一种带起重机的分布式柔性车间调度方法及系统与流程
[0001]
本发明涉及生产调度技术领域,尤其涉及一种带起重机的分布式柔性车间调度方法及系统。
背景技术:
[0002]
随着制造全球化的发展,单个工厂的生产模式已经逐渐被多工厂生产结构所取代。在分布式柔性车间问题(dfjsp)中,每个工厂里是一个柔性车间调度问题。对于不同的制造系统,如设备制造、化工原料生产、手机装配等,都能够建模为dfjsp。在加工系统中,最大完工时间(makespan)是一个重要的优化目标。然而,总能量消耗(tec)在绿色制造中是较为关键的部分。在djfpsc中,需要解决三个子问题。首先,所有的工件需要被分配到各个工厂中。然后,在每个工厂中,需要确定工序的加工顺序,以及需要确定每一个加工工序的加工机器。柔性车间调度问题是np难问题,因此djfpsc也是np难问题。
[0003]
在分布式调度问题中已有关于起重机或机器人运输的限制。li等人为解决dpfsp提出了改进的ig算法,其中每个工厂都有起重机在机器之间运送工件,起重机运输时间也包括在了makespan之内。在现有技术中的模型考虑了运输时间,并且放入每个工件最后一个工序的加工之间之内。liu等学者针对柔性作业车间和起重机运输提出了一个新颖的混合绿色调度问题,其中把起重机运输过程分成了不同的四类。dai等人提出了一个改进的ga来解决考虑能量优化目标和运输约束的柔性作业车间调度问题。ham针对多机器人的柔性作业车间调度问题提出了cp模型,其中优化目标是makespan。li等学者针对柔性作业车间调度问题提出了一个混合迭代贪婪模型,考虑了起重机运输的抬升过程。另外,li等人设计一个改进的jaya算法,应用于考虑运输和设定时间约束的柔性作业车间调度问题。li等学者提出了一个有效的多目标算法来解决多流股的混合流水调度问题。对于柔性任务调度问题,li等人设计了一个混合多目标人工蜂群算法模型应用于云计算系统,并且这个算法在解决车辆路径规划问题也有较好的表现。
[0004]
在柔性车间调度问题和车间调度问题中,起重机和机器人运输约束的研究主题较为活跃。然而发明人发现,实际的生产调度过程并不能完全满足工件加工计划,带起重机或机器人运输约束的分布式调度问题并没有得到实质性解决。
技术实现要素:
[0005]
针对现有技术存在的不足,本发明的目的是提供一种带起重机的分布式柔性车间调度方法及系统,能够达到最小化最大完成时间和总能量消耗的目的,提高了工件加工及运输效率。
[0006]
为了实现上述目的,本发明是通过如下的技术方案来实现:
[0007]
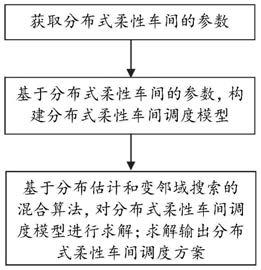
第一方面,本发明的实施例提供了一种带起重机的分布式柔性车间调度方法,包括:
[0008]
获取分布式柔性车间的参数,所述参数包括工厂数量、工件数量、工厂中机器数
量、工序数量、起重机位置坐标;
[0009]
基于分布式柔性车间的参数,构建带起重机的分布式柔性车间调度模型;所述带起重机的分布式柔性车间调度模型包括目标函数和约束条件;
[0010]
基于分布估计和变邻域搜索的混合算法,对带起重机的分布式柔性车间调度模型进行求解;求解输出分布式柔性车间调度方案。
[0011]
作为进一步的实现方式,所述目标函数指最小化最大完成时间和总能量消耗;
[0012]
约束条件是指:在零时刻所有工件都可加工,且所有机器都进入可以加工工件的状态;起重机和所有机器的工作状态是持续的,在加工和搬运过程中不能被强制关闭;每个工序一旦开始加工不允许被打断;所有工序都只能由一台机器加工;一台机器依次加工工件,在加工工件的同时不能加工其他工件;在每个工厂中,起重机只能一次搬运一个工件;
[0013]
在每个工厂中,起重机初始位置位于本工厂第一个工序的加工机器位置;起重机的载重运输过程必须在目标位置的所在机器处于空闲状态时才能进行;在每个工厂中,所有工件的第一个加工工序不需要起重机搬运;在每个工厂中,如果一个工序的加工位置和此工件的前序加工位置是相同的,那么这个工序不需要起重机搬运;一旦工件被分配到工厂中加工,则不会被分配到其他工厂加工。
[0014]
作为进一步的实现方式,根据起重机位置、工序加工位置以及相同工件的前序工序加工位置关系,所有起重机状态被分成空载运输、空载等待、载重等待和载重运输四种。
[0015]
作为进一步的实现方式,总能量消耗包括机器加工的能量消耗、起重机运输的总能量消耗,其中,机器加工的能量消耗为所有工序的能量消耗总和;起重机运输的总能量消耗为四种起重机状态的能量消耗总和。
[0016]
作为进一步的实现方式,在分布估计和变邻域搜索的混合算法中,在分布估计算法部分,参数被设定为自适应,以避免运行过程中过早收敛;在变邻域搜索部分,设置五种针对分布式柔性车间调度问题的邻域结构来寻找满意解。
[0017]
作为进一步的实现方式,在分布估计算法部分,根据个体在种群中的适应度选择优秀的个体来产生新的个体,并替换到种群中相同数量的较差个体;迭代过程中,将概率矩阵更新的过程设定为自适应过程。
[0018]
作为进一步的实现方式,所述邻域结构包括局部交换邻域结构、局部插入邻域结构、局部移动邻域结构、全局移动邻域结构、全局交换邻域结构;在变邻域搜索部分的每次迭代中,只采用一个邻域结构生成新的个体。
[0019]
第二方面,本发明实施例还提供了一种带起重机的分布式柔性车间调度系统,包括:
[0020]
参数获取模块,被配置为:获取分布式柔性车间的参数;所述参数包括工厂数量、工件数量、工厂中机器数量、工序数量、起重机位置坐标;
[0021]
