一种基于胶囊生成对抗网络的噪声建模的图像盲去噪方法与流程
本发明属于计算机视觉领域,具体的说是一种基于胶囊生成对抗网络的噪声建模的图像盲去噪方法。
背景技术:
图像去噪是低视力视觉中的经典话题,也是许多视觉任务中重要的预处理步骤。遵循退化模型y=x+v,图像去噪的目标是通过降低噪声v从嘈杂的观测值y中恢复无噪声的图像x。现有的去噪方法基本有三种:基于图像先验的去噪方法,基于噪声建模的盲去噪方法,基于判别学习的去噪方法。
基于图像先验的去噪方法所采用的图像先验主要是基于人类知识来定义的,并且可能会限制去噪性能;此外,在对图像优先级进行建模时,大多数方法仅利用输入图像的内部信息,而未充分利用来自其他图像的外部信息。
基于噪声建模的盲去噪方法仅利用单个输入图像的内部信息并明确定义噪声模型,这可能会限制噪声建模的能力并进一步影响降噪性能。
基于判别学习的去噪方法尽管实现了很高的去噪质量,但是缺少成对的训练数据的情况下却无法工作。
技术实现要素:
本发明是为了解决上述现有技术存在的不足之处,提出一种基于胶囊生成对抗网络的噪声建模的图像盲去噪方法,以期能在面对诸如图像中的噪声信息不可用或者传感器的不确定性这样的情况下依然可以实现图像有效的降噪,并提高降噪效果。
本发明为达到上述发明目的,采用如下技术方案:
本发明一种基于胶囊生成对抗网络的噪声建模的图像盲去噪方法的特点是按如下步骤进行:
步骤1、对于给定的噪声图像提取平滑的噪声块:
步骤1.1、定义循环变量i和j,并初始化i=1;
步骤1.2、以步长sg对一张噪声图像提取大小为c×c的第i个图像块pi;
步骤1.3、初始化j=1;
步骤1.4、以步长为sl对第i个图像块pi提取大小为h×h的第j个局部图像块qij;
步骤1.5、判断第i个图像块pi和第j个局部图像块
式(1)和式(2)中,mean()表示求平均数,var()表示求方差,μ,γ是取值属于(0,1)的常数系数且μ和γ∈(0,1);
步骤1.6、将j+1赋值给j后,返回步骤1.4,直到j=jmax为止;其中,jmax表示对第i个图像块pi最多所能提取的大小h×h的局部图像块的个数,
步骤1.7、将i+1赋值给i后,返回步骤1.3,直到i=imax为止;从而得到最终的平滑噪声块集合s={s1,s2,…,si,…st};其中,imax表示对一张噪声图片最多所能提取的大小c×c的图像块个数,
步骤1.8、利用式(3)得到第i个近似噪声块vi,从而得到近似噪声块集合v={v1,v2,…,vi,…vt}:
vi=si-mean(si)(3)
步骤2、基于胶囊生成对抗网络的噪声建模:
步骤2.1、将生成对抗网络的判别器重构成胶囊神经网络并作为胶囊生成对抗网络中的判别器:
在所述判别器的卷积层中使用c1个大小为n×n的卷积核,且步长设置为s1,在primarycaps层使用c2个大小为n×n的卷积核,且步长设置为s2,digitcaps层的胶囊个数设为k;
步骤2.2、将生成对抗网络的生成器仿照深度卷积对抗网络dcgan中生成器的结构,并作为胶囊生成对抗网络中的生成器:
在所述生成器的反卷积层中使用大小为m×m的微步幅卷积核;所述生成器的最后一层输出层使用tanh函数作为激活函数,而所述生成器的其他层均使用relu作为激活函数;
由胶囊生成对抗网络中的判别器和生成器构成胶囊生成对抗网络;
步骤2.3、选取wgan的损失函数作为所述胶囊生成对抗网络训练过程的目标函数;
