一种将在线课堂中的图像和视频卡通化的方法与流程
本发明属于在线图像处理技术领域,特别涉及一种将在线课堂中的图像和视频卡通化的方法。
背景技术:
近年来,随着互联网的疾速发展。在线教育随着特殊的优势发展规模越来越大,这一技术随着老师和学生之间的需要逐渐得到完善,但是长时间面对单一枯燥的电脑画面,屏幕前的用户很容易乏味无趣,学习积极性下降,感受到视觉疲劳。
卡通应用于各种场景,卡通的效果有搞笑、可爱、庄重,通过卡通艺术形象,可以让人视觉上感觉焕然一新,能够让生活中增添幽默,丰富精神生活。卡通化是将真实图片作为输入,得到相对应的卡通的图片,现有某些卡通化技术对于更加精细的线条和纹理会选择性忽视,最后造成一些颜色偏移,纹理扭曲等现象,出现用户不喜欢的伪像。
技术实现要素:
本发明的目的在于,克服现有技术中的不足之处,提供一种将在线课堂中的图像和视频卡通化的方法,解决了现有技术中传统课堂画面单一枯燥的技术难题,使用本发明实现课堂画面的卡通化,生成高质量的卡通化图像或视频。
本发明的目的是这样实现的:一种将在线课堂中的图像和视频卡通化的方法,包括以下步骤,
(1)从网上爬取若干真实图像和若干卡通图像作为训练数据集;
(2)构建生成对抗网络,将训练好的网络区别提取图像的高级特征的内容,设计损失函数来调整每个组件的权重;设计三个分别独立的图像处理模块,用来提取相应的三种卡通表示,并指导基于生成对抗网络的图像卡通化框架,平衡生成对抗网络中每个表示的权重,调整损失函数,获得卡通图像输出的最优样式;
(3)对于在线课堂中的输入图像自主选择卡通化模式;
(4)在训练完成后的生成对抗网络的生成器中,输入将要处理的在线课堂图像,输出相对应的卡通图;
其中,卡通化模式包括人像卡通化和整体卡通化,对抗网络由一个生成器g和两个鉴别器dx、dy组成。
步骤(1)中,三个独立的图像处理模块的三种卡通表示分别是,卡通图像通过平滑的轮廓表面表示、不同稀疏色块的结构表示、反映高频率纹理和细节的纹理表示。
为了进一步实现图像的卡通化,所述步骤(2)具体为,将步骤(1)所述真实图像i作为引导图,输入生成器g转化成卡通图象,i1表示输入图片,i11表示参考卡通图像,图像处理模块指导优化生成对抗网络图像卡通化的框架,包括以下步骤,
(201)图像处理模块fd为了平滑图像,同时保持全局语义结构,边缘检测采用可区分的引导滤波器保留过滤,输出只提取保留颜色组成和表面特征的卡通图象;鉴别器dx判断模型是否输出,并且是否和参考卡通图像具有相似的表面,并引导生成器g学习存储在提取的表面表示中的信息,表面损失函数设计为:
lsur(g,dx)=log(dx(fd(i11,i11)))+log(1-dx(fd(g(i1),g(i1))))(1);
(202)图像处理模块fs根据输入的图像,提取一个不可分割图,在每个分割区域使用标准超像素算法用像素值的平均值着色生成结构表示;用预先训练的vggn网络来实施空间约束,结构损失函数设计为:
lstr=||vggn(g(i1))-vgg(fs(g(i1)))||(2);
(203)图像处理模块ft减少颜色和亮度的影响并保留高频特征,然后让网络自主学习纹理细节,在学习纹理特征时,rgb三个颜色通道利用单通道纹理算法分开分析处理,rgb图转化的灰度图表示为u,ft公式为:
ft(irgb)=(1-α)(β1*ir+β2*ig+β3*ib)+α*u(3);
所述公式(3)中,设α在0~1之间取值,β1、β2、β3在-1~1之间取值;
鉴别器dy鉴别输出图像和参考卡通图像提取的纹理表示,并引导生成器g学习存储在纹理表示中的清晰图像和精细纹理,纹理损失函数设计为:
ltex(g,dy)=log(dy(ft(i11)))+log(1-dy(ft(g(i1))))(4);
(204)通过调整λ1、λ2、λ3、λ4以获得损失函数最优化,总得损失函数设计为:
l=λ1*lsur+λ2*lstr+λ3*ltex+λ4*ltv(5);
所述公式(5)中,为了减少高频噪声,设计损失函数ltv,图像的空间维度用h、w、c代表,公式为:
ltv=1/(h*w*c)*||(▽x(g(i1))+▽y(g(i1)))||(6);
其中,ft(irgb)为提取颜色图像,去除亮度和颜色信息;fd为表面表示提取,fs为结构表示提取,ft为纹理表示提取,g(i1))为图像i1通过生成器g生成的卡通图像,vggn(g(i1))为对g(i1)实施空间约束;fs(g(i1)为提取g(i1)的结构表示,vgg(fs(g(i1))为对fs(g(i1))实施空间约束;fd(i11,i11)为输入图像i11,返回被移除纹理和细节的表面表示;fd(g(i1)为提取g(i1)的表面表示,fd(g(i1),g(i1))为输入图像g(i1),返回被移除纹理和细节的表面表示;ir、ig和ib为三个颜色通道,ft(i11)为提取i11颜色图像,去除亮度和颜色信息,ft(g(i1))为提取g(i1)颜色图像,去除亮度和颜色信息,λ1为表面损失函数的参数,λ2为结构损失函数的参数,λ3为纹理损失函数的参数,λ4为噪声损失函数的参数,α为,dy(ft(i11))为判定特征ft(i11)来自训练样本i11的概率,dy(ft(g(i1)))为判定特征ft(g(i1))来自训练样本i1的概率,▽x(g(i1))、▽y(g(i1))使用梯度下降算法对g(i1)进行平滑处理且降低图像失真度。
为了实现卡通图像的自适应调节,所述步骤(2)中,通过防近视识别模块对用户上课的姿势生成对抗网络中每个表示的权重,调整损失函数。
作为本发明的进一步改进,所述步骤(2)中,防近视识别模块用于识别检测接收端用户闭合眼睛次数和看书学习的头部与桌面的距离,判断用户上课姿势是否正确和注意力集中。
为了进一步实现卡通图像的自适应调节,所述步骤(203)和步骤(204)之间还包括以下步骤,
(204a)防近视识别模块每5分钟以双眼眼轴中心两点之间的中心点为起始点,通过摄像头确认眼睛阅读的画面位置,利用霍夫变换检测直线找到起始点与阅读的画面的最短距离点;每2分钟通过摄像头检测眼睛张开闭合的次数和用户在线学习的姿势;
(204b)比较最短距离与设计的阈值大小,若最短距离小于阈值,通过减小表面表示的参数来提醒用户距离画面较近;比较眼睛闭合次数与设计阈值的大小,如小于阈值,则通过增大结构表示的参数来预警用户现在处于疲倦状态;识别用户此时的学习姿势,若姿势不正确,则通过增大纹理表示的参数来提醒用户现在的学习姿势是错误的,若姿势不正确或最短距离小于阈值或眼睛闭合次数小于阈值,转至步骤(204c);若姿势正确、最短距离不小于阈值且眼睛闭合次数不小于阈值,转至步骤(204);