模型构建模块,被配置为:基于分布式柔性车间的参数,构建带起重机的分布式柔性车间调度模型;所述带起重机的分布式柔性车间调度模型包括目标函数和约束条件;
[0022]
输出模块,被配置为:基于分布估计和变邻域搜索的混合算法,对带起重机的分布式柔性车间调度模型进行求解;求解输出分布式柔性车间调度方案。
[0023]
第三方面,本发明实施例还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现所述的带起重
机的分布式柔性车间调度方法。
[0024]
第四方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现所述的带起重机的分布式柔性车间调度方法。
[0025]
上述本发明的实施例的有益效果如下:
[0026]
(1)本发明的一个或多个实施方式提出了一个包含分布估计算法和变邻域搜索算法的混合算法来解决带起重机运输过程的dfjsp,能够提高工件的加工及运输效率;
[0027]
(2)本发明的一个或多个实施方式在起重机运输中,设计了一个包含四种起重机运输状态的判别规则来计算运输过程部分;同时提出了带起重机运输的dfjsp的约束规划模型;
[0028]
(3)本发明的一个或多个实施方式在分布估计算法部分,参数被设定为自适应,能够使得算法在运行过程中避免过早收敛的情况,因此模型具有稳定收敛的特性,具有较好的探索能力。在变邻域搜索部分,设计了五种针对dfjsp的邻域结构来寻找满意解。
附图说明
[0029]
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
[0030]
图1是本发明根据一个或多个实施方式的流程图;
[0031]
图2是本发明根据一个或多个实施方式的工厂中起重机状态的判别规则;
[0032]
图3是本发明根据一个或多个实施方式的工厂中的起重机系统示意图;
[0033]
图4是本发明根据一个或多个实施方式的针对dfjspc所提出的算法eda-vns框架;
[0034]
图5是本发明根据一个或多个实施方式的解的结构和编码示意图;
[0035]
图6是本发明根据一个或多个实施方式的在dfjspc中解的甘特图;
[0036]
图7是本发明根据一个或多个实施方式的局部交换邻域结构;
[0037]
图8是本发明根据一个或多个实施方式的局部插入邻域结构;
[0038]
图9是本发明根据一个或多个实施方式的局部移动邻域结构;
[0039]
图10是本发明根据一个或多个实施方式的全局移动邻域结构;
[0040]
图11是本发明根据一个或多个实施方式的全局交换邻域结构;
[0041]
图12(a)-图12(e)是本发明根据一个或多个实施方式的混合算法参数的因素水平趋势;
[0042]
图13是本发明根据一个或多个实施方式的不同权重下makespan和tec的关系;
[0043]
图14是本发明根据一个或多个实施方式的eda-vns与其他对比算法的收敛曲线;
[0044]
图15(a)是本发明根据一个或多个实施方式的自适应过程比较;
[0045]
图15(b)是本发明根据一个或多个实施方式的探索能力比较;
[0046]
图15(c)是本发明根据一个或多个实施方式的挖掘能力比较;
[0047]
图15(d)是本发明根据一个或多个实施方式的对比算法的anova分析;
[0048]
图16是本发明根据一个或多个实施方式的算法和对比算法的makespan和tec关系;
[0049]
图17是本发明根据一个或多个实施方式的eda-vns优化后的算例20j3f5m的结果。
具体实施方式
[0050]
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
[0051]
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
[0052]
术语解释:
[0053]
dfjsp:分布式柔性车间调度问题;
[0054]
dfjspc:带起重机的分布式柔性车间调度问题;
[0055]
makespan:最大完工时间;
[0056]
eda:分布估计算法;
[0057]
vns:变邻域搜索。
[0058]
实施例一:
[0059]
本发明的实施例提供了一种带起重机的分布式柔性车间调度方法,如图1所示,包括:
[0060]
获取分布式柔性车间的参数,所述参数包括工厂数量、工件数量、工厂中机器数量、工序数量、起重机位置坐标;
[0061]
基于分布式柔性车间的参数,构建带起重机的分布式柔性车间调度模型;所述带起重机的分布式柔性车间调度模型包括目标函数和约束条件;
[0062]
基于分布估计和变邻域搜索的混合算法,对带起重机的分布式柔性车间调度模型进行求解;求解输出分布式柔性车间调度方案。
[0063]
具体的,在dfjspc环境中,i个工件必须分配到f个工厂中。对于每个工件,有一个或多个工序按照顺序进行加工,并且工件的所有工序都要在所指定的工厂内加工。工序o
i,j
的加工机器为所有机器的一个子集。在每个工厂中,都有一个起重机来运送工件在不同机器之间加工。除了考虑机器加工过程的时间和能量消耗,起重机运输过程的时间和能量消耗也考虑在内。
[0064]
在本实施例中,涉及的符号及参数含义为:
[0065]
f:工厂编号,i:工件编号,j:工序编号,k:所有工厂中的机器编号,f:工厂数量,i:工件数量,j:工序数量,k:所有工厂中的机器数量;o
i,j
:工件i的第j个工序,k’:后续工序的加工机器,k(o
i,j
