一种基于互信息相关技术的差分隐私动态数据发布方法与流程
本发明涉及动态数据隐私发布
技术领域:
,具体来说是一种基于互信息相关技术的差分隐私动态数据发布方法。
背景技术:
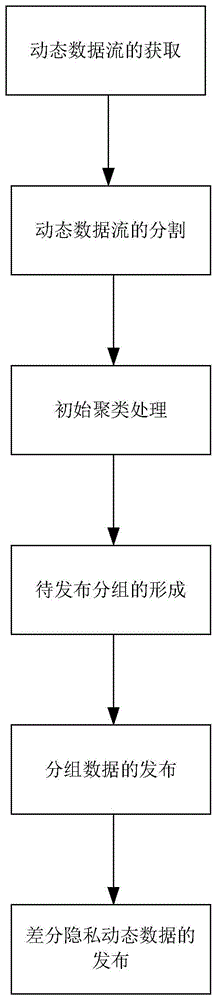
:在混合云数据中心中,不仅存在定期收集的静态数据,也会有源源不断的动态数据流进入,常见的交通流数据、在线交易数据、环境监测数据等均属于动态数据,这些数据通常以一种实时、连续不断、非匀速的方式到达,而且通常类型繁杂、数量无法预知。在对这类数据进行统计发布时,一方面可以挖掘其中蕴含的价值,但另一方面也存在隐私信息泄漏的危险,为了对隐私数据进行保护,不少研究者对此进行了研究。为了保护隐私信息的安全性,研究使用泛化、抑制等方法隐藏敏感信息实现对数据的保护,通常采用k-匿名(sweeneyl.k-anonymity:amodelforprotectingprivacy[j].inter-nationaljournalonuncertainty,fuzzinessandknowledge-basedsystems,2002,10(5):557-570)以及在其基础上改进的l-多样性(machanavajjhalaa,kiferd,gehrkej,etal.l-diversity:privacybeyondk-anonymity[c]//procofthe22ndinternationalconferenceondataengineering.washingtondc:ieeecomputersociety,2006:24-35)、t-保密性(lin,lit,venkatasubramanians.t-closeness:privacybeyondk-anonymityandl-diversity[c]//dataengineering,2007.icde2007.ieee23rdinternationalconferenceon.ieee,2007:106-115)等方法进行数据发布隐私保护。但上述隐私保护方法在现实应用中仍然存在不小的局限性,只能针对特定的攻击手段。近年来,为了抵抗背景知识攻击,差分隐私技术应运而生,该技术可保证即使攻击者获取所能得到的最大背景知识,也无法获取用户的隐私信息,因而结合差分隐私技术的数据发布方法逐渐流行起来(屈晶晶,蔡英,夏红科.面向动态数据发布的差分隐私保护研究综述[j].北京信息科技大学学报(自然科学版),2019,34(06):30-36)。目前,由于数据中心中动态数据体量庞大,针对动态数据的数据发布问题需求强烈,但由于和静态数据特征的不同,导致静态数据的差分隐私发布方法无法支撑动态数据发布。同时,由于动态数据流需要快速而准确的进行统计发布,在进行差分隐私数据发布时通常容易出现噪声积累过多、隐私预算分配不当、数据可用性降低等问题,从而导致数据发布结果误差大,隐私容易泄露等后果。技术实现要素:本发明的目的是为了解决现有技术中噪声积累多、隐私预算分配不当、数据可用性差的缺陷,提供一种基于互信息相关技术的差分隐私动态数据发布方法来解决上述问题。为了实现上述目的,本发明的技术方案如下:一种基于互信息相关技术的差分隐私动态数据发布方法,包括以下步骤:动态数据流的获取:获取待处理的动态数据流;动态数据流的分割:利用滑动窗口技术对动态数据流进行分割,使数据以静态方式展示在滑动窗口中;初始聚类处理:随机抽取滑动窗口内的数据,对其进行初始聚类,计算初始聚类中每个簇的分形维数;待发布分组的形成:对滑动窗口内的剩余数据进行分形维数聚类,利用互信息计算每个聚类成员的权值,选择符合条件的聚类成员,对每个聚类成员的聚类结果进行按类统计,形成待发布分组;分组数据的发布:对待发布分组的数据进行拉普拉斯加噪,发布加噪后的分组数据;对每个聚类成员的每个簇的统计分组结果进行拉普拉斯加噪,其中ε表示隐私预算,得到每个聚类成员加入噪声干扰的数据:差分隐私动态数据的发布:当某个聚类成员的分组数据的数量达到滑动窗口大小时,滑动窗口向前平移,重复初始聚类处理、待发布分组的形成和分组数据的发布步骤,完成差分隐私动态数据的发布。