一种基于K-means++结合肘部法自主聚类技术的动态数据差分隐私直方图发布方法与流程
本发明涉及动态数据隐私处理技术领域,具体来说是一种基于k-means++结合肘部法自主聚类技术的动态数据差分隐私直方图发布方法。
背景技术:
随着社会信息化和网络化程度的不断提高,以及云计算、物联网等新兴技术的融合发展,各行各业产生的数据量呈爆炸式增长,一个大规模生产、分享和应用数据的时代已经悄然而至,数据已然成为促进社会发展至关重要的基础资源。然而,数据集里通常包含着大量个人隐私信息,这些信息随着数据集的发布和共享而存在被泄露的风险。近年来,数据泄露事件频繁发生,用户和企业各类信息安全饱受侵扰,不仅造成经济和名誉上损失,还极大形成了潜在的隐患并阻碍了社会的发展。因此,数据安全问题已成为必须面对和急需解决的问题,而大数据安全和隐私保护也将逐渐上升至国家战略层面。
传统的数据安全隐私保护方法,如匿名化方法(sweeneyl.k-anonymity:amodelforprotectingprivacy.internationaljournalofuncertainty,fuzzinessandknowledge-basedsystems,2002,10(5):557-570)能够在一定程度上保护个人隐私,但是远不足以保证隐私信息的安全。而差分隐私技术能够解决传统隐私保护方法的两个缺陷:首先,差分隐私技术(dworkc.differentialprivacy//proceedingsofthe33rdinternationalcolloquiumonautomata,languagesandprogramming.venice,italy,2006:1-12)无需考虑攻击者所拥有的任何可能的背景知识并完成有效的数据隐私保护;其次,它建立在坚实的数学基础之上,对隐私保护进行了严格的定义并提供了量化评估方法。因此,差分隐私理论迅速被业界认可,并逐渐成为隐私保护领域的一个研究热点。
差分隐私数据发布所关注的重点在于如何在保证数据隐私的前提下尽可能地保证数据的可用性。目前,采用比较多的发布方式主要有采样-过滤发布(chanth,shie,songd.privateandcontinualreleaseofstatistics[j].acmtransactionsoninformation&systemsecurity,2011:14(3):1-24.)、直方图发布(acsg,castellucciac,chenr.differentiallyprivatehistogrampublishingthroughlossycompression[c].ieeeinternationalconferenceondatamining.2013.)、划分发布(dworkc,naorm,pitassit,etal.differentialprivacyundercontinualobservation.[j].stoc,2010:715-724.)、以及泛化发布技术(fangc,changec.differentialprivacywithδ-neighbourhoodforspatialanddynamicdatasets[c].acmsymposiumoninformation,computerandcommunicationssecurity.acm,2014:159-170.)等,其中,直方图发布技术是目前应用比较广泛的一种数据发布方法。
现有差分隐私直方图发布方法的研究大多关注静态数据集的发布问题,然而研究表明,当前社会对数据的动态发布需求更为强烈。而且,静态数据的差分隐私发布方法无法应用于动态数据的发布。