):工序o
i,j
的加工机器,当k≠δ
i
时为0,ts(o
i,j
):工序o
i,j
的加工开始时间,tc(o
i,j
):工序o
i,j
的加工结束时间,p(π
i
):起重机的初始位置,δ
i
:第i个工序的机器位置;x
op
:工序加工位置的x坐标,x
cp
:起重机位置的x坐标,x
pp
:工件的前序工序位置的x坐标,y
op
:工序加工位置的y坐标,y
cp
:起重机位置的y坐标,y
pp
:工件的前序工序位置的y坐标;
[0066]
t
xnos,f
(o
i,j
):工厂f中,工序o
i,j
空载运输过程的启动时间的x坐标,t
xnob,f
(o
i,j
):工厂f中,工序o
i,j
空载运输过程的停止时间的x坐标,t
xnod,f
(o
i,j
):工厂f中,工序o
i,j
空载运输过程的进行时间的x坐标,t
xlos,f
(o
i,j
):工厂f中,工序o
i,j
载重运输过程的启动时间的x坐标,t
xlob,f
(o
i,j
):工厂f中,工序o
i,j
载重运输过程的停止时间的x坐标,t
xlod,f
(o
i,j
):工厂f
中,工序o
i,j
载重运输过程的进行时间的x坐标,t
ynos,f
(o
i,j
):工厂f中,工序o
i,j
空载运输过程的启动时间的y坐标,t
ynob,f
(o
i,j
):工厂f中,工序o
i,j
空载运输过程的停止时间的y坐标,t
ynod,f
(o
i,j
):工厂f中,工序o
i,j
空载运输过程的进行时间的y坐标,t
ylos,f
(o
i,j
):工厂f中,工序o
i,j
载重运输过程的启动时间的y坐标,t
ylob,f
(o
i,j
):工厂f中,工序o
i,j
载重运输过程的停止时间的y坐标,t
ylod,f
(o
i,j
):工厂f中,工序o
i,j
载重运输过程的进行时间的y坐标;t
no,f
(o
i,j
):工厂f中,工序o
i,j
空载运输过程的时间消耗,ts
no,f
(o
i,j
):工厂f中,工序o
i,j
空载运输过程的开始时间,tc
no,f
(o
i,j
):工厂f中,工序o
i,j
空载运输过程的结束时间,t
ns,f
(o
i,j
):工厂f中,工序o
i,j
空载等待过程的时间消耗,ts
ns,f
(o
i,j
):工厂f中,工序o
i,j
空载等待过程的开始时间,tc
ns,f
(o
i,j
):工厂f中,工序o
i,j
空载等待过程的结束时间,t
ls,f
(o
i,j
):工厂f中,工序o
i,j
载重等待过程的时间消耗,ts
ls,f
(o
i,j
):工厂f中,工序o
i,j
载重等待过程的开始时间,tc
ls,f
(o
i,j
):工厂f中,工序o
i,j
载重等待过程的结束时间,t
lo,f
(o
i,j
):工厂f中,工序o
i,j
载重运输过程的时间消耗,ts
lo,f
(o
i,j
):工厂f中,工序o
i,j
载重运输过程的开始时间,tc
lo,f
(o
i,j
):工厂f中,工序o
i,j
载重运输过程的结束时间;
[0067]
t
no
:dfjspc中,所有空载运输过程的时间,t
ns
:dfjspc中,所有空载等待过程的时间,t
ls
:dfjspc中,所有载重等待过程的时间,t
lo
:dfjspc中,所有载重运输过程的时间,e
no
(o
i,j
):工序o
i,j
的空载运输能耗,e
ns
(o
i,j
):工序o
i,j
的空载等待能耗,e
ls
(o
i,j
):工序o
i,j
的载重等待能耗,e
lo
(o
i,j
):工序o
i,j
的载重运输能耗,e
no
:dfjspc中,所有空载运输过程的能耗,e
ns
:dfjspc中,所有空载等待过程的能耗,e
ls
:dfjspc中,所有载重等待过程的能耗,e
lo
:dfjspc中,所有载重运输过程的能耗;ws:抬升设备的重量,wx:横向移动设备的重量,wy:纵向移动设备的重量,wj:工件i的重量,qn:起重机的抬升物重量,tec
mp
:所有机器加工过程的总能耗,tec
ct
:所有起重机搬运过程的总能耗,tec:dfjspc中所有的能耗;ψ(o
i,j
):工序o
i,j
的可加工机器集合,θ<o
i1,j1
,o
i,j
>:工序o
i1,j1
的后续工序o
i,j
在同一台机器上加工的关系参数。
[0068]
假设:
[0069]
·
所有安排的工序在dfjspc中必须全部完成,且在每个工厂内,工序的加工要严格按照所安排的顺序加工。
[0070]
·
在零时刻,所有的工件都可加工,且所有的机器都进入可以加工工件的状态。
[0071]
·
起重机和所有的机器的工作状态是持续的,在加工和搬运过程中不能被强制关闭。
[0072]
·
每个工序一旦开始加工不允许被打断,必须等待其加工完成。
[0073]
·
所有的工序都只能由一台机器加工,在加工过程中不能同时被其他机器加工。
[0074]
·
一台机器依次加工工件,在加工工件的同时不能加工其他工件。
[0075]
·
在每个工厂中,起重机只能一次搬运一个工件,在搬运工件的过程中不能搬运其他工件。
[0076]
·
在每个工厂中,起重机的初始位置位于本工厂的第一个工序的加工机器位置上。
[0077]
·
处于安全考虑,起重机的载重运输过程必须在目标位置的所在机器处于空闲状态时才能进行。
[0078]
·
在每个工厂中,所有的工件的第一个加工工序不需要起重机搬运。
[0079]
·
在每个工厂中,如果一个工序的加工位置和此工件的前序加工位置是相同的,那么这个工序不需要起重机搬运。
[0080]