所述初始聚类处理包括以下步骤:抽取滑动窗口内70%-90%的数据量,对其进行初始聚类:将从第d个数据集xd抽取出的部分数据组成数据集xd',对其进行h次初始聚类,得到h个初始聚类结果,组成聚类结果集λ={λ1,λ2,...,λi,...,λh},λi表示第i次聚类结果;若将初始聚类的簇数设置为k个,则第i次聚类结果λi中每个簇分别记为分别计算每个簇对应的分形维数,其中,第k个簇的分形维数记为其中,计算每个簇的分形维数的公式为:式中,r表示覆盖数据空间所用的盒子边长,r1表示最小边长,r2表示最大边长;q表示阶数,取值可以不同,当q=0时,表示该维数是豪斯道夫维数,当q=1时,表示该维数是信息维数,当q=2时,表示该维数是关联维数;表示盒子所覆盖的数据点数。所述待发布分组的形成包括以下步骤:对滑动窗口内的剩余数据,抽取其中的每一个数据点e,将它加入到每一个初始聚类的簇中,得到其中分别计算加入新的数据点e后组成新的簇的分形维数;计算加入数据点前后的分形影响度vi,其计算公式如下:式中,表示第i个聚类成员的第k个簇的分形影响度,表示第i个聚类成员的第k个簇的分形维数,表示第i个聚类成员的第k个簇加入数据点e后的分形维数;找到每一个数据点e加入后分形影响度最小的簇,若其对应的分形影响度小于给定阈值δ,则认为数据点e属于该簇,加入该簇中;若数据点e未找到任何符合的簇,则将其判定为离群点;利用互信息计算每个聚类成员的权值;当聚类成员的权值小于给定阈值μ时,舍弃,留下权值大于μ的聚类成员,得到部分聚类成员λ'={λ′1,λ′2,...,λ′i,...,λ'h}。所述利用互信息计算每个聚类成员的权值为:设定计算互信息的公式为:式中,λp和λq表示聚类成员,p,q为整数,且1≤p,q≤h,n表示数据集大小,k表示聚类的簇数,ni表示聚类成员λp中属于第i个簇的数据点的数量,nj表示聚类成员λq中属于第j个簇的数据点的数量,nij表示聚类成员λp中第i个簇和聚类成员λq中第j个簇之间所含有的相同数据点的数量;计算平均互信息的公式为:式中,αi表示第i个聚类成员的平均互信息;计算聚类成员的权值的公式为:式中,ωi满足ωi>0(i=1,2,...,h)且有益效果本发明的一种基于互信息相关技术的差分隐私动态数据发布方法,与现有技术相比根据动态数据流的特点,采用分形技术对数据进行聚类处理,并利用互信息相关知识进行聚类成员选择,最后结合差分隐私技术对聚类结果添加隐私保护再发布数据,从而提高动态数据发布的安全性及数据的可用性。本发明基于发现交通流数据、在线交易数据、环境监测数据等动态数据流具有分形的特性,利用分形维数聚类方法对数据流进行处理,再利用互信息的知识对聚类结果进行选择,选择较优的聚类成员,进一步提高聚类质量,再结合差分隐私直方图发布技术,可有效满足动态数据发布需求,在有效保护数据的隐私信息的同时保证数据的可用性。附图说明图1为本发明的方法顺序图。具体实施方式为使对本发明的结构特征及所达成的功效有更进一步的了解与认识,用以较佳的实施例及附图配合详细的说明,说明如下:如图1所示,本发明所述一种基于互信息相关技术的差分隐私动态数据发布方法,包括以下步骤:第一步,动态数据流的获取:获取待处理的动态数据流。第二步,动态数据流的分割:利用滑动窗口技术对动态数据流进行分割,使数据以静态方式展示在滑动窗口中。第三步,初始聚类处理:随机抽取滑动窗口内的数据,对其进行初始聚类,计算初始聚类中每个簇的分形维数。(1)抽取滑动窗口内70%-90%的数据量,对其进行初始聚类:将从第d个数据集xd抽取出的部分数据组成数据集xd',对其进行h次初始聚类,得到h个初始聚类结果,组成聚类结果集λ={λ1,λ2,...,λi,...,λh},λi表示第i次聚类结果;(2)若将初始聚类的簇数设置为k个,则第i次聚类结果λi中每个簇分别记为分别计算每个簇对应的分形维数,其中,第k个簇的分形维数记为其中,计算每个簇的分形维数的公式为:式中,r表示覆盖数据空间所用的盒子边长,r1表示最小边长,r2表示最大边长;q表示阶数,取值可以不同,当q=0时,表示该维数是豪斯道夫维数,当q=1时,表示该维数是信息维数,当q=2时,表示该维数是关联维数;表示盒子所覆盖的数据点数。