数据处理方法、装置、设备及介质与流程
本发明涉及计算机
技术领域:
,尤其涉及一种数据处理方法、数据处理装置、电子设备及计算机可读存储介质。
背景技术:
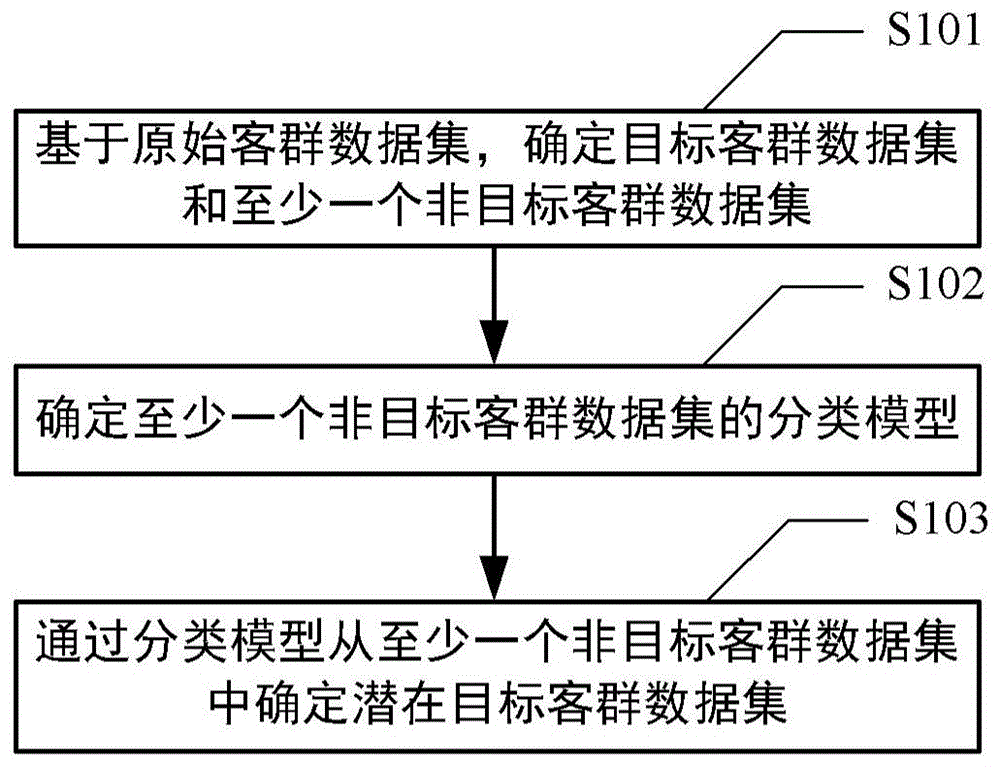
:为配合不同客户的个性化需求,在现有技术的营销过程中,已产生了可以进行客户细分的营销策略,例如借助大数据和机器学习技术,对客户进行聚类以分成不同类型的客户群体(即客群)进行智能营销。随着对客群细分需求的深耕,不仅需要获知聚类-细分后的目标客群,还需要将目标客群最大化,以实现营销效果最大化。现有技术中的智能营销技术只是基于数据现状的客群划分以获取目标客群。由于客户购买行为具有变动迁移性,在进行聚类的时间节点,一些客户没有被划分到目标客群。但是,这些客户之前的购买行为与可以动态迁移到目标客群的客户的购买行为类似,因此这些客户也可以被认为是与目标客群有相似营销特征的潜在目标客群。可见,现有技术中客群购买行为等动态迁移变动产生的潜在目标客群尚不能通过现有的智能营销技术手段作进一步地划分,造成无法更好地实现精细化营销。技术实现要素:(一)要解决的技术问题为解决现有技术中客群购买行为等动态迁移变动产生的潜在目标客群尚不能通过现有的智能营销技术手段作进一步地划分,造成无法更好地实现精细化营销的技术问题,本发明公开了一种数据处理方法、数据处理装置、电子设备及计算机可读存储介质。(二)技术方案本发明的一个方面公开了一种数据处理方法,其中,包括:基于原始客群数据集,确定目标客群数据集和至少一个非目标客群数据集;确定至少一个非目标客群数据集的分类模型;以及通过分类模型从至少一个非目标客群数据集中确定潜在目标客群数据集;其中,目标客群数据集和潜在目标客群数据集用于实现精细化营销。根据本发明的实施例,在基于原始客群数据集,确定目标客群数据集和至少一个非目标客群数据集之前,方法还包括:在第一时间窗口,基于原始客群数据集,建立聚类模型;通过聚类模型对原始客群数据集进行聚类预测处理,获取第一聚类结果;以及在第二时间窗口,通过聚类模型对原始客群数据集进行聚类预测处理,获取第二聚类结果;其中,第二时间窗口与第一时间窗口为具有相同时间间隔的时间段。根据本发明的实施例,在第一时间窗口,基于原始客群数据集,建立聚类模型,包括:基于原始客群数据集中的第一类型数据,建立聚类模型;通过聚类模型对原始客群数据集进行聚类预测处理,获取第一聚类结果,包括:通过聚类模型对第一类型数据进行聚类预测处理,获取第一聚类结果。根据本发明的实施例,在第二时间窗口,通过聚类模型对原始客群数据集进行聚类预测处理,获取第二聚类结果,包括:对原始客群数据集中的第二类型数据进行聚类预测处理,获取第二聚类结果。根据本发明的实施例,第一聚类结果包括至少两个第一类型数据簇,至少两个第一类型数据簇中每个第一类型数据簇为与原始客群数据集中的一个第一客户群对应的数据集;第二聚类结果包括至少两个第二类型数据簇,至少两个第二类型数据簇中每个第二类型数据簇为与原始客群数据集中的一个第二客户群对应的数据集。根据本发明的实施例,基于原始客群数据集,确定目标客群数据集和至少一个非目标客群数据集,包括:根据预设营销客群特征,从至少两个第二类型数据簇中确定一个第二类型数据簇作为目标客群数据集和非一个第二类型数据簇作为非目标客群数据集。根据本发明的实施例,确定至少一个非目标客群数据集的分类模型,包括:根据至少两个第一类型数据簇与至少两个第二类型数据簇之间的随时间变化的数据迁移流向,确定正样本数据集和负样本数据集;在第三时间窗口中,通过对正样本数据集和负样本数据集进行加工,获取第三类型数据;通过对第三类型数据进行分类样本训练,获取至少一个非目标客群数据集的分类模型。根据本发明的实施例,通过分类模型从至少一个非目标客群数据集中确定潜在目标客群数据集,包括:根据至少一个非目标客群数据集确定第四类型数据;通过分类模型对第四类型数据进行分类预测处理,获得具有特定阈值的潜在目标客群数据集。本发明的另一方面公开了一种数据处理装置,其中,包括:目标确定模块、分类建立模块和潜在目标确定模块。目标确定模块用于基于原始客群数据集,确定目标客群数据集和至少一个非目标客群数据集;分类建立模块用于确定至少一个非目标客群数据集的分类模型;以及潜在目标确定模块用于通过分类模型从至少一个非目标客群数据集中确定潜在目标客群数据集;其中,目标客群数据集和潜在目标客群数据集用于实现精细化营销。本发明的另一方面公开了一种电子设备,其中,包括:一个或多个处理器和存储装置;存储装置用于存储一个或多个程序,其中,当一个或多个程序被一个或多个处理器执行时,使得一个或多个处理器实现上述的方法。本发明的另一方面公开了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器实现上述的方法。(三)有益效果本发明公开了一种数据处理方法、数据处理装置、电子设备及计算机可读存储介质。其中,所述数据处理方法包括:基于原始客群数据集,确定目标客群数据集和至少一个非目标客群数据集;确定至少一个非目标客群数据集的分类模型;以及通过分类模型从至少一个非目标客群数据集中确定潜在目标客群数据集;其中,目标客群数据集和潜在目标客群数据集用于实现精细化营销。