·
一旦工件被分配到工厂中加工,则不会被分配到其他工厂加工。
[0081]
机器加工的能量消耗:
[0082]
工序o
i,j
的能量消耗是e
mp
(o
i,j
),通过式(1)计算:
[0083]
e
mp
(o
i,j
)=e
i,j
·
t
i,j
ꢀꢀꢀ
(1)
[0084]
其中e
i,j
和t
i,j
分别是工序o
i,j
的单位能量消耗和加工时间。
[0085]
在所有的工厂中,机器加工的总能量消耗tec
mp
是所有e
mp
(o
i,j
)的总和,通过式(2)计算:
[0086][0087]
(1)起重机运输过程的能量消耗:
[0088]
在所有工厂中,工件在不同机器之间的所有移动过程都通过起重机运输来实现。根据起重机的位置、工序加工位置、以及相同工件的前序工序加工位置关系,所有的起重机状态可以被分成如下四类:空载运输、空载等待、载重等待、载重运输。在每个工厂中,起重机的状态遵循如图2所示的判别规则。
[0089]
在所有工厂中,起重机沿着x方向和y方向移动,不可以沿着对角线方向移动。如图3所示,起重机包括龙门架和吊运车,龙门架沿着x方向移动,吊运车沿着y方向移动。吊运车的移动轨道在龙门架上。对于x方向上的移动,移动的部分包括起重机的抬升设备、龙门架和吊运车。对于y方向上的移动,移动的部分包括起重机的抬升设备和吊运车。
[0090]
(2)空载运输状态的时间和能量消耗:
[0091]
如果工件i被分配到了工厂f中加工,且工序o
i,j
有空载运输状态,则x方向的移动时间由式(3)
–
式(6)计算,y方向的移动时间由式(7)
–
(10)计算。工序o
i,j
的总时间消耗和tec分别由式(11)和式(12)计算。在dfjspc中所有空载运输状态的tec(e
no
)是所有工厂中所有工序的空载运输状态e
no,f
(o
i,j
)的总和。
[0092][0093][0094][0095][0096][0097][0098]
[0099][0100]
t
no,f
(o
i,j
)=t
xnos,f
(o
i,j
)+t
xnob,f
(o
i,j
)+t
xnod,f
(o
i,j
)+t
ynos,f
(o
i,j
)+t
ynob,f
(o
i,j
)+t
ynod,f
(o
i,j
)
ꢀꢀꢀ
(11)
[0101][0102]
(3)空载等待状态的时间和能量消耗:
[0103]
如果工件i被分配到了工厂f中加工,且工序o
i,j
有空载等待状态,则工序o
i,j
的空载等待的时间消耗由式(13)计算,空待等待的能量消耗由式(14)计算。在dfjspc中所有空载等待状态的tec(e
ns
)是所有工厂中所有工序的空载等待状态e
ns,f
(o
i,j
)的总和。
[0104]
t
ns,f
(o
i,j
)=max{tc(o
i,j-1
)-t
no,f
(o
i,j
),0}
ꢀꢀꢀ
(13)
[0105]
e
ns,f
(o
i,j
)=t
ns,f
(o
i,j
)
·
ps
ꢀꢀꢀ
(14)
[0106]
(4)载重等待状态的时间和能量消耗:
[0107]
如果工件i被分配到了工厂f中加工,且工序o
i,j
有载重等待状态,则工序o
i,j
的载重等待的时间消耗由式(15)计算,载重等待的能量消耗由式(16)计算。在dfjspc中所有载重等待状态的tec(e
ls
)是所有工厂中所有工序的载重等待状态e
ls,f
(o
i,j
)的总和。
[0108]
t
ls,f
(o
i,j
)=max{tc(o
i1,j1
)-t
ns,f
(o
i,j
),0}
ꢀꢀꢀ
(15)
[0109]
e
ls,f
(o
i,j
)=t
ls,f
(o
i,j
)
·
ps
ꢀꢀꢀ
(16)
[0110]
(5)载重运输状态的时间和能量消耗:
[0111]
如果工件i被分配到了工厂f中加工,且工序o
i,j
有载重运输状态,则x方向的移动时间由式(17)
–
式(20)计算,y方向的移动时间由式(21)
–
(24)计算。工序o
i,j
的总时间消耗和tec分别由式(25)和式(26)计算。在dfjspc中所有载重运输状态的tec(e
lo
)是所有工厂中所有工序的载重运输状态e
lo,f
(o
i,j
)的总和。
[0112][0113][0114][0115][0116][0117][0118][0119][0120]
t
lo,f
(o
i,j
)=t
xlos,f
(o
i,j
)+t
xlob,f
(o
i,j
)+t
xlod,f
(o
i,j
)+t
ylos,f
(o
i,j
)+t
ylob,f
(o
i,j
)+
t
ylod,f
(o
i,j
)
ꢀꢀꢀ
(25)
[0121][0122]
(6)起重机运输的总能量消耗:
[0123]
起重机的tec是上述四种起重机状态的能量消耗总和,由式(27)计算。dfjspc的tec由式(28)计算。
[0124]
tec
ct
=e
no
+e
ns
+e
ls
+e
lo
ꢀꢀꢀ
(27)
[0125]
tec=tec
mp
+tec
ct
ꢀꢀꢀ
(28)
[0126]
带起重机的分布式柔性车间调度模型由式(29)
–
(50)表达如下:
[0127]
minf=w
·
f1+(1-w)
·
f2ꢀꢀꢀ
(29)
[0128]
f1=max{tc(o
i,j
)}
ꢀꢀꢀ
(30)
[0129]
f2=tec
ꢀꢀꢀ
(31)
[0130][0131][0132][0133][0134][0135][0136][0137][0138][0139][0140][0141][0142][0143][0144][0145][0146][0147][0148]
