一种基于国产平台的图形加速优化方法与流程
本发明属于计算机图形学领域,具体涉及一种基于国产平台的图形加速优化方法。
背景技术:
在4k、4屏输出显示状态下,当图形应用程序输出的画面比较复杂时,现有国产gpu存在运算和处理能力不足的问题,无法满足显示性能需求。在特种应用场景中图形绘制应用较多,对显卡性能的要求较高,特别对于gpu的图形渲染能力有极高的要求。国产gpu单显卡性能较低,无法满足复杂应用系统高性能显示方面的需求,无法解决4k、4屏场景下单卡显示性能不足的问题。显卡超频可以暂时提高显卡的性能,但无法实现长时间运行,因为长时间超频不仅影响系统稳定性,还会减少硬件的寿命。
技术实现要素:
本发明目的是提供了一种基于国产平台的图形加速优化方法,实现两个独立的显卡在同一个cpu的控制下协同工作,各自承担不同的图形绘制任务,从而大幅提高平台的整体图形加速性能,实现双显卡的数据高速传输和同步渲染。
本发明为实现上述目的,通过以下技术方案实现:
一种基于国产平台的图形加速优化方法,其特征在于,包括以下步骤:
a)在主板不同的pcie插槽上,同时接插两块显卡,每块显卡包含一片图形处理芯片,两显卡之间采用特定的数据排线进行数据互联和交换;
b)启动双卡互联技术,cpu自动将复杂的绘图任务分解成两组独立的绘图子任务;
c)cpu分别向两个pcie插槽上的图形显卡发送绘图任务,包括包括配置数据、纹理图像数据、绘图顶点数据以及绘图命令;
d)显卡接收到绘制命令后分别绘制各自需要绘制的图形,绘制完成后两显卡通过内部专用互联总线将图形绘制数据传送到一个显卡上,由此显卡汇总两显卡的图形内容后,送至显示输出端口;
优选的,还包括显存访问优化,方法如下:
a)获取vram显存的物理地址和大小;
b)利用国产处理器的虚拟地址映射机制,为vram显存进行虚拟地址映射,把它映射到内核虚拟地址空间;
c)在vram显存位于页表中的页表项中,为其定义架构适应属性;
d)系统使用映射的虚拟地址访问vram显存。
优选的,还包括3d加速优化,扩展api接口支持、标准和技术支持,优化显示处理框架和显示架构,提高3d图形硬件加速性能,采用延迟io技术,减少显存操作;优化opengl图形库,进行适配优化,提升图形着色、渲染的性能。
优选的,还包括3d引擎设计,包括以下步骤:
a)在3d引擎中定义一组缓冲池的方式,建立缓冲区池模块和可动态伸缩的缓冲区机制,每一个渲染客户端可以拥有一个或多个缓冲区;
b)当前应用客户端需要缓冲区进行渲染时就会在该缓冲区池中获取一个新的对象缓存直接使用,使用完后再释放回缓冲区池中,当应用客户端的渲染上下文结束或销毁后,缓冲池中的每一个缓存将被释放;同时由于在整个渲染上下文中保存了旧缓冲区,在很多情况下可以重复利用这些缓冲内容进行增量渲染,减小了渲染的开销;
c)提供灵活的缓冲区池缓存数量的配置接口,根据实际需求灵活配置缓存数量。
本发明的优点在于:本发明拟采用双卡互联显示方案,实现两个独立的显卡在同一个cpu的控制下协同工作,各自承担不同的图形绘制任务,从而大幅提高平台的整体图形加速性能,关键难点是实现双显卡的数据高速传输和同步渲染。通过专用的高速互连通道实现双显卡的数据高速传输,解决数据传输速度的瓶颈;同时通过底层驱动调度,使用交错帧模式或分隔帧模式实现双显卡的同步渲染。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
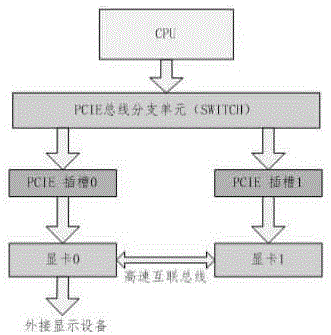
图1为本发明双卡互联显示技术结构示意图。
图2为本发明动态多缓冲机制执行框架示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
1)双卡互联设计
基于国产高性能gpu双卡互联的显卡实现技术可协同使用两块独立的显卡,使两块显卡并行工作,各自承担不同的图形绘制任务,从而大幅提高平台的整体图形加速性能。在此工作模式下,两个独立的显卡系统在同一个cpu的控制下协同工作,各自承担不同的图形绘制任务,从而大幅提高平台的整体图形加速性能。双卡互联显示技术在工作时,cpu可以根据绘图复杂度将同一帧画面自动划分成两个绘图子任务(上层驱动程序,可根据任务负载动态划分),分配给两块不同的显卡进行并行处理。这样单块显卡渲染的图元数目相对降低为原图形的一半,每帧渲染的时间相应缩短,以此达到提高绘图渲染效率的目的。
双卡互联技术采用的方案:在主板不同的pcie插槽上,同时接插两块显卡(显卡0和显卡1),每块显卡上均包含一片图形处理芯片(国产高性能gpujm7200芯片),两块显卡之间采用特定的数据排线进行数据互联和交换。
工作原理:在启动双卡互联技术时,cpu自动将复杂的绘图任务分解为两组独立的绘图子任务(具体划分形式可依据实际情况自动裁定),分别向两个pcie插槽上的图形显卡发送绘图任务(包括配置数据、纹理图像数据、绘图顶点数据以及绘图命令等)。显卡0和显卡1接收到绘制命令后分别绘制各自需要绘制的图形部分。当两个显卡都完成了各自的图形绘制任务后,显卡1会通过内部专用互联总线将图形绘制数据传送到显卡0上。最后由显卡0汇总两个显卡分别绘制的图形内容后,送至显示输出端口进行视频显示。