因此,针对动态数据的统计发布的需求和特点,目前的差分隐私直方图发布方法仍存在一定的缺点和不足,例如张啸剑等人提出的一种流式直方图发布方法(张啸剑,孟小峰.基于差分隐私的流式直方图发布方法[j].软件学报,2016,27(2):381-393.)并不能启发式地发布直方图,yan等提出的分形维数聚类方法(yanf,zhangx,lic,etal.differentiallyprivatehistogrampublishingthroughfractaldimensionfordynamicdatasets[c].201813thieeeconferenceonindustrialelectronicsandapplications(iciea)1542-1546.)可以启发式发布直方图,但是未能自动确定k-means聚类最优k值,影响了数据可用性和发布效率。
传统肘部法通过对图形的观察获取最优k值,无法自动获取,而吴广建等人提出k-means聚类自动获取最优k值的方法(吴广建,章剑林,袁丁.基于k-means的手肘法自动获取k值方法研究[j].软件,2019,040(005):167-170.)需根据数据集特征人为设定k值范围,这造成其自动化程度差且聚类次数较多,算法复杂度较高。因此需要一种针对动态数据的差分隐私直方图方法,不但可以启发式地发布直方图,而且可以在保证数据隐私的前提下改善数据的可用性,并具有较高的发布效率,使得数据发布达到更加安全、可行和智能的目的。
技术实现要素:
本发明的目的是为了解决现有技术中无法启发式地发布直方图、隐私数据可用性低、发布效率低的缺陷,提供一种基于k-means++结合肘部法自主聚类技术的动态数据差分隐私直方图发布方法来解决上述问题。
为了实现上述目的,本发明的技术方案如下:
一种基于k-means++结合肘部法自主聚类技术的动态数据差分隐私直方图发布方法,包括以下步骤:
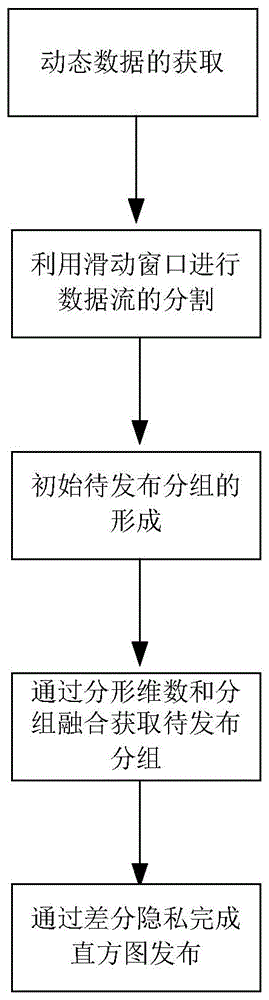
动态数据的获取:获取待进行差分隐私直方图处理的动态数据流;
利用滑动窗口进行数据流的分割:将一个长度为t的动态数据流分割成t个时间戳上的数据点,即d={x1,x2,…xt},将数据流以静态方式展示在窗口中,随着数据的流入,数据量达到窗口大小时,窗口向前平移进行分割,形成窗口数据;
初始待发布分组的形成:通过肘部法利用相邻斜率比自动获取最优k值的k-means++聚类方法对初始窗口数据进行聚类,形成初始待发布分组h={c1,c2,…,ck};
通过分形维数和分组融合获取待发布分组:对k-means++聚类后形成的初始待发布分组进行分形维数计算,通过分形影响度对新数据分类,再通过分组融合获得待发布分组hd={c’1,c’2,…,c’p};
通过差分隐私完成直方图发布:对待发布分组添加laplace噪声,发布动态数据差分隐私直方图hl={c’l1,c’l2,…,c’ln}。
所述初始待发布分组的形成包括以下步骤:
依次设置聚类个数即k值,k=1,2,3…n;
从窗口内数据中随机选取一个点作为初始聚类的中心c1;
计算每个样本xi与已有聚类中心点的距离d(x);
根据d(x)计算每个样本点被选取作为下一个聚类中心的概率,用轮盘法选出下一个聚类中心;
直到选择出k个聚类中心点;
通过k-means++迭代输出每个k的聚类结果;
对每一个k值聚类记下对应的误差平方和sse,并画出k和sse的关系图;
记录各点的坐标(xi,yi),计算k和sse的关系图中各点间的斜率;
设k=1的点和k=2的点之间的斜率
若出现斜率比ri小于阈值d,则k停止迭代,选择其图形肘部点作为最优k值;
通过获取的最优k值选择对应的聚类结果,形成初始待发布分组h={c1,c2,…,ck}。
所述通过分形维数和分组融合获取待发布分组包括以下步骤:
计算初始待发布分组h={c1,c2,…,ck}中每个桶ci的分形维数di,ci包含若干个数据点,桶数即肘部法自动获取的最优聚类个数k;
