基于多尺度自注意生成对抗网络的单幅图像去雾方法与流程
本发明属于图像处理技术领域,涉及一种基于多尺度自注意生成对抗网络的单幅图像去雾方法。
背景技术:
单幅图像去雾的目的是从有雾图像中恢复干净的图像,这对于后续的高级别任务(如对象识别和场景理解)是必不可少的。因此,图像去雾在计算机视觉领域得到了广泛的关注。根据物理模型,图像去雾过程可以用公式表示为
i(x)=j(x)t(x)+a(1-t(x))(1);
其中i(x)和j(x)分别表示有雾图像和清晰图像。a表示全局大气光,t(x)表示传输映射。传输映射可以表示为t(x)=e-βd(x),d(x)和β分别表示景深和大气散射系数。定义一张有雾图像i(x),大多数算法通过估计t(x)和a来恢复清晰图像j(x)。
然而,从有雾图像中估计传输映射和全局大气光通常是一个不适定的问题。早期基于先验的方法试图利用清晰图像的统计特性来估计传输映射,如暗通道先验和颜色线先验,这些图像先验很容易产生和真实图像不一致的情况,导致传输估计不准确,因此,恢复的图像质量通常不准确。
随着深度学习的兴起,透射图或大气光的估计由卷积神经网络来估计,而不是依赖先验。为了解决这一问题,研究人员采用卷积神经网络(cnn)直接估计传输映射、全局大气光或预测清晰图像,这种方法具有显著的性能改进。但是,无论是估计传输映射和全局大气光还是基于深度学习,都几乎取决于物理散射模型,大气光和透射图的估计精度对去雾图像的质量有很大的影响,从而影响了最终清晰图像的获取。
技术实现要素:
本发明的目的是提供一种基于多尺度自注意生成对抗网络的单幅图像去雾方法,解决了现有技术中存在的去雾图像质量差的问题。
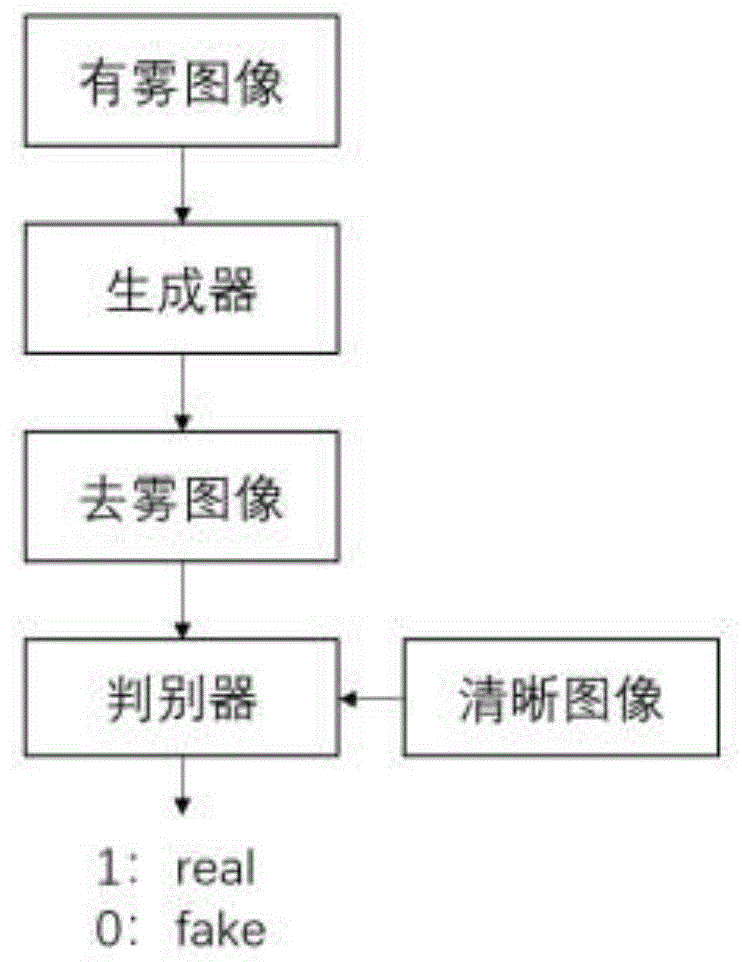
本发明所采用的技术方案是,基于多尺度自注意生成对抗网络的单幅图像去雾方法,包括以下步骤:
步骤1、获取图像数据集,对图像数据集中的每个有雾图像的像素值归一化为[-1,1],得到训练集;
步骤2、将输入的有雾图像进行两次下采样得到两个尺度的缩放图像,构建生成对抗网络模型,生成对抗网络模型由生成网络和判别网络组成;
步骤3、利用步骤1得到的训练集对步骤2构建的生成对抗网络模型进行训练,得到训练后的生成对抗网络模型,训练过程中对去雾结果采用损失函数进行优化;
步骤4、将有雾图像输入到步骤3训练后的生成对抗网络模型中,得到去雾图像。
本发明的特点还在于,
步骤2构建生成对抗网络模型的步骤为:将输入原始大小有雾图像的路径作为生成器的主干网络,下采样后两个尺度缩放图像的路径作为分支输入到主干网络中,每一个分支都采用自注意力机制;
对于生成器生成的去雾图像,和输入图像尺寸大小相同的输出作为最终的去雾结果,将得到的分支去雾结果作为监督学习的一部分,来约束生成器模型。
构建生成对抗网络模型步骤中:
自注意力机制首先对输入的特征映射x进行线性映射,然后得到特征θ,
通过调整特征映射的维度,合并上述的三个特征除通道数外的维度,然后对θ和
残差块主要包括卷积层和激活函数两个部分,输入特征首先经过卷积层得到特征映射,然后将得到的特征映射输入到激活函数中进行激活,将激活后的特征映射再次输入到卷积层中进行卷积,将卷积得到的特征映射与输入进行相加,并将相加的结果经过激活函数处理后输出最终的特征映射;
卷积残差块首先将输入的特征分为五个部分,每个部分根据卷积核的大小按不同的比例分配输入的特征映射,然后每个卷积层对分配的特征映射进行卷积得到对应卷积核的特征映射,最后将得到的5个部分的特征映射进行通道连接,得到与输入特征映射通道数相同的结果。
构建生成对抗网络模型具体操作为:
a.将训练集中的图像ix使用双线性插值进行下采样得到图像尺度为ix的
b.对于输入为
c.将特征映射o1输入到自注意力模块attention中,得到具有全局注意力的特征映射o2;
d.将自注意力特征o2经过一个残差块进行特征矫正;
e.对于输入为
f.对于主干分支,我们首先将输入的
g.将特征映射o7依次经过三个残差块来提取浅层特征;
h.使用卷积核大小为3,步长为2的卷积层对特征映射o10进行下采样得到特征映射o11;
