一种基于监督学习的航班离场平均延误预测方法与流程
本发明涉及一种基于监督学习的航班离场平均延误预测方法,属于航班离场平均延误预测技术领域。
背景技术:
随着民航的快速发展,航班延误问题已成为航空运输系统的一个重要课题,航空业一直在遭受经济损失。根据美国交通统计局(bts)的数据,2018年有超过20%的航班延误。为了缓解突发性航班延误带来的负面经济影响,平衡日益增长的航班需求与航班延误,准确预测机场的航班延误是必要前提。
目前对延误预测的研究一般可分为两类:基于延误传播的方法和数据驱动的方法。基于延误传播的方法侧重于研究航空运输网络中的航班延误传播现象,并尝试基于潜在机制预测航班延误。数据驱动分析是近年来非常流行的方法,它试图通过数据挖掘、统计分析和/或机器学习技术直接预测航班延误,而不是探索延误传播机制。到目前为止,航班延误预测一直是众多研究者研究的热点,但以往的研究很少从机场的角度对航班预计起飞延误进行预测。
技术实现要素:
本发明所要解决的技术问题是:提供一种基于监督学习的航班离场平均延误预测方法,利用机场的航班数据和天气信息的集合,采用监督机器学习方法,实现了对航班离场平均延误的预测。
本发明为解决上述技术问题采用以下技术方案:
一种基于监督学习的航班离场平均延误预测方法,包括如下步骤:
步骤1,获取待预测机场某一段时间的航班数据以及天气数据,并将相同时间段的航班数据与天气数据对应融合起来,形成初始数据集,对初始数据集进行清洗得到可用数据集;
步骤2,从可用数据集中提取出四类特征作为监督学习方法所用特征,包括时间特征、飞行特征、延误特征和天气特征,并对所有特征进行标准化处理,得到标准化后的数据集;
步骤3,将标准化后的数据集分为训练数据集、验证数据集和测试数据集,以待预测时间段的期望延误时间作为预测目标,利用训练数据集和验证数据集分别对多元线性回归模型、支持向量机模型、极端随机树模型和lightgbm模型进行训练,从而得到训练好的各个模型;
步骤4,利用测试数据集,对训练好的各个模型进行测试,得到各个模型对应的预测结果,选择均方误差和绝对平均误差作为性能指标,比较各个模型的预测结果,选择预测结果最好的模型作为预测模型进行预测。
作为本发明的一种优选方案,所述步骤1的具体过程如下:
步骤1.1,获取待预测机场某一段时间的航班数据,所述航班数据包括日期、航班计划起飞和降落时间、实际起飞和降落时间;
步骤1.2,获取与步骤1.1所述某一段时间相同的时间段内待预测机场的天气数据,所述天气数据包括观测时间、露点温度、温度、风向、风速、压强、湿度、天气情况;
步骤1.3,将一天分为24个时间段,每个时间段的时长为1小时,将相同时间段的航班数据与天气数据融合起来,并按照时间段先后的顺序顺序排列,形成初始数据集,对初始数据集进行清洗,去除异常数据,得到可用数据集。
作为本发明的一种优选方案,所述步骤2的具体过程如下:
步骤2.1,从可用数据集中提取时间特征,所述时间特征包括月份、星期几、一天中的某小时;
步骤2.2,令预测时间段为i,预测时间段的前一时间段为i-1,从可用数据集中提取飞行特征,所述飞行特征包括前一时间段的计划进场航班数量、前一时间段的计划离场航班数量、前一时间段的实际进场航班数量、前一时间段的实际离场航班数量、预测时间段的计划进场航班数量、预测时间段的计划离场航班数量、预测时间段的累计进场航班需求数量、预测时间段的累计离场航班需求数量;
步骤2.3,从可用数据集中提取延误特征,所述延误特征包括前一时间段的进场航班延误数量、前一时间段的离场航班延误数量、前一时间段的进场航班延误期望、前一时间段的离场航班延误期望;
步骤2.4,从可用数据集中提取天气特征,所述天气特征包括观测时间、露点温度、温度、风向、风速、压强、湿度、天气情况,将其中的风向和天气情况通过编码转换成数字;