通过本发明的数据处理方法,相对现有技术中的智能营销技术手段实现了进一步的优化,具体实现了动态迁移变动产生的潜在目标客群的划分,提升目标客群的数量,更好地优化了营销效果,进一步提高了营销效率。附图说明图1示意性示出了根据本发明实施例的数据处理方法的流程图;图2示意性示出了根据本发明实施例的第一时间窗口和第二时间窗口的对比图;图3示意性示出了根据本发明实施例的对应第一时间窗口和第二时间窗口的动态迁移流向图;图4示意性示出了根据本发明实施例的第三时间窗口和第四时间窗口的对比图;图5示意性示出了根据本发明实施例的数据处理装置的架构图;图6示意性示出了根据本发明实施例的适于实现上述数据处理方法的电子设备的方框图。具体实施方式为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。以下,将参照附图来描述本发明的实施例。但是应该理解,这些描述只是示例性的,而并非要限制本发明的范围。在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本发明实施例的全面理解。然而,明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本发明。在此使用的术语“包括”、“包含”等表明了所述特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。在使用类似于“a、b和c等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有a、b和c中至少一个的系统”应包括但不限于单独具有a、单独具有b、单独具有c、具有a和b、具有a和c、具有b和c、和/或具有a、b、c的系统等)。在使用类似于“a、b或c等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有a、b或c中至少一个的系统”应包括但不限于单独具有a、单独具有b、单独具有c、具有a和b、具有a和c、具有b和c、和/或具有a、b、c的系统等)。在智能营销技术手段中,主要基于支付流水来计算对应某时间段(即时间窗口)内客户群体中每个客户的消费特征数据,然后通过传统的聚类算法,将具有不同消费特征数据的客户细分到不同的类簇内,由类簇中心点的特征数据代表细分到某个类簇的客群的消费特征,然后根据预定的营销目标选定某个细分的客群。例如,如某销售方希望通过促销活动来提升其客群的价值(此处的价值可理解为相对于销售方而言的客户价值,例如某客户对该销售方进行的消费次数多、消费金额高,则可将该客户定义为高价值客户,相应的,根据消费次数、消费金额的比较可定义中价值、低价值客户),但是由于客户众多,其中一些客户本身就是高价值客户(通常而言,并没有必要对高价值客户进行营销),一些价值较低的客户无法获取营销效果(因为这些客户大概率只是偶尔消费,并不对销售方有很多关注),而处于价值区间中段的客户则有很大的价值提升潜力,所以就需要从众多客户中识别出中价值客户和有可能动态迁移到中价值的客户进行细分营销。变动迁移性是指客户自身价值观、对购买商品的功能性需求等因素会随着时间变化产生变动。例如,属于非目标客群的某客户之前喜爱购买一些性价比较高的生活必需品。随着时间变化,该客户的薪资和生活品质的提升,会更偏向于购买一些品牌型、奢侈型商品。因此该客户的购买行为则随着时间变化产生了消费提升的情况,此时该客户则可能具有目标客群的消费特征。另外,一些客户消费降低产生价值迁移的识别也是现代细分营销中的一个关键点。然而现有技术中的智能营销技术手段,通过传统的聚类算法,无法将因变动迁移性产生的潜在目标客户进行有效区分,因而无法更好地实现精细化智能营销。为解决现有技术中客群购买行为等动态迁移变动产生的潜在目标客群尚不能通过现有的智能营销技术手段作进一步地划分,造成无法更好地实现精细化营销的技术问题,本发明公开了一种数据处理方法、数据处理装置、电子设备及计算机可读存储介质。如图1所示,本发明的一个方面公开了一种数据处理方法,其中,包括步骤s101-s103。步骤s101:基于原始客群数据集,确定目标客群数据集和至少一个非目标客群数据集;步骤s102:确定至少一个非目标客群数据集的分类模型;以及步骤s103:通过分类模型从至少一个非目标客群数据集中确定潜在目标客群数据集;其中,目标客群数据集和潜在目标客群数据集用于实现精细化营销。根据本发明的实施例,原始客群数据集为具有所有客户的所有属性的数据集合,各个客户之间的id代码或名称具有一定差异,每个客户都对应有包括年龄、性别、消费时间、消费频次以及消费金额等消费特征属性,对应每一种消费特征属性均具有相应的具体数值或代码作为原始数据。通过对原始客群数据集,首先获得用于精细化营销的目标客群数据集,例如可以通过聚类算法,对原始客群数据集进行聚类预测,来获得相应地目标客群数据集。其中,该目标客群数据集对应的可以是中价值客户群体的数据集合,以利于对其直接进行精细化营销。在获得目标客群数据集的同时,可以获得非目标客群数据集,其中,该非目标客群数据集可以是高价值客户群体的数据集合。