(204c)预设数值x1作为表面表示减小的变化范围,预设数值x2作为结构表示增大的变化范围,预设数值x3作为纹理表示增大的变化范围,损失函数l’设计为,
l′=(λ1–x1)lsur+(λ2+x2)lstr+(λ3+x3)ltex+λ4ltv(7);
其中,最短距离小于距离阈值,0<x1<λ1,否则x1=0;比较眼睛闭合次数小于设计的次数阈值,0<x2<λ2,否则x2=0;姿势不正确,0<x3<λ3,否则x3=0。
为了进一步实现视频的卡通化,当选择视频被卡通化时,依据对输入视频的当前帧进行卡通化处理,并作为参考帧使后续帧实现视频实时卡通化。
本发明与现有技术相比,本发明将真实的图像和卡通图像放入基于生成对抗网络中的图像卡通化框架中训练,生成高质量的卡通化图像或视频;用户可以通过平衡每个表示的权重来调整在线课堂中图像输出的不同风格样式,实现用户卡通化的选择和修改,解决在线课堂中用户视觉疲劳的问题;调整损失函数使图像增加更多的细节,减少不适当颜色和细节的修改,做到图像和视频卡通化的合理性和有效性;根据用户在屏幕前的行为表现,可自动调节图象来形成警示效果,避免用户不良习惯的形成,预防近视的增加。
附图说明
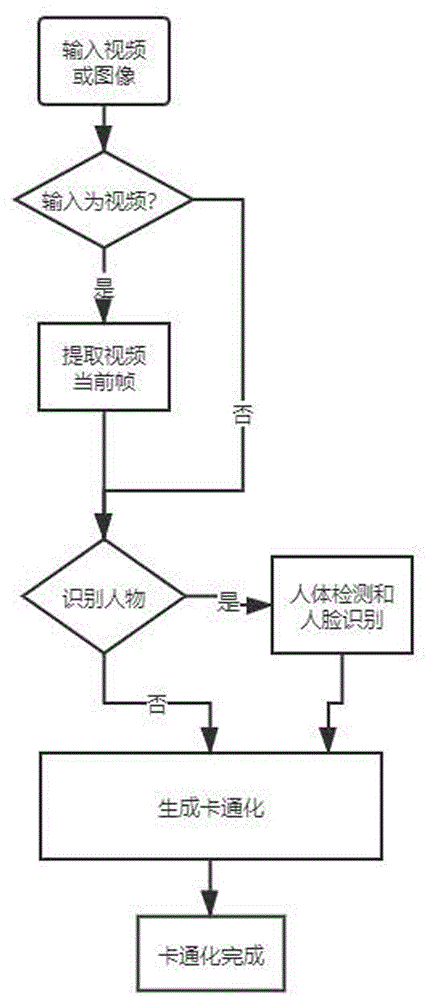
图1为本发明的总体流程框图。
图2为本发明中卡通化的流程框图。
具体实施方式
下面结合附图对本发明进行进一步说明。
如图1所示的一种将在线课堂中的图像和视频卡通化的方法,包括以下步骤:
(1)从网上爬取若干真实图像和若干卡通图像作为训练数据集,取得的真实图像和卡通图像作为训练数据集,具体如下,
找到真实图片网站,要求真实人脸图像和风景图像清晰可见;
找到卡通图片网站,要求卡通人脸图像和风景图像清晰可见;
利用网络爬虫技术,从真实图片网站爬取获得20000张人脸图像和20000张风景图像,从卡通图片网站爬取获得20000张人脸图像和20000张风景图像;
(2)构建生成对抗网络,该网络由一个生成器g和两个鉴别器dx和dy组成,具体如下,
首先,生成器网络是一个全卷积的网络,由三种层组成:卷积层、降采样层、双线性层,将stride=2的卷积层作为下采样层,双线性插值层作为上采样层,生成器g是输入真实图像自动生成卡通图像输出;其次鉴别器网络使用patchgan,patchgan输出的是一个n*n的矩阵x,这个n*n的矩阵的每一个元素xij,只有正确或错误两个选择,逐次叠加的卷积层最终输出的这个n*n的矩阵,其中的每一个元素,代表着原图中的一个比较大的感受域,也就是对应着原图中的一个矩阵;
然后将训练好的网络区别提取图像的高级特征的内容,设计损失函数来调整每个组件的权重;设计三个分别独立的图像处理模块,用来提取相应的三种卡通表示,并指导基于生成对抗网络的图像卡通化框架,平衡生成对抗网络中每个表示的权重,调整损失函数,获得卡通图像输出的最优样式;
基于上述已构建的生成对抗网络,将训练数据集中的真实图像作为输入,在训练过程中不断调整生成器和鉴别器,在通过防近视识别模块之前使损失到达最优化;
(3)对于在线课堂中的输入图像自主选择卡通化模式;