[0149]
所提模型的总目标为式(29),其中权重w表示模型对两个目标(式(30)的makespan和式(31)的tec)之间的偏好。本研究中,w取0.8。约束(32)保证了工件的工序加工时间不发生重叠现象,约束(33)保证了每个工序只可由允许加工的机器加工。约束(34)规定了每个工厂中的起重机的初始位置在相应工厂中加工安排的第一个工序的加工机器上。约束(35)保证了每个工序只由一台机器加工,约束(36)和(37)规定了每台机器在同一时间只能加工一个工序。约束(38)保证了工序根据安排的顺序进行加工,约束(39)保证了工件的加工机器位于选定的工厂内。约束(40)
–
(43)描述了四种起重机状态的发生顺序。约束(44)规定了在每个工厂中,自重运输过程必须当目标位置的机器为空闲状态时才可开始,约束(45)规定了每个工件的第一个工序不需要起重机运输。约束(46)规定了如果一个工件的加工位置和前序位置相同,则此工序不需要起重机运输。约束(47)
–
(50)定义了二元决策变量的范围。
[0150]
本实施例分布估计和变邻域搜索的混合算法如图4所示,在混合算法中,dfjspc的每个解都视为种群的个体。在eda部分,根据个体在种群中的适应度选择优秀的个体来产生新的个体,并替换到种群中相同数量的较差个体。由三个概率矩阵来生成新的个体,这些个体继承了优秀个体的特性。
[0151]
在eda部分中,迭代过程常常会出现过早收敛的情况。因此,将概率矩阵更新的过程设定为自适应过程,模型能够以一个较为平稳的状态进行收敛,提高优化结果。在所述算法中,eda部分具有较强的探索能力。为了提高开拓能力,提出了vns部分,其中包括五种不同的邻域结构,涉及到工厂内的和工厂之间的策略。在算法的每次迭代中,eda部分用来探索更多的优化空间来寻找较优解,vns部分用来在邻域结构中获得更优解。
[0152]
在所述算法的每一次迭代中,eda和vns部分应该同时进行计算。然而,eda在迭代的初始阶段具有较好的优化效果,但是在后续的迭代过程中不能产生更优的解。另外,eda部分需要相当一部分的计算过程。因此,提出了一个控制eda部分启动的概率值。如果在某一轮迭代过程中所有的概率矩阵都没有被更新,则后续的迭代过程中eda不发动。
[0153]
进一步的,解的编码过程为:
[0154]
dfjspc的解由三个向量构成:工厂向量λ,加工向量π和机器安排向量ξ。λ的长度为工件的数量。π和ξ的长度相等,为所有工件的工序总数。对于工厂向量λ={λ1,λ2,
…
,λ
n
},每个元素λ
i
代表工厂的编号。对于加工向量π={π1,π2,
…
,π
n
},每个元素π
i
代表工件的编号,每个工件出现的次数即为该工件的工序。对于机器安排向量ξ={δ1,δ2,
…
,δ
n
},每个元素δ
i
代表了相应工序的可加工机器编号。
[0155]
图5描述了以2工厂4工件2机器(4j2f2m)的编码举例,整个编码的解包括工厂向量,加工向量和机器安排向量。在图5中,工件2和3被分配到了工厂1加工,工件1和4被分配到了工厂2加工。机器1和2在工厂1中,机器3和4在工厂2中。图6画出了这个解的甘特图。
[0156]
解码过程为:
[0157]
当解确定之后,可以根据对应的工厂向量λ、加工向量π和机器安排向量ξ来计算适应度值。
[0158][0159]
初始化和更新过程:
[0160]
所述算法的初始化包括群体解的初始化和eda部分中概率矩阵a、b和c的初始化。群体解是随机进行初始化的。概率矩阵a、b和c分别负责生成工厂向量、加工向量和机器安排向量。
[0161]
a
if
是概率矩阵a的元素,a
if
(gen)表示工件i在第gen代分配给工厂f的概率。概率矩阵a的初始化用式(51)表示,其中f表示工厂总数。a的更新过程用式(52)表示,其中α是概率矩阵a的学习率,si是群体中优秀个体的数量。i
if
用式(53)表示,其中s表示群体中第s优的个体。
[0162][0163][0164][0165]
b
mi
是概率矩阵b的元素,b
mi
(gen)表示工件i在加工向量的第m个位置被分配的概率。概率矩阵b的初始化用式(54)表示,其中i表示工件的总数。b的更新过程用式(55)表示,其中β是概率矩阵b的学习率。i
mi
用式(53)表示。
[0166][0167]
[0168][0169]
c
fijk
是概率矩阵c的元素,c
fijk
(gen)表示工厂f中工件i的第j个工序被分配给机器k加工。概率矩阵c的初始化用式(57)表示,其中k
available
表示工件工件i的第j个工序的可加工机器数。b的更新过程用式(58)表示,其中γ是概率矩阵c的学习率。i
fijk
用式(59)表示。
[0170][0171][0172][0173]
更新公式(52),(55)和(58)的设计确保了:1)在机器向量中,每个工件i在所有工厂中生成概率之和为1;2)在加工向量中,每个位置m对于所有工件的生成概率之和为1;3)在机器分配向量中,每个工序o
i,j
对于所有可加工机器上的生成概率之和为1。引理1、2和3证明了上述结论。
[0174]
引理1:对于工件i,给定当概率矩阵更新后,等式依然成立。
[0175]
证明:根据更新公式(52),公式可以写成式(60)。计算过程为式(61)。注意如果工件i被分配到了工厂f中,则其他工厂不能加工工件i,因此,
[0176][0177][0178]