为进一步实现精细化智能营销,本发明需要对高价值客户群体的数据集合作进一步的数据挖掘或提取,以在高价值客户群体中获得与中价值客户群体购买行为具有相似营销特征的潜在客户群体,以针对该潜在客户群体作营销,实现更进一步地精细化营销。举例而言,在销售方实施客群营销的过程中,可以对客户价值进行再次衡量,其衡量指标例如是r(消费时间)、f(消费频次)、m(消费金额)等消费特征属性的数据(一般可以通过一个时间段内的流水数据进行计算获取)。具体地,可以选择一个时间窗口,计算每个客户基于该时间窗口流水数据的r、f、m特征数据,然后通过聚类算法,判断出每个客户所属的类簇,每个类簇就代表一个细分客群数据集(如目标客群数据集和至少一个非目标客群数据集),类簇中心点的r、f、m特征数据就是该类簇客群的价值特征。因此,可以选定具有中价值特征的类簇群体作为目标客群数据集,选定具有高价值特征的类簇群体作为非目标客群数据集。其中,在上述的聚类营销过程,每个客户的消费特征数据是基于时间窗口内的流水数据计算得来的,时间窗口选择的不同,计算出来的特征数据就不相同,后续聚类算法结果中,某个客户对应不同时间窗口而分属的类簇就有可能不同。分类模型的建立需要基于分类算法的分类预测学习规则实现。其中,通过该分类模型可以实现:分类算法所选择的特征数据可基于其他的消费特征数据比如交易订单数周期变化,交易金额周期变化等对至少一个非目标客群数据集中的每个客户进行分类判断,来获得潜在目标客户。该潜在目标客户是与目标客群中的目标客户具有类似、相近或相同消费行为的客户。本领域技术人员应当理解,根据本发明的实施例,对于选定中价值特征的类簇群体作为目标客群,高价值和低价值特征的类簇群体都可作为非目标客群的备选客群。因此,非目标客群数据集的数量一般可以具有至少一个,而对应中价值客群的目标客群数据集的数量一般为一个。此外,需要说明的是,根据本发明的实施例,聚类预测的过程是一个无监督的算法过程,原始客群数据集为没有预先标记的样本数据集合,所选择聚类的特征数据通常与要进行聚类判断的结果是对应的。例如,若要进行某客户为高价值或低价值的细分,聚类特征数据就是代表客户价值的r、f、m特征数据;而非目标客群数据集中与目标客户相似的客群判断则是一个有监督的算法过程,需要事先标记出目标客群和非目标客群。通过本发明的数据处理方法,可以通过聚类算法对原始客群数据进行聚类预测,获得符合营销目标的目标客群数据集和至少一个非目标客群数据集,然后基于分类算法从至少一个非目标客群数据集中获得与目标客群数据集中的营销目标相符合的潜在目标客群,并对目标客群和潜在目标客群同时实现智能营销。因此,本发明相对现有技术中的智能营销技术手段实现了进一步的优化,具体实现了动态迁移变动产生的潜在目标客群的划分,提升目标客群的数量,更好地优化了营销效果,进一步提高了营销效率。换言之,将现有技术中直接以聚类细分结果确定目标客群的方法转换为聚类和分类两步结合的方法,实现了在客户聚类细分的基础上,进一步实现深层的潜在客户的预测。具体地,本发明首先通过聚类方法在不同的时间窗口内将原始客群数据集划分为几个不同消费特征的客群数据集,然后根据不同时间窗口的前后聚类结果中客户群体的迁移进行样本标记,结合特定时间窗口的客户行为特征,建立分类模型,发掘出非目标客群中有较大概率转化为目标客群的潜在目标客群,最后通过对目标客群和潜在目标客群作为营销对象,以进一步实现营销效果最大化,即精细化智能营销。根据本发明的实施例,在步骤s101之前,本发明的数据处理方法还包括:在第一时间窗口,基于原始客群数据集,建立聚类模型;通过聚类模型对原始客群数据集进行聚类预测处理,获取第一聚类结果。根据本发明的实施例,在第一时间窗口,基于原始客群数据集,建立聚类模型,包括:基于原始客群数据集中的第一类型数据,建立聚类模型;通过聚类模型对原始客群数据集进行聚类预测处理,获取第一聚类结果,包括:通过聚类模型对第一类型数据进行聚类预测处理,获取第一聚类结果。根据本发明的实施例,第一聚类结果包括至少两个第一类型数据簇,至少两个第一类型数据簇中每个第一类型数据簇为与原始客群数据集中的一个第一客户群对应的数据集。时间窗口是指某一时间范围(即为时间段),用于加工算法模型所需要的特征数据,即原始客群数据集中的原始数据。因为机器学习所使用的原始数据一般是基于流水数据加工而来,由于客户在不同的时间点都会有数据产生,而模型所用到的特征数据一般是对应的某个时间段内的客户数据的汇总,例如加工某客户在2019年上半年的总消费金额数据,则需要计算20190101-20190630这一时间段中,该客户消费流水的金额总和,则该时间窗口即20190101-20190630这一时间段。如图2所示,根据本发明的实施例,若要查看某客群在2019年全年的价值迁移情况,如2019年上半年至下半年的价值迁移,则对应于时间轴t,基于2019年上半年作为第一时间窗口t1,邻近的2019年下半年作为第二时间窗口t2,需要分别对应上述两个时间窗口的原始客群数据的聚类特征数据。如图2所示,第一时间窗口t1可理解为20190101-20190630的时间段,第二时间窗口t2可理解为20190701-20191231的时间段。本领域技术人员应当理解,该第一时间窗口t1与第二时间窗口t2在时间轴t上也可以不相邻近,本发明在此不作限制。