一种说话人确认方法及装置与流程
本发明涉及语音识别领域,更具体地,涉及一种说话人确认方法及装置。
背景技术:
说话人确认是通过声音特征对说话人进行身份验证的方法。在进行说话人确认时,用户先预留一段声音,然后输入验证语音。将验证语音与系统预留语音进行对比,即可判断该用户是否存在。
目前,说话人确认方法以统计模型为主,性能较好的说话人确认方法一般基于i-vector模型和plda模型。i-vector模型对语音信号建立如下线性模型:
x=tw+v
其中,x为语音信号的mfcc特征,t为一个低秩矩阵,w为句子向量,即i-vector,v为高斯噪声。该模型事实上是一个概率pca模型。实际应用中,一般将语音空间分成若干区域,对每个区域进行上述线性建模。所有区域共享句子向量w。w是一个低维向量,包含说话人、说话内容、信道等信息。为提高对说话人的区分性,引入plda模型:
w=hu+kc+n
其中u为说话人向量,c为表达向量,包括发音方式,信道等,n为高斯噪声。plda将说话人特征和表达特征区分开。
上述模型基于通用的mfcc特征,通过模型将说话人信息分离出来。该方法基于信号的分布状态建模,因此需要较多的数据才能得到较好的结果,而且计算量较大,且容易受到信道、噪声和时变的影响。
技术实现要素:
为克服上述需要数据多、计算量大且鲁棒性差的问题或者至少部分地解决上述问题,本发明提供一种说话人确认方法及装置。
根据本发明的一个方面,提供一种说话人确认方法,包括:
获取第二语音;
将预先获取的第一语音和所述第二语音转换成对应的第一声谱图和第二声谱图;
使用卷积神经网络对所述第一声谱图和所述第二声谱图进行特征提取,获取对应的第一特征和第二特征;
使用时延神经网络对所述第一特征和所述第二特征进行特征提取,获取对应的第三特征和第四特征;
根据所述第三特征和所述第四特征对说话人进行确认。
具体地,在使用卷积神经网络对所述第一声谱图和所述第二声谱图进行特征提取之前,还包括:
对所述卷积神经网络和所述时延神经网络进行训练。
具体地,在使用时延神经网络对所述第一特征和所述第二特征进行特征提取之前,还包括:
对所述第一特征和所述第二特征进行降维。
具体地,所述使用时延神经网络对所述第一特征和所述第二特征进行特征提取,获取对应的第三特征和第四特征,包括:
分别对所述第一语音和所述第二语音中的帧进行拼接;
对所述第一语音中拼接后的帧对应的所述第一特征和所述第二语音中拼接后的帧对应的所述第二特征进行降维;
对降维后的所述第一特征和第二特征进行线性变换,获取对应的第三特征和第四特征。
具体地,对所述卷积神经网络和所述时延神经网络进行训练,包括:
使用交叉熵函数作为目标函数对所述卷积神经网络和所述时延神经网络进行训练。
根据本发明的另一个方面,提供一种说话人确认装置,包括:
获取单元,用于获取第二语音;
转换单元,用于将预先获取的第一语音和所述第二语音转换成对应的第一声谱图和第二声谱图;
第一提取单元,用于使用卷积神经网络对所述第一声谱图和所述第二声谱图进行特征提取,获取对应的第一特征和第二特征;
第二提取单元,用于使用时延神经网络对所述第一特征和所述第二特征进行特征提取,获取对应的第三特征和第四特征;
确认单元,用于根据所述第三特征和所述第四特征对说话人进行确认。
具体地,还包括:
训练单元,用于对所述卷积神经网络和所述时延神经网络进行训练。
具体地,还包括:
第一降维单元,用于对所述第一特征和所述第二特征进行降维。
具体地,所述第二提取单元包括:
拼接子单元,用于分别对所述第一语音和所述第二语音中的帧进行拼接;
第二降维子单元,用于对所述第一语音中拼接后的帧对应的所述第一特征和所述第二语音中拼接后的帧对应的所述第二特征进行降维;
变换子单元,用于对降维后的所述第一特征和第二特征进行线性变换,获取对应的第三特征和第四特征。
具体地,所述训练单元具体用于:
使用交叉熵函数作为目标函数对所述卷积神经网络和所述时延神经网络进行训练。
