基于骨骼数据双通道深度可分离卷积的行为识别方法与流程
本发明属于人体姿态行为识别技术领域,具体涉及一种基于骨骼点数据双通道深度可分离卷积的姿态行为识别方法。
背景技术:
人体动作识别是近年来cv领域热门研究的一个方向,骨骼点动作识别是人体动作识别中的一个分支,旨在识别由骨骼点数据随时间变化构成的骨骼序列,人体动作识别的另外一个分支是处理rgb视频序列。
基于rgb视频序列由于其时间序列性,一般使用gru、3d卷积、lstm变种等方式处理;但是由于rgb数据会放大光照、颜色以及遮盖物等因素的影响,进而导致模型鲁棒性不如骨骼数据拟合的模型。
基于骨骼数据的模型,由于其骨骼和关节相互连接,和图结构的数据非常契合,加上其对颜色和光照、遮挡物的强鲁棒性,因此近年来基于骨骼数据的模型大部分是基于图卷积网络。
然而针对特定场景中,azureforkinect设备开发应用程序所依赖运行设备的性能不足,以及对数据处理的时效性和准确率考虑,因此综合考虑设计一种基于骨骼点数据的姿态行为识别方法显得尤为重要。
技术实现要素:
针对现有技术中存在的上述问题,本发明的目的在于提供一种基于骨骼点坐标的姿态行为识别方法,通过在图卷积网络中嵌入d2se块来处理骨骼数据,相比于传统的图卷积识别方法,能够降低模型训练参数和训练时间的同时保证动作识别的准确率。
本发明提供如下技术方案:基于骨骼数据双通道深度可分离卷积的行为识别方法,其特征在于包括以下步骤:
步骤一、获取人体行为姿态关节骨骼点数据;
步骤二、使用类邻接矩阵策略对骨骼点数据处理提取行为空间特征;
步骤三、将depth层和point层嵌入卷积层中,构建d2se双通道深度可分离卷积层,在时间维度上提取行为时间特征;
步骤四、将图卷积上的空间信息和d2se网络层上的时间信息叠加提取姿态行为的时空信息;
步骤五、使用relu函数获取骨骼动作分类。
所述的基于骨骼数据双通道深度可分离卷积的行为识别方法,其特征在于所述步骤一中,通过azureforkinect获取人体关节骨骼点数据,对获取的骨骼点数据进行预处理,具体构建步骤如下:
2.1、从导出的文件中获取姿态骨骼数据序列,去除噪声数据;
2.2、将去噪后的数据构建图数据。
所述的基于骨骼数据双通道深度可分离卷积的行为识别方法,其特征在于所述步骤二中,将步骤一中预处理后的骨骼点数据使用类邻接矩阵策略转换成一张伪图像矩阵来提取行为空间特征。
所述的基于骨骼数据双通道深度可分离卷积的行为识别方法,其特征在于所述步骤三中,采用构建基于dse网络的姿态行为识别方法提取时间特征,所述dse网络包括双通道se网络层及conv层两个部分,所述双通道se网络层对输入数据进行卷积操作,conv层使用depthwise和pointwise卷积组合。
所述的基于骨骼数据双通道深度可分离卷积的行为识别方法,其特征在于所述步骤四中,构建d2se-gcn双通道深度可分离卷积网络将图卷积上的空间信息和d2se网络层上的时间信息叠加提取姿态行为的时空信息,采用随机梯度下降sgd优化网络参数,预设初始学习率、权重衰减、训练和测试样本batch_size、训练epoch及warm_up预热学习率。
所述的基于骨骼数据双通道深度可分离卷积的行为识别方法,其特征在于所述学习率的更新包括模型预热阶段、正式训练阶段,使用预热学习率能加快模型收敛速度。
所述的基于骨骼数据双通道深度可分离卷积的行为识别方法,其特征在于所述步骤四中,将测试样本输入已训练好的双通道深度可分离卷积d2se-gcn模型中,输出向量中最大值对应的姿态行为类别即可判断该测试样本的动作类型,实现姿态行为的准确识别。
通过采用上述技术,与现有技术相比,本发明的有益效果如下:
1)本发明使用图卷积神经网络gcn和d2se网络层,对人体姿态行为骨骼数据使用空间上的图卷积来提取空间信息,通过前后相邻帧的常规卷积来提取时间信息,最后通过二者的叠加来提取时空信息;
