基于话题的群体情感分析方法与流程
本发明涉及观点抽取、倾向性分析及用户画像
技术领域:
,尤其涉及一种基于话题的群体情感分析方法。
背景技术:
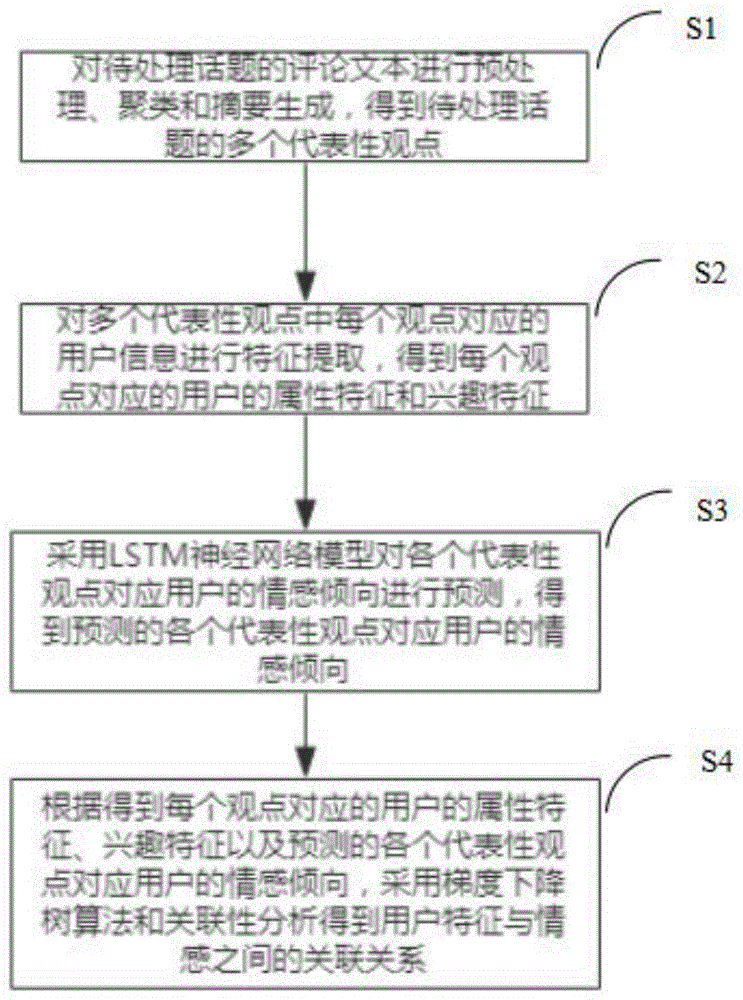
:传统的信息抽取(ie)技术和信息检索(ir)技术研究的重点是客观表达的事实信息。为从海量数据中发现有效、新颖、有用、可理解的模式,我们需要极性倾向分析和观点抽取技术,对于观点抽取技术,即使是英文语种,大多采用的也是统计学方法。统计学方法虽然对结构简单的句子可以取得较好的结果,但是,对于结构较复杂的语句,难以达到理想的效果。倾向性分析又称意见挖掘,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。互联网上产生了大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。基于此,潜在的用户就可以通过浏览这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法。用户特征建模的核心工作就是给用户打标签,标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、兴趣等。这些标签集合就能抽象出一个用户的信息全貌,每个用户都有自己的标签集合,每个标签分别描述了该用户的一个维度,各个维度之间相互联系,共同构成对用户的一个整体描述。机器学习是一门多学科交叉专业,涵盖概率论知识,统计学知识,近似理论知识和复杂算法知识,使用计算机作为工具并致力于真实和实时的模拟人类学习方式,并将现有内容进行知识结构划分来有效地提高学习效率。近年来,机器学习算法在各领域都得到了广泛的应用,将不同的机器学习算法结合起来是一个重要的研究方向。当前研究者关于观点抽取的工作主要关注主题抽取、语义极性倾向和极性强度三个方面,但是在具体的观点抽取方面没有取得很好的效果;目前用户特征建模的应用主要是个性化推荐(电商、资讯类产品)、风控、预测等方面,很少应用到情感分析领域;另外,舆情事件相关话题的用户特征与情感关联性分析在社交网络研究中还较少,之前研究者大多是对文本情感分析或者关于用户特征建模的单一研究,结果也没有较好的解释性。因此,开发一种以舆情事件为背景的基于话题的群体情感分析方法有重要的现实意义。技术实现要素:本发明提供了一种基于话题的群体情感分析方法,以实现以舆情事件为背景的群体情感预测。为了实现上述目的,本发明采取了如下技术方案。本实施例提供了一种基于话题的群体情感分析方法,其特征在于,包括:s1对待处理话题的评论文本进行预处理、聚类和摘要生成,得到待处理话题的多个代表性观点;s2对所述多个代表性观点中每个观点对应的用户信息进行特征提取,得到每个观点对应的用户的属性特征和兴趣特征;s3采用lstm神经网络模型对各个代表性观点对应用户的情感倾向进行预测,得到预测的各个代表性观点对应用户的情感倾向;s4根据得到每个观点对应的用户的属性特征、兴趣特征以及预测的各个代表性观点对应用户的情感倾向,采用梯度下降树算法和关联性分析得到用户特征与情感之间的关联关系。优选地,对待处理话题的评论文本进行预处理、聚类和摘要生成,得到待处理话题的多个代表性观点,包括:将对待处理话题的评论文本进行分词、去除特殊符号、简繁转换的预处理;把预处理后的文本输入到ap(affinitypropagationclustering,亲和力传播聚类)算法中,聚成若干类;选取类内用户数大于一定个数的类,用textrank算法对选取的类进行摘要生成;得到待处理话题的多个代表性观点。优选地,对所述多个代表性观点中每个观点对应的用户信息进行特征提取,得到每个观点对应的用户的属性特征和兴趣特征,包括:根据数据库中的用户信息对群体中的每个用户进行属性特征和兴趣特征的提取。