在本发明的实施例中,原始客群数据集为对应某时间窗口中针对所有客户的所有属性的数据集合。其中,该原始客群数据集中包括多个不同属性的特征数据,每种特征数据可以对应多个不同的类型数据,该类型数据可以根据设定时间窗口加工。对应于如图2所示的第一时间窗口t1(例如是本发明实施例中20190101-20190630的时间段),处于该第一时间窗口t1中的原始客群数据集包括特征数据feature1,其中通过对应该特征数据feature1的类型数据data1,即可以建立一对应原始客群数据集的聚类模型fmodel。其中,该特征数据feature1为依据不同的营销目标选定的业务特征数据,该类型数据data1可以理解为聚类算法所要作用的数据集合,该类型数据data1即上述的第一类型数据。需要说明的是,关于类型数据data1,在计算机学习
技术领域:
中,算法的输入数据为一个数据集,可理解为数据库中的一张表,表的第一个字段可认为是一个索引字段,用于标识不同的样本点,表中其他字段数据可认为是样本点对应的指标值。例如,上述的r、f、m特征数据的集合即为特征数据feature1,其中每个客户在对应第一时间窗口t1内的r、f、m特征数据为类型数据data1,即进行聚类算法训练的原始r、f、m字段数据。类型数据data1可以是下表1所示的包含上百万客户的的数据集合,该数据集合可以通过数据库中的流水数据汇总生成。客户idrfma120190320130.5b120190501310.0c120190530251.0表1将数据库中汇总的类型数据data1导入聚类模型,通过聚类算法依据业务需求或根据数据分布情况将该第一类型数据data1划分为至少两个簇,以获得较好的聚类效果。所得到聚类结果中(即第一聚类结果),具有对应每个数据点所归属的簇,以及每个簇的中心点,中心点即代表当前所在簇中所包含客群的特征。其中,本领域技术人员应当理解,在本发明的实施例中,特征是通用名称,可以理解为一种指标名称。进一步地,聚类模型fmodel是基于无监督学习算法所获得,用于反映聚类中心点的数据(可以下述如表2所示),以划分输入数据到不同的类簇,其实现过程是根据设定的聚类数不断更新聚类中心点,使得每个输入数据点能划分到距离其最近的中心点所包含的类簇中。通过该聚类模型fmodel对原始客群数据集进行聚类预测处理。其中,涉及的聚类算法是一种开源算法,只需要提供算法需要作用的数据、以及算法的聚类簇数目参数,就可以据此类算法计算出每个样本数据所对应的聚类簇索引,以及每个聚类簇的中心点的位置。其中,聚类算法包括k-means聚类、em聚类以及层次聚类等。具体地,下面将以k-means聚类算法为例,对本发明的聚类预测过程的原理框架作进一步地说明,如下:首先,确定大小为n的数据集,当iter=1时,获取k个初始聚类中心zj(iter),j=1,2,3,...,k,iter代表不同迭代轮数。其中,k为3,n为原始客群数据集中所涵盖的总样本客户数,如n=14773119。之后,确定每个样本数据与聚合中心的距离d(xi,zj(iter)),i=1,2,3,...,n,并将样本分到簇中心点距离其最近的簇内。然后,在确定iter=iter+1时,由当前簇所包含的样本点计算中心点,该中心点用于作为新的聚类中心。其中,设定目标函数值j(iter)为和误差平方和:最后,当|j(iter+1)-j(iter)|<theta(目标函数收敛)或者样本点无类别变化时,则完成聚类预测;否则,iter=iter+1,继续重复实现上述“确定每个样本数据与聚合中心的距离d(xi,zj(iter)),i=1,2,3,...,n,并将样本分到簇中心点距离其最近的簇内”及之后的步骤,直至完成聚类预测。根据聚类预测处理,可以获得具有至少一个不同特征的客群数据集,即第一聚类结果。其中,每个客群数据集都为该聚类预测出的类簇(简称簇),该第一聚类结果包括至少两个簇,每个簇对应一个客群。在本发明的实施例中,该第一聚类结果可以具有3个簇,如簇a(对应于客群a1)、簇b(对应于客群b1)和簇c(对应于客群c1),其中的簇a、簇b或簇c也即本发明实施例中的第一类型数据簇。如下表2所示,即可以表示为本发明的第一聚类结果的具体实例。簇聚类中心(r,f,m)簇样本数a0.154449,0.004816,0.000369a1:7327021b0.505266,0.001952,0.000148b1:3968862c0.827605,0.001319,0.000097c1:3477236表2综上,在本发明实施例中,为实现对客户价值的聚类细分,如需将原始客群数据集细分为对应多个不同客群的数据子集,聚类算法会根据簇内每个数据点的r、f、m数据,不断更新三个聚类中心点的数值,直至每个数据点被分到的类簇不再变动,来获得聚类结果。聚类结果会返回每个数据点对应的簇索引,即其属于哪个类簇,以及对应每个类簇的中心点r、f、m的数据值。根据本发明的实施例,在步骤s101之前,本发明的数据处理方法还包括:在第二时间窗口,通过聚类模型对原始客群数据集进行聚类预测处理,获取第二聚类结果;其中,第二时间窗口与第一时间窗口为具有相同时间间隔的时间段。