2)本发明是基于双通道,普通的se块通过网络根据loss学习特征权重,使得有效的featuremap权重和无效的featuremap自适应,但是在网络的计算过程中不可避免的增加了参数和计算量,深度可分离卷积层网络架构隐式依赖提供一种更高效的划分方法,在提高基于深度分离卷积架构性能的同时不会引入额外的复杂度,同时能使卷积层的参数明显缩减,而双通道的模型在输入特征适应不同卷积核,多视野域卷积能使得split获取多个卷积核的不同感受野,通过线性变换操作、归一化、得到通道特征,和原始特征加乘,然后经过fuse聚合来自多个路径的信息,从而获得全局选择性权重表现,双通道se-block能对读入的相邻帧骨骼数据时间维度信息自适应其卷积核的权重,使得模型的准确率得到更有效的提升。
附图说明
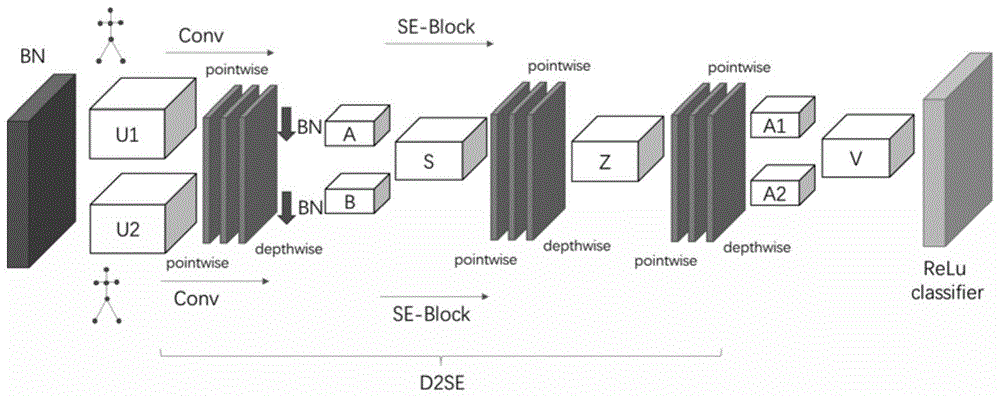
图1为本发明的d2se模型的网络层示意图;
图2为本发明的azureforkinect骨骼点数据采集示意图;
图3为本发明的人体骨骼数据具体分布示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合说明书附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
请参阅图1-3,一种基于骨骼数据双通道深度可分离卷积的行为识别方法,所述方法包括以下步骤:
步骤一:使用azureforkinect获取人体行为姿态数据;
步骤二:使用类邻接矩阵策略对骨骼点数据处理提取行为空间特征;
步骤三:将depth层和point层嵌入卷积层中,构建d2se双通道深度可分离卷积层,在时间维度上提取行为时间特征;
步骤四:将图卷积上的空间信息和d2se网络层上的时间信息叠加提取姿态行为的时空信息。
步骤五:使用relu函数获取骨骼动作分类。
通过azureforkinect获取人体32个关节骨骼点数据,如图3所示,对获取的骨骼点数据进行预处理,具体为:
从文件中获取姿态骨骼序列,去除噪声数据,获取的骨骼点为32个身体关节数据,关节层次结构按照从人体中心向四肢的流向分布,每个连接点将父关节与子关节链接起来。
获取的数据为连续的骨骼点帧数据,维度为(t、v、c),t表示时间,v表示关节点、c表示骨骼点坐标空间位置(x、y、z)。
将处理后的骨骼点数据使用类邻接矩阵策略转换成一张伪图像矩阵来提取行为空间特征,具体操作为:首先构建一个图矩阵,骨骼点即为图矩阵的节点n,骨骼点之间的连接即为图矩阵的边s,对于每一个骨骼点,邻节点个数不固定,通过定义一个映射函数l将参数和邻节点对应,可用如下函数操作表示。
其中f是输入输出的特征张量,w是权重,n是节点,i表示节点n于w权重之间映射,z是归一化操作。
建立d2se层网络,使用d2se卷积提取相邻帧上的时间信息,具体操作如下:
d2se层网络分两部分,一个是se-block单元,本实例中使用双向se通道对输入数据进行卷积操作,se层嵌入使用点卷积depthwise和深度pointwise卷积处理,具体为:
引入se-block单元:输入为骨骼点的channel数据,构建block_list块,步长为1,使用两个branch,branch全局参数r为16,l为32(r为压缩因子,l为d的最小值,d为卷积操作的输出特征,c为输入特征的channel),如下所示:
d=max(c/r,l)
构建ds层网络,将ds层作为se-block的卷积层读入数据。
ds层操作以及参数设置如下:
pointwise卷积层(卷积核1*1,步长0)->bn层归一化->pointwise卷积层->bn归一化层->depthwise卷积层。
pointwise卷积层卷积核kernel_size为1*1,步长stride为1,padding为0,dilation膨胀系数为1,卷积组groups为1,偏置项bias为false。