优选地,采用lstm神经网络模型对各个代表性观点对应用户的情感倾向进行预测,得到预测的各个代表性观点对应用户的情感倾向,包括:对待处理话题的评论文本进行打标签,将打好标签的文本分为训练集和测试集,通过训练集对lstm(longshort-termmemory,长短时记忆)网络模型训练;采用训练好的lstm网络模型对各个代表性观点对应用户的情感倾向进行预测,得到预测的各个代表性观点对应用户的情感倾向。优选地,根据得到每个观点对应的用户的属性特征、兴趣特征以及预测的各个代表性观点对应用户的情感倾向,采用梯度下降树算法和关联性分析得到用户特征与情感之间的关联关系,包括:根据得到每个观点对应的用户群的情感倾向特征和预测的各个代表性观点对应用户的情感倾向输入到梯度下降树算法中,训练分类器,将用户特征与用户情感倾向进行关联,采用spearman系数进行特征关联性分析,并结合显著性检验的结果,进而得到最终的关联关系。优选地,方法还包括:采用测试集对训练好的lstm网络模型进行测试。优选地,测试集和训练集的比为4:1。优选地,标签包括正向、负向和中立三种,中立包括情感倾向不明确或者确实中立,正向是针对实验中的舆情事件相关话题的支持,负向是针对实验中的舆情事件相关话题的反对。优选地,属性特征和兴趣特征分别包括如下表1和2所示的特征:表1编号属性特征1id用户id2location位置3protected是否受保护4friends_count好友数5followers_count粉丝数6list_count所属公开组个数7created_at创建时间8favorites_count获得点赞数9time_zone时区10htc_offset时差11language语言12geo_enabled是否允许标识位置13verified是否认证14statuses_count总发文数15db_statuses_count数据库内发文数16max_retweet最大转发数17min_retweet最小转发数18max_favorite最大点赞数19min_favorite最小点赞数20max_length推文最大长度21min_length推文最小长度22zero_retweet零转发比例23zero_favorite零点赞比例24activity活跃度表2编号兴趣特征1美国2中国3中国台湾4党派5中国香港6媒体7政府8社会关系9国际政治10新冠疫情11教育12民主自由13法治14娱乐15华为16和平与战争17社交平台18食物19情绪20经济优选地,方法还包括:获取待处理话题的评论文本,具体包括:爬取实际的舆情事件在社交平台上的用户评论及用户个人历史发文数据作为实验数据集;统计该舆情事件相关的话题标签,选取评论数据及参与用户数均达到一定数量的话题标签,将每个话题标签作为一个话题,根据用户在社交平台上发文时附带的话题标签确定用户参与的话题,一个话题标签下的所有评论数据构成一个话题的实验数据集,即待处理话题的评论文本。由上述本发明的基于话题的群体情感分析方法提供的技术方案可以看出,本发明以舆情事件为背景,结合对用户特征的刻画,实现了对群体情感倾向更有效地预测,有效地改善了文本情感分析或者关于用户画像的单一研究结果解释性较差的问题。本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。附图说明为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例提供的一种基于话题的群体情感分析方法的流程示意图。具体实施方式下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。本
技术领域:
技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤和/或操作,但是并不排除存在或添加一个或多个其他特征、整数、步骤和/或操作的组。应该理解,这里使用的措辞“和/或”包括一个或更多个相关联的列出项的任一单元和全部组合。本