本发明提出一种说话人确认方法及装置,通过将卷积神经网络和时延神经网络相结合,对所述第一语音和所述第二语音进行两次特征提取,将最终提取的第三特征和所述第四特征进行比较,从而实现对说话人的确认,本发明计算简单,鲁棒性强,能达到很好的识别效果。
附图说明
图1为本发明实施例提供的说话人确认方法流程图;
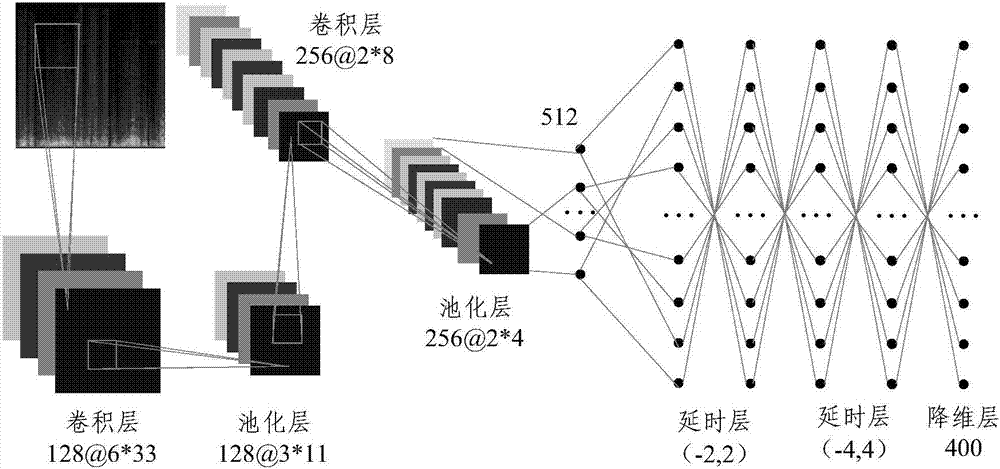
图2为所述卷积神经网络和所述时延神经网络模型结构图;
图3为本发明实施例提供的说话人确认装置结构图;
图4为本发明又一实施例提供的说话人确认装置结构图;
图5为本发明又一实施例提供的说话人确认装置结构图;
图6为本发明又一实施例提供的说话人确认装置结构图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
图1为本发明实施例提供的说话人确认方法流程图,包括:s1,获取第二语音;s2,将预先获取的第一语音和所述第二语音转换成对应的第一声谱图和第二声谱图;s3,使用卷积神经网络对所述第一声谱图和所述第二声谱图进行特征提取,获取对应的第一特征和第二特征;s4,使用时延神经网络对所述第一特征和所述第二特征进行特征提取,获取对应的第三特征和第四特征;s5,根据所述第三特征和所述第四特征对说话人进行确认。
具体地,s1中,获取所述第二语音,所述第二语音为说话人新录入的语音,是需要验证的语音。s2中,所述第一语音为说话人预先录入的语音,每一条第一语音对应有一个说话人标签,根据所述说话人标签能唯一确认说话人。所述第一语音可以包括多个说话人的语音,每个说话人可以对应有一条或多条第一语音。将所有的所述第一语音转换成第一声谱图,将所述第二语音转换成第二声谱图。所述第一声谱图和所述第二声谱图的横轴表示时间,纵轴表示频率,颜色或亮度表示幅度。
s3中,使用卷积神经网络对所述第一声谱图和所述第二声谱图进行特征提取。所述卷积网络可以包括多个卷积层。每个卷积层的卷积核的个数和大小可以根据需要进行调整。在使用每个卷积核对所述第一声谱图和所述第二声谱图进行卷积时,都会生成一个特征平面。每个卷积层后可以接一个池化层。所述池化层可以为最大池化层或平均池化层。所述池化层的窗口可以重叠,也可以不重叠。所述池化层的窗口大小可以根据需要进行调整。可以使用低阶矩阵对第二个所述池化层得到的特征平面进行降维,但不限于此种降维方式。
s4中,所述时延网络可以包括多个时延层,每个时延层分别对所述第一语音和所述第二语音中的帧进行拼接,并对所述第一语音中拼接后的帧对应的所述第一特征和所述第二语音中拼接后的帧对应的所述第二特征进行降维。本发明不限于降维的方法。然后对降维后的所述第一特征和第二特征进行线性变换,获取对应的第三特征和第四特征。由于所述第一特征和所述第二特征也为声谱图,声谱图的横坐标表示时间,所述第一语音和所述第二语音中的每一帧也有对应的时间。因此,所述第一语音中拼接后的帧对应的所述第一特征为所述第一语音中从拼接后的帧中的第一帧到最后一帧时间段内的第一特征,所述第二语音中拼接后的帧对应的所述第二特征为所述第二语音中从拼接后的帧中的第一帧到最后一帧时间段内的第二特征。
s5中,将所述验证语音通过所述神经网络进行前向计算,提取所述第一语音和所述第二语音中每一帧的特征。可以根据每一帧的特征使用任何统计模型对说话人进行确认。如分别计算所述第一语音和所述第二语音中每一帧的特征的平均值,计算所述第二语音中每一帧的特征的平均值和每条所述第一语音中每一帧的平均值之间的距离。所述距离可以为余弦相似度。但不限于此种距离。当计算出的余弦相似度大于预设阈值时,则根据所述第一语音对应的说话人标签确认当前说话人。
本实施例通过将卷积神经网络和时延神经网络相结合,对所述第一语音和所述第二语音进行两次特征提取,将最终提取的第三特征和所述第四特征进行比较,从而实现对说话人的确认,本发明计算简单,鲁棒性强,能达到很好的识别效果。