步骤2.5,对于时间特征、飞行特征、延误特征和天气特征,每个特征中的数据进行标准化处理,得到标准化后的数据集。
作为本发明的一种优选方案,步骤2.2所述预测时间段的累计进场航班需求数量、预测时间段的累计离场航班需求数量分别为:
预测时间段i的累计进场航班需求数量=前一时间段i-1未进场航班数量+预测时间段i计划进场航班数量,前一时间段i-1未进场航班数量=前一时间段i-1的前一时间段i-2未进场航班数量+前一时间段i-1计划进场航班数量;
预测时间段i的累计离场航班需求数量=前一时间段i-1未离场航班数量+预测时间段i计划离场航班数量,前一时间段i-1未离场航班数量=前一时间段i-1的前一时间段i-2未离场航班数量+前一时间段i-1计划离场航班数量。
作为本发明的一种优选方案,步骤2.3所述前一时间段的进场航班延误期望、前一时间段的离场航班延误期望分别为:
前一时间段的进场航班延误期望=前一时间段内进场航班总延误时间/进场航班总架次;
前一时间段的离场航班延误期望=前一时间段内离场航班总延误时间/离场航班总架次。
作为本发明的一种优选方案,所述步骤3的具体过程如下:
步骤3.1,将20%标准化后的数据集作为测试数据集,对剩余的80%标准化后的数据集,采用5倍交叉验证方法分为训练数据集和验证数据集;
步骤3.2,利用训练数据集和验证数据集对多元线性回归模型进行训练和调参,得到训练好的多元线性回归模型;利用训练数据集和验证数据集对支持向量机模型进行训练和调参,得到训练好的支持向量机模型;利用训练数据集和验证数据集对极端随机树模型进行训练和调参,得到训练好的极端随机树模型;利用训练数据集和验证数据集对lightgbm模型进行训练和调参,得到训练好的lightgbm模型。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
本发明航班离场平均延误预测方法所提取的特征与采用的机器学习算法可以较为准确的对机场离场航班平均延误做出预测判断,为缓解空中交通延误,平衡航班需求与航班延误提供理论前提,并可帮助空中交通管制员做出合理的航班调度。
附图说明
图1是本发明一种基于监督学习的航班离场平均延误预测方法的原理图。
图2是监督机器学习模型数据集划分图。
图3是预测误差值随实际延误值的累计分布散点图。
图4是测试集上误差值的累计分布图。
具体实施方式
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
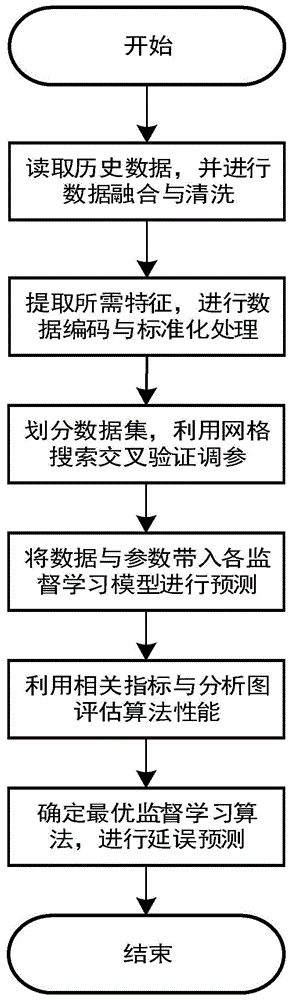
如图1所示,为本发明一种基于监督学习的航班离场平均延误预测方法的原理图,包括如下步骤:
(1)分析选取所研究机场的某一段时间(如一年)的航班计划数据以及天气数据,并进行数据融合及数据清洗工作;
包括以下分步骤:
(1.1)读取历史航班飞行计划数据,包括日期,航班的计划起降时间,实际起降时间等数据字段。在本实施例中,选取了南京禄口国际机场2017年3月-2018年2月共一年的106003条离场航班计划数据;
(1.2)读取机场历史气象数据,包括观测时间,露点温度,温度,风向,风速,压强,湿度,天气情况(阴雪雨晴多云等);
(1.3)将机场历史航班数据与气象数据按时间字段融合,并对初始数据进行清洗,去除一些不相关的特征,删除一些异常数据,包括航班的取消数据及返航数据等,本实施例中共取消起飞航班388架次,返航航班32架次。
(2)从所选数据集中提取出四类特征作为监督学习所用特征,包括时间特征、飞行计划特征、延误特征和天气特征,并对所有特征进行标准化处理;
包括以下分步骤:
(2.1)从处理完成的数据中提取出如下时间特征数据:月份,星期几,一天中的某小时;