技术领域:
技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。为便于对本发明实施例的理解,下面将结合附图以几个具体实施例为例做进一步的解释说明,且并不构成对本发明实施例的限定。实施例图1为本发明实施例提供的一种基于话题的群体情感分析方法的流程示意图,参照图1,该方法包括:s1对待处理话题的评论文本进行预处理、聚类和摘要生成,得到待处理话题的多个代表性观点。具体包括:将对待处理话题的评论文本进行分词、去除特殊符号、简繁转换的预处理;把预处理后的文本输入到ap(affinitypropagationclustering,亲和力传播聚类)算法中,聚成若干类。在聚类初始时刻每条文本都可当作一个观点,根据文本之间的相似度不同,文本最终可聚成若干类。选取类内用户数大于一定个数的类,用textrank算法对选取的类进行摘要生成;得到待处理话题的多个代表性观点。同一类中都是相似度较高的观点,优选地,选取类内用户数大于20的类。s2对多个代表性观点中每个观点对应的用户信息进行特征提取,得到每个观点对应的用户的属性特征和兴趣特征。根据数据库中的用户信息对用户群体中的每个用户进行属性特征和兴趣特征提取。属性特征和兴趣特征分别包括如下表1和2所示的特征:表1编号属性特征1id用户id2location位置3protected是否受保护4friends_count好友数5followers_count粉丝数6list_count所属公开组个数7created_at创建时间8favorites_count获得点赞数9time_zone时区10htc_offset时差11language语言12geo_enabled是否允许标识位置13verified是否认证14statuses_count总发文数15db_statuses_count数据库内发文数16max_retweet最大转发数17min_retweet最小转发数18max_favorite最大点赞数19min_favorite最小点赞数20max_length推文最大长度21min_length推文最小长度22zero_retweet零转发比例23zero_favorite零点赞比例24activity活跃度表2s3采用lstm神经网络模型对各个代表性观点对应用户的情感倾向进行预测,得到预测的各个代表性观点对应用户的情感倾向。对待处理话题的评论文本进行打标签,将打好标签的文本分为训练集和测试集,通过训练集对lstm(longshort-termmemory,长短时记忆)网络模型训练;采用训练好的lstm网络模型对各个代表性观点对应用户的情感倾向进行预测,得到预测的各个代表性观点对应用户的情感倾向。示意性地,还可以选取部分待处理话题的评论文本进行打标签。标签包括正向、负向和中立三种,中立包括情感倾向不明确或者确实中立,正向是针对实验中的舆情事件相关话题的支持是针对实验中的舆情事件相关话题的反对。该方法还包括:采用测试集对训练好的lstm网络模型进行测试。本实施例中采用测试集对训练好的lstm网络模型进行测试的准确率为86%。其中,测试集和训练集的比为4:1。s4根据得到每个观点对应的用户的属性特征、兴趣特征以及预测的各个代表性观点对应用户的情感倾向,采用梯度下降树算法和关联性分析得到用户特征与情感之间的关联关系。通过梯度下降树算法可以实现根据用户特征预测用户情感倾向,通过特征与情感的关联性分析可以进一步明确在用户情感分类中哪些特征是更加显著的及相关关系(正相关或负相关)。根据得到每个观点对应的用户群的情感倾向特征和预测的各个代表性观点对应用户的情感倾向输入到梯度下降树算法中,训练分类器,将用户特征与用户情感倾向进行关联,能够根据用户特征预测用户情感倾向。采用spearman系数进行特征关联性分析,通过spearman系数分析某一特征在用户情感分类中是正向作用还是负向作用,spearman系数为负数则为负相关,反之为正相关,并结合显著性检验的结果,得到用户情感分类中的显著特征,便于分析持有某种情感的群体具有的群体特征。