根据本发明的实施例,在第二时间窗口,通过聚类模型对原始客群数据集进行聚类预测处理,获取第二聚类结果,包括:对原始客群数据集中的第二类型数据进行聚类预测处理,获取第二聚类结果。根据本发明的实施例,第二聚类结果包括至少两个第二类型数据簇,至少两个第二类型数据簇中每个第二类型数据簇为与原始客群数据集中的一个第二客户群对应的数据集。与上述关于第一聚类结果的获取类似,本发明的第二聚类结果的获取可以通过下述实施方式进行获取,具体如下:在第二时间窗口t2内,通过聚类模型fmodel对原始客群数据集中的特征数据feature1的类型数据data2进行聚类预测,来获得第二聚类结果。该第二聚类结果为通过聚类算法将类型数据data2划分所获得的至少两个簇,其中,第一聚类结果所包括的簇数量与第二聚类结果所包括的簇数量一致,该簇数量等于聚类模型训练时设定的聚类数k。其中,每个簇为具有至少一个特定特征的客群数据集。在本发明的实施例中,该第二聚类结果同样可以具有3个簇,如簇a(对应客群a2)、簇b(对应客群b2)和簇c(对应客群c2),其中簇a、簇b或簇c即本发明实施例中第二类型数据簇。可见,以对于第二类型数据簇的簇a为例,其对应的客群为a2,即上述的第二客户群;与上述第一类型数据簇的簇a对应的客群a1(即上述的第一客户群)有所区分,这是本领域技术人员应当知晓的内容,本发明不再赘述。如下表3所示为本发明的第二聚类结果的具体实例,其根据表2中聚类中心(即聚类中心(r,f,m)列)的数据,经计算获得每个客户在t2的r、f、m数据到每个中心点的距离,取距离最小的中心点为客户对应的类簇中心点,即该客户属于该簇。簇簇样本数aa2:12009573bb2:937120cc2:1826426表3在本发明的实施例中,该特征数据feature1对应原始客群数据集中在第二时间窗口t2的r、f、m数据集合,将该特征数据feature1依据聚类模型fmodel进行聚类预测,即可以获取上述的第二聚类结果。其中,对应第一时间窗口t1的原始客群数据集与对应第二时间窗口t2的原始客群数据集都对应相同的多个客户。此外,为确保后期能够通过对应第一时间窗口t1所获得的聚类模型fmodel来对对应第二时间窗口t2的原始客群数据集进行处理,保证每个特征指标的数据是基于相同时间段计算,保持数据的一致可比性,第二时间窗口t2与第一时间窗口t1为具有相同时间间隔的时间段。需要说明的是,上述的类型数据data2即本发明实施例中的第二类型数据。具体地,类型数据data2对应第二时间窗口t2获取的特征数据,用来根据第一时间窗口t1的第一类型数据data1数据集合训练出来的聚类模型fmodel(即每个簇的中心点),计算原始客群数据集中每个客户在第二时间窗口t2时间段所归属的类簇。类型数据data2一方面作用于获取通过聚类预测产生的第二聚类结果以期进一步获得目标客群数据集,另一方面是作用于对第二聚类结果中的各簇进行样本标记,以为下述的分类预测作准备。其中,第一时间窗口t1和第二时间窗口t2两个时间段的作用就是要标记出某客户在前后两个时间周期内所属的不同类簇,以反应该客户在第二时间窗口t2内相对第一时间窗口t1的迁移流向。根据本发明的实施例,确定至少一个非目标客群数据集的分类模型,包括:根据至少两个第一类型数据簇与至少两个第二类型数据簇之间的随时间变化的数据迁移流向,确定正样本数据集和负样本数据集。在本发明的实施例中,聚类算法可以根据前后两个时间窗口(即第一时间窗口t1和第二时间窗口t2)内的聚类结果中标记出流向目标簇的样本作为样本数据。其中,第二时间窗口t2的第二类型数据data2进行聚类所应用的聚类模型fmodel,与第一时间窗口t1的第一类型数据data1所建立的聚类模型fmodel一致,以保证在迁移流向过程中每个簇的中心特征点在第一时间窗口t1、第二时间窗口t2内是固定不变的,确保客群迁移具有可比性,以期获得标记样本用于后期分类。分类标记的前提是依据业务目标确定目标客群,若目标客群是中价值客群,则对应第一时间窗口t1的第一聚类结果中为高价值或低价值的客户,若在第二时间窗口t2的第二聚类结果中变成中价值,则将该客户标记为正样本,具体可以在分类数据中将该客户的标记值确定为1;若该客户变成高价值或低价值,则将该客户标记为负样本,具体可以在分类数据中将该客户的标记值确定为0。其中,该被标记的客户是非第一时间窗口t1内的具有目标客群特征的簇对应的客户。多个正样本的集合即正样本数据集,多个负样本的集合即负样本数据集。如图3所示,对应于第一时间窗口t1的第一聚类结果包括至少两个第一类型数据簇,对应第二时间窗口t2的第二聚类结果包括至少两个第二类型数据簇。其中,基于前述实施例,该第一聚类结果可以具有3个簇,如簇a(对应客群a1)、簇b(对应客群b1)和簇c(对应客群c1),其中簇a、簇b或簇c即本发明实施例中第一类型数据簇。同理,该第二聚类结果同样可以具有3个簇,如簇a(对应客群a2)、簇b(对应客群b2)和簇c(对应客群c2),其中簇a、簇b或簇c即本发明实施例中第二类型数据簇。如图3所示,实心圆点代表属于某个簇的数据点,空心圆点为簇的中心点。其中,在第一时间窗口t1中获取的第一聚类结果中的簇a,其对应实心圆点1的客户,流向到在第二时间窗口t2中获取的第二聚类结果中的簇b,即实心圆点1′。