引理2:对于位置m,给定当概率矩阵更新后,等式依然成立。
[0179]
证明:根据更新公式(55),公式可以写成式(62)。计算过程为式(63)。注意如果工件i在位置m上出现,则在位置m上其他工件不可出现,因此,
[0180]
[0181][0182]
引理3:对于工厂f中的工序o
i,j
,给定其中k为工厂f中的可加工机器数,当概率矩阵更新后,等式依然成立。
[0183]
证明:根据更新公式(58),公式可以写成式(64)。计算过程为式(65)。注意如果工序o
i,j
在机器k上加工,则其他机器不可加工工序o
i,j
,因此,
[0184][0185][0186]
为了改进结果,si,α,β和γ在收敛中为自适应过程。si表示种群在本次迭代中从上一代学习优秀个体的程度。si越小,下一代学习到的特征就越优秀。因此,si应当在迭代过程中逐渐减小,如式(66)所示。对于学习率α,β和γ,他们越大,下一代学习到的优秀特征就越多,因此,α,β和γ应当随着迭代过程逐渐增大,如式(67)
–
式(69)所示。
[0187][0188][0189][0190][0191]
在式(66)中,int[x]为取整函数。α
max
、β
max
、γ
max
和gen
max
为常数,且α
max
、β
max
、γ
max
为在自适应迭代过程中α,β和γ的最大值。从式(67)
–
式(69)可以总结出随着所述算法的迭代,si,α,β和γ的值均匀地分别从20到popsize
×
η、α
max
到0.01、β
max
到0.01、和γ
max
到0.01变换。其中popsize为种群内个体的个数(本研究中popsize为100),η为从种群中划定为优秀个体的比例。
[0192]
eda新解的产生:
[0193]
解的工厂向量、加工向量和机器安排向量分别由概率矩阵a、b和c生成。每个工件的工厂分配是根据工厂向量的概率分布确定的。加工向量中的工序顺序是根据每个位置的概率{p
i1
,p
i2
,
…
,p
ij
}分布确定的。注意到如果一个工件的所有工序都在加工向量中分配,则后续的该工件的概率应为0。这保证了后续的每个位置的概率总和为1。为了得到合理的解,在迭代过程中,每当位置c上的概率分布发生了改变,则进行修复过程,由式(70)计算:
[0194][0195]
每个工序的加工机器分配是根据机器分配向量上的可加工机器概率分布来确定的。
[0196]
eda概率机制:
[0197]
相比于vns部分,eda部分会更消耗计算时间。另外,eda部分在收敛过程的初期作用较大,而在中期和后期作用有限。因此,如果eda部分在每次迭代都进行计算,则会浪费大部分计算时间。
[0198]
本实施例中,采用概率p
eda
来调整eda部分的计算与否。p
eda
的初值为1,表明在迭代开始时eda部分的调用概率为100%。如果在本次迭代中至少有一个概率矩阵的值发生改变,则p
eda
保持不变。如果本次迭代过程中三个概率矩阵都没有发生改变,则p
eda
设置为0,表明在后续的迭代过程中eda部分不会参与计算。应当注意的是vns部分能够引起概率矩阵的改变,因此,即使eda部分在迭代初期不会产生明显的作用,eda部分也会在迭代初期持续参与计算。
[0199]
vns邻域结构:
[0200]
在vns部分中,提出了五种不同的邻域结构,它们包括局部策略和全局策略。这些邻域结构产生的新解也是合理可解的。
[0201]
(1)局部交换邻域结构:
[0202]
局部交换(ls)邻域结构通过交换同一工厂中两个工序的加工位置来产生新的相邻解。图7表示ls邻域结构的过程,具体的ls步骤如下:
[0203]
第1步:随机选择一个工厂,其中的工件数必须至少为2。
[0204]
第2步:在加工向量中,随机选择两个位置p1和p2,这两个位置上的工序都在选定工厂之内。
[0205]
第3步:将选定工厂内所有工序的机器加工安排记录到ms1中。
[0206]
第4步:在加工向量中,交换位置p1和p2。
[0207]
第5步:对于选定工厂的每一个位置,将ms1中记录的每个工序的机器安排还原到机器加工向量中。
[0208]
(2)局部插入邻域结构:
[0209]
局部插入(li)邻域结构通过将一个工序在原位置删除并且插入到一个新的位置来产生邻域解。图8表示li的过程,li的具体步骤如下:
[0210]
第1步:随机选择一个工厂,其中的工件数必须至少为2。
[0211]
第2步:在加工向量中,随机选择两个位置p1和p2,这两个位置上的工序都在选定工厂之内。
[0212]
第3步:将选定工厂内所有工序的机器加工安排记录到ms2中。
[0213]
第4步:在选定的工厂内,将加工向量中p1位置的工序移动到p2位置,将两个位置之间的所有工序(包括p2位置)向前移动一格。
[0214]
第5步:对于选定工厂的每一个位置,将ms2中记录的每个工序的机器安排还原到机器加工向量中。
[0215]
(3)局部移动邻域结构:
[0216]
局部移动(lm)邻域结构通过改变关键路径上工序的机器安排来产生新的邻域解。图9表示lm的过程,lm的具体步骤如下:
[0217]
第1步:将具有最大完工时间的机器视为关键机器。
[0218]
第2步:随机选择关键机器上的一个工序。
[0219]
第3步:改变这个工序的机器安排,选择这个工厂内的其他可用加工机器。
[0220]
(4)全局移动邻域结构:
[0221]
全局移动(gm)邻域结构通过把一个工件的所有工序从一个工厂移入另一个工厂得到新的邻域解。图10表示lm的过程,lm的具体步骤如下:
[0222]