将新流入的数据点e加入到初始发布分组中的每个桶中,计算加入数据点后每个桶的分形维数d’i;
并计算其分形影响度vi=|d’i-di|;
若加入e后分形影响度vi最小,则e属于该桶,并从其余桶中删除数据点e;
采用相似桶融合并求均值,以融合桶的均值作为新的统计结果:c’=(ci+ci+1)/2;获得待发布分组hd={c’1,c’2,…,c’p}。
有益效果
本发明的一种基于k-means++结合肘部法自主聚类技术的动态数据差分隐私直方图发布方法,与现有技术相比解决了启发式发布直方图的缺陷,优化了分组结果,提高了发布效率,可保证动态数据隐私安全同时降低发布误差,改善数据可用性;使得动态数据的差分隐私直方图发布更加安全、可用、高效且智能。
本发明通过肘部法自动选择最优k值的k-means++聚类方法对窗口内数据进行聚类,获取最优的簇数量即k值,优化直方图初始桶数;将k-means++聚类后的结果形成的初始待发布分组,结合分形维数和分组融合,通过laplace加噪完成动态数据的差分隐私直方图发布。
同时,本发明还具备以下优点为:
1、本发明通过k-means++对窗口内数据进行初始聚类,与现有技术相比可降低滑动窗口内数据的聚类误差,在保证数据隐私的前提下改善数据的可用性,同时运行时间短,可提高数据发布效率。
2、本发明通过计算相邻斜率比自动获取图形工具肘中的最优k值,并运用到k-means++聚类中,与现有技术相比解决了聚类个数选择问题,自动获取聚类中最优的簇数量,优化了直方图发布的初始桶个数,降低了直方图离群点问题,使得差分隐私直方图发布更加智能、安全且高效。
3、本发明通过k-mean++聚类算法和分形维数结合,并利用分组融合和laplace加噪完成对动态数据的差分隐私直方图发布,与现有技术相比提高了新数据流入后分类的准确性,在保证数据隐私性前提下降低了总体误差,提高了数据可用性。
附图说明
图1为本发明的方法顺序图;
图2为本发明中聚类个数k与误差平方和sse关系图;
图3为三种聚类方法在发布数据集上的聚类误差平方和对比图;
图4为三种聚类方法在发布数据集上的聚类运行时间对比图;
图5为本发明各种动态数据差分隐私直方图发布方法的负载误差对比图;
图6为本发明中各种动态数据差分隐私直方图发布方法的负载误差对比图。
具体实施方式
为使对本发明的结构特征及所达成的功效有更进一步的了解与认识,用以较佳的实施例及附图配合详细的说明,说明如下:
如图1所示,本发明所述的一种基于k-means++结合肘部法自主聚类技术的动态数据差分隐私直方图发布方法,包括以下步骤:
第一步,动态数据的获取:获取待进行差分隐私直方图处理的动态数据流。
第二步,利用滑动窗口进行数据流的分割:将一个长度为t的动态数据流分割成t个时间戳上的数据点,即d={x1,x2,…xt},将数据流以静态方式展示在窗口中,随着数据的流入,数据量达到窗口大小时,窗口向前平移进行分割,形成窗口数据。
第三步,初始待发布分组的形成。初始待发布分组的确定是保证最终直方图安全发布的关键,如何快速确定初始桶数并获得最优的分组结果是初始直方图形成的核心问题,传统的k-means聚类虽然可启发式形成初始分组,但其聚类精度不高且效率低影响最终直方图发布,其核心问题在于初始聚类中心选择存在缺陷,而通过初始聚类中心距离优化其选择的k-means++聚类可大大提升初始分组结果和效率,在此基础上更为重要的是,如何准确且快速地自动获取其最优聚类个数(k值、初始桶数)是急需解决的问题,因此本发明通过肘部法利用相邻斜率比自动获取最优k值的k-means++聚类方法对初始窗口数据进行聚类,形成初始待发布分组h={c1,c2,…,ck}。其具体步骤如下:
(1)依次设置聚类个数即k值,k=1,2,3…n;
(2)从窗口内数据中随机选取一个点作为初始聚类的中心c1;
(3)计算每个样本xi与已有聚类中心点的距离d(x);
计算每个样本点被选取作为下一个聚类中心的概率