在第一时间窗口t1中获取的第一聚类结果中的簇b,其对应3个实心圆点2的客户,可以分别流向到在第二时间窗口t2中获取的第二聚类结果中的簇a和簇c,即3个实心圆点2′。同理,在第一时间窗口t1中获取的第一聚类结果中的簇c,其对应2个实心圆点3的客户,可以分别流向到在第二时间窗口t2中获取的第二聚类结果中的簇a和簇b,即2个实心圆点3′。其中,若第二时间窗口t2的簇b对应的簇为目标客群,则图3中第二时间窗口t2内簇b对应数据点(即圆点)代表的客户皆为目标客户。因此,在下文所述的本发明实施例的分类过程中,第二时间窗口t2内簇a、簇c的所有数据点所代表的客户为潜在目标客群的原始客群。本发明的技术方案的目的之一即要通过分类算法从该原始客群中挖掘出潜在目标客群。为此,在进行分类训练之前,对上述的原始客群数据中的每个客户,需要通过上述的迁移流向进行训练样本标记,将从对应第一时间窗口t1的其他客群中流向对应第二时间窗口t2的目标客群(如簇b)的客户,标记为1,即正样本;相反,从对应第一时间窗口t1的其他客群中流向对应第二时间窗口t2的非目标客群(如簇a和簇c)的客户,标记为0,即负样本。多个正样本的集合即正样本数据集,多个负样本的集合即负样本数据集。根据本发明的实施例,基于原始客群数据集,确定目标客群数据集和至少一个非目标客群数据集,包括:根据预设营销客群特征,从至少两个第二类型数据簇中确定一个第二类型数据簇作为目标客群数据集,并将至少两个第二类型数据簇中的非一个第二类型数据簇作为非目标客群数据集。预设营销客群特征是与目标客群数据集相关的确定标准,目标客群与销售方营销业务的目标设定相关。例如,在本发明实施例的智能营销的应用场景,若希望对目标客群以及具有价值提升潜力的潜在客群进行定向营销,则首先需要判断聚类结果中哪个簇的中心点特征是符合目标客群特征的,同时考虑聚类结果中聚类中心点是根据聚类算法逐步迭代更新计算得到,聚类结果中每个簇的客群特征是通过比较不同簇中心点的数值大小进行定义。基于销售方营销业务目标确定聚类算法要选择的特征,以及相应聚类参数,然后根据聚类结果确定目标客群。针对原始客群数据集在第二时间窗口t2内的第二类型数据data2被聚类划分所获得的第二聚类结果,以簇中心点的特征数值符合营销业务目标客群的特征为判断标准,确定第二聚类结果中的某簇为目标客群数据集。具体地,针对第二聚类结果,其中簇a、簇b或簇c分别对应客群a2、b2和c2。其中,若簇b符合上述的营销业务目标客群的特征(即预没营销客群特征),则将对应客群b2的该簇b确定为目标客群数据集,客群b2为目标客群,其他的簇a和簇c则为非目标客群数据集,对应客群a2和c2则为非目标客群。其中,目标客群是根据聚类簇的中心点确定的,哪个簇的中心点特征数据符合业务定义的目标客群,则归属于该簇的客户即是目标客户,其他客户则为非目标客户。需要说明的是,在本发明的实施例中,除了目标客群之外,主要的营销对象还可以是非目标客群中的至少部分客户。例如,对于一聚类结果,如表2所示第一聚类结果的聚类中心点数据,可认为三个簇对应客群的价值排序为:簇a(高价值)>簇b(中价值)>簇c(低价值),则表3中簇b对应的客群b2为目标客群时,簇a对应的客群a2中至少部分客户即可以为本发明实施例中营销活动的潜在目标客群。其中,该簇a对应的客群a2为具有高价值客户的集合,为了维持该部分客群的价值,防止其中部分客户粘性降低则需要挖掘出其中哪些客户的消费行为会使其迁移到中价值客群,具体可以利用分类模型预测结果查找区分,对其实施营销,以进一步提升营销的精细化。需要进一步说明的是,在本发明的实施例中,簇a、簇b或簇c均可理解为聚类模型中某个簇的名称,例如,a1为第一时间窗口t1时间段内属于簇a的客群,a2为第二时间窗口t2时间段内属于簇a的客群。根据本发明的实施例,在第三时间窗口中,通过对正样本数据集和负样本数据集进行加工,获取第三类型数据;通过对第三类型数据进行分类样本训练,获取至少一个非目标客群数据集的分类模型。在确定目标客群数据集和至少一个非目标客群数据集之后,通过建立分类模型,利用分类模型从至少一个非目标客群数据集挖掘出潜在目标客群数据集。其中,如上述实施例所示,在第一时间窗口t1到第二时间窗口t2的迁移流向过程中,可以将对应第一时间窗口t1的客群a1、客群c1中流向对应第二时间窗口t2的客群b2的每个客户标记为正样本,以构成正样本数据集;而将其他流向的客户标记为负样本,以构成负样本数据集。在第三时间窗口t3内,基于上述正、负样本数据集生成特征数据feature2的第三类型数据data3,对该第三类型数据data3进行分类样本训练,以建立分类模型cmodel。考虑对应客群a1的簇a中的高价值客群会向簇b中价值客群迁移,选定a1客群为分类模型训练样本集,将流向b2的客户样本标记为1,将其他流向的客户样本标记为0。之后,在第三时间窗口t3内加工分类模型特征字段feature2以生成第三类型数据data3,利用第三类型数据data3进行分类模型训练,获取分类模型cmodel。利用上述的分类模型,本发明可以实现从目标客群之外的其他客群(即非目标客群)中挖掘一个客群,作为潜在目标客群。其中,第三类型数据data3作用于训练分类模型,以利于后期在第四时间窗口中挖掘出非目标客群数据集中的潜在目标客群。