(4)在训练完成后的生成对抗网络的生成器中,输入将要处理的在线课堂图像,输出相对应的卡通图;
其中,卡通化模式包括人像卡通化和整体卡通化,对抗网络由一个生成器g和两个鉴别器dx、dy组成;步骤(1)中,三个独立的图像处理模块的三种卡通表示分别是,卡通图像通过平滑的轮廓表面表示、不同稀疏色块的结构表示、反映高频率纹理和细节的纹理表示,高频纹理就是图像转化为灰度图像,边缘和纹理信息变化比较大的。
为了进一步实现图像的卡通化,所述步骤(2)具体为,将步骤(1)所述真实图像i作为引导图,输入生成器g转化成卡通图象,i1表示输入图片,i11表示参考卡通图像,图像处理模块指导优化生成对抗网络图像卡通化的框架,包括以下步骤,
(201)图像处理模块fd为了平滑图像,同时保持全局语义结构,边缘检测采用可区分的引导滤波器保留过滤,输出只提取保留颜色组成和表面特征的卡通图象;鉴别器dx判断模型是否输出,并且是否和参考卡通图像具有相似的表面,并引导生成器g学习存储在提取的表面表示中的信息,表面损失函数设计为:
lsur(g,dx)=log(dx(fd(i11,i11)))+log(1-dx(fd(g(i1),g(i1))))(1);
(202)图像处理模块fs根据输入的图像,提取一个不可分割图,在每个分割区域使用标准超像素算法用像素值的平均值着色生成结构表示;用预先训练的vggn网络来实施空间约束,结构损失函数设计为:
lstr=||vggn(g(i1))-vgg(fs(g(i1)))||(2);
(203)图像处理模块ft减少颜色和亮度的影响并保留高频特征,然后让网络自主学习纹理细节,在学习纹理特征时,rgb三个颜色通道利用单通道纹理算法分开分析处理,rgb图转化的灰度图表示为u,ft公式为:
ft(irgb)=(1-α)(β1*ir+β2*ig+β3*ib)+α*u(3);
所述公式(3)中,设α在0~1之间任意值,β1、β2、β3在-1~1之间取值;
鉴别器dy鉴别输出图像和参考卡通图像提取的纹理表示,并引导生成器g学习存储在纹理表示中的清晰图像和精细纹理,纹理损失函数设计为:
ltex(g,dy)=log(dy(ft(i11)))+log(1-dy(ft(g(i1))))(4);
(204)通过调整λ1、λ2、λ3、λ4以获得损失函数最优化,总得损失函数设计为:
l=λ1*lsur+λ2*lstr+λ3*ltex+λ4*ltv(5);
所述公式(5)中,为了减少高频噪声,设计损失函数ltv,图像的空间维度用h、w、c代表,公式为:
ltv=1/(h*w*c)*||(▽x(g(i1))+▽y(g(i1)))||(6);
其中,ft(irgb)为提取颜色图像,去除亮度和颜色信息;fd为表面表示提取,fs为结构表示提取,ft为纹理表示提取,g(i1))为图像i1通过生成器g生成的卡通图像,vggn(g(i1))为对g(i1)实施空间约束;fs(g(i1)为提取g(i1)的结构表示,vgg(fs(g(i1))为对fs(g(i1))实施空间约束;fd(i11,i11)为输入图像i11,返回被移除纹理和细节的表面表示;fd(g(i1)为提取g(i1)的表面表示,fd(g(i1),g(i1))为输入图像g(i1),返回被移除纹理和细节的表面表示;ir、ig和ib为三个颜色通道,ft(i11