图2为所述卷积神经网络和所述卷积神经网络的结构图,如图2所示,所示卷积神经网络的输入为频谱图。所述卷积神经网络有两个卷积层,第一个卷积层的卷积核为128个,每个卷积核的大小为6x33;第一个池化层的池化窗口大小为3x11。第二个卷积层的卷积核为256个,每个卷积核的大小为2x8。第二个池化层的池化窗口大小为2x4。对第二个池化层得到的256个特征平面进行降维,降维成512个特征,对应512个神经元。所述时延网络有两个时延层,每个时延层通过时序拼接对上下文信息进行扩展。第一个时延层拼接前后各2帧信号,第二个时延层拼接前后各4帧信号。每个时延层后接一个降维层。每个降维层将延时层进行降维,输出400个特征。对所述第二个时延层的降维层的输出的400个特征进行线性变换。
在上述实施例的基础上,本实施中在使用卷积神经网络对所述第一声谱图和所述第二声谱图进行特征提取之前,还包括对所述卷积神经网络和所述时延神经网络进行训练。
具体地,在训练前,获取需要确认的说话人的语音,将需要确认的说话人的语音作为训练集。在进行训练时,将所述语音中的每一个帧作为学习样本,经过所述卷积神经网络和所述卷积神经网络两次特征提取后,计算所述两次特征提取前后该帧的特征之间的距离,确认该帧的说话人是否为该帧对应的说话人标签,使用说话人确认的误差信息反向调整所述卷积神经网络和所述卷积神经网络中的参数。目标函数为交叉熵函数。训练时使用的后向反馈算法可以为nsgd(naturalstochasticgradientdescent,自然随机梯度下降)算法或任何深度神经网络训练方法。
本实施例中,使用语音中的每一个帧作为学习样本对所述卷积神经网络和所述卷积神经网络进行训练,调整所述卷积神经网络和所述卷积神经网络中的参数,该种训练方法需要的数据少,使用优化的参数能提高说话人确认的准确性。
图3为本发明实施例提供的说话人确认装置结构图,如图3所示,包括获取单元1、转换单元2、第一提取单元3、第二提取单元4和确认单元5,其中:
所述获取单元1用于获取第二语音;所述转换单元2用于将预先获取的第一语音和所述第二语音转换成对应的第一声谱图和第二声谱图;所述第一提取单元3用于使用卷积神经网络对所述第一声谱图和所述第二声谱图进行特征提取,获取对应的第一特征和第二特征;所述第二提取单元4用于使用时延神经网络对所述第一特征和所述第二特征进行特征提取,获取对应的第三特征和第四特征;所述确认单元5用于根据所述第三特征和所述第四特征对说话人进行确认。
具体地,所述获取单元1获取所述第二语音。所述第二语音为说话人新录入的语音,是需要验证的语音。所述转换单元2将所有的所述第一语音转换成第一声谱图,将所述第二语音转换成第二声谱图。所述第一语音为说话人预先录入的语音,每一条第一语音对应有一个说话人标签,根据所述说话人标签能唯一确认说话人。所述第一语音可以包括多个说话人的语音,每个说话人可以对应有一条或多条第一语音。所述第一声谱图和所述第二声谱图的横轴表示时间,纵轴表示频率,颜色或亮度表示幅度。
所述第一提取单元3使用卷积神经网络对所述第一声谱图和所述第二声谱图进行特征提取。所述卷积网络可以包括多个卷积层。每个卷积层的卷积核的个数和大小可以根据需要进行调整。在使用每个卷积核对所述第一声谱图和所述第二声谱图进行卷积时,都会生成一个特征平面。每个卷积层后可以接一个池化层。所述池化层可以为最大池化层或平均池化层。所述池化层的窗口可以重叠,也可以不重叠。所述池化层的窗口大小可以根据需要进行调整。
所述时延网络可以包括多个时延层,所述时延网络包括多个全连接的时延层,每个时延层中的所述第二提取单元4通过拼接前后各帧对上下文信息进行扩展。拼接前后各帧的数目可以根据需要进行设置。
所述确认单元5将所述验证语音通过所述神经网络进行前向计算,提取所述第一语音和所述第二语音中每一帧的特征。可以根据每一帧的特征使用任何统计模型对说话人进行确认。如分别计算所述第一语音和所述第二语音中每一帧的特征的平均值,计算所述第二语音中每一帧的特征的平均值和每条所述第一语音中每一帧的平均值之间的距离。所述距离可以为余弦相似度。但不限于此种距离。当计算出的余弦相似度大于预设阈值时,则根据所述第一语音对应的说话人标签确认当前说话人。