此外,区别于作为聚类模型的特征字段的特征数据feature1,特征数据feature2是分类模型的特征字段,具体可以从营销业务角度出发选取的算法训练字段。如图4所示,为确保前后数据处理过程的客群结果对应,若要预测客户特征与目标客群特征相似,则需要确定一个时间段用于加工分类模型特征数据feature2的第三类型数据data3。第三时间窗口t3是指对应第一时间窗口t1的时间段,以用于在该时间段内实现通过流水数据加工分类模型训练数据。第三时间窗口t3可以为第一时间窗口t1相同的时间段。但是,第三时间窗口t3的时间段大小要小于等于第一时间窗口t1的时间段大小,即t3≤t1。在本发明的实施例中,分类模型的建模方法包括逻辑回归分类法、随机森林分类法等其中之一。其中,客群a1、客群c1为和/或的关系,可以基于不同的业务目标进行区分。比如销售方希望从簇a和簇c的客群中挖掘潜在目标客群,则选择a1和c1客群;如果销售方只希望从簇a或簇c中挖掘潜在目标客群,则只需选择a1或c1客群。其中,特征数据feature2的选定可以依据建模需要选定的业务特征通过正、负样本数据集获得,这属于本领域技术人员应当知晓的内容,此处不再赘述。根据本发明的实施例,通过分类模型从至少一个非目标客群数据集中确定潜在目标客群数据集,包括:根据至少一个非目标客群数据集确定第四类型数据;通过分类模型对第四类型数据进行分类预测处理,获得具有特定阈值的潜在目标客群数据集。具体地,如上述第二聚类结果的簇b(对应客群b2)作为该实施例的目标客群数据集时,在第四时间窗口t4内,依据分类模型cmodel,对属于非目标客群数据集的客群a2、客群c2的特征数据feature2的第四类型数据data4进行分类预测,获取潜在目标客群数据集。其中,潜在目标客群数据集每个潜在目标客户具有特定阈值p,该阈值p为一概率值,大小范围满足(0,1)。其中,该阈值p与预设阈值pth满足:p≥pth。即作为潜在目标客户的阈值p最小等于预设阈值pth。其中,预设阈值pth由销售方依据营销范围自主设定,通常根据二分类模型的评估指标确定概率阈值,例如可选的评估指标为精确率、召回率等,具体选择依据模型效果和业务背景确定。因此,本发明的分类预测结果对应的特定阈值实际上为对应某客户为正样本的概率,即某客户在第四时间窗口t4内的消费行为决定其在下一个时间段内会转为中价值的概率。若设定0.6的概率阈值,就可以从非目标客群数据集中挖掘出具有0.6以上概率并会流向中价值的客群作为潜在目标客群,对应的潜在目标客群数据可以为202134,即可从其他非目标客群中挖掘出1.68%(202134/12009573,12009573为非目标客群数据集中的客户数据)的客群作为潜在目标客群。在本发明的实施例中,第四时间窗口t4是对应第二时间窗口t2的时间段,以用于在该时间段内实现通过流水数据加工分类模型测试集特征数据。若确定第二聚类结果的簇a对应的a2客群为分类模型测试集,在第四时间窗口t4内可以加工分类模型测试集的特征字段feature2以确定第四类型数据data4。如图4所示,第四时间窗口t4可以为第二时间窗口t2相同的时间段。但是,第四时间窗口t4的时间段大小要小于等于第二时间窗口t2的时间段大小,即t4≤t2。进一步地,基于上述的分类模型cmodel作为分类预测手段,对第四类型数据data4进行分类预测。预测结果中的每个客户具有对应的二分类预测结果概率值,即阈值p,范围为(0,1)。其中,预测结果的概率值越大,表明该客户与正样本越相近,即越有可能是潜在目标客户。需要说明的是,客群a2、客群c2为和/或的关系,也即本发明的分类预测可以从客群a2中挖掘潜在目标客群,也可以从客群c2中挖掘潜在目标客群,或从两者之和的总客群中挖掘潜在目标客群。通过本发明数据处理方法,将聚类预测和分类预测进行结合,在考虑客群迁移变动的影响的前提下,实现了对通过聚类进行客群数据处理以进行细分营销的方法的进一步优化,可以进一步提升所要营销的目标客群的数量,进一步实现精细化智能营销,优化营销效果。需要指出的是,具体的营销活动和营销规则是本发明的数据处理方法的一种应用,并非是对本发明保护范围的限制,该数据处理方法还可以应用于电商技术等计算机数据处理技术相关领域中进行数据处理。此外,本发明的数据处理方法在应用于精细化营销活动后,可以使得销售方能够从原始流水数据中对应的所有客群中对有提升价值潜力的客群进行定向营销活动的开展,覆盖客群数量更多,实现提升客户粘度和贡献度的效果。因此,本发明实施例中,销售方实际上也可以称作营销施策方,此处不再赘述。如图5所示,本发明的另一方面公开了一种数据处理装置500,其中,包括:目标确定模块510、分类建立模块520和潜在目标确定模块530。目标确定模块510用于基于原始客群数据集,确定目标客群数据集和至少一个非目标客群数据集;分类建立模块520用于确定至少一个非目标客群数据集的分类模型;以及潜在目标确定模块530用于通过分类模型从至少一个非目标客群数据集中确定潜在目标客群数据集;其中,目标客群数据集和潜在目标客群数据集用于实现精细化营销。具体地,上述的数据处理装置500可以用于实现上述的数据处理方法,此处不再赘述。