i.将特征o11与输入为
j.使用卷积核大小为3,步长为2的卷积层将特征o12进行下采样,进一步扩大网络的感受野;
k.将特征o13与输入为
l.将特征o17使用卷积核为3,步长为2的反卷积层进行上采样得到特征映射o18;
m.将特征o18与跳跃链接o12进行通道连接,并用两个残差块进行整合;
n.将深层特征o19输入卷积核为3、步长为2的反卷积层进行上采样,输出特征o20;
o.通过跳过连接将特征o20与浅层特征o10进行通道连接得到组合特征,并将组合特征输入三个残差块进行整合,输出特征o21;
p.将特征o21使用卷积核为3,步长为1的卷积操作来恢复通道数,并使用tanh激活函数激活,得到最终的去雾图像rx;
q.将特征o19与特征o3进行通道连接,并使用一个残差块进行整合得到输出特征o22;
r.将特征o22使用卷积核为3,步长为1的卷积操作来恢复通道数,并使用tanh激活函数激活,得到最终的去雾图像
s.将特征o17与特征o6进行通道连接,并使用一个残差块进行整合得到输出特征o23;
t.将特征o23使用卷积核为3,步长为1的卷积操作来恢复通道数,并使用tanh激活函数激活,得到最终的去雾图像
残差块采用金字塔卷积残差块。
步骤3中的损失函数具体为:去雾结果
上式中,lossl1为l1损失,lossssim为结构相似性损失,lossvgg为感知损失。参数为λ1=10,λ2=0.00001,λ3=10。
结构相似性损失函数中,设x和y分别表示观察到的图像和输出图像,r(x)表示输入x的去雾结果,因此,r(x)和y之间的ssim如下所示:
ssim=[l(r(x),y)]α·[c(r(x),y)]β·s(r(x),y)γ;其中,l、c和分别表示亮度、对比度和结构,α,β和γ是系数,ssim损失可以定义为:lossssim=1-ssim(r(x),y);
对抗性损失为在去雾结果中,采用的具有梯度惩罚的wgan(wgan-gp),损失函数为:
感知损失为引入了预先训练的vgg19网络的感知损失,函数为:
l1损失为为了捕获图像中的低电平频率所使用的函数,函数为:
本发明的有益效果是:
本发明提出的基于多尺度自注意生成对抗网络的单幅图像去雾方法,首先将有雾图像进行两次下采样,从而产生三种尺度的有雾图像,对于下采样后两个尺度的图像,首先经过自注意力机制,然后对应的特征映射输入到生成器的主干网络中。对于不同尺度的图像采用自注意力机制可以在扩大感受野的同时提高网络的特征提取能力。对于生成器,用残差块替代了传统的卷积块,并且在生成器的中间部分采用金字塔卷积残差块来提高网络的性能;判别器采用patchgans的判别网络,最终提高了去雾图像的质量。
附图说明
图1是本发明单幅图像去雾方法的流程图;
图2是本发明单幅图像去雾方法中自注意力机制的结构示意图;
图3是本发明单幅图像去雾方法中残差块的结构示意图;
图4是本发明单幅图像去雾方法中金字塔卷积残差块的结构示意图;
图5是本发明单幅图像去雾方法中生成器的结构示意图;
图6是本发明单幅图像去雾方法实施例的流程示意图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明基于多尺度自注意生成对抗网络的单幅图像去雾方法,生成器网络输入包括三个不同的图像尺度,对于两个分支网络,通过采用自注意力机制考虑每个像素与所有其他像素的关系来计算非局部增强特征,并将得到的增强的特征输入到主干网络中,增强主干网络的图像去雾能力。目前自注意力机制的存放位置一般为网络的前端,而注意力由于计算复杂,因此通用的做法是在主干网络中对特征映射进行下采样后再引入自注意力机制,但是这种方法不能直接从图像中通过自注意力机制得到增强特征,因此我们采用了先对图像进行下采样,然后直接使用自注意力机制的方法来充分提取图像的增强特征。在网络的末端我们将对网络中不同的分辨率的特征映射都卷积为一个去雾图像,通过不同尺度的监督学习来进一步提高和输入图像尺寸相同的去雾结果。
利用训练集对生成对抗网络模型进行训练,得到训练后的生成对抗网络模型,训练过程中不同的尺度的去雾结果采用不同的损失函数进行优化。去雾结果ri和去雾结果rj采用l1损失和结构相似性损失,去雾结果rk采用对抗损失、感知损失、l1损失和结构相似性损失进行优化,k=2j=4i。