步骤2.4、设置胶囊生成对抗网络中的判别器和生成器的迭代次数之比为1∶2;利用所述近似噪声集合v训练所述胶囊生成对抗网络,从而生成噪声样本v′;
步骤3、对深层cnn进行训练,得到一个降噪模型:
步骤3.1、将所获取的一张无噪声图像分成大小为c×c的e个小块,并构成小块集合x={x1,x2,…,xe,…xe},其中,xe表示第e个小块,且e=1,2,…,e;
利用式(4)将噪声样本v′中的第k个噪声块v′k随机添加到小块集合x的第e个小块xe中,从而得到第f个噪声图片yf,从而得到噪声图片集合y={y1,y2,…,yf,…yf},且f=1,2,…,f:
yf=xe+v′k(4)
由小块集合x和噪声图片集合y构成训练数据集{x,y};
步骤3.2、令所述深层cnn与dncnn的网络结构相似:
令所述深层cnn的卷积核的大小为q×q,所述深层cnn的深度为m,所述深层cnn的每一层均采用零填充的方式使得每一层输入和输出的图片尺寸相同;
步骤3.3、选取dncnn的损失函数作为训练过程中的目标函数;
步骤3.4、利用所述训练数据集{x,y}训练所述深层cnn,从而得到降噪模型,以实现对图像的盲去噪。
与现有技术相比,本发明的有益效果在于:
1.本发明方法训练了基于胶囊生成对抗网络,以估计输入噪声图像上的噪声分布并生成噪声样本,从得到的噪声样本中采样的噪声补丁被用于构建配对的训练数据集,该训练数据集又用于训练深度卷积神经网络(cnn)进行降噪。通过整体的流程,在面对诸如图像中的噪声信息不可用或者传感器的不确定性这样的情况下,本发明比现存在的技术表现出一定的优越性。
2.本发明通过将生成对抗网络的判别器重构成胶囊神经网络,重构之后的胶囊神经网络可以改善传统生成对抗网络的判别器在识别对象时没有完全利用人脑的特点,以及改善了传统生成对抗网络的判别器在采样的时候会浪费一些信息的缺点。
3.本发明中使用胶囊生成对抗网络生成更多的噪声数据,使得训练集数据得到加强,比现有的技术中直接训练深层cnn得到降噪模型的效果要更加的优秀。
附图说明
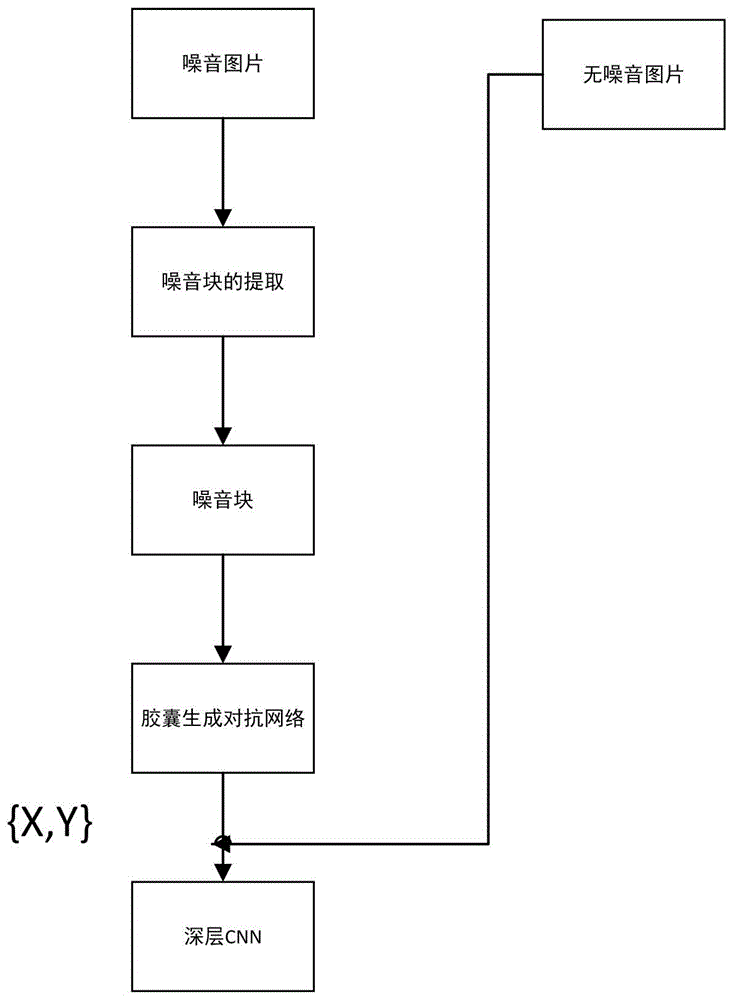
图1为本发明所构建的基于胶囊生成对抗网络的模型示意图;
图2为本发明使用的深层cnn的架构示意图;
图3为本发明使用的胶囊生成对抗网络判别网络架构示意图;
图4本发明使用的胶囊生成对抗网络生成网络架构示意图。
具体实施方式
在本实例中,参见图1,一种基于胶囊生成对抗网络的噪声建模的图像盲去噪方法是按如下步骤进行:
步骤1、对于给定的噪声图像提取平滑的噪声块:
步骤1.1、定义循环变量i和j,并初始化i=1;本实施例中,采用的噪声图像数据集是bsd68。
步骤1.2、以步长sg对一张噪声图像提取大小为c×c的第i个图像块pi,本实施例中,设置sg=32,c=64;
步骤1.3、初始化j=1;
步骤1.4、以步长为sl对第i个图像块pi提取大小为h×h的第j个局部图像块
步骤1.5、判断第i个图像块pi和第j个局部图像块
式(1)和式(2)中,mean()表示求括号内的值的平均数,var()表示求括号内的值的方差,μ,γ是取值属于(0,1)的常数系数;
步骤1.6、将j+1赋值给j后,返回步骤1.4,直到j=jmax为止;其中,jmax表示对第i个图像块pi最多所能提取的大小h×h的局部图像块的个数,
