一种日志文件的统计与异常探测方法及电子装置与流程
[0001]
本发明属于软件设计与应用技术领域尤其涉及一种日志文件的统计与异常探测方法及电子装置。
背景技术:
[0002]
日志是业务系统状态的一种记录,是一种时间序列数据。对应用系统的日志数据进行分析有助于了解该应用系统的运行状态。通常,日志分析系统并不会随业务系统一起上线。现实情况多是业务系统上线一段时间后产生对一些需要进行日志分析的业务需求,如考察网站的流量变化,异常流量及原因尤其在网站经历一次攻击后;业务的日志格式可能随时间有所变化;历史日志被打包备份在硬盘上。如何对此种场景下的日志进行分析是现实环境中一个亟待解决的问题。
[0003]
目前,市场上存在很多开源或商业的日志处理分析工具。elk(elasticsearch logstash kibana)是在工业界得到普遍应用的工具集。其各组件可以灵活地应用到不同地架构中,以便应对不同的分析应用。本发明基于elk提出一种框架来处理上述场景下的日志分析。
[0004]
异常探测在很多领域都有应用,且其定义通常依赖于领域知识。日志反映了用户访问业务网站的行为,对其进行异常探测可用于辨别业务网站是否存在爬虫或其他恶意攻击。elk的机器学习组件支持的异常探测整合了包括聚类、时间序列分解、贝叶斯分布模型及关联分析等多种机器学习方法,但需付费订阅。本发明应用统计方法和python机器学习类库scikit-learn对日志进行了异常探测分析。
技术实现要素:
[0005]
本发明为了解决上述背景中提到的至少一个技术问题,提出了一种日志文件的统计与异常探测方法及电子装置,利用elasticsearch技术栈相关工具进行日志分析处理,并依据分析处理结果,实现异常探测。
[0006]
本发明的技术方案包括:
[0007]
一种日志文件的统计方法,其步骤包括:
[0008]
1)将日志文件转化为事件流;
[0009]
2)解析事件流中的事件,将不同业务类型的日志文件转化为具有相同结构的结构化日志数据,其中通过解析事件流中的事件时间戳,得到结构化日志数据时间戳;
[0010]
3)依据结构化日志数据时间戳与通过ip分析出的地域信息,对结构化日志数据进行统计分析,得到日志统计结果。
[0011]
进一步地,将日志文件转化为事件流的方法包括:使用filebeat。
[0012]
进一步地,所述日志文件包括:历史日志文件和实时日志文件。
[0013]
进一步地,若系统没有消息队列组件,设置logstash流水线的logstash persistent queue作事件缓存;若系统已经有消息队列组件,logstash流水线利用此消息
队列组件作事件缓存。
[0014]
进一步地,通过不同的logstash流水线,解析历史日志文件事件流和实时日志文件事件流中的不同业务类型的事件。
[0015]
进一步地,将日志统计结果存储至关系型数据库中。
[0016]
进一步地,对于历史日志文件,得到日志统计结果的方法包括:按设定时间段对日志进行统计并持久化至关系型数据库中,随后基于此关系型数据库作聚合统计、或直接利用es的聚合查询接口对es中的日记文档进行统计。
[0017]
进一步地,通过以下步骤解析事件流中的事件:
[0018]
1)通过grok将事件流中的每个事件即日志记录解析成多个键值对;
[0019]
2)移除不感兴趣的键值对;
[0020]
3)依据请求类型丢掉静态文件请求事件及图标请求事件;
[0021]
4)对保留的键值对做进一步拆分和重命名。
[0022]
进一步地,将结构化日志数据时间戳存为一字段并索引为date格式。
[0023]
进一步地,通过以下步骤所述字段索引为date格式:
[0024]
1)按照默认方式索引部分日志数据,得到默认的索引模板;
[0025]
2)在默认的索引模板基础上,通过put_templateapi创建新的索引模板,设置相应字段索引为date格式;
[0026]
3)删除已索引的日志数据,并重新导入数据使其按照新的索引模板索引数据。
[0027]
一种日志文件的异常探测方法,其步骤包括:
[0028]
1)对通过上述方法得到的结构化日志数据进行聚合,依据连续相同大小的时间窗口内的不同ip的请求数量,得到一个以请求量为元素的数组a和另一个包含结构化日志数据时间戳及ip元信息的数组b;
[0029]