如图6所示,以尺寸为256x256x3的有雾图像为实施例,本发明基于多尺度自注意生成对抗网络的单幅图像去雾方法。
如图1所示,包括以下步骤:
步骤1、获取图像数据集,对图像数据集中的每个有雾图像的像素值归一化为[-1,1],得到训练集;
步骤2、将输入的尺寸为256x256x3的有雾图像进行两次下采样得到尺寸为128x128x3和64x64x3,构建生成对抗网络模型,生成对抗网络模型包括生成网络和判别网络;
将输入有雾图像尺寸为256x256x3的路径作为生成器的主干网络,尺寸为128x128x3和尺寸为64x64x3的路径作为的分支输入到主干网络中,并且每一个分支都采用自注意力机制;
对于生成器生成的去雾图像,将和输入图像尺寸256x256x3大小相同的输出作为最终的去雾结果,将得到的分支去雾结果作为监督学习的一部分,来约束生成器模型。
如图2所示,自注意力机制首先对输入的特征映射x进行线性映射,然后得到特征θ,
通过调整特征映射的维度,合并上述的三个特征除通道数外的维度,然后对θ和
将得到的注意力特征映射与特征g进行点乘,然后将点乘后的结果经过线性变换后与输入的特征进行相加得到自注意力特征z;
如图3所示,残差块主要包括卷积层和激活函数两个部分,输入特征首先经过卷积层得到特征映射,然后将得到的特征映射输入到激活函数中进行激活,将激活后的特征映射再次输入到卷积层中进行卷积,将卷积得到的特征映射与输入进行相加,并将相加的结果经过激活函数处理后输出最终的特征映射。
如图4所示,金字塔卷积残差块是以残差块的结构为主干,改进了卷积层的处理方式。金字塔卷积首先将输入特征映射根据卷积核尺寸1、3、5、7、9按1:1:2:4:8的比例划分为五个部分,然后每个卷积层对分配的特征映射进行卷积得到对应卷积核的特征映射,最后将得到的5个部分的特征映射进行通道连接,得到与输入特征映射通道数相同的结果。
如图5所示,生成网络的具体操作如下:
a.将训练集中的图像i256使用双线性插值进行下采样得到图像尺度为128x128x3的i128和图像尺度为64x64x3的i64;
i128=downsmaple(i256)(1);
i64=downsmaple(i128)(2);
b.对于输入为i128的分支,我们首先将输入的图像经过一个由卷积、实例归一化和激活函数组成的网络层进行特征提取得到处理后的特征映射o1:
o1=relu(instance_norm(conv(i128)))(3);
c.将o1输入到自注意力模块attention中,得到具有全局注意力的特征映射o2:
o2=attention(o1)(4);
d.将自注意力特征o2经过一个残差块进行特征矫正;
o3=resblock(o2)(5);
e.对于输入为i64的分支采用和输入为i128分支相同的操作得到o6;
o4=relu(instance_norm(conv(i64)))(6);
o5=attention(o4)(7);
o6=resblock(o5)(8);
f.对于主干分支,我们首先将输入的i256经过一个卷积核大小为3,步长为1的卷积层,输出特征映射o7;
o7=conv(i256)(9);
g.将特征映射o7依次经过三个残差块来提取浅层特征;
o8=resblock(o7)(10);
o9=resblock(o8)(11);
o10=resblock(o9)(12);
h.使用卷积核大小为3,步长为2的卷积层对特征映射o10进行下采样得到特征映射o11;
o11=relu(instance_norm(conv(o10)))(13);
i.将特征o11与输入为i128的分支的特征o3进行通道连接,并使用两个残差块来整合特征;
o12=resblock(resblock(concat(o11,o3)))(14);
j.使用卷积核大小为3,步长为2的卷积层将特征o12进行下采样,进一步扩大网络的感受野;
o13=relu(instance_norm(conv(o12)))(15);