第1步:在工厂向量中,选择一个工件并改变它的工厂安排。
[0223]
第2步:在加工向量中,选择这个工件的所有工序,将其加工工厂进行改变。
[0224]
第3步:在机器安排向量,改变移动后工序的机器安排,新安排的加工机器位于改变后的工厂中,机器的安排从新的工厂内随机进行选择。
[0225]
(5)全局交换邻域结构:
[0226]
全局交换(ge)邻域结构通过交换两个不同工厂的工件工序来得到新的邻域解。图11表示ge的过程,ge的具体步骤如下:
[0227]
第1步:从不同的工厂中分别随机选择一个工件。
[0228]
第2步:在工厂向量中,交换这两个工件的工厂安排。
[0229]
第3步:在加工向量中,将这两个工件的所有工序互相交换安排的工厂。
[0230]
第4步:在机器加工向量中,改变上述工序的机器安排。新安排的加工机器在新安排的工厂内,并且是在可选机器内随机确定的。
[0231]
在vns部分的每次迭代中,只采用一个邻域结构生成新的个体。ls、li、lm、gm和ge的重复次数分别是r
ls
、r
li
、r
lm
、r
gm
和r
ge
。在每次重复中,比较新生成的解和原始解,保留较好的一个。邻域结构的重复次数根据当前迭代代数gen决定(对于第一次迭代,gen为1)。为了改善所述算法,五种邻域结构被设定成八组,vns部分的具体过程通过算法2说明。
[0232][0233]
本实施例提出了混合eda-vns算法来解决dfjspc,eda部分被概率值控制是否启动来减小迭代过程的计算负担,迭代的参数被设定为自适应变化过程。种群通过eda部分的探索能力进行进化,vns部分用于最优值挖掘。在vns部分中,五种包括局部和全局的邻域结构来获得优化后的解。
[0234]
实施例二:
[0235]
本实施例将实施例一所述算法进行实验分析来评价其性能,所述算法和其他的对比算法由c++实现,在intel core i7 2.6-ghz 8gb内存电脑上运行。对比算法包括改进的ga算法、禁忌搜索(ts)算法以及改进的差分进化模拟退火(de-sa)算法。
[0236]
为了比较所述算法和其他算法的性能,提出了如下的相对百分增长(rpi)的性能指标:
[0237][0238]
其中f
c
是给定算法的平均适应度值,f
b
是所有比较算法中f
c
的最优值。
[0239]
实验算例:
[0240]
本实施例包括三种类型的算例。第一类算例通过随机产生,共36个。在第一类算例中,工厂数量f={2,3,5},工件数量i={20,40,60,80,100,200},每个工厂内机器数量m={3,5}。第一类算例用于所述算法和其他算法的性能比较。第二类算例通过随机产生,共10个,用于校正实验的参数。在第二类算例中,工厂数量f=2,工件数量i={20,40,60,80,100},每个工厂内机器数量m={3,5}。第三类算例共12个,用于与精确求解的cplex进行结
果比较。在第三类算例中,工厂数量f={2,3},工件数量i={2,3,4,5,6},每个工厂内机器数量m={2,3}。对于以上三类算例,加工时间平均分布在区间[10,20]。
[0241]
eda-vns算法包含五个重要参数:η、α
max
、β
max
、γ
max
和gen
max
。为了研究这些参数对算法的影响,采用了田口正交试验设计方法(doe)来校正模型参数。每个参数设定了四个水平,如表1所示。
[0242]
表1实验参数和因素水平值
[0243][0244]
根据正交表,通过所述算法采取不同的参数水平组合独立运行了第二类算例16次。参数的适应度值为每个水平所有试验结果的平均值。为了消除不同尺度结果的影响,将平均适应度值进行归一化。对于所有的参数组合,算例i的归一化平均适应度值(naf
i
)由式(72)计算:
[0245][0246]
其中af
i
是算例i的平均适应度值,minaf
i
和maxaf
i
分别是算例i中所有适应度值的最小值和最大值。
[0247]
naf是所有归一化后naf
i
的平均值,通过式(73)计算:
[0248][0249]
其中ci是参数组合的总数。
[0250]
表2正交表以及归一化的平均适应度值
[0251][0252]
通过表2的结果,绘制出图12(a)-图12(e)的每个因素的趋势图。能够看出,η是五个参数中最显著的参数。根据上述分析,确定参数值η=0.5、α
max
=0.2、β
max
=0.2、γ
max
=0.5以及gen
max
=100为后续实验的参数值。
[0253]
参数自适应过程比较实验:
[0254]
为了对比有无自适应过程策略的效果,编写了两种算法:不含自适应过程的eda-vns(eda-vns-na)和包含所有部分的eda-vns。
[0255]
在eda-vns-na中,si=popsize*η(η=0.5)、α=α
max
=0.2、β=β
max
=0.2、以及γ=γ
max
=0.5。除了自适应过程策略,两种算法的其余部分均相同。
[0256]
选择多因素变量分析(anova)将两种对比算法当做其中的因素进行分析。图14(a)显示了两种算法适应度值的平均值和95%置信区间。分析得到的p值小于0.01,说明两种算法具有显著性差异。从实验结果可以得到自适应策略能够显著提升所述算法的性能。
[0257]
探索能力比较实验:
[0258]
为了评价所述算法的探索能力,编写了两种算法:不含eda部分的eda-vns(neda-vns)和包含所有部分的eda-vns。两种算法的其余部分均相同。图15(b)显示了两种算法适应度值的平均值和95%置信区间。分析得到的p值小于0.01,说明两种算法具有显著性差异。从实验结果可以得到eda部分能够显著提升所述算法的性能。