本实施例通过将卷积神经网络和时延神经网络相结合,对所述第一语音和所述第二语音进行两次特征提取,将最终提取的第三特征和所述第四特征进行比较,从而实现对说话人的确认,本发明计算简单,鲁棒性强,能达到很好的识别效果。
图4为本发明实施例提供的说话人确认装置结构图,如图4所示,在上述实施例的基础上,还包括:训练单元6,用于对所述卷积神经网络和所述时延神经网络进行训练。
具体地,在训练前,获取需要确认的说话人的语音,将需要确认的说话人的语音作为训练集。在进行训练时,所述训练单元6,将所述语音中的每一个帧作为学习样本,经过所述卷积神经网络和所述卷积神经网络两次特征提取后,计算所述两次特征提取前后该帧的特征之间的距离,确认该帧的说话人是否为该帧对应的说话人标签,使用说话人确认的误差信息反向调整所述卷积神经网络和所述卷积神经网络中的参数。目标函数为交叉熵函数。训练时使用的后向反馈算法可以为nsgd(naturalstochasticgradientdescent,自然随机梯度下降)算法或任何深度神经网络训练方法。
本实施例中,使用语音中的每一个帧作为学习样本对所述卷积神经网络和所述卷积神经网络进行训练,调整所述卷积神经网络和所述卷积神经网络中的参数,该种训练方法需要的数据少,使用优化的参数能提高说话人确认的准确性。
图5为本发明实施例提供的说话人确认装置结构图,如图5所示,在上述各实施例的基础上,还包括:第一降维子单元7,用于对所述第一特征和所述第二特征进行降维。
具体地,使用所述卷积神经网络对所述第一声谱图和所述第二声谱图进行特征提取时,每个卷积核生成一张特征平面。当卷积核的数量很多时,会生成很多张特征平面,每张平面上有很多特征,虽然每个卷积层后接一个池化层,但特征数量依然很多,会大大降低计算速度。所以需要对所述卷积神经网络提取的所述第一特征或所述第二特征进行降维。可以使用低阶矩阵进行降维,本实施例不限于降维的方法。本实施例通过对所述第一特征和所述第二特征进行降维,大大提高了计算速度。
图6为本发明实施例提供的说话人确认装置结构图,如图6所示,在上述各实施例的基础上,所述第二提取单元4包括拼接子单元41、第二降维子单元42和变换子单元43,其中:
所述拼接子单元41用于分别对所述第一语音和所述第二语音中的帧进行拼接;所述第二降子维单元42用于对所述第一语音中拼接后的帧对应的所述第一特征和所述第二语音中拼接后的帧对应的所述第二特征进行降维;所述变换子单元43用于对降维后的所述第一特征和第二特征进行线性变换,获取对应的第三特征和第四特征。
具体地,每个延时层中所述拼接子单元41拼接的帧的数目相同,不同延时层中所述拼接子单元41拼接的帧的数目可以不同。拼接窗口可以重叠。所述第二降维子单元42对每个时延层中拼接的帧对应的特征平面进行降维。由于所述第一特征和所述第二特征也为声谱图,声谱图的横坐标表示时间,所述第一语音和所述第二语音中的每一帧也有对应的时间。因此,所述第一语音中拼接后的帧对应的所述第一特征为所述第一语音中从拼接后的帧中的第一帧到最后一帧时间段内的第一特征,所述第二语音中拼接后的帧对应的所述第二特征为所述第二语音中从拼接后的帧中的第一帧到最后一帧时间段内的第二特征。可以对所述第一特征和所述第二特征上的平移窗口中的特征取平均值,用一个特征值为所述平均值的特征替代所述平移窗口中的特征,从而实现降维。本发明不限于对所述特征平面进行降维的方法。所述变换子单元43对降维后的特征进行线性变换。可以用逻辑斯蒂回归模型进行线性变换。
本发明实施例使用时延神经网络对所述第一特征和所述第二特征进行特征提取,获取对应的第三特征和第四特征,所述时延神经网络对特征具有较强的提取能力,为说话人的准确确认奠定基础。
最后,本申请的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!