(2.2)从处理完成的数据中提取出如下飞行计划特征数据:
前一时段的计划进/离场航班数量:根据航班计划中的计划进/离场时间字段,统计计划进/离场时间在预测时段前一时段范围内的航班数量;
前一时段的实际进/离场航班数量:根据航班计划中的实际进/离场时间字段,统计实际进/离场时间在预测时段前一时段范围内的航班数量;
预测时段的计划进/离场航班数量:根据航班计划中的计划进/离场时间字段,统计计划进/离场时间在预测时段范围内的航班数量;
预测时段的累计进/离场航班需求数量:累计进/离场航班需求数量的提取公式如下:设预测时段为i,则时段i累计进/离场航班需求数=时段i-1未进/离场航班数+时段i计划进/离场航班数,时段i-1未进/离场航班数=时段i-2未进/离场航班数+时段i-1计划进/离场航班数-时段i-1实际进/离场航班数;
(2.3)从处理完成的数据中提取出如下延误特征数据:
前一时段的进/离场航班延误数量:根据《航班正常管理规定》中的定义,将进/离场延误时间超过15分钟的航班视为延误航班。根据航班计划中的计划进/离场时间与实际进离场时间,统计预测时段的前一时段内实际进离场时间减去计划进/离场时间大于15分钟的航班数量;
前一时段的进/离场航班延误期望:统计预测时段前一时段内进/离场航班总延误时间与进/离场航班总架次的比值,计算公式如下:
前一时段的进/离场航班延误期望=前一时段内进(离)场航班总延误时间/进(离)场航班总架次
(2.4)从处理完成的数据中提取出如下天气特征数据:露点温度,温度,湿度,风向,风速,压强和天气情况(阴、晴、雨、雪等)。风向和天气情况这两个天气特征是无法直接计算的类别属性,因此,这两种类型的文本标签通过编码被转换成数字用于模型构建;
(2.5)对所有特征进行标准化处理,标准化公式如下:
其中,xi表示特征样本的原始值,e[x]表示期望值,var[x]表示方差,
(3)将机场各时段的期望延误时间作为标签和预测目标,采用多元线性回归(linearr)、支持向量机(svm)、极端随机树(extrart)和lightgbm等不同的监督学习方法进行预测建模;
包括以下分步骤:
(3.1)为了对模型进行无偏评价,将建模数据分为训练数据集、验证数据集和测试数据集。训练数据集是一组用于拟合模型参数的示例,验证数据集用于模型的无偏评估和超参数的调整,测试数据集用于提供最终模型的无偏评估。将20%的原始数据独立为测试数据集,而剩余的数据通过5倍交叉验证方法被分为训练和验证数据集。数据集划分方式如图2所示;
(3.2)在以上数据划分的基础上,利用网格搜索算法分别对多元线性回归(linearr)、支持向量机(svm)、极端随机树(extrart)和lightgbm四种监督学习算法进行调参,确定各算法所用超参数;
(3.3)将合适参数代入模型,分别利用多元线性回归(linearr)、支持向量机(svm)、极端随机树(extrart)和lightgbm四种监督学习模型进行预测。本实施例利用python的scikit-learn工具进行机器学习调参与建模。
(4)选择均方误差(mse)和绝对平均误差(mae)作为性能指标,比较不同模型的预测结果,选择最优预测模型;
包括以下分步骤:
(4.1)根据预测结果,绘制模型预测误差值随实际延误值的累计分布散点图(如图3所示)以及测试集上误差值的累计分布图(如图4所示),观察四种模型的预测效果;
(4.2)选择均方误差(mse)和绝对平均误差(mae)作为性能指标,比较不同模型的预测结果,选择最优预测模型。均方误差(mse)和绝对平均误差(mae)的计算公式如下:
其中,yi表示原始数据,
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!