[0259]
挖掘能力比较实验:
[0260]
为了评价所述算法的探索能力,编写了两种算法:不含vns部分的eda-vns(eda-nvns)和包含所有部分的eda-vns。两种算法的其余部分均相同。图15(b)显示了两种算法适应度值的平均值和95%置信区间。分析得到的p值小于0.01,说明两种算法具有显著性差异。从实验结果可以得到vns部分能够显著提升所述算法的性能。
[0261]
为了计算适应度值,本实施例选择权重w(w=0.8)来联合两个目标(makespan和tec)。然而,权重是由决策者从两种目标的关系中主观决定的。因此本实施例将权重设定为0.1~0.9来测试不同的权重值对makespan和tec的影响。本实施例的实验使用了第二类算例,其中的每个算例均独立运行了15次。
[0262]
图13显示了实验的rpi值结果,图中的每个点代表对应的权重下每个算例目标rpi值的平均值。从图13能够看出:(1)权重能够影响makespan和tec的平衡关系,权重较小时优化更偏好tec,权重较大时优化更偏好makespan;(2)相比tec,权重变化对makespan的影响程度更强。
[0263]
与全局优化cplex的比较实验:
[0264]
为了评价所提组合整数规划模型的可行性,选用ibmilogcplex 12.7计算12个小规模算例的解,最大线程为3,cpu运行时间每次设定为3小时。所述算法对每个小算例运行10次,cpu运行时间为30秒。
[0265]
表3 eda-vns与cplex的计算结果比较
[0266][0267]
表3比较了所述算法和cplex的计算结果。第二列表示算例的规模(如3j2f2m表示这个算例包含3个工件,2个工厂,每个工厂有2台机器)。第三列为两种算法得到的最优值。通过两种算法得到的适应度值和rpi分别在后面四列中。
[0268]
从表3可以得到:(1)eda-vns相比cplex能够得到更高质量的解;和(2)随着算例复
杂度的提升,cplex的性能逐渐变差。
[0269]
对比算法性能实验:
[0270]
表4列出了所述算法和其他对比算法的计算结果,其中第一列是算法编号,第二列为算例规模,第三列为四种算法适应度平均值的最优值。第四列到第七列为所有算法独立运行30次的平均值,第八列到第十一列为rpi值。
[0271]
表4显示eda-vns在36个算例中获得了34个最优结果,其他算法的表现相对较差,表明eda-vns相比其他对比算法具有较好的表现。图14(a)
–
图14(h)显示了算例1、7、10、16、20、26、30和36的收敛过程,其收敛数据为30次独立运行后的平均值。图15(d)显示了四种算法的均值和95%置信区间,能够发现eda-vns相比其他算法具有较为显著的优秀表现。
[0272]
表4 eda-vns与其他对比算法的计算结果
[0273][0274]
对于进一步的比较,将makespan和tec的每次运行值作为两个变量进行分析。算例1、7、10、16、20、26、30和36的30次makespan和tec值表示在图16(a)
–
图(h),说明相比其他算法所述算法较为优秀。从图16(a)
–
图(h)可以看出,随着算例规模的增大,不同算法的优化范围越来越明显。
[0275]
图17显示了算例20j3f5m通过所述算法优化后的结果,白框中的x-y表示工序o
x,y
的运行时间。
[0276]
本实施例将所述算法与其他三种不同算法进行性能比较,通过实验分析能够证明所述算法具有可靠性和鲁棒性。
[0277]
实施例三:
[0278]
本实施例还提供了一种带起重机的分布式柔性车间调度系统,包括:
[0279]
参数获取模块,被配置为:获取分布式柔性车间的参数;所述参数包括工厂数量、工件数量、工厂中机器数量、工序数量、起重机位置坐标;
[0280]
模型构建模块,被配置为:基于分布式柔性车间的参数,构建带起重机的分布式柔性车间调度模型;所述带起重机的分布式柔性车间调度模型包括目标函数和约束条件;
[0281]
输出模块,被配置为:基于分布估计和变邻域搜索的混合算法,对带起重机的分布式柔性车间调度模型进行求解;求解输出分布式柔性车间调度方案。
[0282]
实施例四:
[0283]
本发明实施例还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现实施例一所述的带起重机的分布式柔性车间调度方法。
[0284]
实施例五:
[0285]
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现实施例一所述的带起重机的分布式柔性车间调度方法。
[0286]
以上实施例三-五中涉及的各步骤与方法实施例一相对应,具体实施方式可参见实施例一的相关说明部分。术语“计算机可读存储介质”应该理解为包括一个或多个指令集的单个介质或多个介质;还应当被理解为包括任何介质,所述任何介质能够存储、编码或承载用于由处理器执行的指令集并使处理器执行本发明中的任一方法。
[0287]
本领域技术人员应该明白,上述本发明的各模块或各步骤可以用通用的计算机装置来实现,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。本发明不限制于任何特定的硬件和软件的结合。
[0288]
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1