第四步,待发布分组的形成:对滑动窗口内的剩余数据进行分形维数聚类,利用互信息计算每个聚类成员的权值,选择符合条件的聚类成员,对每个聚类成员的聚类结果进行按类统计,形成待发布分组。对抽取完剩下的数据再进行分形维数聚类,可以将剩下的数据添加到更符合的聚类簇中,然后利用互信息,计算每个聚类成员的权值,选择符合阈值条件的聚类成员,也就是选择聚类结果较好的聚类成员,可以有效提升聚类效果,也就是获取了较优的数据聚类分析结果,获取有效的待发布数据的统计结果,为后续添加拉普拉斯噪声后保持数据的可用性做出贡献。其具体步骤如下:(1)对滑动窗口内的剩余数据,抽取其中的每一个数据点e,将它加入到每一个初始聚类的簇中,得到其中(2)分别计算加入新的数据点e后组成新的簇的分形维数;(3)计算加入数据点前后的分形影响度vi,其计算公式如下:式中,表示第i个聚类成员的第k个簇的分形影响度,表示第i个聚类成员的第k个簇的分形维数,表示第i个聚类成员的第k个簇加入数据点e后的分形维数;(4)找到每一个数据点e加入后分形影响度最小的簇,若其对应的分形影响度小于给定阈值δ,则认为数据点e属于该簇,加入该簇中;若数据点e未找到任何符合的簇,则将其判定为离群点;(5)利用互信息计算每个聚类成员的权值;初次分形聚类后得到的聚类成员,其聚类效果各有不同,此时利用互信息,计算得到每个聚类成员的权值,选择符合阈值标准的聚类成员,可以得到更优的聚类结果,达到更好的聚类分析效果,有利于后续添加差分隐私保护。设定计算互信息的公式为:式中,λp和λq表示聚类成员,p,q为整数,且1≤p,q≤h,n表示数据集大小,k表示聚类的簇数,ni表示聚类成员λp中属于第i个簇的数据点的数量,nj表示聚类成员λq中属于第j个簇的数据点的数量,nij表示聚类成员λp中第i个簇和聚类成员λq中第j个簇之间所含有的相同数据点的数量;计算平均互信息的公式为:式中,αi表示第i个聚类成员的平均互信息;计算聚类成员的权值的公式为:式中,ωi满足ωi>0(i=1,2,...,h)且(6)当聚类成员的权值小于给定阈值μ时,舍弃,留下权值大于μ的聚类成员,得到部分聚类成员λ'={λ′1,λ′2,...,λ′i,...,λ'h}。第五步,分组数据的发布:对待发布分组的数据进行拉普拉斯加噪,发布加噪后的分组数据;对每个聚类成员的每个簇的统计分组结果进行拉普拉斯加噪,其中ε表示隐私预算,得到每个聚类成员加入噪声干扰的数据:第六步,差分隐私动态数据的发布:当某个聚类成员的分组数据的数量达到滑动窗口大小时,滑动窗口向前平移,重复初始聚类处理、待发布分组的形成和分组数据的发布步骤,完成差分隐私动态数据的发布。在此,以某动态数据为例,其差分隐私动态数据发布方法,包括以下几个步骤:步骤一:使用滑动窗口技术对动态数据流进行分割:将长度为t的数据流x分割成n个时间戳上的数据点集,得到数据点集的集合p={x1,x2,..,xd,..,xn}。使数据以静态方式展示在滑动窗口中。步骤二:对数据先进行初始聚类。采集一段时间的数据流,抽取出其中一部分数据,采用一种现有的聚类算法k-means聚类算法对数据进行初始聚类:对第d个数据集xd进行h次初始聚类。本实例中,采用uci数据集iris作为一个时间戳下的数据集,其中共有150条四维数据,抽取其中90%的数据组成新的数据集,进行h次聚类,得到h次聚类结果集λ={λ1,λ2,...,λi,...,λh},h取值设为3,即对抽取的90%的数据组成的数据集进行3次初始k-means聚类,λi表示第i次聚类结果,若设定聚类簇数有k个,则λi聚类结果中每个簇分别记为本实施例中将聚类簇数设置为3,即k取3,得到聚类结果集,计算初始聚类中每个簇的分形维数,第k个簇的分形维数记为其中计算分形维数的公式为:式(1)中,r表示覆盖数据空间所用的盒子边长,r1表示最小边长,r2表示最大边长;q表示阶数,可取正负数,当q=0时,表示该维数是豪斯道夫维数,当q=1时,表示该维数是信息维数,当q=2时,表示该维数是关联维数;表示盒子所覆盖的数据点数。