一种基于STFT的双通道语声分离方法与流程
本发明涉及一种语音处理方法,尤其是涉及一种基于stft的双通道语声分离方法。
背景技术:
人声分离的主要技术来自于对频率和相位的处理,现有的技术基本都是两个手法联动作业,比如先进行频率阶段的滤波,在某些频率上再使用相位抵消。dft算法可以有效的将时域信息转换为频域信息,dft反变换则可以将频域信息转换为时域信息。dft算法在数字滤波、功率谱分析、通讯理论中有广泛的应用。将此技术应用于人声与背景音乐的分离上,并加以改进,可以很好的分离人声。
单通道音乐人声分离中的多种特定乐器强化分离方法涉及一种单通道音乐人声分离中的多种特定乐器强化分离方法。该方法对电吉他、单簧管、小提琴、钢琴、木吉他、风琴、长笛和小号共计8种乐器进行强化分离,该强化分离是通过一层单乐器分离器和三层多乐器组合强化器实现,其中,第一层多乐器组合强化器能够分离2类乐器声,第二层多乐器组合强化器能够分离4类乐器声,第三层多乐器组合强化器能够分离8类乐器声。然而该技术局限于对乐器声音的分离,应用领域较为狭窄;仅仅可以处理单通道音乐,单声道中所具有的信息太少,从而只能根据语声与背景音乐的差异性进行区分,这样带来的结果通常情况下是难以想象的。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种能够很好的分离人声与背景音乐的基于stft的双通道语声分离方法。
本发明的目的可以通过以下技术方案来实现:
一种基于stft的双通道语声分离方法,用于将语声和背景音乐分离,包括以下步骤:
s1,分别对左声道和右声道的时域信号序列进行stft变换,得到左声道和右声道的频域信号序列,各频点的信号分离表达式如下:
其中,|ωl|为左声道信号的模值,
s2,令各频点|ωhumanl|=|ωhumanr|,
s3,对步骤s2得到的结果进行stft反变换,并进行噪声滤波,得到语声和音乐分离后的左声道和右声道的时域信号。
所述的步骤s2中,左、右声道背景音乐分量之间的夹角条件为:当频点信号的频率大于603hz时,
单个拾音装置接收音频的角度
所述的步骤s2中,语声分量与频点信号之间的夹角条件为:
所述的stft变换中,将时域信号序列分片,并对每个片段加窗提取前4个频点信号,窗函数为
与现有技术相比,本发明通过stft算法(短时傅里叶变换),得到频域信号后,可以将背景音乐和语声有效分离;半重叠的stft方案,可以在减弱接续冲激的前提条件下完全还原原始信号;考虑拾音系统的角度范围和拾音系统两通道之间的距离,确定了不同的相差条件,从而使计算结果更加准确;对得到的最后结果进行滤波,滤除不必要的噪声,可应用于k歌类型的手机应用程序中。
附图说明
图1为本发明方法的流程图;
图2为实施例拾音系统与声源关系示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例
如图1所示,一种基于stft的双通道语声分离方法,用于将语声和背景音乐分离,包括以下步骤:
s1,分别对左声道和右声道的时域信号序列进行stft变换,得到左声道和右声道的频域信号序列。
s2,令各频点|ωhumanl|=|ωhumanr|,