用户特征对于情感分类任务在显著性检验中的概率p。p是反映某一事件发生的可能性大小。在统计学中根据显著性检验得到的p值,一般以p<0.05为有统计学差异,p<0.01为有显著统计学差异,p<0.001为有极其显著统计学差异。其含义是样本间的差异由抽样误差所致的概率小于0.05、0.01、0.001。需要说明的是,该方法还包括:获取待处理话题的评论文本,具体包括:爬取实际的舆情事件在社交平台上的用户评论及用户个人历史发文数据作为实验数据集;统计该舆情事件相关的话题标签,选取评论数据及参与用户数均达到一定数量的话题标签,将每个话题标签作为一个话题,根据用户在社交平台上发文时附带的话题标签确定用户参与的话题,一个话题标签下的所有评论数据构成一个话题的实验数据集,即待处理话题的评论文本。以下为采用本实施例方法的具体算例,具体内容包括:1)以#hashtag1作为指定话题,则先对关于该话题的用户评论进行文本聚类,聚类得到100个群体观点,选取类内用户数大于20的类作为代表性观点,共取到了10个类,即该话题的10个代表性观点。2)统计这10个代表性观点中的用户,共4000个社交网络用户。对这4000个用户进行特征提取,包括如表1和表2所述的属性特征24维和兴趣特征20维。3)从话题的评论文本中随机选取5000条做标签标定,标签是正向、中立或者负向。以80%的数据作训练集,即4000条,剩下的20%作测试集,即1000条。用训练集训练lstm模型,用测试集对训练好的模型进行测试,得到改模型的最终准确率为86%。通过训练好的lstm模型对文本的情感倾向预测,用户在该话题下的所有评论文本的情感倾向即代表用户个人的情感倾向。4)将用户的属性特征、兴趣特征、情感特征输入到梯度下降树算法中,可以实现根据用户特征预测用户情感倾向。为了进一步发现单个特征与情感的关联关系,通过spearman系数并结合显著性检验分析进行特征关联性分析,spearman系数为负数则为负相关,反之为正相关。下表3为采用本实施例方法得到的结果,如下表3所示,除零转发比例外,粉丝数、好友数、获赞数、总推文数、数据库内推文数和最大转发数的几个特征spearman系数都为负数,说明零转发比例与情感特征成正相关,即零转发比例越大,用户情感越正向,其他几个表中的特征与情感成负相关。表3中的p值即用户特征对于情感分类任务在显著性检验中的概率。表3中的特征都是小于0.001的,说明粉丝数、好友数、获赞数、总推文数、数据库内推文数和最大转发数的特征对于情感分类是极为显著的特征。根据上述研究可以得到该话题中10个代表性观点中的4000个用户的特征与情感倾向的关联关系:粉丝数、好友数、获赞数、总推文数、数据库内推文数和最大转发数更多的用户对该话题更容易持反对意见,用户评论的零转发比例更大的用户更容易持支持意见。表3特征spearman系数p值粉丝数-0.29742.5777e-58好友数-0.24722.8630e-40获赞数-0.28934.0151e-55总推文数-0.30341.0264e-60数据库内推文数-0.36867.2970e-91最大转发数-0.44783.1991e-138零转发比例0.25807.6506e-44本发明实施例的基于话题的群体情感分析方法对社交网络用户提取了更全面更细粒度的特征,并首次应用属性特征及兴趣特征进行情感的预测及关联性分析,应用到真实的舆情事件分析和预测中。通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本发明可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例或者实施例的某些部分所述的方法。以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1