本实施例中q值取2。对抽取的90%的数据进行初始k-means聚类,结果计算得到的分形维数如下表1所示:表1初始聚类计算所得分形维数值表步骤三:将步骤一中分割后的滑动窗口数据执行分形维数聚类操作以进行聚类分析,对所剩下的10%的数据进行分形维数聚类:对其中的每一个数据点e加入到每一个初始聚类中去,得到分别计算其分形维数;可以得到新计算的分形维数如表2所示:表2加入剩余数据所得新的分形维数值表计算分形影响度vi,分型影响度计算结果如下表3所示:表3分形影响度表找到分形影响度最小的类,若其小于给定阈值δ,则认为数据点e属于该类,加入该类中;若数据点e未找到任何符合的类,则认定其为离群点,将其作为单独的一个类。计算分形影响度的公式为:式(2)中,表示第i个聚类成员的第k个簇的分形影响度,表示第i个聚类成员的第k个簇的分形维数,表示第i个聚类成员的第k个簇加入数据点e后的分形维数。利用互信息计算每个聚类成员的权值:计算互信息的公式为:式(3)中,λp和λq表示聚类成员,p,q为整数,且1≤p,q≤h,n表示数据集大小,k表示聚类的簇数,ni表示聚类成员λp中属于第i个簇的数据点的数量,nj表示聚类成员λq中属于第j个簇的数据点的数量,nij表示聚类成员λp中第i个簇和聚类成员λq中第j个簇之间所含有的相同数据点的数量。计算三组聚类成员之间的互信息结果如下表4所示,表4三个聚类成员之间的互信息值表聚类成员123100.52860.474620.528600.665230.47460.66520计算平均互信息的公式为:式(4)中,αi表示第i个聚类成员的平均互信息。计算聚类成员的权值的公式为:式(5)中,ωi满足ωi>0(i=1,2,...,h)且计算三个聚类成员所得平均互信息及其权值大小如下表5:表5三个聚类成员的平均互信息及其权值的计算所得值表α(平均互信息)0.33440.39790.3799ω(权值)0.36760.30890.3235选择符合条件的聚类成员,当聚类成员的权值小于给定阈值μ时,舍弃,留下权值大于μ的聚类成员,得到部分聚类成员λ'={λ1',λ2',...,λi',...,λ'h}。由表5结果可知,将选择第一个聚类成员作为最终进行统计的聚类结果,对每个聚类成员的聚类结果进行按类统计,形成待发布分组,计算所得统计结果为:[35,59,56]。对分组进行拉普拉斯加噪:对每个聚类成员的每个簇进行拉普拉斯加噪,采用直方图发布方法发布数据时,其查询敏感度为1,故而添加1/ε的拉普拉斯噪声即可满足ε的差分隐私,其中ε表示隐私预算,得到每个聚类成员加入噪声干扰的数据:并发布加噪后的分组数据。如表6所示:添加不同隐私预算所得到的加噪数据是不一样的,隐私预算的取值越接近1,隐私保护的效果越差,但数据的可用型较强,取值越接近0,隐私保护的效果越好,但数据的可用性会有所降低。表6不同隐私预算取值对比表原始统计数据隐私预算取值0.1隐私预算取值0.5隐私预算取值0.93539.136.633.75952.359.257.75656.25955.1步骤四:当某个聚类成员的分组数据的数量达到与滑动窗口大小差不多时,滑动窗口向前平移,重复步骤三。对比使用k-means聚类算法及使用本发明中所提及的聚类方法对iris数据集的聚类结果对比如下表7:表7不同聚类方式的准确性和误差对比表k-means分形聚类基于互信息的分形聚类聚类准确性0.52670.53330.8667聚类误差163.2624199.7899143.4537说明本发明方法可有效提升聚类效果,对后续为聚类分析结果进行差分隐私加噪具有重大帮助。以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1