depthwise卷积层将ds层接受参数作为输入。
对于第一个branch,执行一次ds卷积操作,ds参数为,3*3卷积核,步长为1,dilation为1。
对ds卷积后的features进行relu激活得到特征图a,如图1所示。
对于第二个branch,执行一次ds卷积操作,ds参数为5*5卷积核,步长为2,dilation为2;对ds卷积后的features进行relu激活得到特征图b,如图1所示。
将特征图a和特征图b使用sum进行融合操作得到特征图u,使用自适应平均池化adaptiveavgpool_2d降采样,输出1*1尺寸的特征图s,如图1所示,h、w为输入特征图的高和宽,特征图s可表达为如下:
全连接层fc读入特征图s,同样使用两次ds卷积,参数为1*1的卷积核,步长为1,对卷积后的features使用relu激活,得到特征图z,δ为relu函数,b为归一化函数,ws为ds的输出特征,f(fc)为全连接函数。
z=ffc(s)=δ(b(ws))
将全连接后的特征图z再进行两次ds卷积操作,参数为1*1的卷积核,步长为1,padding为0。
通过线性变换还原全连接层fc压缩状态,输出为两个channel,分别进行softmax归一化操作,此时每个channel对应自身的价值,表示channel的重要程度,也即seblock能够自适应特征图感受野权重,选择最优的权重,将两个channel乘上原始对应的特征图得到新的特征图a1,a2,如图1所示。
重复之前的sum融合操作,得到输出特征v。
原始特征图x经过ds卷积、融合fuse、池化pool、全连接fc、ds卷积、归一化bn、融合后得到特征图v,也即特征图v融合了多个感受野的信息。
特征图v使用最大池化降采样,通过relu激活后进行分类。
使用azureforkinect获取的数据训练d2se-gcn网络,采用随机梯度下降sgd优化网络参数,初始学习率base_lr为0.1,权重衰减weight_decay为0.0001,训练和测试样本的batch_size设置为64,训练epoch设置为80,warm_up预热学习率设置为5个epoch。
其中,学习率更新分为两个阶段,模型预热阶段和正式训练阶段,使用预热学习率能使得模型收敛速度变得更快,具体为:
模型训练预热阶段,学习率更新为:
模型正式训练阶段,学习率更新为:
lr=0.1sum(f(step))×base_lr
模型使用交叉熵作为损失函数,在每batch_size样本被训练后,初始化梯度为0,反向传播求得梯度,更新模型参数。
训练完所有epoch后,将测试集输入模型预测,使用top-1作为测试集预测结果,以此衡量模型的性能。
将测试样本输入已训练好的双通道深度可分离卷积d2se-gcn模型中,输出向量中最大值对应的姿态行为类别即可判断该测试样本的动作类型,实现姿态行为的准确识别。
为了与公开模型对比性能,将d2se-gcn与主流深度学习模型做对比,如表1-姿态行为识别top1对比图所示,基于双通道深度可分离卷积的动作行为识别准确率较其他模型在nut的x-sub和x-view数据上表现更好。
基于双通道的性能优势在于,普通的se块通过网络根据loss学习特征权重,使得有效的featuremap权重和无效的featuremap自适应,但是在网络的计算过程中不可避免的增加了参数和计算量,深度可分离卷积层网络架构隐式依赖提供一种更高效的划分方法,在提高基于深度分离卷积架构性能的同时不会引入额外的复杂度,同时能使卷积层的参数明显缩减,而双通道的模型在输入特征适应不同卷积核,多视野域卷积能使得fuse和split的操作后全局感受野自适应调整。
表1
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!