2)通过机器学习方法对数组a进行分析,得到异常的请求量,并利用数组a与数组b之间的关联关系,得到异常发生的时间窗口和ip元信息;
[0030]
3)对各异常发生的时间窗口内的ip的请求进行请求响应聚合,依据聚合后请求响应分布信息,确定异常发生的时间和请求ip。
[0031]
进一步地,机器学习方法包括:scikit-learn中的异常探测分析方法localoutilierfactor。
[0032]
一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述所述的方法。
[0033]
一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机以执行上述所述的方法。
[0034]
与现有技术相比,本发明具有以下优点:
[0035]
(1)对异构日志数据进行处理,从而构成具有相同结构的结构化数据,以便统计分析需要。
[0036]
(2)基于解析后的结构化数据进行包括统计量(一般为请求数、下载量等)、时间、地域(依ip地址得出)在内的二维或三维统计分析。
[0037]
(3)依据日志进行业务网站异常流量探测,以便进一步分析是否存在爬虫或恶意攻击。
附图说明
[0038]
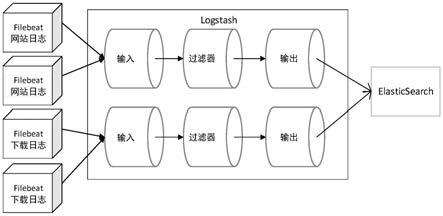
图1为本发明的日志处理实施架构图。
[0039]
图2为本发明的日志处理过滤流程图。
[0040]
图3为本发明的异常探测流程图。
具体实施方式
[0041]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施例和附图,对本发明做进一步详细说明。
[0042]
本发明的日志分析与异常探测系统,包括:
[0043]
(1)本发明采用filebeat将日志文件转化为事件流,利用logstash流水线对事件流中的事件进行解析,转化为具有相同结构的结构化数据,并存储至es集群。需对历史日志、不同业务的日志启动不同的filebeat实例。logstash过滤掉无关的事件如静态文件请求,网站页面的图标请求等。es集群根据业务需求配置索引以便据业务进行日志的统计分析。日志记录中的时间戳对日志统计有重要意义,需要将该时间戳信息提取转化并按“date”格式进行索引。
[0044]
(2)ngnix日志通常包含时间戳、ip地址、访问的url,请求类型等信息。针对网站日志的统计因此主要涉及某一时间段内网站的总访问量,不同ip的访问量,不同地域的访问量等。可归纳为统计量、时间的二维统计,以及统计量、时间、地域的三维统计。利用es提供聚合操作api或嵌套聚合可得出此类统计结果。但当聚合操作涉及的数据量较大时(时间跨度较大),聚合操作容易超时。因此,实时对数据做统计不可行。本发明采用对历史统计结果进行持久化,对部分数据实时统计的策略,避免重复计算。历史统计依据时间维度存入postgres关系型数据库中。空间维度利用postgres对json数据结构的支持将同一时间跨度下的地域分布存为json格式。
[0045]
(3)对日志进行异常探测有利于网站安全。就业务网站访问日志而言,一段时间窗口内请求量激增意味着可能有异常发生(如爬虫或恶意攻击)。本发明以解析后的索引日志为目标数据,首先利用es的聚合算法得到一段时间内某一时间窗口的各ip的访问量。然后对此聚合结果进行重组得到一访问量数组。随后利用机器学习类库scikit-learn中的聚类方法进行异常值分析,每个数组中的每个访问量将得到一个异常值。由此得到访问量对应的时间点和ip。进一步据此过滤出此间的请求并分析其响应状态分布可判断是发生异常请求。
[0046]
本发明的日志分析与异常探测方法,包括以下步骤:
[0047]
(1)日志解析
[0048]
本发明的实施架构图如图1所示。历史日志、实时日志文件经过filebeat转化为事件流经logstash流水线处理存储至es集群。在存放日志的机器上分别启动filebeat实例,依据日志类型设置filebeat的输出为logstash的不同socket。logstash设置两条流水线分别用于处理下载日志和网站日志,输入分别为其实例的不同socket,依日志类型作不同处理,处理成具有相同结构的数据并输出至es存储索引。
[0049]