直到选择出k个聚类中心点;
(4)通过k-means++迭代输出每个k的聚类结果;
(5)对每一个k值聚类记下对应的误差平方和sse,并画出k和sse的关系图;
(6)记录各点的坐标(xi,yi),计算k和sse的关系图中各点间的斜率;
设k=1的点和k=2的点之间的斜率
若出现斜率比ri小于阈值d,则k停止迭代,选择其图形肘部点作为最优k值;
(7)通过获取的最优k值选择对应的聚类结果,形成初始待发布分组h={c1,c2,…,ck}。
第四步,通过分形维数和分组融合获取待发布分组。由于现今需处理的数据规模越来越大,加上数据流的动态性,势必增加聚类的运行代价,因此通过先部分数据聚类再对新增数据分类的方式可有效降低运算开销,而对于新增数据的分类,传统的通过距离方式无法反映数据集的真实特征导致发布误差,而分形维数可判断其数据自相似性,其不受任何聚类形状的限制,且能够处理数据集内部密度不均匀的情况,随着数据点的加入,可动态描述数据集的特性。因此对kmeans++聚类后形成的初始待发布分组进行分形维数计算,通过分形影响度对新数据分类;为进一步降低发布误差进而优化分组,因此通过分组融合获得待发布分组hd={c’1,c’2,…,c’p}。其具体步骤如下:
(1)计算初始待发布分组h={c1,c2,…,ck}中每个桶ci的分形维数di,ci包含若干个数据点,桶数即肘部法自动获取的最优聚类个数k;
(2)将新流入的数据点e加入到初始发布分组中的每个桶中,c’i=ci∪e(i=1,2,..,k),计算加入数据点后每个桶的分形维数d’i;
并计算其分形影响度vi=|d’i-di|;
若加入e后分形影响度vi最小,则e属于该桶,即e∈ci,并从其余桶中删除数据点e;
(3)采用相似桶融合并求均值,以融合桶的均值作为新的统计结果:c’=(ci+ci+1)/2;获得待发布分组hd={c’1,c’2,…,c’p}。
第四步,通过差分隐私完成直方图发布:对待发布分组添加laplace噪声,发布动态数据差分隐私直方图hl={c’l1,c’l2,…,c’ln}。
在此,以实验硬件平台为:intel(r)core(tm)i5-8250ucpu@1.60ghz1.80ghz,8.0gb。实验环境是win10操作系统下的python3.5.1以及matlabr2017a.实验数据为实验数据集选取了公开数据集:美国统计数据adultdataset。
以图2为例,以100个数据点的窗口内进行k-means++聚类,计算相邻斜率比选择出k=3为最优聚类个数,从而设定其为初步桶的数量。以图3和图4为例,其中发布数据分别选取100、150、200、250和300个静态数据点,k-means++,k-means,二分k-means三种针对统计数据的聚类算法。在以100到300个数据点的窗口内进行聚类比较,k-means++在此数据集上聚类的误差平方和(sse)和运行时间均为最优。
以图5图6为例,图5中对比方法分别为基于滑动窗口的等宽直方图发布方法,基于k-means的分形维数差分隐私发布方法,以及基于二分k-means的分形维数差分隐私发布方法,参数隐私预算设置为0.5-1.5;图6中对比方法分别为基于滑动窗口的等宽直方图发布方法,基于k-means的分形维数差分隐私发布方法,以及基于二分k-means的分形维数差分隐私发布方法,参数滑动窗口大小设置为100-300。
本发明比较基于滑动窗口的等宽直方图发布方法,基于k-means的分形维数差分隐私发布方法,以及基于二分k-means的分形维数差分隐私发布方法,显示本发明在不同隐私预算和不同滑动窗口的情况下负载误差最低,验证其方法对于保证其数据可用性效果最优。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
- 还没有人留言评论。精彩留言会获得点赞!