步骤1.7、将i+1赋值给i后,返回步骤1.3,直到i=imax为止;从而得到最终的平滑噪声块集合s={s1,s2,…,si,…st};其中,imax表示对一张噪声图片最多所能提取的大小c×c的图像块个数,
步骤1.8、利用式(3)得到第i个近似噪声块vi,从而得到近似噪声块集合v={v1,v2,…,vi,…vt}:
vi=si-mean(si)(3)
步骤2、基于胶囊生成对抗网络的噪声建模:
步骤2.1、将生成对抗网络的判别器重构成胶囊神经网络并作为胶囊生成对抗网络中的判别器:
在所述判别器的卷积层中使用c1个大小为n×n的卷积核,且步长设置为s1,在primarycaps层使用c2个大小为n×n的卷积核,且步长设置为s2,digitcaps层的胶囊个数设为k,在本实例中,c1=256,n=9,c2=32,s2=2,k=2,判别器总体架构如图3所示;
步骤2.2、将生成对抗网络的生成器仿照深度卷积对抗网络dcgan中生成器的结构,并作为胶囊生成对抗网络中的生成器:
在所述生成器的反卷积层中使用大小为m×m的微步幅卷积核,在本实例中,m设置为5;所述生成器的最后一层输出层使用tanh函数作为激活函数,而所述生成器的其他层均使用relu作为激活函数,生成器总体架构如图4所示;
由胶囊生成对抗网络中的判别器和生成器构成胶囊生成对抗网络;
步骤2.3、选取wgan的损失函数作为所述胶囊生成对抗网络训练过程的目标函数;
步骤2.4、设置胶囊生成对抗网络中的判别器和生成器的迭代次数之比为1∶2;利用所述近似噪声集合v训练所述胶囊生成对抗网络,从而生成噪声样本v′;
步骤3、对深层cnn进行训练,得到一个降噪模型:
步骤3.1、将所获取的一张无噪声图像分成大小为c×c的e个小块,并构成小块集合x={x1,x2,…,xe,…xe},其中,xe表示第e个小块,且e=1,2,…,e,在本实例中,所采用的无噪声训练集是clean1;
利用式(4)将噪声样本v′中的第k个噪声块v′k随机添加到小块集合x的第e个小块xe中,从而得到第f个噪声图片yf,从而得到噪声图片集合y={y1,y2,…,yf,…yf},且f=1,2,…,f:
yf=xe+v′k(4)
由小块集合x和噪声图片集合y构成训练数据集{x,y};
步骤3.2、令所述深层cnn与dncnn的网络结构相似:
令所述深层cnn的卷积核的大小为q×q,所述深层cnn的深度为m,所述深层cnn的每一层均采用零填充的方式使得每一层输入和输出的图片尺寸相同,在本实例中,q=3,m=20,深层cnn的具体架构如图2所示。
步骤3.3、选取dncnn的损失函数作为训练过程中的目标函数;
步骤3.4、利用所述训练数据集{x,y}训练所述深层cnn,从而得到降噪模型,以实现对图像的盲去噪。上述所有步骤的整体架构如图1所示。
实施例:
为了验证本发明方法的有效性,本实例采用混合噪声验证本方法的降噪效果,在本实例中,采用的混合噪声是由10%的均匀噪声(分布区间为[-s,s],20%方差为1的高斯噪声和70%方差为0.01的高斯噪声组成,并且采用峰值信噪比(psnr)作为评价指标,如表1所示。
表1
从表1的实验结果可以看出,本发明方法在混合噪声去噪方面,无论是在噪声非盲模式下的已存在的方法bm3d,wnnm,epll,还是噪声盲去噪模式下的已存在方法multisclale,dncnn,峰值信噪比都比这些方法要高,显示了本方法的优越性。
- 还没有人留言评论。精彩留言会获得点赞!