图形绘制性能:举例说明,采用的gpu芯片内核频率1.3ghz,像素填充率6gpixels/s,根据统计,双卡互联技术能够达到单显卡性能的85%以上提升的实际效果,像素填充率可以达到10.2gpixels/s。实际使用时,采用图像分割技术需要cpu发送两组相同绘图数据给两块显卡的gpu单元,会有一定的带宽损失,但是另一方面,分割发生在顶点处理之后,顶点处理的时间与单片相同,这部分时间无法并行。
计算能力:采用的gpu单片等效运算能力为1tflops,两片并行处理可以达到1.5tflops,执行科学计算基本没有性能损失,可以使两片gpu完全并行执行。
2)显存优化设计
由于国产处理器平台的处理能力不足,对写合并机制的支持不成熟,cpu端写vram显存的速率较低,影响了显示性能的发挥。基于此问题,需要对现有显存框架进行研究,针对显存管理进行优化,提升整体显存访问的性能。
国产处理器的mmu可以支持2级、3级和4级页表。mmu除了可以进行虚拟地址转换外,也可以对内存位置的访问权限和属性进行控制。对内存位置的访问权限和属性的控制也是以页为单位进行控制的,同样要借助于页表结构。页表的每一项中,除了保存有物理页帧号外,还保存有对页的访问权限和属性标志。
对于设备内存的时序属性,国产处理器提供了4种组合可供选择使用:ngnrne、ngnre、ngre和gre。因此为设置访问设备地址空间的时序属性提供了一定的灵活性。
操作系统中mair_el1寄存器只预定义了6组属性。要提升访问显卡显存vram的速度,只能放宽其访问时序要求。基于此特性,显存访问优化方法如下:
(1)获取vram显存的物理地址和大小;
(2)利用国产处理器的虚拟地址映射机制,为vram显存进行虚拟地址映射,把它映射到内核虚拟地址空间;
(3)在vram显存位于页表中的页表项中,为其定义架构适应属性;
(4)系统使用映射的虚拟地址访问vram显存。
经过上述优化后,图形显示子系统访问vram显存时指令可以重排序,中间缓存部件可以提取返回写确认,从而大大提高了cpu访问vram显存的速度。
3)3d加速优化设计
在组织构成上,3d图形显示的主要功能是由opengl核心库和opengl实用库来完成。图形处理性能优化重点是获得更加完善的api接口支持、更多的标准和技术支持;优化显示处理框架和显示架构,提高3d图形硬件加速性能,采用延迟io技术,减少显存操作;其次是优化opengl图形库,与操作系统厂商进行更加深入的合作,对opengl的整个工作流程(包括数据分类、光栅化、片元操作、送入帧缓冲区等)进行适配优化,提升图形着色、渲染的性能。最终,完成图形处理性能的提升。
支持opengl规范有利于跨平台开发和移植,最大限度保护用户的软件投入。因此,自主显卡需要提供opengl的驱动程序支持,当前支持的opengl版本为2.0。根据opengl的工作流程原理,驱动程序的主要处理流程为:创建显示窗口、开辟显示帧存空间、发送状态配置命令、配置硬件寄存器参数、发送顶点数据到顶点buffer、发送绘图命令、硬件开始进行绘制、等待空闲状态、开始下一帧绘制。
为了实现对国产平台环境的支持,采用分层抽象设计的方式,从应用层到操作系统及bsp层之间分别是:用户api层,opengl功能实现层,硬件访问层,操作系统接口层。
4)3d引擎设计
基于动态多缓冲的国产平台显示优化技术采用动态内存模式,结合3d引擎的前后缓冲切换技术,通过在3d引擎中定义一组缓冲池的方式,建立缓冲区池模块和可动态伸缩的缓冲区机制,每一个渲染客户端可以拥有一个或多个缓冲区,根据实际情况为渲染输出提供灵活的缓冲决策,x服务器端不直接参与空闲缓冲区的释放,实现渲染的实时缓冲内存需求和引擎对缓冲区数量的灵活控制,当前应用客户端需要缓冲区进行渲染时就会在该缓冲区池中获取一个新的对象缓存直接使用,使用完后再释放回缓冲区池中,当应用客户端的渲染上下文结束或销毁后,缓冲池中的每一个缓存将被释放。同时由于在整个渲染上下文中保存了旧缓冲区,在很多情况下可以重复利用这些缓冲内容进行增量渲染,减小了渲染的开销。另外提供了灵活的缓冲区池缓存数量的配置接口,用户可以根据实际需求灵活配置缓存数量,充分提升渲染能力。动态多缓冲技术能提高应用程序对缓冲区使用的命中率,进而提升与x服务端同步对象的吞吐量,从而达到加快图形渲染速度的目的。
3d引擎动态多缓冲技术针对和xserver交互的复杂3d应用有比较明显的效果提升,在这种渲染上下文中,应用程序渲染时需要的缓冲区数量多而且对图像渲染得实时性要求比较高,在缓冲区池存在的情况下,可以更有效的减少和xserver交互等待缓冲的时间。预估基于此技术整体渲染能力提升至少20%。
- 还没有人留言评论。精彩留言会获得点赞!