k.将特征o13与输入为i64的分支的特征o6进行通道连接,并使用四个金字塔卷积残差块来充分利用深层特征;
o14=concat(o13,o6)(16);
o15=pyresblock(o14)(17);
o16=pyresblock(o15)(18);
o17=pyresblock(o16)(19);
l.将特征o17使用卷积核为3,步长为2的反卷积层进行上采样得到特征映射o18;
o18=relu(instance_norm(deconv(o17)))(20);
m.将特征o18与跳跃链接o12进行通道连接,并用两个残差块进行整合;
o19=resblock(resblock(concat(o18,o12)))(21);
n.将深层特征o19输入卷积核为3、步长为2的反卷积层进行上采样,输出特征o20;
o20=relu(instance_norm(deconv(o19)))(22);
o.通过跳过连接将特征o20与浅层特征o10进行通道连接得到组合特征,并将组合特征输入三个残差块进行整合,输出特征o21;
o21=resblock(resblock(resblock(concat(o20,o10))))(23);
p.将特征o21使用卷积核为3,步长为1的卷积操作来恢复通道数,并使用tanh激活函数激活,得到最终的去雾图像r256;
q.将特征o19与特征o3进行通道连接,并使用一个残差块进行整合得到输出特征o22;
o22=resblock(concat(o19,o3))(25);
r.将特征o22使用卷积核为3,步长为1的卷积操作来恢复通道数,并使用tanh激活函数激活,得到最终的去雾图像r128;
s.将特征o17与特征o6进行通道连接,并使用一个残差块进行整合得到输出特征o23;
o23=resblock(concat(o17,o6))(27);
t.将特征o23使用卷积核为3,步长为1的卷积操作来恢复通道数,并使用tanh激活函数激活,得到最终的去雾图像r64;
步骤3、利用训练集对生成对抗网络模型进行训练,得到训练后的生成对抗网络模型,训练过程中不同的尺度的去雾结果采用不同的损失函数进行优化。去雾结果r64和去雾结果r128采用l1损失和结构相似性损失,去雾结果r256采用对抗损失、感知损失、l1损失和结构相似性损失进行优化。网络的总损失函数为:
上式中,lossl1为l1损失,lossssim为结构相似性损失,lossvgg为感知损失,根据多次的实验调参,我们在λ1=10,λ2=0.00001,λ3=10时的去雾结果最好。
结构相似性损失:我们使用结构相似性损失来提高每个尺度去雾图像的结构质量。设x和y分别表示观察到的图像和输出图像,r(x)表示输入x的去雾结果,因此,r(x)和y之间的ssim如下所示:
ssim=[l(r(x),y)]α·[c(r(x),y)]β·s(r(x),y)γ(1);
上式中,l、c和s分别表示亮度、对比度和结构,α,β和γ是系数,ssim损失可以定义为:
lossssim=1-ssim(r(x),y)(2);
对抗性损失:在尺寸为256x256x3的去雾结果中,采用的具有梯度惩罚的wgan(wgan-gp),损失函数如下:
r256表示去雾后的结果,j为清晰图像,
感知损失:为了尽量减少融合解码器结果的感知特征与真实图像的感知特征之间的差异,引入了预先训练的vgg19网络的感知损失,公式如下:
上式中,φi()表示vgg19网络第i层的激活。w,h和c分别表示图像的宽度,高度和通道数。
l1损失:为了使生成的多尺度去雾图像更真实,使用l1损失函数来捕获图像中的低电平频率。l1的损失为:
lossl1=||r64-j64||1+||r128-j128||1+||r256-j256||1(6)。
步骤4、将有雾图像输入训练后的生成对抗网络模型中,得到去雾图像。
本发明方法得到的去雾图像可以分别采用峰值信噪比、结构相似性与清晰图像进行对比,来评价去雾结果。本方法提高了去雾图像与清晰图像之间的结构相似性和峰值信噪比,使得去雾结果更逼近真实的清晰图像。
- 还没有人留言评论。精彩留言会获得点赞!