)为提取i11颜色图像,去除亮度和颜色信息,ft(g(i1))为提取g(i1)颜色图像,去除亮度和颜色信息,λ1为表面损失函数的参数,λ2为结构损失函数的参数,λ3为纹理损失函数的参数,λ4为噪声损失函数的参数,α为,dy(ft(i11))为判定特征ft(i11)来自训练样本i11的概率,dy(ft(g(i1)))为判定特征ft(g(i1))来自训练样本i1的概率,▽x(g(i1))、▽y(g(i1))使用梯度下降算法对g(i1)进行平滑处理且降低图像失真度。
步骤(2)中,防近视识别模块用于识别检测接收端用户闭合眼睛次数和看书学习的头部与桌面的距离,判断用户上课姿势是否正确和注意力集中;所述步骤(203)和步骤(204)之间还包括以下步骤,
(204a)防近视识别模块每5分钟以双眼眼轴中心两点之间的中心点为起始点,通过摄像头确认眼睛阅读的画面位置,利用霍夫变换检测直线找到起始点与阅读的画面的最短距离点;每2分钟通过摄像头检测眼睛张开闭合的次数和用户在线学习的姿势;
(204b)比较最短距离与设计的阈值大小,若最短距离小于阈值,通过减小表面表示的参数来提醒用户距离画面较近;比较眼睛闭合次数与设计阈值的大小,如小于阈值,则通过增大结构表示的参数来预警用户现在处于疲倦状态;识别用户此时的学习姿势,若姿势不正确,则通过增大纹理表示的参数来提醒用户现在的学习姿势是错误的,若姿势不正确或最短距离小于阈值或眼睛闭合次数小于阈值,转至步骤(204c);若姿势正确、最短距离不小于阈值且眼睛闭合次数不小于阈值,转至步骤(204);
(204c)预设数值x1作为表面表示减小的变化范围,预设数值x2作为结构表示增大的变化范围,预设数值x3作为纹理表示增大的变化范围,损失函数l’设计为,
l′=(λ1–x1)lsur+(λ2+x2)lstr+(λ3+x3)ltex+λ4ltv(7);
其中,最短距离小于距离阈值,0<x1<λ1,否则x1=0;比较眼睛闭合次数小于设计的次数阈值,0<x2<λ2,否则x2=0;姿势不正确,0<x3<λ3,否则x3=0。
为了进一步实现视频的卡通化,当选择视频被卡通化时,依据对输入视频的当前帧进行卡通化处理,并作为参考帧使后续帧实现视频实时卡通化。
本发明的步骤(3)中当对人像进行卡通化处理时,通过人体检测和人脸识别算法获得真实人物图像,通过后续步骤实现人像卡通化处;本发明将真实的图像和卡通图像放入基于生成对抗网络中的图像卡通化框架中训练,生成高质量的卡通化图像或视频;用户可以通过平衡每个表示的权重来调整在线课堂中图像输出的不同风格样式,实现用户卡通化的选择和修改,解决在线课堂中用户视觉疲劳的问题;调整损失函数使图像增加更多的细节,减少不适当颜色和细节的修改,做到图像和视频卡通化的合理性和有效性;根据用户在屏幕前的行为表现,可自动调节图象来形成警示效果,避免用户不良习惯的形成,预防近视的增加;可应用于在线上课时给图像和视频卡通化的工作中。
本发明并不局限于上述实施例,在本发明公开的技术方案的基础上,本领域的技术人员根据所公开的技术内容,不需要创造性的劳动就可以对其中的一些技术特征作出一些替换和变形,这些替换和变形均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!