如图6所示,本发明的另一方面公开了一种电子设备,其中,包括:一个或多个处理器和存储装置;存储装置用于存储一个或多个程序,其中,当一个或多个程序被一个或多个处理器执行时,使得一个或多个处理器实现上述的方法。根据本发明实施例的电子设备600包括处理器601,其可以根据存储在只读存储器(rom)602中的程序或者从存储部分608加载到随机访问存储器(ram)603中的程序而执行各种适当的动作和处理。处理器601例如可以包括通用微处理器(例如cpu)、指令集处理器和/或相关芯片组和/或专用微处理器(例如,专用集成电路(asic)),等等。处理器601还可以包括用于缓存用途的板载存储器。处理器601可以包括用于执行根据本发明实施例的方法流程的不同动作的单一处理单元或者是多个处理单元。在ram603中,存储有设备600操作所需的各种程序和数据。处理器601、rom602以及ram603通过总线604彼此相连。处理器601通过执行rom602和/或ram603中的程序来执行根据本发明实施例的方法流程的各种操作。需要注意,所述程序也可以存储在除rom602和ram603以外的一个或多个存储器中。处理器601也可以通过执行存储在所述一个或多个存储器中的程序来执行根据本发明实施例的方法流程的各种操作。根据本发明的实施例,设备600还可以包括输入/输出(i/o)接口605,输入/输出(i/o)接口605也连接至总线604。设备600还可以包括连接至i/o接口605的以下部件中的一项或多项:包括键盘、鼠标等的输入部分606;包括诸如阴极射线管(crt)、液晶显示器(lcd)等以及扬声器等的输出部分607;包括硬盘等的存储部分608;以及包括诸如lan卡、调制解调器等的网络接口卡的通信部分609。通信部分609经由诸如因特网的网络执行通信处理。驱动器610也根据需要连接至i/o接口605。可拆卸介质611,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器610上,以便于从其上读出的计算机程序根据需要被安装入存储部分608。根据本发明的实施例,根据本发明实施例的方法流程可以被实现为计算机软件程序。例如,本发明的实施例包括一种计算机程序产品,其包括承载在计算机可读存储介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分609从网络上被下载和安装,和/或从可拆卸介质611被安装。在该计算机程序被处理器601执行时,执行本发明实施例的系统中限定的上述功能。根据本发明的实施例,上文描述的系统、设备、装置、模块、单元等可以通过计算机程序模块来实现。图6示出的电子设备仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。本发明的另一方面公开了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器实现上述的方法。本发明的计算机可读存储介质可以是上述实施例中描述的设备/装置/系统中所包含的;也可以是单独存在,而未装配入该设备/装置/系统中。上述计算机可读存储介质承载有一个或者多个程序,当上述一个或者多个程序被执行时,实现根据本发明实施例的方法。根据本发明的实施例,计算机可读存储介质可以是非易失性的计算机可读存储介质,例如可以包括但不限于:便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本发明中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。例如,根据本发明的实施例,计算机可读存储介质可以包括上文描述的rom602和/或ram603和/或rom602和ram603以外的一个或多个存储器。本发明实施例的另一方面提供了一种计算机程序,所述计算机程序包括计算机可执行指令,所述指令在被执行时用于实现如上所述的方法。附图中的流程图和框图,图示了按照本发明各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,上述模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图或流程图中的每个方框、以及框图或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。本领域技术人员可以理解,本发明的各个实施例和/或权利要求中记载的特征可以进行多种组合和/或结合,即使这样的组合或结合没有明确记载于本发明中。特别地,在不脱离本发明精神和教导的情况下,本发明的各个实施例和/或权利要求中记载的特征可以进行多种组合和/或结合。所有这些组合和/或结合均落入本发明的范围。以上对本发明的实施例进行了描述。但是,这些实施例仅仅是为了说明的目的,而并非为了限制本发明的范围。尽管在以上分别描述了各实施例,但是这并不意味着各个实施例中的措施不能有利地结合使用。本发明的范围由所附权利要求及其等同物限定。不脱离本发明的范围,本领域技术人员可以做出多种替代和修改,这些替代和修改都应落在本发明的范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1