s3,对步骤s2得到的结果进行stft反变换,并进行噪声滤波,得到语声和音乐分离后的左声道和右声道的时域信号。
对于每一个频点,有下面的等式:
ωi=ωhuman+ωmusic
其中ωi为第i个频点的复数值,ωhuman为第i个频点的语声分量,ωmusic是背景音乐的分量了。这里所有的变量都是复数,换言之,可以将上式写成
对于双声道的歌曲会有
对于等式(1),左边是的已知变量,某一频点的复数值,也可以分解为单位向量和模值。左边的变量有两个,而所求的右边变量有四个,考虑到频点的独立性,可以认为在数值上等式(1)是不可解得。同样对于等式(2)也会有类似的结论。考虑到日常听的专辑其中的语声多数都是通过一个话筒录入的,即在任意频点,应该有:
|ωhumanl|=|ωhumanr|
从而,将等式(2)变换为下面的形式:
若采用离散傅里叶变换(dft),如下所示
其中:
假设对于两条(包含左右声道)足够长的序列进行分片,得到:
经过分片傅里叶变换之后得到的结果为
其中ωrij表示右声道第i个切片的第j项,ωlij表示左声道第i个切片的第j项。如果希望反变换之后的所有切片贴合,尽量不产生冲激响应,应该要求任意频点在各个切片之间的变化尽量小。可以选择一段未处理的音频对其进行分片傅里叶变换,并选择其中同一位置的频点进行分析,以观察连续且没有接续冲激响应的频率相位变化。
假设有一段正弦信号,用某一固定长度的时域片采样,在此时间片内信号经过的相位为:
对于第n个采样周期,认为其采样的范围是:
其中n为某一小时域切片所经历的周期数,
模值上的特征不如相位上的特征明显,但是信号通过频域重建之后,相邻切片之间的时域信号必须连续顺滑,否则将会出现明显的冲激响应。
接下来尝试通过式(7)中的xrij及xlij重建出新的x'rij及x'lij。由于算法假设必然会导致相邻小片之间的相位出现剧烈变化,也会导致时域上的信号不再连续。正因为这个原因,stft变成了解决这个问题的首选。
可以把stft看作是相互重叠的傅里叶变换的小片。比如对于下面的信号:
x(n)=xn,x∈{x0,x1,x2,x3,…,xi-2,xi-1,xi,…}
可以选择其中连续的四个值作为一个处理单元。提取其中的处理单元的过程可以称作加窗。假设有一个窗函数:
如果需要取出x最前面的四个值,只需要将w(n)与x点乘:
x'(n)=x(n)·w(n)
假设相邻的窗函数之间相差δp的距离,可以认为第m个窗口所截取的信号为:
s(m,n)=x(n)·w(n-δp·m)
那么可以认为第m个窗口的stft变换结果为
s(m,n)=dft(x(n)·w(n-δp·m))(9)
当然随着窗函数的不同以及相邻窗的间隔δp的不同,短时傅里叶变换会有不同的结果。当窗函数由l个连续的1组成,并且有δp=l,短时傅里叶变换就回归到切片傅里叶变换。而在上文中所介绍的连续短时傅里叶变换如果直接离散化,应该是建立在δp=1的基础之上。事实上δp的取值是非常随意的,如果仅仅是希望同时在时域和频域上观察信号。
在δp等于1的前提下,可以获得最细致的观察步长。但是由于信号信息量的不变性,δp为1的结果更确切地说应该是有效信息的线型组合,毕竟在δp=l的前提条件下就可以无损地保持信号的信息量了。