如图2所示,首先通过grok将日志记录解析成多个键值对;然后移除不感兴趣的键值对;依据请求类型丢掉静态文件请求及图标请求;对保留的键值对做进一步拆分、重命名
等变换。grok社区提供了一些日志记录的匹配模式,实际应用中可基于合适的模式作一些改动以满足实际需求。
[0050]
通过设置logstash persistent queue作为事件缓存,而无需引入消息队列来缓存,还可以应对logstash机器故障重启,保证数据可靠性。已有的系统可能已经有消息队列组件,此时,可将消息队列包含在架构中。
[0051]
日志作为时间序列数据,其时间戳具有重要意义。默认情况下,logstash选取其初次读取日志记录的时间作为时间戳。对于历史日志来说显然不合适,实时日志也会在filebeat异常情况下导致时间偏移较大。因此,需要将通过grok解析出来的时间戳存为一字段并索引为date格式,以此作为日志记录的时间戳,以便基于时间范围作日志统计。
[0052]
要将处理的字段索引为date格式,需修改日志索引(默认为logstash-*)的索引模板。可在logstash流水线设置文件中配置logstash-*的索引模板。或者先按照默认方式索引部分日志数据,然后通过put_templateapi修改创建的索引模板即设置提取的时间戳字段为date索引,再删除已索引的日志数据,重新导入数据即可。
[0053]
(2)日志统计
[0054]
日志统计分析基于解析索引后的具有相同结构的结构化日志数据。对于历史日志的统计,本发明比较了两种统计方式。一种是按天对日志进行统计并持久化至关系型数据库中,业务需要时再对关系型数据库进行聚合查询返回一段时间内的统计结果。每天的日志统计结果如表1所示。
[0055]
表1每天的统计
[0056]
日期ip访问量城市
[0057]
另一种方式是直接利用es的聚合查询接口得出业务所需的统计结果并存入关系型数据库中,业务需要时直接查询关系型数据库即可。两种方式均对统计结果作了间接或直接的持久化,因此可以将es中已统计完的历史日志数据删除。
[0058]
两种统计方式的比较如表2所示。
[0059]
表2历史日志统计方式比较
[0060][0061]
本实施例采用方式二进行历史日志的统计,得出的统计结果为json格式,经简单处理可存入postgres数据库中,其中涉及地域的三维统计可利用postgres对json格式的支持,如表3所示。
[0062]
表3聚合统计结果
[0063]
[0064]
(3)异常探测
[0065]
本发明中,对于异常访问的探测,采用结合领域知识和机器学习方法的方式进行。网站访问日志的异常主要考虑爬虫和恶意攻击,这两者都意味着短时间内访问流量异常增大。异常的主体应考虑为ip地址。将时间流划分为连续的相同大小的时间窗口,以这些时间窗口内的请求数量为机器学习分析的目标数据。
[0066]
异常探测流程如图3所示,具体表述如下。
[0067]
首先利用es的组合聚合操作对目标日志(比如某一日的日志)进行聚合,获取连续时间窗口(如十分钟)内的不同ip的请求数量。统计结果为下述形式。
[0068]
[0069][0070]
对上述数据进行变换得到一以请求量为元素的数组a=[[0,请求量],[1,请求量],...]和另一存有时间戳及ip元信息的数组b=[[
‘
datetime-ip’],[datetime-ip],...],a、b根据下标关联。
[0071]
利用scikit-learn中的异常探测分析方法localoutilierfactor对a数组进行分析,a数组中的每个元素将收获一异常值。异常值越大表示即表示异常发生。由a、b之间的关联关系可以得出异常发生的时间窗口和ip元信息
‘
datetime-ip’。据此元信息再利用es聚合操作可以进一步查看该时间窗口该ip的请求响应信息。
[0072][0073]
以示例数据为例,可以发现ip地址"210.27.112.57"在时间窗口[2020-08-06t09:20:00.000z,2020-08-06t09:30:00.000z]内的请求响应代码均为500,由此可以断定发生恶意请求。
[0074]
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本
发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1