电特征向量,y(v)是得到的情绪状态。u(v)是储备池的状态,wr是储备池权重,win是输入层权重,wout是输出层权重,tanh(·)是激活函数,wout通过步骤s4中模型训练得到。
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!