由于本专利讨论的是需要将信号进行重组,意味着窗函数以及步进的选择应该满足特定的等式,使信号在变换之后直接反变换可以得到原始的结果。这样随意选择窗函数就会加重算法的负担。当然了,任意窗函数在δp=l的前提条件下都会精确地返回,但是这样做又会与上文的dft切片没有区别,引入难以处理的冲激响应。
本专利提出了一种半重叠的stft方案,可以在减弱接续冲激的前提条件下完全还原原始信号。对于等式(3.9),有
s(m,n)=dft-1(s(m,n))(10)
考虑到窗函数w(n),本发明认为逆变换的窗函数因子应具有与之前窗函数一样的形式:
结合之前s(m,n)的表达式,有
令
h(n)=w2(n)
利用h(n)可以将y(n)重新写成:
为了得到完全的信号重建,要求:
其实只要满足等式(3.12)的h(n)可以实现完全的信号重构。考虑到信号的渐变效果,可以选取窗函数:
此时选取
当然,这里的n是一个偶数。所以会有
到这里为止,建立了后文将会用到的可以尽量减弱接续冲激响应的stft模型以及逆stft模型。
在短时傅里叶变换之后得到的频域结果可以进行下一步的语声音频分离算法了。接下来的所有的处理过程都是对每一个频点进行处理。令s(m,n)为这里的输入参数。考虑到信号的来源是左右声道,结合式(2),有:
如果令:
得到下面这个简单的等式:
这里的参数g是上文没有出现的,这里假设的模型更为精确。如果语声在后期处理的时候出现响度上的偏移,比如要做在耳边唱歌的效果,g1≠g2。不过这里仅仅考虑g1=g2的情况。两个参数具体为多少并不重要,因为
所以等式(13)可变为:
考虑某一频点除去中间部分(语声
所以,有第一个通过假设和先验知识得来的附加条件,这一条件在后文也称之为第一相差条件:
这一等式看似简单确是求解问题的关键。这样的假设其实有很多的问题,因为现在左右声道的录音之间的距离只有30cm左右,而对于300hz以内的部分而言,左右声道的相差达到90°是几乎不可能的。因为300hz以内的声波波长一定大于1米,而考虑声源到左右声道接入点的距离,会有:
只有在声源出现在两个接收器的延长线上时,这一音源发出的这一频点才会达到0.6π。以下具体讨论对于不同频率夹角选择的优化。这里仍然以
将等式(14)代入到(15)中,会有:
化简得:
这里的θ是
将其按照二阶方程进行求解,可以得到两个根:
考虑到能量分布的问题,这里取负号。所以:
所以需要求解的所有分量为:
接下来的工作就是代入等式(11)求解stft反变换。对得到的最后结果进行滤波,滤除不必要的噪声即可。
上文在对于等式(4)求解时利用了等式(5),认为所有频点的夹角的均值应该是
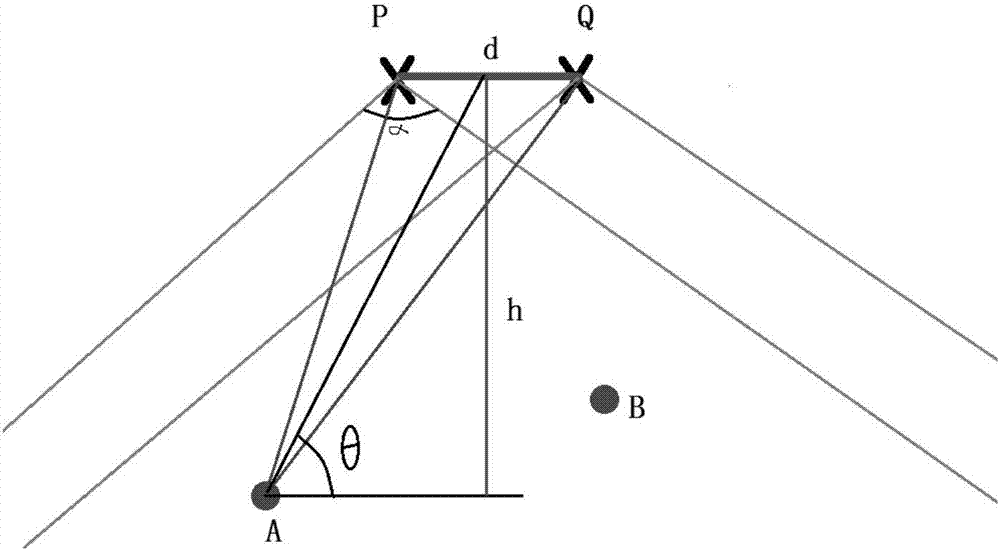
另外需要考虑的是收音制式的收音角度的影响。对于两个特定的观测点——对于人类而言是左右耳,对于拾音系统而言是左右声道收音器,而对于后期处理则是两个声音模拟的接收点,音源位置往往在这两个观测点的前方的一个有限的收音场内,如图2所示:
由于拾音系统通常情况下有一定的角度范围,可以简单地认为拾音装置p,q只能在一定角度范围之间接收音频,这一角度在图中用α来表示。对于一个小型乐队伴奏而言,对这一角度的要求往往并不是非常苛刻,换句话说,音源与拾音装置的连线,与两个拾音装置延长线的夹角θ不是一个非常小的锐角。设想录制交响乐的场景,拾音系位于在乐队之前。由于交响乐团队的人数以及空间上的分布,拾音系统往往要求乐队摆成一个扇形的阵型,并且对每一声部有具体的要求,比如首席小提琴师无论是出于声音效果还是传统都会位于乐队近似中心的位置。
对于音频像点距离拾音系统的尺度以及拾音系统两通道之间的距离也是值得研究的。现代通常情况拾音系统双声道之间的距离为:
d=30cm
而h通常情况下是1~2m,当然这个距离往往会更加随意一点,而这一距离其实也暗含着后期制作时添加像点的距离。所以可以认为,某一音源到达两个拾音装置时的相差为:
这一等式说明了:到达两个拾音之间的相差并不会随音源距离拾音系统的距离增加而出现距离而剧烈变化,而且由于d的确定,在低频范围内,
原因:在λ较大的时候,由于d较小,并且θ较大,两个拾音装置之间的相差是不会到达
可以给定图2中的α上限。特别的,可以认为所有的音源都从拾音系统的一边出现并且:
建立在以上条件之下,对于波长为λ的声波,到达两个拾音装置之间的相差最大值为θ最小的时候,而位于两拾音设备垂直平分线上的所有音源都会不会有相差:
建立在等式(23)基础之上,有:
这时对于上节中等式(15)修正为,这一等式也称为第二相差条件:
给定这里的参数值,λ为当前处理频点的波长,
由等式(25)以及等式(14),有:
代入α,d,有:
由等式(26)可得,当波长小于0.2819m,相差条件应该选择等式(15)。考虑到运算位于频域,并且空气中声波的速度为340m/s,有:
所以在检测频点小于603hz时选择第二种相差条件,频点数值大于603hz时选择第一相差条件。给定限制条件之后就可以对方程进行求解。在第二相差条件之下,有如下等式:
这里
考虑到音频绝大多数能量都集中在中低频的范围内,而在这一范围内,声波在两个拾音装置之间(只有30cm左右),在空气中的衰减的幅度相差并不大。具体的,由于距离相差距离较短,并且不考虑空气吸收衰减,地面吸收衰减,仅仅考虑扩散衰减,可以认为声源距离两个拾音设备最少1m,有:
其中l1,l2为某一声源距离两个拾音装置的距离,p1,p2为声源发出的声波到达两个拾音装置的声压。事实上,这两者的比值应该略大于1,而不是靠近上式得到的结果1.69,因为这里声源一般会在两个拾音设备的正对面,而不是在侧面的延长线上,并且声源的距离也会大于1m。这一等式的意义在于给出一个变化的上界,从而方便建立下面的近似:
结合等式(28)得到这样近似的误差范围:
事实上这是一个可以接受的误差范围。并且相信在大多数情况下,这种近似可以得到较为精确的结果。将其代入等式(27),尝试消去
化简得:
与等式(18)一样的原理,将一次项作近似化为标量:
一元二次方程的各项系数为:
求解仍然按照上文所述方案并考虑符号的统一性,同样应该取符号为负的根,原理同上,不应该得到一个反向的左右声道:
由于各种反射绕射衍射所致,在低频处并不是两边相差几乎为零。在这里仅简单地写成:
之后的操作就是在处理后的左右声道进行短时傅里叶变换反变换,得到时域信号。对时域信号进行滤波处理,滤掉因为处理产生的高频部分的噪声,得到最终结果:
- 还没有人留言评论。精彩留言会获得点赞!